
txtai 是一个用于语义搜索、LLM 编排和语言模型工作流的一体化 AI 框架。

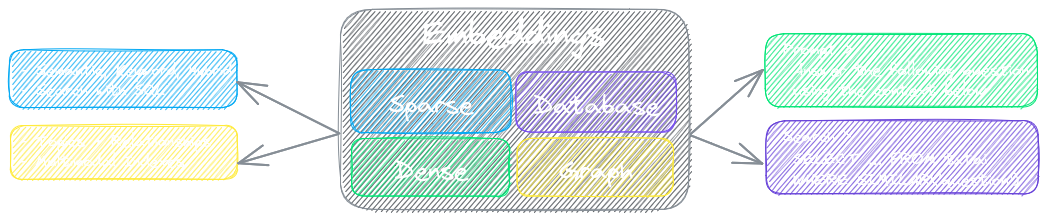
txtai 的关键组件是嵌入数据库,它是向量索引(稀疏和密集)、图网络和关系数据库的联合。
该基础支持向量搜索和/或作为大型语言模型 (LLM) 应用的强大知识源。
构建自主代理、检索增强生成 (RAG) 流程、多模型工作流程等。
txtai 功能总结:
🔎 使用 SQL、对象存储、主题建模、图形分析和多模态索引进行向量搜索
📄 为文本、文档、音频、图像和视频创建嵌入
💡 由语言模型驱动的管道,运行 LLM 提示、问答、标记、转录、翻译、摘要等
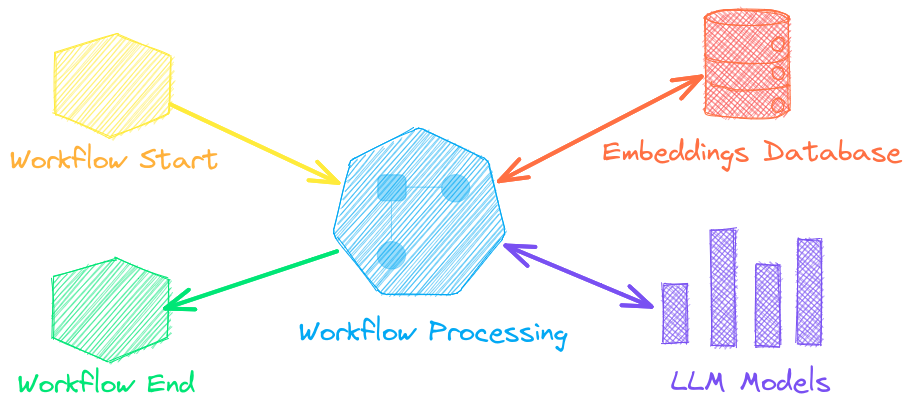
↪️️ 工作流将管道连接在一起并聚合业务逻辑。txtai 流程可以是简单的微服务或多模型工作流。
🤖 智能地将嵌入、管道、工作流和其他代理连接在一起,以自主解决复杂问题
⚙️ Web 和模型上下文协议 (MCP) API。可用于JavaScript 、 Java 、 Rust和Go 的绑定。
🔋 默认配备电池,可快速启动和运行
☁️ 本地运行或使用容器编排进行扩展
txtai 是基于 Python 3.10+、 Hugging Face Transformers 、 Sentence Transformers和FastAPI构建的。txtai 在 Apache 2.0 许可下开源。
想要了解如何轻松安全地运行托管的 txtai 应用程序?那就加入
为什么是 txtai?


新的矢量数据库、LLM 框架以及介于两者之间的各种技术每天都在涌现。为什么要使用 txtai 进行构建?
内置 API 让您可以轻松地使用您选择的编程语言开发应用程序
本地运行——无需将数据发送到不同的远程服务
使用微模型直至大型语言模型 (LLM)
占用空间小——安装额外的依赖项并在需要时扩展
通过示例学习- 笔记本涵盖所有可用功能
Related MCP server: ReActMCP Web Search
用例
以下章节介绍了常见的 txtai 用例。此外,我们还提供了一套包含 60 多个示例笔记本和应用程序的综合资源。
语义搜索
构建语义/相似性/向量/神经搜索应用程序。

传统的搜索系统使用关键词来查找数据。语义搜索能够理解自然语言,并识别具有相同含义(不一定是相同的关键词)的结果。

从以下示例开始。
|笔记本|描述|
|:---|:---|---:|
|txtai 介绍▶️|txtai 提供的功能概述|![]() |
|图像相似性搜索|将图像和文本嵌入到同一空间进行搜索|
|
|图像相似性搜索|将图像和文本嵌入到同一空间进行搜索|![]() |
|建立 QA 数据库|问题匹配与语义搜索|
|
|建立 QA 数据库|问题匹配与语义搜索|![]() |
|语义图|探索主题、数据连接并运行网络分析|
|
|语义图|探索主题、数据连接并运行网络分析|![]() |
|
LLM 编排
自主代理、检索增强生成 (RAG)、与您的数据聊天、与大型语言模型 (LLM) 接口的管道和工作流。
请参阅下文以了解更多信息。
|笔记本|描述|
|:---|:---|---:|
|提示模板和任务链|构建模型提示并将任务与工作流连接在一起|![]() |
|整合 LLM 框架|集成 llama.cpp、LiteLLM 和自定义生成框架|
|
|整合 LLM 框架|集成 llama.cpp、LiteLLM 和自定义生成框架|![]() |
|使用 LLM 构建知识图谱|使用 LLM 驱动的实体提取构建知识图谱|
|
|使用 LLM 构建知识图谱|使用 LLM 驱动的实体提取构建知识图谱|![]() |
|使用 txtai 解析星星|探索已知恒星、行星、星系的天文知识图谱|
|
|使用 txtai 解析星星|探索已知恒星、行星、星系的天文知识图谱|![]() |
|
代理商
代理将嵌入、管道、工作流和其他代理连接在一起,以自主解决复杂问题。
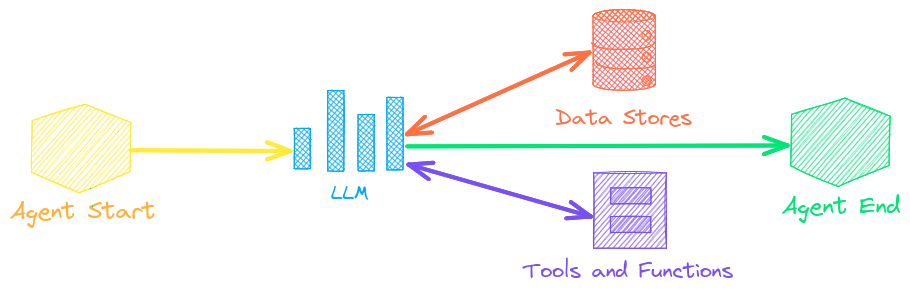
txtai 代理基于smolagents框架构建。它支持 txtai 所支持的所有 LLM(Hugging Face、llama.cpp、OpenAI / Claude / 通过 LiteLLM 实现的 AWS Bedrock)。
请参阅下面的链接以了解更多信息。
|笔记本|描述|
|:---|:---|---:|
|使用图表和代理分析“拥抱脸”帖子|使用图形分析和代理探索丰富的数据集|![]() |
|赋予代理人自主权|按照自己的意愿迭代解决问题的代理|
|
|赋予代理人自主权|按照自己的意愿迭代解决问题的代理|![]() |
|使用图表和代理分析 LinkedIn 公司帖子|探索如何利用人工智能提高社交媒体参与度|
|
|使用图表和代理分析 LinkedIn 公司帖子|探索如何利用人工智能提高社交媒体参与度|![]() |
|
检索增强生成
检索增强生成 (RAG) 通过使用知识库作为上下文来约束输出,从而降低了 LLM 幻觉的风险。RAG 通常用于“与数据对话”。


txtai 的一个新颖的特点是它可以同时提供答案和来源引用。
|笔记本|描述|
|:---|:---|---:|
|使用 txtai 构建 RAG 管道|检索增强生成指南,包括如何创建引文|![]() |
|为 RAG 分块数据|提取、分块和索引内容以实现有效检索|
|
|为 RAG 分块数据|提取、分块和索引内容以实现有效检索|![]() |
|具有图形路径遍历的高级 RAG|图形路径遍历,为高级 RAG 收集复杂的数据集|
|
|具有图形路径遍历的高级 RAG|图形路径遍历,为高级 RAG 收集复杂的数据集|![]() |
|语音到语音 RAG ▶️|使用 RAG 的全周期语音到语音工作流程|
|
|语音到语音 RAG ▶️|使用 RAG 的全周期语音到语音工作流程|![]() |
|
语言模型工作流程
语言模型工作流(也称为语义工作流)将语言模型连接在一起以构建智能应用程序。

虽然 LLM 功能强大,但也存在许多规模更小、更专业的模型,它们能够更好、更快地完成特定任务。这些模型包括用于提取式问答、自动摘要、文本转语音、转录和翻译的模型。
|笔记本|描述|
|:---|:---|---:|
|运行管道工作流程▶️|简单而强大的结构可以高效处理数据|![]() |
|构建抽象文本摘要|运行抽象文本摘要|
|
|构建抽象文本摘要|运行抽象文本摘要|![]() |
|将音频转录为文本|将音频文件转换为文本|
|
|将音频转录为文本|将音频文件转换为文本|![]() |
|在多种语言之间翻译文本|简化机器翻译和语言检测|
|
|在多种语言之间翻译文本|简化机器翻译和语言检测|![]() |
|
安装


最简单的安装方法是通过 pip 和 PyPI
支持 Python 3.10+。建议使用 Python虚拟环境。
请参阅详细的安装说明以获取更多信息,包括可选依赖项、特定于环境的先决条件、从源代码安装、 conda 支持以及如何使用容器运行。
模型指南
请参阅下表,了解当前推荐的型号。这些型号均可用于商业用途,并兼具速度和性能。
成分 | 型号 |
使用训练管道进行微调 | |
模型可以通过 Hugging Face Hub 中的路径或本地目录加载。模型路径可选,未指定时会加载默认值。对于没有推荐模型的任务,txtai 会使用 Hugging Face 任务指南中所示的默认模型。
请参阅以下链接以了解更多信息。
由 txtai 提供支持
以下应用程序由 txtai 提供支持。
除了此列表之外,还有许多其他开源项目、已发布的研究成果和封闭的专有/商业项目在生产中基于 txtai 构建。
进一步阅读


文档
txtai 的完整文档包括嵌入、管道、工作流、API 的配置设置以及常见问题的常见问题解答。
贡献
对于那些想要为 txtai 做出贡献的人,请参阅本指南。
{kind=link}
{kind=link}
{kind=link}