
txtai — это комплексная среда искусственного интеллекта для семантического поиска, оркестровки LLM и рабочих процессов языковой модели.

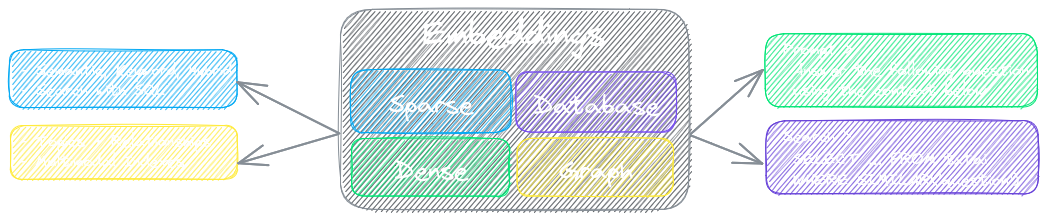
Ключевым компонентом txtai является база данных вложений, которая представляет собой объединение векторных индексов (разреженных и плотных), графовых сетей и реляционных баз данных.
Эта основа позволяет осуществлять векторный поиск и/или служит мощным источником знаний для приложений большой языковой модели (LLM).
Создавайте автономные агенты, процессы расширенной генерации данных (RAG), многомодельные рабочие процессы и многое другое.
Краткое описание возможностей txtai:
🔎 Векторный поиск с SQL, хранилищем объектов, тематическим моделированием, анализом графов и мультимодальным индексированием
📄 Создавайте вставки для текста, документов, аудио, изображений и видео
💡 Конвейеры на основе языковых моделей, которые запускают подсказки LLM, вопросы и ответы, маркировку, транскрипцию, перевод, реферирование и многое другое
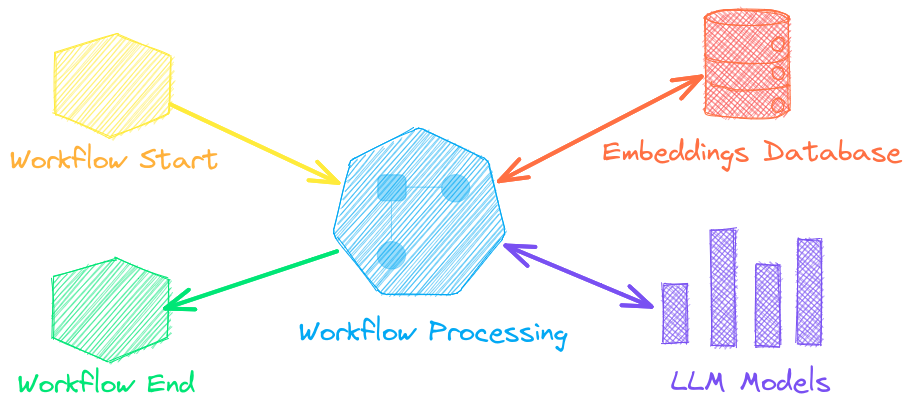
↪️️ Рабочие процессы для объединения конвейеров и агрегации бизнес-логики. Процессы txtai могут быть простыми микросервисами или многомодельными рабочими процессами.
🤖 Агенты, которые интеллектуально связывают встраивания, конвейеры, рабочие процессы и других агентов вместе для автономного решения сложных задач
⚙️ API Web и Model Context Protocol (MCP). Доступны привязки для JavaScript , Java , Rust и Go .
🔋 В комплект поставки входят батареи по умолчанию для быстрого начала работы
☁️ Запуск локально или масштабирование с помощью оркестровки контейнеров
txtai создан с использованием Python 3.10+, Hugging Face Transformers , Sentence Transformers и FastAPI . txtai имеет открытый исходный код под лицензией Apache 2.0.
Интересуетесь простым и безопасным способом запуска размещенных приложений txtai? Тогда присоединяйтесь к предварительному просмотру
Почему TXTAI?


Новые векторные базы данных, фреймворки LLM и все, что между ними, появляются ежедневно. Зачем разрабатывать с txtai?
Встроенный API упрощает разработку приложений с использованием выбранного вами языка программирования.
Работает локально — нет необходимости отправлять данные в разрозненные удаленные службы
Работа с микромоделями вплоть до больших языковых моделей (LLM)
Низкий уровень энергопотребления — устанавливайте дополнительные зависимости и масштабируйте по мере необходимости
Учитесь на примерах — ноутбуки охватывают все доступные функции
Related MCP server: ReActMCP Web Search
Варианты использования
В следующих разделах представлены общие случаи использования txtai. Также доступен полный набор из более чем 60 примеров блокнотов и приложений .
Семантический поиск
Создавайте приложения семантического/сходного/векторного/нейронного поиска.

Традиционные поисковые системы используют ключевые слова для поиска данных. Семантический поиск понимает естественный язык и находит результаты, имеющие одинаковое значение, не обязательно одинаковые ключевые слова.

Начните со следующих примеров.
|Блокнот|Описание|
|:---|:---|---:|
|Представляем txtai ▶️|Обзор функциональных возможностей, предоставляемых txtai|![]() |
|Поиск сходства с изображениями|Встраивайте изображения и текст в одно и то же пространство для поиска|
|
|Поиск сходства с изображениями|Встраивайте изображения и текст в одно и то же пространство для поиска|![]() |
|Создание базы данных контроля качества|Сопоставление вопросов с семантическим поиском|
|
|Создание базы данных контроля качества|Сопоставление вопросов с семантическим поиском|![]() |
|Семантические графы|Изучите темы, возможности подключения к данным и проведите сетевой анализ|
|
|Семантические графы|Изучите темы, возможности подключения к данным и проведите сетевой анализ|![]() |
|
Магистр права (LLM) по оркестровке
Автономные агенты, расширенная генерация данных (RAG), чат с вашими данными, конвейеры и рабочие процессы, взаимодействующие с большими языковыми моделями (LLM).
Более подробную информацию смотрите ниже.
|Блокнот|Описание|
|:---|:---|---:|
|Шаблоны подсказок и цепочки задач|Создавайте подсказки для моделей и связывайте задачи с рабочими процессами|![]() |
|Интеграция фреймворков LLM|Интеграция llama.cpp, LiteLLM и пользовательских фреймворков генерации|
|
|Интеграция фреймворков LLM|Интеграция llama.cpp, LiteLLM и пользовательских фреймворков генерации|![]() |
|Создавайте графы знаний с помощью LLM|Создавайте графы знаний с помощью извлечения сущностей на основе LLM|
|
|Создавайте графы знаний с помощью LLM|Создавайте графы знаний с помощью извлечения сущностей на основе LLM|![]() |
|Анализ звезд с помощью txtai|Изучите график астрономических знаний известных звезд, планет и галактик.|
|
|Анализ звезд с помощью txtai|Изучите график астрономических знаний известных звезд, планет и галактик.|![]() |
|
Агенты
Агенты объединяют встраивания, конвейеры, рабочие процессы и других агентов для автономного решения сложных задач.
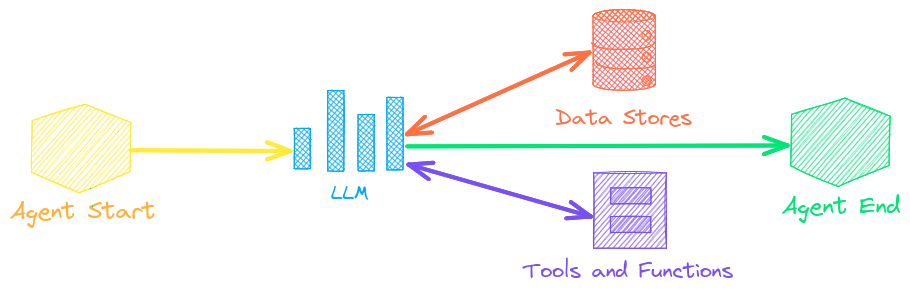
Агенты txtai построены на основе фреймворка smolagents . Он поддерживает все LLM, поддерживаемые txtai (Hugging Face, llama.cpp, OpenAI / Claude / AWS Bedrock через LiteLLM).
Более подробную информацию можно узнать по ссылке ниже.
|Блокнот|Описание|
|:---|:---|---:|
|Анализ постов с объятиями с помощью графиков и агентов|Исследуйте богатый набор данных с помощью графического анализа и агентов|![]() |
|Предоставление автономии агентам|Агенты, которые итеративно решают проблемы так, как считают нужным|
|
|Предоставление автономии агентам|Агенты, которые итеративно решают проблемы так, как считают нужным|![]() |
|Анализ публикаций компании в LinkedIn с помощью графиков и агентов|Изучение того, как улучшить взаимодействие в социальных сетях с помощью ИИ|
|
|Анализ публикаций компании в LinkedIn с помощью графиков и агентов|Изучение того, как улучшить взаимодействие в социальных сетях с помощью ИИ|![]() |
|
Дополненная генерация поиска
Дополненная генерация поиска (RAG) снижает риск галлюцинаций LLM, ограничивая вывод базой знаний в качестве контекста. RAG обычно используется для «чата с вашими данными».


Новой функцией txtai является то, что он может предоставить как ответ, так и ссылку на источник.
|Блокнот|Описание|
|:---|:---|---:|
|Создание RAG-конвейеров с помощью txtai|Руководство по поиску дополненной реальности, включая создание ссылок|![]() |
|Разделение данных на части для RAG|Извлечение, фрагментация и индексация контента для эффективного поиска|
|
|Разделение данных на части для RAG|Извлечение, фрагментация и индексация контента для эффективного поиска|![]() |
|Расширенный RAG с обходом пути графа|Обход пути графа для сбора сложных наборов данных для расширенного RAG|
|
|Расширенный RAG с обходом пути графа|Обход пути графа для сбора сложных наборов данных для расширенного RAG|![]() |
|Речь в речь RAG ▶️|Полный цикл речевого рабочего процесса с RAG|
|
|Речь в речь RAG ▶️|Полный цикл речевого рабочего процесса с RAG|![]() |
|
Рабочие процессы языковой модели
Рабочие процессы языковых моделей, также известные как семантические рабочие процессы, объединяют языковые модели для создания интеллектуальных приложений.

Хотя LLM являются мощными, есть множество меньших, более специализированных моделей, которые работают лучше и быстрее для определенных задач. Это включает модели для извлекаемых вопросов-ответов, автоматического реферирования, преобразования текста в речь, транскрипции и перевода.
|Блокнот|Описание|
|:---|:---|---:|
|Запуск рабочих процессов конвейера ▶️|Простые, но мощные конструкции для эффективной обработки данных|![]() |
|Создание абстрактных текстовых резюме|Выполнить абстрактное резюмирование текста|
|
|Создание абстрактных текстовых резюме|Выполнить абстрактное резюмирование текста|![]() |
|Транскрибировать аудио в текст|Конвертировать аудиофайлы в текст|
|
|Транскрибировать аудио в текст|Конвертировать аудиофайлы в текст|![]() |
|Перевод текста между языками|Оптимизируйте машинный перевод и определение языка|
|
|Перевод текста между языками|Оптимизируйте машинный перевод и определение языка|![]() |
|
Установка


Самый простой способ установки — через pip и PyPI.
Поддерживается Python 3.10+. Рекомендуется использовать виртуальную среду Python.
Подробные инструкции по установке содержат дополнительную информацию о дополнительных зависимостях , предварительных условиях для конкретной среды , установке из исходного кода , поддержке conda и о том, как работать с контейнерами .
Модель руководства
См. таблицу ниже для текущих рекомендуемых моделей. Все эти модели допускают коммерческое использование и предлагают сочетание скорости и производительности.
Компонент | Модель(и) |
Тонкая настройка с помощью конвейера обучения | |
Модели можно загрузить как путь из Hugging Face Hub или локального каталога. Пути к моделям необязательны, если не указано иное, загружаются значения по умолчанию. Для задач без рекомендуемой модели txtai использует модели по умолчанию, как показано в руководстве Hugging Face Tasks.
Более подробную информацию можно узнать по следующим ссылкам.
При поддержке txtai
Следующие приложения работают на базе txtai.
Приложение | Описание |
Приложение Retrieval Augmented Generation (RAG) | |
Создание баз знаний для RAG | |
Семантический поиск и рабочие процессы для медицинских/научных статей | |
Автоматически аннотировать статьи с LLM |
В дополнение к этому списку существует также множество других проектов с открытым исходным кодом , опубликованных исследований и закрытых проприетарных/коммерческих проектов, которые построены на TXTAI в производстве.
Дальнейшее чтение


Представляем txtai — комплексную платформу искусственного интеллекта
Что нового в txtai 8.0 | 7.0 | 6.0 | 5.0 | 4.0
Начало работы с семантическим поиском | рабочие процессы | rag
Документация
Доступна полная документация по txtai, включая параметры конфигурации для встраивания, конвейеров, рабочих процессов, API, а также раздел часто задаваемых вопросов и ответов на распространенные проблемы.
Внося вклад
Для тех, кто хотел бы внести свой вклад в txtai, пожалуйста, ознакомьтесь с этим руководством .
{kind=link}
{kind=link}
{kind=link}