
txtai は、セマンティック検索、LLM オーケストレーション、言語モデル ワークフローのためのオールインワン AI フレームワークです。

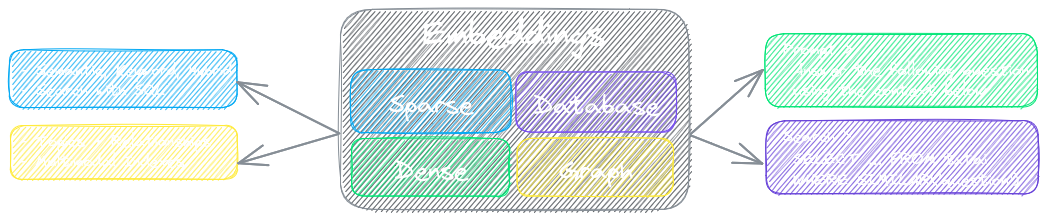
txtai の主要コンポーネントは、ベクトル インデックス (スパースとデンス)、グラフ ネットワーク、およびリレーショナル データベースの結合である埋め込みデータベースです。
この基盤により、ベクトル検索が可能になり、大規模言語モデル (LLM) アプリケーションのための強力な知識ソースとして機能します。
自律エージェント、検索拡張生成 (RAG) プロセス、マルチモデル ワークフローなどを構築します。
txtai の機能の概要:
🔎 SQL、オブジェクトストレージ、トピックモデリング、グラフ分析、マルチモーダルインデックスを使用したベクトル検索
📄 テキスト、ドキュメント、オーディオ、画像、ビデオの埋め込みを作成する
💡 LLMプロンプト、質問応答、ラベル付け、文字起こし、翻訳、要約などを実行する言語モデルを搭載したパイプライン
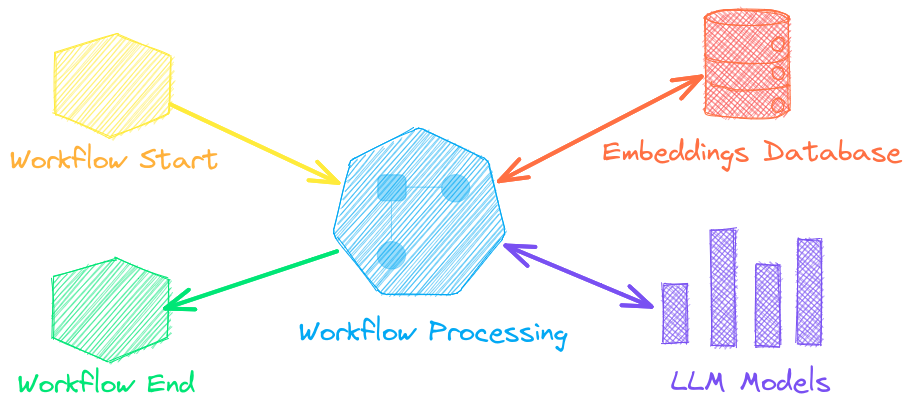
↪️️ パイプラインを結合してビジネス ロジックを集約するワークフロー。txtai プロセスは、単純なマイクロサービスまたはマルチモデル ワークフローにすることができます。
🤖 埋め込み、パイプライン、ワークフロー、その他のエージェントをインテリジェントに接続し、複雑な問題を自律的に解決するエージェント
⚙️ Web および Model Context Protocol (MCP) API。JavaScript、 Java 、 Rust 、 Goのバインディングが利用可能です。
🔋 すぐに起動できるようにバッテリーが標準装備されています
☁️ コンテナ オーケストレーションを使用してローカルで実行またはスケールアウトする
txtai は、Python 3.10+、 Hugging Face Transformers 、 Sentence Transformers 、 FastAPIを使用して構築されています。txtai は、Apache 2.0 ライセンスに基づくオープンソースです。
ホストされた txtai アプリケーションを簡単かつ安全に実行する方法に興味がありますか?
なぜtxtaiなのか?


新しいベクターデータベース、LLMフレームワーク、そしてその間のあらゆるものが日々誕生しています。なぜtxtaiで構築するのでしょうか?
組み込みAPIにより、お好みのプログラミング言語を使用してアプリケーションを簡単に開発できます。
ローカルで実行 - 異なるリモート サービスにデータを送信する必要がない
マイクロモデルから大規模言語モデル(LLM)までを扱う
フットプリントが小さい - 追加の依存関係をインストールし、必要に応じてスケールアップします
例で学ぶ- ノートブックは利用可能なすべての機能をカバーします
Related MCP server: ReActMCP Web Search
ユースケース
以下のセクションでは、txtaiの一般的な使用例を紹介します。60を超える包括的なサンプルノートブックとアプリケーションもご用意しています。
セマンティック検索
セマンティック/類似性/ベクトル/ニューラル検索アプリケーションを構築します。

従来の検索システムは、キーワードを使ってデータを検索します。セマンティック検索は自然言語を理解し、必ずしも同じキーワードではなく、同じ意味を持つ結果を識別します。

次の例から始めましょう。
|ノート|説明|
|:---|:---|---:|
|txtaiのご紹介▶️|txtaiが提供する機能の概要|![]() |
|画像による類似検索|画像とテキストを同じスペースに埋め込んで検索する|
|
|画像による類似検索|画像とテキストを同じスペースに埋め込んで検索する|![]() |
|QAデータベースを構築する|セマンティック検索による質問マッチング|
|
|QAデータベースを構築する|セマンティック検索による質問マッチング|![]() |
|セマンティックグラフ|トピック、データの接続性を探索し、ネットワーク分析を実行する|
|
|セマンティックグラフ|トピック、データの接続性を探索し、ネットワーク分析を実行する|![]() |
|
LLMオーケストレーション
自律エージェント、検索拡張生成 (RAG)、データとのチャット、大規模言語モデル (LLM) とインターフェースするパイプラインおよびワークフロー。
詳細については以下を参照してください。
|ノート|説明|
|:---|:---|---:|
|プロンプトテンプレートとタスクチェーン|モデルプロンプトを構築し、ワークフローを使用してタスクを接続する|![]() |
|LLMフレームワークを統合する|llama.cpp、LiteLLM、カスタム生成フレームワークを統合する|
|
|LLMフレームワークを統合する|llama.cpp、LiteLLM、カスタム生成フレームワークを統合する|![]() |
|LLMで知識グラフを構築する|LLM 駆動型エンティティ抽出によるナレッジ グラフの構築|
|
|LLMで知識グラフを構築する|LLM 駆動型エンティティ抽出によるナレッジ グラフの構築|![]() |
|txtaiで星を解析する|既知の星、惑星、銀河の天文学的知識グラフを探索する|
|
|txtaiで星を解析する|既知の星、惑星、銀河の天文学的知識グラフを探索する|![]() |
|
エージェント
エージェントは、埋め込み、パイプライン、ワークフロー、およびその他のエージェントを接続して、複雑な問題を自律的に解決します。
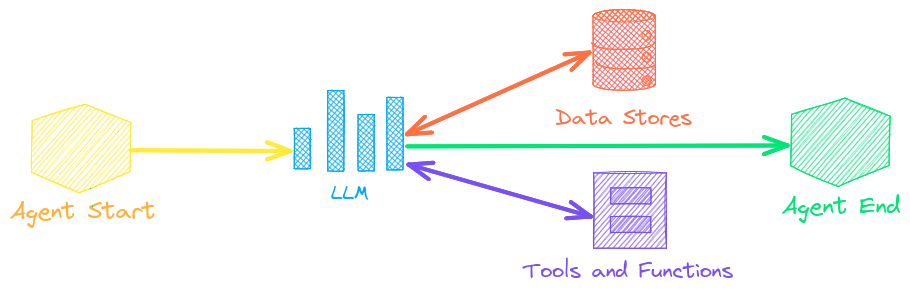
txtaiエージェントはsmolagentsフレームワーク上に構築されています。txtaiがサポートするすべてのLLM(Hugging Face、llama.cpp、OpenAI / Claude / AWS Bedrock(LiteLLM経由))をサポートします。
詳細については、以下のリンクをご覧ください。
|ノート|説明|
|:---|:---|---:|
|グラフとエージェントを用いたハグフェイス投稿の分析|グラフ分析とエージェントで豊富なデータセットを探索する|![]() |
|エージェントに自律性を与える|問題を適切に反復的に解決するエージェント|
|
|エージェントに自律性を与える|問題を適切に反復的に解決するエージェント|![]() |
|LinkedIn の企業投稿をグラフとエージェントで分析する|AIを活用してソーシャルメディアのエンゲージメントを向上させる方法を探る|
|
|LinkedIn の企業投稿をグラフとエージェントで分析する|AIを活用してソーシャルメディアのエンゲージメントを向上させる方法を探る|![]() |
|
検索拡張生成
検索拡張生成(RAG)は、知識ベースをコンテキストとして出力を制約することで、LLM幻覚のリスクを軽減します。RAGは一般的に「データとチャットする」ために使用されます。


txtai の新しい機能は、回答とソースの引用の両方を提供できることです。
|ノート|説明|
|:---|:---|---:|
|txtaiでRAGパイプラインを構築する|引用の作成方法を含む検索拡張生成に関するガイド|![]() |
|RAG 用にデータをチャンク化する|効果的な検索のためにコンテンツを抽出、チャンク化、インデックス化する|
|
|RAG 用にデータをチャンク化する|効果的な検索のためにコンテンツを抽出、チャンク化、インデックス化する|![]() |
|グラフパストラバーサルを備えた高度なRAG|高度なRAGのための複雑なデータセットを収集するためのグラフパストラバーサル|
|
|グラフパストラバーサルを備えた高度なRAG|高度なRAGのための複雑なデータセットを収集するためのグラフパストラバーサル|![]() |
|スピーチ・トゥ・スピーチ RAG ▶️|RAG を使用したフルサイクルの音声対音声ワークフロー|
|
|スピーチ・トゥ・スピーチ RAG ▶️|RAG を使用したフルサイクルの音声対音声ワークフロー|![]() |
|
言語モデルワークフロー
言語モデル ワークフロー (セマンティック ワークフローとも呼ばれます) は、言語モデルを接続してインテリジェントなアプリケーションを構築します。

LLMは強力ですが、特定のタスクにおいてより効率的かつ高速に動作する、より小規模で特化したモデルも数多く存在します。これには、抽出型質問応答、自動要約、音声合成、文字起こし、翻訳などのモデルが含まれます。
|ノート|説明|
|:---|:---|---:|
|パイプラインワークフローを実行する▶️|データを効率的に処理するためのシンプルかつ強力な構造|![]() |
|抽象的なテキスト要約の作成|抽象的なテキスト要約を実行する|
|
|抽象的なテキスト要約の作成|抽象的なテキスト要約を実行する|![]() |
|音声をテキストに書き起こす|オーディオファイルをテキストに変換する|
|
|音声をテキストに書き起こす|オーディオファイルをテキストに変換する|![]() |
|言語間でテキストを翻訳する|機械翻訳と言語検出を効率化|
|
|言語間でテキストを翻訳する|機械翻訳と言語検出を効率化|![]() |
|
インストール


最も簡単な方法はpipとPyPIを使うことです
Python 3.10以降がサポートされています。Python仮想環境の使用をお勧めします。
オプションの依存関係、環境固有の前提条件、ソースからのインストール、 conda のサポート、コンテナーでの実行方法などの詳細については、詳細なインストール手順を参照してください。
モデルガイド
現在推奨されているモデルについては、以下の表をご覧ください。これらのモデルはすべて商用利用が可能で、速度とパフォーマンスのバランスが取れています。
成分 | モデル |
トレーニングパイプラインで微調整する | |
モデルは、Hugging Face Hubからのパスまたはローカルディレクトリから読み込むことができます。モデルパスの指定は任意で、指定がない場合はデフォルトのモデルが読み込まれます。推奨モデルが指定されていないタスクの場合、txtaiはHugging Face Tasksガイドに記載されているデフォルトのモデルを使用します。
詳細については、次のリンクを参照してください。
txtaiによって提供
以下のアプリケーションはtxtaiによって提供されています。
このリストに加えて、txtai をベースに製品を構築した他のオープンソース プロジェクト、公開された研究、およびクローズドなプロプライエタリ/商用プロジェクトも多数あります。
さらに読む


ドキュメント
埋め込み、パイプライン、ワークフロー、API の構成設定や、よくある質問/問題に関する FAQ など、 txtai に関する完全なドキュメントが利用可能です。
貢献
txtai に貢献したい方は、このガイドをご覧ください。
{kind=link}
{kind=link}
{kind=link}