
Docs MCP 서버: AI의 최신 문서 전문가
AI 코딩 어시스턴트는 종종 오래된 문서로 인해 잘못된 제안이나 환각적인 코드 예시를 생성하는 데 어려움을 겪습니다. 특정 라이브러리 버전과 AI 응답을 비교하는 것은 시간이 많이 걸리고 비효율적일 수 있습니다.
Docs MCP 서버는 AI 비서를 위한 개인적이고 항상 최신 상태를 유지하는 지식 베이스 역할을 함으로써 이 문제를 해결합니다. 주요 목적은 코드베이스에서 실제로 사용하는 라이브러리 인 타사 문서를 색인하는 것 입니다. 웹사이트, GitHub 저장소, 패키지 관리자(npm, PyPI), 심지어 로컬 파일까지 스크래핑하여 로컬에서 문서를 카탈로그화합니다. 그런 다음 모델 컨텍스트 프로토콜(MCP)을 통해 코딩 에이전트에 강력한 검색 도구를 제공합니다.
이를 통해 LLM 에이전트는 귀하가 추가하는 모든 라이브러리에 대한 최신 공식 문서 에 액세스할 수 있어 생성된 코드와 통합 세부 정보의 품질과 안정성이 획기적으로 향상됩니다.
Docs MCP 서버는 정확하고 버전을 고려한 컨텍스트에서 AI 응답을 제공함으로써 간결하고 관련성 있는 통합 세부 정보와 코드 조각을 수신할 수 있도록 하여 LLM 지원 개발의 안정성과 효율성을 향상시킵니다.
무료 이며, 오픈 소스이고 , 개인정보 보호를 위해 로컬로 실행되며, 개발 워크플로에 완벽하게 통합됩니다.
Docs MCP 서버를 사용해야 하는 이유는 무엇입니까?
LLM 지원 코딩은 속도와 효율성을 약속하지만 다음과 같은 이유로 종종 기대에 미치지 못합니다.
🌀 오래된 지식: LLM은 인터넷 스냅샷을 기반으로 교육을 받기 때문에 새로운 라이브러리 릴리스와 API 변경 사항에 빠르게 뒤처집니다.
👻 코드 환각: AI는 구문적으로는 올바르지만 기능적으로는 틀렸거나 존재하지 않는 API를 사용하는 것처럼 보이는 코드를 만들어낼 수 있습니다.
❓ 버전 모호성: 일반적인 답변은 프로젝트 의 특정 버전 종속성을 거의 고려하지 않아 미묘한 버그가 발생합니다.
⏳ 검증 오버헤드: 개발자는 AI 제안을 공식 문서와 다시 한번 확인하는 데 귀중한 시간을 소비합니다.
Docs MCP 서버는 다음을 통해 이러한 문제를 직접 해결합니다.
✅ 항상 최신 컨텍스트 제공: 요구에 따라 공식 소스(웹사이트, GitHub, npm, PyPI, 로컬 파일)에서 직접 문서를 가져와 색인합니다.
🎯 버전별 답변 제공: 검색 질의는 정확한 라이브러리 버전을 타겟으로 하여 정보가 프로젝트 종속성과 일치하는지 확인할 수 있습니다.
💡 환각 감소: LLM을 실제 문서에 기반하여 정확한 예와 통합 세부 정보를 제공합니다.
⚡ 생산성 향상: AI 비서 워크플로에 직접 통합되어 신뢰할 수 있는 답변을 더 빠르게 얻을 수 있습니다.
Related MCP server: mcp-hn
✨ 주요 특징
최신 지식: 소스에서 직접 최신 문서를 가져옵니다.
버전별 검색: 특정 라이브러리 버전과 관련된 답변을 얻으세요(예:
react@18.2.0대react@17.0.0).정확한 스니펫: 공식 문서의 맥락을 활용하여 AI의 환각 현상을 줄입니다.
웹 인터페이스: 문서 검색 및 관리를 위한 사용하기 쉬운 웹 인터페이스를 제공합니다.
광범위한 소스 호환성: 웹사이트, GitHub 저장소, 패키지 관리자 사이트(npm, PyPI), 심지어 로컬 파일 디렉터리까지 스크래핑합니다.
지능형 처리: 문서를 의미적으로 자동으로 분류하고 임베딩을 생성합니다.
유연한 임베딩 모델: OpenAI(Ollama와 같은 호환 API 포함), Google Gemini/Vertex AI, Azure OpenAI, AWS Bedrock 등을 지원합니다.
강력한 하이브리드 검색: 벡터 유사성과 전체 텍스트 검색을 결합하여 관련성을 높입니다.
로컬 및 개인 정보 보호: 전적으로 사용자의 컴퓨터에서 실행되므로 데이터와 쿼리가 비공개로 유지됩니다.
무료 & 오픈 소스: 커뮤니티를 위해, 커뮤니티에 의해 만들어졌습니다.
간단한 배포: Docker 또는
npx통한 간편한 설정.원활한 통합: MCP 호환 클라이언트(예: Claude, Cline, Roo)와 함께 작동합니다.
Docs MCP 서버를 실행하는 방법
빠르게 시작하세요! 가장 간편한 설정과 관리를 위해 Docker Desktop(Docker Compose)을 사용하는 것을 권장합니다.
권장: Docker Desktop
이 방법은 Docker Compose를 사용하여 서버와 웹 인터페이스를 실행하여 지속적인 로컬 설정을 제공합니다. 저장소를 복제해야 하지만 두 서비스를 함께 관리하는 것이 더 간편해집니다.
Docker와 Docker Compose가 설치되어 실행 중인지 확인하세요.
저장소를 복제합니다.
지엑스피1
환경 설정: 예제 환경 파일을 복사하고 편집하여 OpenAI API 키를 추가합니다(필수):
cp .env.example .env # Edit the .env file and set your OpenAI API key:예시
.env:OPENAI_API_KEY=your-api-key-here추가 구성 옵션(예: 다른 공급자, 고급 설정)에 대한 내용은 구성 섹션을 참조하세요.
서비스 시작: 저장소의 루트 디렉터리에서 이 명령을 실행하세요. 필요한 경우 이미지를 빌드하고 백그라운드에서 서버와 웹 인터페이스를 시작합니다.
docker compose up -d-d: 컨테이너를 분리 모드(백그라운드)로 실행합니다. 터미널에서 로그를 직접 보려면 이 옵션을 생략하세요.
참고: 저장소에 대한 업데이트를 가져오는 경우(예:
git pull사용),docker compose up -d --build실행하여 변경 사항을 포함하도록 Docker 이미지를 다시 빌드해야 합니다.MCP 클라이언트를 구성하세요. 다음 구성 블록을 MCP 설정 파일에 추가하세요(예: Claude, Cline, Roo의 경우):
{ "mcpServers": { "docs-mcp-server": { "url": "http://localhost:6280/sse", // Connects via HTTP to the Docker Compose service "disabled": false, "autoApprove": [] } } }구성을 업데이트한 후 AI 어시스턴트 애플리케이션을 다시 시작하세요.
참고: Docker Compose 설정은 Docs MCP 서버를 HTTP 모드(SSE를 통해)로 실행하도록 설계되었으며, 독립형 연결 가능 인스턴스로 의도되었습니다. stdio 통신은 지원하지 않습니다.
웹 인터페이스에 접속하세요. 웹 인터페이스는
http://localhost:6281에서 이용할 수 있습니다.
이 방법의 이점:
단일 명령으로 서버와 웹 UI를 모두 실행합니다.
로컬 소스 코드를 사용합니다(코드가 변경되고
docker compose up --build실행하면 자동으로 다시 빌드됨).docs-mcp-dataDocker 볼륨을 통한 지속적인 데이터 저장..env파일을 통해 구성 관리가 간편합니다.
서비스를 중지하려면 저장소 디렉토리에서 docker compose down 실행합니다.
라이브러리 문서 추가
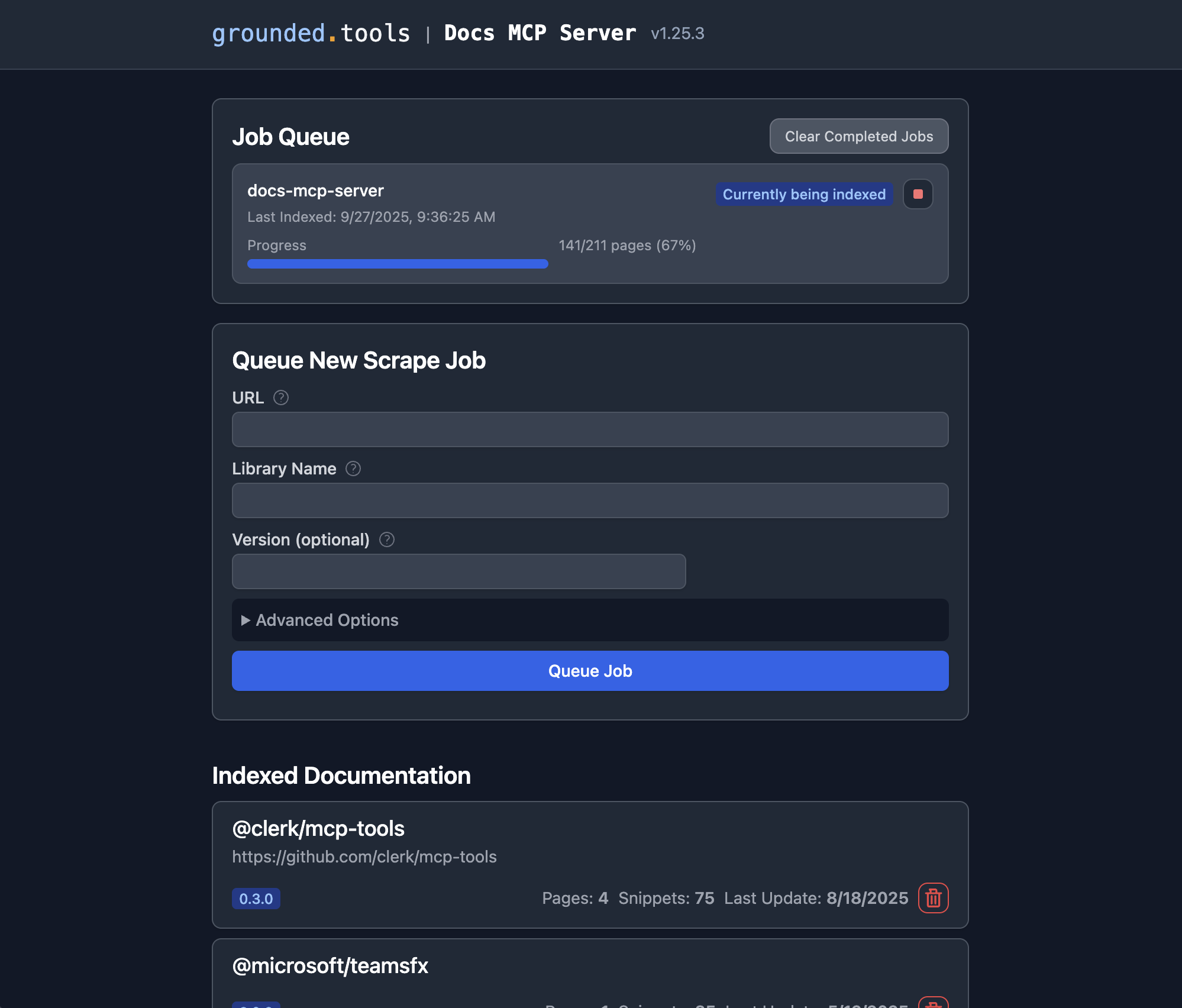
Docs MCP 서버가 실행되면 웹 인터페이스를 사용하여 색인할 새 문서를 추가하거나 기존 문서를 검색할 수 있습니다.
웹 인터페이스를 엽니다. 권장되는 Docker Compose 설정을 사용한 경우 브라우저에서
http://localhost:6281로 이동합니다."새로운 스크레이프 작업 대기" 양식을 찾으세요. 이 양식은 일반적으로 메인 페이지에 눈에 띄게 표시됩니다.
세부 정보를 입력하세요:
URL: 인덱싱하려는 문서의 시작 URL을 제공합니다(예:
https://react.dev/reference/react,https://github.com/expressjs/express,https://docs.python.org/3/).라이브러리 이름: 짧고 기억하기 쉬운 이름을 지정하세요(예:
react,express,python). 검색 시 참조할 때 사용됩니다.버전(선택 사항): 특정 버전을 인덱싱하려면 여기에 입력하세요(예:
18.2.0,4.17.1,3.11). 비워 두면 서버가 최신 버전을 감지하거나 버전이 지정되지 않은 버전으로 인덱싱하는 경우가 많습니다.(선택 사항) 고급 설정: 필요에 따라
Scope(예: '하위 페이지', '호스트 이름', '도메인'),Max Pages,Max Depth,Follow Redirects조정합니다. 일반적으로 기본값으로 충분합니다.
"작업 대기"를 클릭하세요. 서버가 문서를 가져오고, 처리하고, 색인하기 위한 백그라운드 작업을 시작합니다. 웹 UI의 "작업 대기" 섹션에서 진행 상황을 확인할 수 있습니다.
반복: 서버에서 문서를 관리하려는 모든 라이브러리에 대해 3~4단계를 반복합니다.
이제 완료되었습니다! 작업이 성공적으로 완료되면 해당 라이브러리 및 버전에 대한 문서를 연결된 AI 코딩 어시스턴트( search_docs 도구 사용)에서 검색하거나 웹 UI에서 "색인된 문서" 섹션에서 라이브러리 이름을 클릭하여 직접 검색할 수 있습니다.
대안: Docker 사용
이 방법은 쉽고 간단하며 저장소를 복제할 필요가 없습니다.
Docker가 설치되어 실행 중인지 확인하세요.
MCP 설정을 구성하세요.
Claude/Cline/Roo 구성 예: 다음 구성 블록을 MCP 설정 파일에 추가합니다(필요에 따라 경로를 조정).
{ "mcpServers": { "docs-mcp-server": { "command": "docker", "args": [ "run", "-i", "--rm", "-e", "OPENAI_API_KEY", "-v", "docs-mcp-data:/data", "ghcr.io/arabold/docs-mcp-server:latest" ], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }"sk-proj-..."실제 OpenAI API 키로 바꾸고 애플리케이션을 다시 시작하세요.이제 AI 비서가 서버를 사용할 수 있습니다.
Docker 컨테이너 설정:
-i: STDIN을 열어두는 것은 stdio를 통한 MCP 통신에 필수적입니다.--rm: 컨테이너가 종료될 때 자동으로 제거합니다.-e OPENAI_API_KEY: 필수. OpenAI API 키를 설정하세요.-v docs-mcp-data:/data: 지속성을 위해 필수입니다.docs-mcp-data라는 이름의 Docker 볼륨을 마운트하여 데이터베이스를 저장합니다. 원하는 경우 특정 호스트 경로로 바꿀 수 있습니다(예:-v /path/on/host:/data).
모든 구성 환경 변수(위의 구성 참조)는 -e 플래그를 사용하여 컨테이너에 전달할 수 있습니다. 예:
웹 인터페이스 시작
브라우저를 통해 http://localhost:6281 에서 웹 기반 GUI에 접속하여 도서관 문서를 관리하고 검색할 수 있습니다.
Docker로 서버를 실행하는 경우 웹 인터페이스에도 Docker를 사용하세요.
다음 사항을 확인하세요.
서버와 동일한 볼륨 이름(이 예에서는
docs-mcp-data)을 사용하세요.-p 6281:6281로 포트 6281을 매핑합니다.-e플래그를 사용하여 모든 구성 환경 변수를 전달합니다.
CLI 사용
이미지 이름 뒤에 CLI 명령을 전달하여 Docker를 통해 직접 문서를 관리할 수 있습니다.
예:
MCP 서버 컨테이너와 데이터를 공유하려면 동일한 볼륨 이름(이 예에서는 docs-mcp-data )을 사용해야 합니다. 모든 구성 환경 변수(위의 구성 참조)는 -e 플래그를 사용하여 전달할 수 있습니다.
사용 가능한 주요 명령은 다음과 같습니다.
scrape: URL에서 문서를 스크래핑하고 인덱싱합니다.search: 색인된 문서를 검색합니다.list: 인덱스된 모든 라이브러리를 나열합니다.remove: 인덱스된 문서를 제거합니다.fetch-url: 단일 URL을 가져와서 마크다운으로 변환합니다.find-version: 라이브러리에 가장 잘 맞는 버전을 찾습니다.
자세한 명령어 사용법을 보려면 --help 플래그를 사용하여 CLI를 실행하세요(예: docker run ... ghcr.io/arabold/docs-mcp-server:latest --help ).
대안: npx 사용
이 방법은 로컬 파일 접근이 필요할 때 유용합니다(예: 로컬 파일 시스템에서 문서 인덱싱). Docker 컨테이너에 경로를 마운트하여 접근할 수도 있지만, npx 사용하는 것이 더 간단하지만 Node.js 설치가 필요합니다.
Node.js가 설치되어 있는지 확인하세요.
MCP 설정을 구성하세요.
Claude/Cline/Roo 구성 예: MCP 설정 파일에 다음 구성 블록을 추가합니다.
{ "mcpServers": { "docs-mcp-server": { "command": "npx", "args": ["-y", "@arabold/docs-mcp-server"], // This will run the default MCP server (stdio). // To run in HTTP mode, add arguments: e.g. // "args": ["-y", "@arabold/docs-mcp-server", "--protocol", "http", "--port", "6280"], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }"sk-proj-..."실제 OpenAI API 키로 바꾸고 애플리케이션을 다시 시작하세요.이제 AI 비서가 서버를 사용할 수 있습니다.
웹 인터페이스 시작
npx 로 MCP 서버를 실행하는 경우(위에 표시된 대로 기본적으로 실행됨) 웹 인터페이스에도 npx 사용하세요.
--port 플래그를 사용하여 웹 인터페이스에 다른 포트를 지정할 수 있습니다.
npx 방식은 시스템의 기본 데이터 디렉터리(일반적으로 홈 디렉터리)를 사용하여 서버와 웹 인터페이스 간의 일관성을 보장합니다.
CLI 사용
npx 로 MCP 서버를 실행하는 경우 CLI 명령에도 npx 사용할 수 있습니다.
예:
npx 방식은 일관성을 보장하기 위해 시스템의 기본 데이터 디렉터리(일반적으로 홈 디렉터리)를 사용합니다.
자세한 명령어 사용법을 보려면 --help 플래그(예: npx -y @arabold/docs-mcp-server --help )를 사용하여 CLI를 실행하세요.
구성
다음 환경 변수는 임베딩 모델 동작을 구성하는 데 지원됩니다. .env 파일에 환경 변수를 지정하거나 Docker 또는 npx를 통해 서버를 실행할 때 -e 플래그로 전달하세요.
임베딩 모델 구성
DOCS_MCP_EMBEDDING_MODEL: 선택 사항입니다. 형식:provider:model_name또는model_name(기본값:text-embedding-3-small). 지원되는 공급자 및 필수 환경 변수는 다음과 같습니다.openai(기본 공급자): OpenAI의 임베딩 모델을 사용합니다.OPENAI_API_KEY: OpenAI API 키입니다.openaiOPENAI_ORG_ID: 선택 사항. OpenAI 조직 ID입니다.OPENAI_API_BASE: 선택 사항. OpenAI 호환 API(예: Ollama)에 대한 사용자 지정 기본 URL입니다.
vertex: Google Cloud Vertex AI 임베딩을 사용합니다.GOOGLE_APPLICATION_CREDENTIALS: 필수. 서비스 계정 JSON 키 파일 경로입니다.
gemini: Google Generative AI(제미니) 임베딩을 사용합니다.GOOGLE_API_KEY: 필수. Google API 키입니다.
aws: AWS Bedrock 임베딩을 사용합니다AWS_ACCESS_KEY_ID: 필수. AWS 액세스 키AWS_SECRET_ACCESS_KEY: 필수. AWS 비밀 키AWS_REGION또는BEDROCK_AWS_REGION: 필수. Bedrock용 AWS 리전입니다.
microsoft: Azure OpenAI 임베딩 사용AZURE_OPENAI_API_KEY: 필수. Azure OpenAI API 키AZURE_OPENAI_API_INSTANCE_NAME: 필수. Azure 인스턴스 이름입니다.AZURE_OPENAI_API_DEPLOYMENT_NAME: 필수. Azure 배포 이름입니다.AZURE_OPENAI_API_VERSION: 필수. Azure API 버전입니다.
벡터 차원
데이터베이스 스키마는 벡터 임베딩에 1536의 고정된 차원을 사용합니다. 차원 축소를 지원하는 특정 제공자(예: Gemini)를 제외하고, 차원이 1536 이하인 벡터를 생성하는 모델만 지원됩니다.
OpenAI 호환 API(예: Ollama)의 경우 엔드포인트를 가리키는 OPENAI_API_BASE 와 함께 openai 공급자를 사용하세요.
개발
이 섹션에서는 개발 목적으로 소스 코드에서 직접 서버/CLI를 실행하는 방법을 다룹니다. 주요 사용 방법은 "대안: Docker 사용" 섹션에 설명된 대로 공개 Docker 이미지( ghcr.io/arabold/docs-mcp-server:latest )를 사용하거나, "권장: Docker Desktop" 섹션에 설명된 대로 Docker Compose를 사용하는 것입니다.
소스에서 실행
참고: Playwright 브라우저는
npm install명령으로 자동으로 설치되지 않습니다. Playwright가 필요한 테스트를 실행하거나 기능을 사용하려면 다음을 실행하세요.npx playwright install --no-shell --with-deps chromium
이는 격리된 환경을 제공하고 HTTP 엔드포인트를 통해 서버를 노출합니다.
이 방법은 프로젝트에 기여하거나 공개되지 않은 버전을 실행하는 데 유용합니다.
저장소를 복제합니다.
git clone https://github.com/arabold/docs-mcp-server.git # Replace with actual URL if different cd docs-mcp-server종속성 설치:
npm install프로젝트 빌드: TypeScript를 JavaScript로 컴파일하여
dist/디렉토리에 저장합니다.npm run build설정 환경: 구성 섹션에 설명된 대로
.env파일을 만들고 구성하세요. 이는OPENAI_API_KEY제공하는 데 필수적입니다.달리다:
기본 MCP 서버(개발):
Stdio 모드(기본값):
npm run dev:serverHTTP 모드:
npm run dev:server:http(기본 포트 사용)사용자 지정 HTTP:
vite-node src/index.ts -- --protocol http --port <your_port>
웹 인터페이스(개발):
npm run dev:web이렇게 하면 웹 서버(예: 포트 6281)가 시작되고 자산 변경 사항을 감시합니다.
CLI 명령(개발):
npm run dev:cli -- <command> [options]예:
npm run dev:cli -- list예:
vite-node src/index.ts scrape <library> <url>
프로덕션 모드(
기본 MCP 서버(stdio):
npm run start(또는node dist/index.js)MCP 서버(HTTP):
npm run start -- --protocol http --port <your_port>(또는node dist/index.js --protocol http --port <your_port>)웹 인터페이스:
npm run web -- --port <web_port>(또는node dist/index.js web --port <web_port>)CLI 명령:
npm run cli -- <command> [options](또는node dist/index.js <command> [options])
테스트
MCP 서버는 Node.js(또는 vite-node )를 통해 직접 실행할 경우 stdio를 통해 통신하므로 디버깅이 어려울 수 있습니다. MCP Inspector 사용을 권장합니다.
프로젝트를 빌드한 후( npm run build ):
개발에 vite-node 사용하는 경우:
검사기는 브라우저에서 디버깅 도구에 액세스할 수 있는 URL을 제공합니다.
건축학
프로젝트의 아키텍처와 디자인 원칙에 대한 자세한 내용은 ARCHITECTURE.md를 참조하세요.
특히, 이 프로젝트 코드의 대부분은 AI 비서 클라인에 의해 생성되었으며, 바로 이 MCP 서버의 기능을 활용했습니다.