
Docs MCP サーバー: AI による最新のドキュメント作成エキスパート
AIコーディングアシスタントは、古いドキュメントに苦労することが多く、誤った提案や幻覚的なコード例が表示されることがあります。AIの応答を特定のライブラリバージョンと照合するのは、時間がかかり、非効率的になる可能性があります。
Docs MCP Serverは、 AIアシスタントのための常に最新の個人用ナレッジベースとして機能することで、この問題を解決します。主な目的は、サードパーティのドキュメント、つまりコードベースで実際に使用しているライブラリをインデックス化することです。ウェブサイト、GitHubリポジトリ、パッケージマネージャー(npm、PyPI)、さらにはローカルファイルからドキュメントをスクレイピングし、ローカルでカタログ化します。そして、Model Context Protocol(MCP)を介して、コーディングエージェントに強力な検索ツールを提供します。
これにより、LLM エージェントは追加したライブラリの最新の公式ドキュメントにアクセスできるようになり、生成されたコードと統合の詳細の品質と信頼性が大幅に向上します。
Docs MCP サーバーでは、AI 応答を正確なバージョン認識コンテキストに基盤を置くことで、簡潔で関連性の高い統合の詳細とコード スニペットを受け取ることができるため、LLM 支援開発の信頼性と効率が向上します。
無料、オープンソース、プライバシー保護のためローカルで実行され、開発ワークフローにシームレスに統合されます。
Docs MCP サーバーを使用する理由
LLM 支援コーディングはスピードと効率を約束しますが、多くの場合、次の理由により不十分です。
🌀古い知識: LLM はインターネットのスナップショットでトレーニングするため、新しいライブラリのリリースや API の変更にすぐに遅れてしまいます。
👻コードの幻覚: AI は、構文的には正しいが機能的に間違っている、または存在しない API を使用する、もっともらしいコードを作成する可能性があります。
❓**バージョンの曖昧さ:**一般的な回答では、プロジェクト内の特定のバージョンの依存関係が考慮されることがほとんどなく、微妙なバグが発生します。
⏳**検証のオーバーヘッド:**開発者は AI の提案を公式ドキュメントと照らし合わせて二重チェックするのに貴重な時間を費やします。
Docs MCP Server は、次の方法でこれらの問題に正面から取り組みます。
✅常に最新のコンテキストを提供: オンデマンドで公式ソース (Web サイト、GitHub、npm、PyPI、ローカル ファイル) から直接ドキュメントを取得してインデックスを作成します。
🎯**バージョン固有の回答を提供:**検索クエリは正確なライブラリ バージョンをターゲットにできるため、情報がプロジェクトの依存関係と一致することが保証されます。
💡幻覚の軽減: LLM を実際のドキュメントに基づいて構築することで、正確な例と統合の詳細が提供されます。
⚡生産性の向上: AI アシスタントのワークフローに直接統合され、信頼できる回答をより早く得ることができます。
Related MCP server: mcp-hn
✨ 主な特徴
**最新の知識:**最新のドキュメントをソースから直接取得します。
**バージョン認識検索:**特定のライブラリ バージョン (例:
react@18.2.0とreact@17.0.0) に関連する回答を取得します。**正確なスニペット:**公式ドキュメントのコンテキストを使用して AI の幻覚を軽減します。
**Web インターフェイス:**ドキュメントの検索と管理に使いやすい Web インターフェイスを提供します。
幅広いソース互換性: Web サイト、GitHub リポジトリ、パッケージ マネージャー サイト (npm、PyPI)、さらにはローカル ファイル ディレクトリをスクレイピングします。
**インテリジェント処理:**ドキュメントを意味的に自動的にチャンク化し、埋め込みを生成します。
柔軟な埋め込みモデル: OpenAI (Ollama などの互換性のある API を含む)、Google Gemini/Vertex AI、Azure OpenAI、AWS Bedrock などをサポートします。
**強力なハイブリッド検索:**ベクトル類似性と全文検索を組み合わせて関連性を調べます。
**ローカル & プライベート:**完全にマシン上で実行され、データとクエリは非公開のままになります。
**無料かつオープンソース:**コミュニティによって、コミュニティのために構築されました。
シンプルなデプロイメント: Docker または
npx経由で簡単にセットアップできます。シームレスな統合: MCP 互換クライアント (Claude、Cline、Roo など) と連携します。
Docs MCP サーバーの実行方法
すぐに起動して実行できます。最も簡単なセットアップと管理のために、Docker Desktop (Docker Compose) の使用をお勧めします。
推奨: Docker デスクトップ
この方法は、Docker Composeを使用してサーバーとWebインターフェースを実行することで、永続的なローカルセットアップを実現します。リポジトリのクローン作成は必要ですが、両方のサービスの管理が簡素化されます。
Docker と Docker Compose がインストールされ、実行されていることを確認します。
リポジトリをクローンします。
git clone https://github.com/arabold/docs-mcp-server.git cd docs-mcp-server**環境を設定します。**サンプル環境ファイルをコピーし、編集して OpenAI API キー (必須) を追加します。
cp .env.example .env # Edit the .env file and set your OpenAI API key:例
.env:OPENAI_API_KEY=your-api-key-here追加の構成オプション (他のプロバイダー、詳細設定など) については、 「構成」セクションを参照してください。
**サービスを起動します。**リポジトリのルートディレクトリからこのコマンドを実行します。これにより、(必要に応じて)イメージがビルドされ、サーバーとWebインターフェースがバックグラウンドで起動します。
docker compose up -d-d: コンテナをデタッチモード(バックグラウンド)で実行します。ログをターミナルで直接確認するには、これを省略してください。
**注意:**リポジトリの更新をプルする場合 (例:
git pullを使用)、docker compose up -d --buildを実行して Docker イメージを再構築し、変更を含める必要があります。**MCP クライアントを構成します。**次の構成ブロックを MCP 設定ファイルに追加します (例: Claude、Cline、Roo の場合)。
{ "mcpServers": { "docs-mcp-server": { "url": "http://localhost:6280/sse", // Connects via HTTP to the Docker Compose service "disabled": false, "autoApprove": [] } } }設定を更新した後、AI アシスタント アプリケーションを再起動します。
注:Docker Compose セットアップでは、Docs MCP サーバーはスタンドアロンの接続可能なインスタンスとして設計されているため、HTTP モード(SSE 経由)で実行されます。stdio 通信はサポートされていません。
Web インターフェイスにアクセスします。Webインターフェイスは
http://localhost:6281で利用できます。
この方法の利点:
1 つのコマンドでサーバーと Web UI の両方を実行します。
ローカル ソース コードを使用します (コードが変更され、
docker compose up --buildを実行すると、自動的に再構築されます)。docs-mcp-dataDocker ボリュームを介した永続的なデータ ストレージ。.envファイルによる簡単な構成管理。
サービスを停止するには、リポジトリ ディレクトリからdocker compose downを実行します。
ライブラリドキュメントの追加
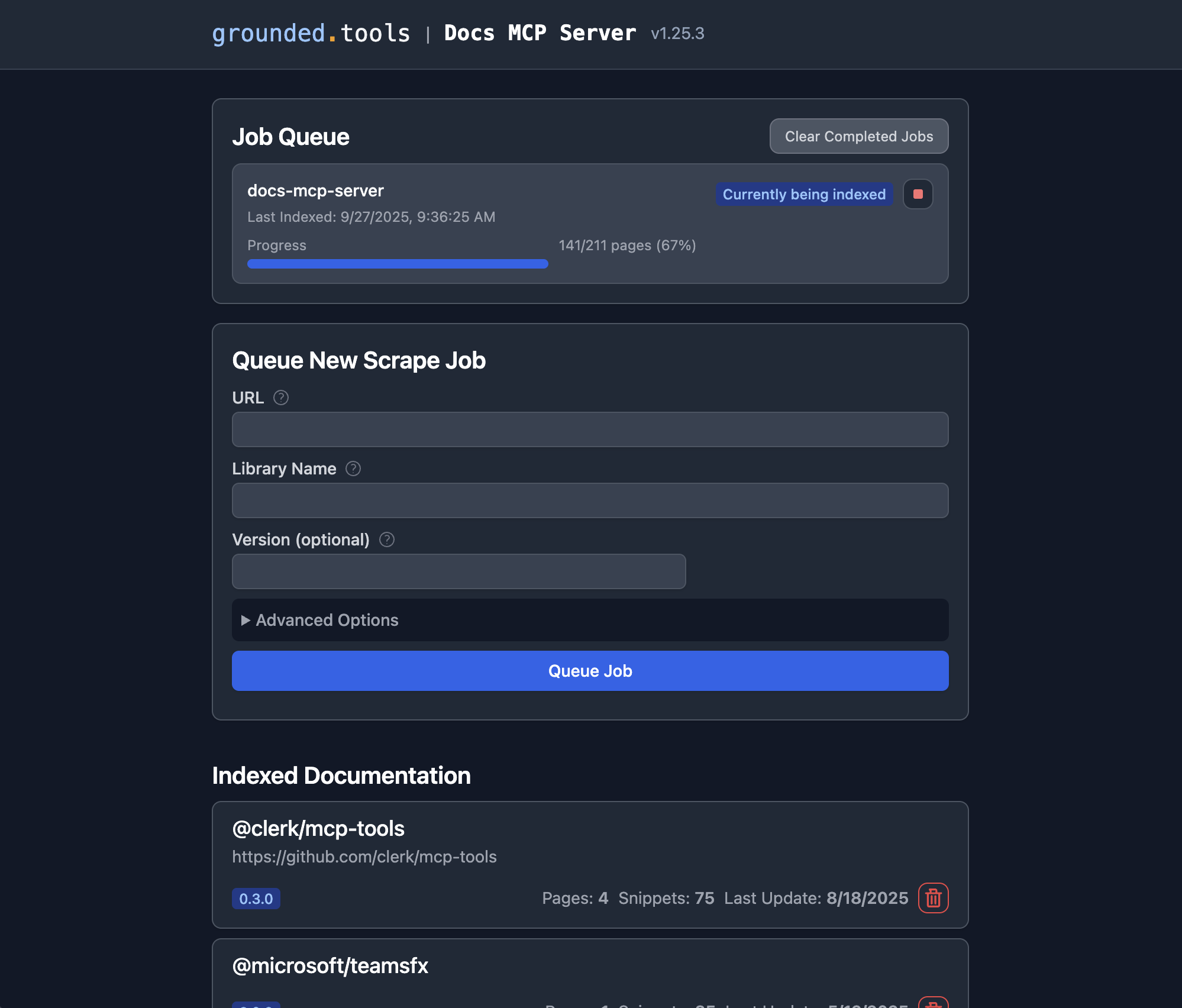
Docs MCP サーバーが実行される場合は、Web インターフェイスを使用して、インデックスを作成する新しいドキュメントを追加したり、既存のドキュメントを検索したりすることができます。
**Web インターフェイスを開きます。**推奨される Docker Compose セットアップを使用した場合は、ブラウザで
http://localhost:6281に移動します。**「新しいスクレイプ ジョブをキューに追加」フォームを見つけます。**これは通常、メイン ページに目立つように表示されます。
詳細を入力してください:
**URL:**インデックスを作成するドキュメントの開始 URL を指定します (例:
https://react.dev/reference/react、https://github.com/expressjs/express、https://docs.python.org/3/)。**ライブラリ名:**短くて覚えやすい名前を付けます(例:
react、express、python)。検索時にこの名前で参照されます。**バージョン(オプション):**特定のバージョンをインデックスに登録したい場合は、ここに入力してください(例:
18.2.0)。空白3.11ままにすると、サーバーは最新バージョン4.17.1検出しようとするか、バージョンなしとしてインデックスに登録します。**(オプション)詳細設定:**必要に応じて、
Scope(例:「サブページ」、「ホスト名」、「ドメイン」)、Max Pages、Max Depth、Follow Redirects調整します。通常はデフォルトで十分です。
**「ジョブをキューに追加」をクリックすると、**サーバーはドキュメントの取得、処理、インデックス作成を行うバックグラウンドジョブを開始します。Web UIの「ジョブキュー」セクションで進行状況を確認できます。
**繰り返し:**サーバーでドキュメントを管理するライブラリごとに手順 3 ~ 4 を繰り返します。
**これで完了です。**ジョブが正常に完了すると、そのライブラリとバージョンのドキュメントが、接続されている AI コーディング アシスタント ( search_docsツールを使用) を通じて検索できるようになるか、Web UI で「インデックス付きドキュメント」セクションのライブラリ名をクリックして直接検索できるようになります。
代替案: Dockerを使用する
このアプローチは簡単でわかりやすく、リポジトリのクローンを作成する必要がありません。
Docker がインストールされ、実行されていることを確認します。
MCP 設定を構成します。
**Claude/Cline/Roo 構成例:**次の構成ブロックを MCP 設定ファイルに追加します (必要に応じてパスを調整します)。
{ "mcpServers": { "docs-mcp-server": { "command": "docker", "args": [ "run", "-i", "--rm", "-e", "OPENAI_API_KEY", "-v", "docs-mcp-data:/data", "ghcr.io/arabold/docs-mcp-server:latest" ], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }"sk-proj-..."実際の OpenAI API キーに置き換えて、アプリケーションを再起動してください。**これで完了です。**これで AI アシスタントがサーバーを利用できるようになります。
Dockerコンテナの設定:
-i: STDIN を開いたままにします。これは、stdio 経由の MCP 通信に重要です。--rm: コンテナの終了時に自動的に削除します。-e OPENAI_API_KEY:必須。OpenAI APIキーを設定します。-v docs-mcp-data:/data:**永続化に必須です。**データベースを保存するためにdocs-mcp-dataという名前のDockerボリュームをマウントします。必要に応じて、特定のホストパスに置き換えることもできます(例:-v /path/on/host:/data)。
設定環境変数(上記の「設定」を参照)は、 -eフラグを使用してコンテナに渡すことができます。例:
Webインターフェースの起動
http://localhost:6281で Web ベースの GUI にアクセスし、ブラウザ経由でライブラリ ドキュメントを管理および検索できます。
Docker を使用してサーバーを実行している場合は、Web インターフェースにも Docker を使用します。
必ず次の点に注意してください:
サーバーと同じボリューム名(この例では
docs-mcp-data)を使用します。-p 6281:6281でポート 6281 をマップします-eフラグを使用して、任意の設定環境変数を渡します。
CLIの使用
CLI を使用して、イメージ名の後に CLI コマンドを渡すことで、Docker 経由で直接ドキュメントを管理できます。
例:
MCPサーバーコンテナとデータを共有する場合は、必ず同じボリューム名(この例ではdocs-mcp-data )を使用してください。設定環境変数(上記の「設定」を参照)は、 -eフラグを使用して渡すことができます。
利用できる主なコマンドは次のとおりです。
scrape: URL からドキュメントをスクレイピングしてインデックスを作成します。search: インデックス化されたドキュメントを検索します。list: インデックスが付けられたすべてのライブラリを一覧表示します。remove: インデックス付けされたドキュメントを削除します。fetch-url: 単一の URL を取得して Markdown に変換します。find-version: ライブラリに最適なバージョンを検索します。
コマンドの詳細な使用方法については、--help フラグを使用して CLI を実行してください (例: docker run ... ghcr.io/arabold/docs-mcp-server:latest --help )。
代替案: npx を使用する
このアプローチは、ローカルファイルへのアクセスが必要な場合(例:ローカルファイルシステムからドキュメントのインデックス作成)に便利です。これはDockerコンテナにパスをマウントすることでも実現できますが、 npxを使用する方が簡単ですが、Node.jsのインストールが必要です。
Node.js がインストールされていることを確認します。
MCP 設定を構成します。
**Claude/Cline/Roo 構成例:**次の構成ブロックを MCP 設定ファイルに追加します。
{ "mcpServers": { "docs-mcp-server": { "command": "npx", "args": ["-y", "@arabold/docs-mcp-server"], // This will run the default MCP server (stdio). // To run in HTTP mode, add arguments: e.g. // "args": ["-y", "@arabold/docs-mcp-server", "--protocol", "http", "--port", "6280"], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }"sk-proj-..."実際の OpenAI API キーに置き換えて、アプリケーションを再起動してください。**これで完了です。**これで AI アシスタントがサーバーを利用できるようになります。
Webインターフェースの起動
npxを使用して MCP サーバーを実行している場合 (上記のように、デフォルトで実行されます)、Web インターフェイスでもnpxを使用します。
--portフラグを使用して、Web インターフェイスに別のポートを指定できます。
npxアプローチでは、システム上のデフォルトのデータ ディレクトリ (通常はホーム ディレクトリ内) が使用され、サーバーと Web インターフェイス間の一貫性が確保されます。
CLIの使用
npxを使用して MCP サーバーを実行している場合は、CLI コマンドにnpxを使用することもできます。
例:
npxアプローチでは、システム上のデフォルトのデータ ディレクトリ (通常はホーム ディレクトリ内) が使用され、一貫性が確保されます。
コマンドの詳細な使用方法については、--help フラグを使用して CLI を実行してください (例: npx -y @arabold/docs-mcp-server --help )。
構成
埋め込みモデルの動作を設定するために、以下.env環境変数がサポートされています。.env ファイルで指定するか、Docker または npx 経由でサーバーを実行する際に-eフラグとして渡してください。
埋め込みモデルの構成
DOCS_MCP_EMBEDDING_MODEL:**オプション。**形式:provider:model_nameまたはmodel_name(デフォルトはtext-embedding-3-small)。サポートされているプロバイダーと必要な環境変数:openai(デフォルトのプロバイダー): OpenAI の埋め込みモデルを使用します。OPENAI_API_KEY: OpenAI APIキー。openaiopenaiOPENAI_ORG_ID:オプション。OpenAI組織IDOPENAI_API_BASE:オプション。OpenAI互換API(例:Ollama)のカスタムベースURL。
vertex: Google Cloud Vertex AI 埋め込みを使用しますGOOGLE_APPLICATION_CREDENTIALS:**必須。**サービスアカウントのJSONキーファイルへのパス
gemini: Google Generative AI (Gemini) の埋め込みを使用しますGOOGLE_API_KEY:必須。Google APIキー
aws: AWS Bedrock 埋め込みを使用しますAWS_ACCESS_KEY_ID:必須。AWSアクセスキーAWS_SECRET_ACCESS_KEY:必須。AWSシークレットキーAWS_REGIONまたはBEDROCK_AWS_REGION:必須。Bedrockの AWS リージョン
microsoft: Azure OpenAI 埋め込みを使用AZURE_OPENAI_API_KEY:必須。Azure OpenAI APIキーAZURE_OPENAI_API_INSTANCE_NAME:必須。Azureインスタンス名AZURE_OPENAI_API_DEPLOYMENT_NAME:必須。Azureデプロイメント名AZURE_OPENAI_API_VERSION:必須。Azure APIバージョン
ベクトル次元
データベーススキーマは、ベクトルの埋め込みに1536次元という固定次元を使用します。次元削減をサポートする特定のプロバイダ(Geminiなど)を除き、1536次元以下のベクトルを生成するモデルのみがサポートされます。
OpenAI 互換 API (Ollama など) の場合は、エンドポイントを指すOPENAI_API_BASEを持つopenaiプロバイダーを使用します。
発達
このセクションでは、開発目的でソースコードから直接サーバー/CLIを実行する方法について説明します。主な使用方法は、「代替手段:Dockerの使用」セクションで説明されているように、パブリックDockerイメージ( ghcr.io/arabold/docs-mcp-server:latest )を使用するか、「推奨:Docker Desktop」セクションで説明されているように、Docker Composeを使用することです。
ソースから実行
注: Playwrightブラウザは
npm installでは自動的にインストールされません。Playwrightを必要とするテストや機能を使用する必要がある場合は、以下を実行してください。npx playwright install --no-shell --with-deps chromium
これにより、分離された環境が提供され、HTTP エンドポイントを介してサーバーが公開されます。
この方法は、プロジェクトに貢献したり、未公開バージョンを実行したりする場合に役立ちます。
リポジトリをクローンします。
git clone https://github.com/arabold/docs-mcp-server.git # Replace with actual URL if different cd docs-mcp-server依存関係をインストールします:
npm install**プロジェクトをビルドします。**これにより、TypeScript が
dist/ディレクトリ内の JavaScript にコンパイルされます。npm run build環境設定:設定セクションの説明に従って、
.envファイルを作成して設定します。これはOPENAI_API_KEY提供するために不可欠です。走る:
デフォルトの MCP サーバー (開発):
stdioモード(デフォルト):
npm run dev:serverHTTP モード:
npm run dev:server:http(デフォルトのポートを使用)カスタム HTTP:
vite-node src/index.ts -- --protocol http --port <your_port>
Webインターフェース(開発):
npm run dev:webこれにより、Web サーバー (たとえば、ポート 6281) が起動し、アセットの変更が監視されます。
CLI コマンド (開発):
npm run dev:cli -- <command> [options]例:
npm run dev:cli -- list例:
vite-node src/index.ts scrape <library> <url>
プロダクションモード (
デフォルトの MCP サーバー (stdio):
npm run start(またはnode dist/index.js)MCP サーバー (HTTP):
npm run start -- --protocol http --port <your_port>(またはnode dist/index.js --protocol http --port <your_port>)Web インターフェース:
npm run web -- --port <web_port>(またはnode dist/index.js web --port <web_port>)CLI コマンド:
npm run cli -- <command> [options](またはnode dist/index.js <command> [options])
テスト
MCPサーバーはNode.js(またはvite-node )経由で直接実行する場合、stdio経由で通信するため、デバッグが困難になる可能性があります。MCP Inspectorの使用をお勧めします。
プロジェクトをビルドした後 ( npm run build ):
開発にvite-nodeを使用する場合:
インスペクターは、ブラウザでデバッグ ツールにアクセスするための URL を提供します。
建築
プロジェクトのアーキテクチャと設計原則の詳細については、 ARCHITECTURE.md を参照してください。
注目すべきは、このプロジェクトのコードの大部分が、まさにこの MCP サーバーの機能を活用して、AI アシスタント Cline によって生成されたことです。