
Docs MCP 服务器:您的 AI 最新文档专家
AI 编程助手经常会遇到文档过时的问题,导致给出错误的建议或代码示例不准确。根据特定库版本验证 AI 的响应可能既耗时又低效。
Docs MCP 服务器可以为您的 AI 助手提供个性化、始终更新的知识库,从而解决此问题。它的主要目的是索引第三方文档——即您在代码库中实际使用的库。它会抓取网站、GitHub 代码库、包管理器(npm、PyPI)甚至本地文件,并在本地对文档进行编目。然后,它通过模型上下文协议 (MCP) 为您的编码代理提供强大的搜索工具。
这使您的 LLM 代理能够访问您添加的任何库的最新官方文档,从而显著提高生成的代码和集成细节的质量和可靠性。
通过将 AI 响应置于准确、版本感知的环境中,Docs MCP Server 使您能够接收简洁、相关的集成详细信息和代码片段,从而提高 LLM 辅助开发的可靠性和效率。
它是免费的、开源的、在本地运行以保护隐私,并无缝集成到您的开发工作流程中。
为什么要使用 Docs MCP 服务器?
LLM 辅助编码保证了速度和效率,但往往达不到要求,原因如下:
🌀陈旧的知识: LLM 在互联网快照上进行训练,很快就落后于新库的发布和 API 的变化。
👻**代码幻觉:**人工智能可以发明看似合理的代码,该代码在语法上正确,但功能上是错误的,或者使用不存在的 API。
❓**版本模糊性:**通用答案很少考虑项目中的特定版本依赖关系,从而导致细微的错误。
⏳**验证开销:**开发人员花费宝贵的时间根据官方文档仔细检查 AI 建议。
Docs MCP 服务器通过以下方式正面解决这些问题:
✅**提供始终最新的上下文:**它根据需要直接从官方来源(网站、GitHub、npm、PyPI、本地文件)获取和索引文档。
🎯**提供特定版本的答案:**搜索查询可以针对精确的库版本,确保信息与项目的依赖项一致。
💡**减少幻觉:**通过将 LLM 置于真实文档中,它提供了准确的示例和集成细节。
⚡**提高生产力:**更快地获得可信赖的答案,直接集成到您的 AI 助手工作流程中。
Related MCP server: mcp-hn
✨ 主要特点
**最新知识:**直接从源获取最新文档。
**版本感知搜索:**获取与特定库版本相关的答案(例如,
react@18.2.0与react@17.0.0)。**准确的片段:**通过使用官方文档中的上下文来减少 AI 幻觉。
**Web 界面:**提供易于使用的 Web 界面来搜索和管理文档。
**广泛的源兼容性:**抓取网站、GitHub 存储库、包管理器站点(npm、PyPI)甚至本地文件目录。
**智能处理:**自动对文档进行语义分块并生成嵌入。
**灵活的嵌入模型:**支持 OpenAI(包括兼容 API,如 Ollama)、Google Gemini/Vertex AI、Azure OpenAI、AWS Bedrock 等。
**强大的混合搜索:**将向量相似度与全文搜索相结合以获得相关性。
**本地和私人:**完全在您的机器上运行,确保您的数据和查询保持私密。
**免费且开源:**由社区构建,为社区服务。
**简单部署:**通过 Docker 或
npx轻松设置。**无缝集成:**与 MCP 兼容客户端(如 Claude、Cline、Roo)配合使用。
如何运行 Docs MCP 服务器
快速启动并运行!我们推荐使用 Docker Desktop (Docker Compose),以实现最便捷的设置和管理。
推荐:Docker Desktop
此方法通过使用 Docker Compose 运行服务器和 Web 界面来提供持久的本地设置。它需要克隆存储库,但简化了两个服务的同时管理。
确保 Docker 和 Docker Compose 已安装并正在运行。
克隆存储库:
git clone https://github.com/arabold/docs-mcp-server.git cd docs-mcp-server**设置您的环境:**复制示例环境文件并编辑它以添加您的 OpenAI API 密钥(必需):
cp .env.example .env # Edit the .env file and set your OpenAI API key:示例
.env:OPENAI_API_KEY=your-api-key-here有关其他配置选项(例如其他提供程序、高级设置),请参阅配置部分。
**启动服务:**从仓库的根目录运行此命令。它将构建镜像(如有必要)并在后台启动服务器和 Web 界面。
docker compose up -d-d:以分离模式(后台)运行容器。忽略此项可直接在终端中查看日志。
**注意:**如果您拉取存储库的更新(例如,使用
git pull),则需要通过运行docker compose up -d --build来重建 Docker 镜像以包含更改。**配置您的 MCP 客户端:**将以下配置块添加到您的 MCP 设置文件(例如,对于 Claude、Cline、Roo):
{ "mcpServers": { "docs-mcp-server": { "url": "http://localhost:6280/sse", // Connects via HTTP to the Docker Compose service "disabled": false, "autoApprove": [] } } }更新配置后重新启动您的 AI 助手应用程序。
注意:Docker Compose 设置会以 HTTP 模式(通过 SSE)运行 Docs MCP Server,因为它旨在用作独立的可连接实例。它不支持 stdio 通信。
访问 Web 界面: Web 界面将在
http://localhost:6281上可用。
此方法的好处:
使用单个命令运行服务器和 Web UI。
使用本地源代码(如果代码发生变化并且运行
docker compose up --build自动重建)。通过
docs-mcp-dataDocker 卷进行持久数据存储。通过
.env文件轻松进行配置管理。
要停止服务,请从存储库目录运行docker compose down 。
添加库文档
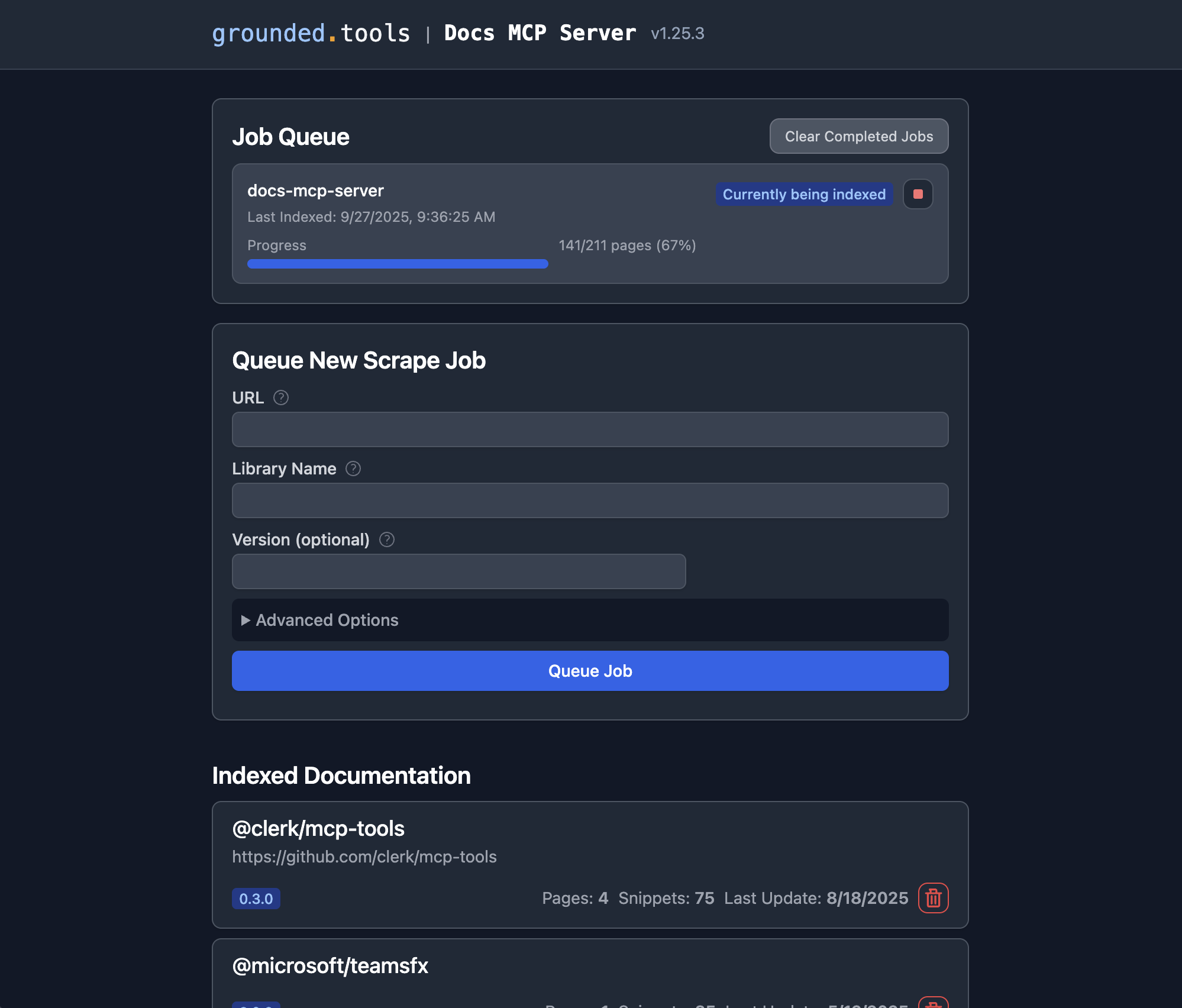
一旦 Docs MCP 服务器运行,您就可以使用 Web 界面添加要索引的新文档或搜索现有文档。
**打开 Web 界面:**如果您使用了推荐的 Docker Compose 设置,请将浏览器导航至
http://localhost:6281。**找到“排队新的抓取作业”表单:**这通常在主页上突出显示。
输入详细信息:
**URL:**提供要索引的文档的起始 URL(例如,
https://react.dev/reference/react:https://github.com/expressjs/express``https://docs.python.org/3/)。**库名称:**给它起一个简短易记的名称(例如,
react、express、python)。这样你在搜索时就可以引用它了。**版本 (可选):**如果您要索引特定版本,请在此处输入 (例如,
18.2.0、4.17.1、3.11)。如果留空,服务器通常会尝试检测最新版本,或将其索引为未版本化版本。**(可选)高级设置:**调整
Scope(例如“子页面”、“主机名”、“域名”)、Max Pages、Max Depth以及Follow Redirects如有需要)。默认值通常已足够。
**点击“队列作业”:**服务器将启动后台作业来获取、处理和索引文档。您可以在 Web UI 的“作业队列”部分监控其进度。
**重复:**对您希望服务器管理其文档的每个库重复步骤 3-4。
**就是这样!**作业成功完成后,您可以通过连接的 AI 编码助手(使用search_docs工具)搜索该库和版本的文档,或者直接在 Web UI 中点击“索引文档”部分中的库名称进行搜索。
替代方案:使用 Docker
这种方法简单、直接,并且不需要克隆存储库。
确保 Docker 已安装并正在运行。
配置您的 MCP 设置:
**Claude/Cline/Roo 配置示例:**将以下配置块添加到您的 MCP 设置文件(根据需要调整路径):
{ "mcpServers": { "docs-mcp-server": { "command": "docker", "args": [ "run", "-i", "--rm", "-e", "OPENAI_API_KEY", "-v", "docs-mcp-data:/data", "ghcr.io/arabold/docs-mcp-server:latest" ], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }请记住用您的实际 OpenAI API 密钥替换
"sk-proj-..."并重新启动应用程序。**就这样!**现在你的AI助手就可以使用服务器了。
Docker容器设置:
-i:保持 STDIN 开放,这对于通过 stdio 进行 MCP 通信至关重要。--rm:容器退出时自动删除。-e OPENAI_API_KEY:**必需。**设置您的 OpenAI API 密钥。-v docs-mcp-data:/data:**持久化必需。**挂载一个名为docs-mcp-data的 Docker 卷来存储数据库。您可以根据需要将其替换为特定的主机路径(例如,-v /path/on/host:/data)。
任何配置环境变量(参见上文的配置)都可以使用-e标志传递给容器。例如:
启动Web界面
您可以通过浏览器访问基于 Web 的 GUI http://localhost:6281来管理和搜索库文档。
如果您使用 Docker 运行服务器,那么也可以使用 Docker 作为 Web 界面:
请确保:
使用与服务器相同的卷名(本例中为
docs-mcp-data)使用
-p 6281:6281使用
-e标志传递任何配置环境变量
使用 CLI
您可以使用 CLI 通过在镜像名称后传递 CLI 命令来直接通过 Docker 管理文档:
例子:
如果您希望 MCP 服务器容器与 MCP 服务器容器共享数据,请确保使用相同的卷名(本例中为docs-mcp-data )。任何配置环境变量(请参阅上文的配置)都可以使用-e参数传递。
可用的主要命令有:
scrape:从 URL 中抓取并索引文档。search:搜索索引文档。list:列出所有索引库。remove:删除索引文档。fetch-url:获取单个 URL 并转换为 Markdown。find-version:查找库的最佳匹配版本。
有关详细的命令用法,请使用 --help 标志运行 CLI(例如, docker run ... ghcr.io/arabold/docs-mcp-server:latest --help )。
替代方案:使用 npx
当您需要本地文件访问(例如,从本地文件系统索引文档)时,此方法非常有用。虽然也可以通过将路径挂载到 Docker 容器中来实现,但使用npx更简单,但需要安装 Node.js。
确保已安装 Node.js。
配置您的 MCP 设置:
**Claude/Cline/Roo 配置示例:**将以下配置块添加到您的 MCP 设置文件:
{ "mcpServers": { "docs-mcp-server": { "command": "npx", "args": ["-y", "@arabold/docs-mcp-server"], // This will run the default MCP server (stdio). // To run in HTTP mode, add arguments: e.g. // "args": ["-y", "@arabold/docs-mcp-server", "--protocol", "http", "--port", "6280"], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }请记住用您的实际 OpenAI API 密钥替换
"sk-proj-..."并重新启动应用程序。**就这样!**现在你的AI助手就可以使用服务器了。
启动Web界面
如果您使用npx运行 MCP 服务器(如上所示,它默认运行),也请使用npx作为 Web 界面:
您可以使用--port标志为 Web 界面指定不同的端口。
npx方法将使用系统上的默认数据目录(通常在您的主目录中),确保服务器和 Web 界面之间的一致性。
使用 CLI
如果您使用npx运行 MCP 服务器,那么您也可以使用npx执行 CLI 命令:
例子:
npx方法将使用系统上的默认数据目录(通常在您的主目录中),以确保一致性。
有关详细的命令用法,请使用 --help 标志运行 CLI(例如, npx -y @arabold/docs-mcp-server --help )。
配置
支持使用以下环境变量来配置嵌入模型的行为。您可以在.env文件中指定它们,或者在通过 Docker 或 npx 运行服务器时将它们作为-e标志传递。
嵌入模型配置
DOCS_MCP_EMBEDDING_MODEL:**可选。**格式:provider:model_name或直接为model_name(默认为text-embedding-3-small)。支持的提供程序及其所需的环境变量:openai(默认提供商):使用 OpenAI 的嵌入模型。OPENAI_API_KEY:您的 OpenAI API 密钥。如果OPENAI_ORG_ID:**可选。**您的 OpenAI 组织 IDOPENAI_API_BASE:**可选。**与 OpenAI 兼容的 API(例如 Ollama)的自定义基本 URL。
vertex:使用 Google Cloud Vertex AI 嵌入GOOGLE_APPLICATION_CREDENTIALS:**必需。**服务帐户 JSON 密钥文件的路径
gemini:使用 Google Generative AI(Gemini)嵌入GOOGLE_API_KEY:**必填。**您的 Google API 密钥
aws:使用 AWS Bedrock 嵌入AWS_ACCESS_KEY_ID:必需。AWS访问密钥AWS_SECRET_ACCESS_KEY:必需。AWS密钥AWS_REGION或BEDROCK_AWS_REGION:必填。Bedrock的 AWS 区域
microsoft:使用 Azure OpenAI 嵌入AZURE_OPENAI_API_KEY:必需。Azure OpenAI API 密钥AZURE_OPENAI_API_INSTANCE_NAME:必需。Azure实例名称AZURE_OPENAI_API_DEPLOYMENT_NAME:必需。Azure部署名称AZURE_OPENAI_API_VERSION:必需。Azure API 版本
向量维度
数据库架构使用固定维度 1536 来嵌入向量。仅支持生成维度 ≤ 1536 的向量的模型,但某些支持降维的提供商(例如 Gemini)除外。
对于与 OpenAI 兼容的 API(如 Ollama),请使用指向您的端点的OPENAI_API_BASE的openai提供程序。
发展
本节介绍如何从源代码直接运行服务器/CLI 以进行开发。主要使用方法是通过公共 Docker 镜像 ( ghcr.io/arabold/docs-mcp-server:latest ),详见“替代方案:使用 Docker”部分;或者通过 Docker Compose,详见“推荐方案:Docker Desktop”部分。
从源运行
注意:
npm install期间不会自动安装 Playwright 浏览器。如果您需要运行测试或使用需要 Playwright 的功能,请运行:npx playwright install --no-shell --with-deps chromium
这提供了一个隔离的环境并通过 HTTP 端点公开服务器。
此方法对于为项目做出贡献或运行未发布的版本很有用。
克隆存储库:
git clone https://github.com/arabold/docs-mcp-server.git # Replace with actual URL if different cd docs-mcp-server安装依赖项:
npm install**构建项目:**这会将
dist/目录中的 TypeScript 编译为 JavaScript。npm run build**设置环境:**按照配置部分所述创建并配置
.env文件。这对于提供OPENAI_API_KEY至关重要。跑步:
默认 MCP 服务器(开发中):
Stdio 模式(默认):
npm run dev:serverHTTP 模式:
npm run dev:server:http(使用默认端口)自定义 HTTP:
vite-node src/index.ts -- --protocol http --port <your_port>
Web 界面(开发):
npm run dev:web这将启动 Web 服务器(例如,在端口 6281 上)并监视资产变化。
CLI 命令(开发):
npm run dev:cli -- <command> [options]例如:
npm run dev:cli -- list例如:
vite-node src/index.ts scrape <library> <url>
生产模式(
默认 MCP 服务器 (stdio):
npm run start(或node dist/index.js)MCP 服务器 (HTTP):
npm run start -- --protocol http --port <your_port>(或者node dist/index.js --protocol http --port <your_port>)Web 界面:
npm run web -- --port <web_port>(或node dist/index.js web --port <web_port>)CLI 命令:
npm run cli -- <command> [options](或node dist/index.js <command> [options])
测试
由于 MCP 服务器通过 Node.js (或vite-node ) 直接运行时通过 stdio 进行通信,因此调试起来可能比较困难。我们建议使用MCP Inspector 。
构建项目后( npm run build ):
如果使用vite-node进行开发:
检查器将提供一个 URL 来访问浏览器中的调试工具。
建筑学
有关该项目的架构和设计原则的详细信息,请参阅ARCHITECTURE.md 。
值得注意的是,该项目的绝大部分代码都是由人工智能助手 Cline 生成的,利用了这个 MCP 服务器的功能。