
Docs MCP Server: Der aktuelle Dokumentationsexperte Ihrer KI
KI-Codierungsassistenten kämpfen oft mit veralteter Dokumentation, was zu falschen Vorschlägen oder irreführenden Codebeispielen führt. Die Überprüfung der KI-Antworten anhand bestimmter Bibliotheksversionen kann zeitaufwändig und ineffizient sein.
Der Docs MCP Server löst dieses Problem, indem er als persönliche, stets aktuelle Wissensdatenbank für Ihren KI-Assistenten fungiert. Sein Hauptzweck ist die Indexierung von Drittanbieterdokumentationen – den Bibliotheken, die Sie tatsächlich in Ihrer Codebasis verwenden. Er durchsucht Websites, GitHub-Repositories, Paketmanager (npm, PyPI) und sogar lokale Dateien und katalogisiert die Dokumente lokal. Anschließend stellt er Ihrem Code-Agenten leistungsstarke Suchwerkzeuge über das Model Context Protocol (MCP) zur Verfügung.
Dadurch kann Ihr LLM-Agent auf die neueste offizielle Dokumentation für jede von Ihnen hinzugefügte Bibliothek zugreifen, wodurch die Qualität und Zuverlässigkeit des generierten Codes und der Integrationsdetails erheblich verbessert wird.
Indem KI-Antworten in einem präzisen, versionsbewussten Kontext verankert werden, ermöglicht Ihnen der Docs MCP Server, präzise und relevante Integrationsdetails und Codeausschnitte zu erhalten und so die Zuverlässigkeit und Effizienz der LLM-gestützten Entwicklung zu verbessern.
Es ist kostenlos , Open Source , wird aus Datenschutzgründen lokal ausgeführt und lässt sich nahtlos in Ihren Entwicklungsworkflow integrieren.
Warum den Docs MCP-Server verwenden?
LLM-gestütztes Codieren verspricht Geschwindigkeit und Effizienz, bleibt jedoch oft aus folgenden Gründen hinter den Erwartungen zurück:
🌀 Veraltetes Wissen: LLMs trainieren anhand von Schnappschüssen des Internets und bleiben schnell hinter neuen Bibliotheksversionen und API-Änderungen zurück.
👻 Code-Halluzinationen: KI kann plausibel aussehenden Code erfinden, der syntaktisch korrekt, aber funktional falsch ist oder nicht vorhandene APIs verwendet.
❓ Versionsmehrdeutigkeit: Allgemeine Antworten berücksichtigen selten die spezifischen Versionsabhängigkeiten in Ihrem Projekt, was zu subtilen Fehlern führt.
⏳ Überprüfungsaufwand: Entwickler verbringen wertvolle Zeit damit, KI-Vorschläge anhand der offiziellen Dokumentation zu überprüfen.
Der Docs MCP Server geht diese Probleme direkt an, indem er:
✅ Bereitstellung eines stets aktuellen Kontexts: Es ruft Dokumentationen bei Bedarf direkt aus offiziellen Quellen (Websites, GitHub, npm, PyPI, lokale Dateien) ab und indiziert sie.
🎯 Bereitstellung versionsspezifischer Antworten: Suchanfragen können auf genaue Bibliotheksversionen abzielen, um sicherzustellen, dass die Informationen mit den Abhängigkeiten Ihres Projekts übereinstimmen.
💡 Reduzierung von Halluzinationen: Durch die Verankerung des LLM in echter Dokumentation werden genaue Beispiele und Integrationsdetails bereitgestellt.
⚡ Produktivitätssteigerung: Erhalten Sie schneller vertrauenswürdige Antworten, direkt integriert in Ihren KI-Assistenten-Workflow.
Related MCP server: mcp-hn
✨ Hauptmerkmale
Aktuelles Wissen: Ruft die neueste Dokumentation direkt von der Quelle ab.
Versionsbasierte Suche: Erhalten Sie Antworten, die für bestimmte Bibliotheksversionen relevant sind (z. B.
react@18.2.0vs.react@17.0.0).Genaue Snippets: Reduziert KI-Halluzinationen durch Verwendung des Kontexts aus offiziellen Dokumenten.
Webschnittstelle: Bietet eine benutzerfreundliche Webschnittstelle zum Suchen und Verwalten von Dokumentationen.
Breite Quellkompatibilität: Scraped Websites, GitHub-Repos, Paketmanager-Sites (npm, PyPI) und sogar lokale Dateiverzeichnisse.
Intelligente Verarbeitung: Zerlegt die Dokumentation automatisch in semantische Blöcke und generiert Einbettungen.
Flexible Einbettungsmodelle: Unterstützt OpenAI (inkl. kompatibler APIs wie Ollama), Google Gemini/Vertex AI, Azure OpenAI, AWS Bedrock und mehr.
Leistungsstarke Hybridsuche: Kombiniert Vektorähnlichkeit mit Volltextsuche auf Relevanz.
Lokal und privat: Läuft vollständig auf Ihrem Computer und hält Ihre Daten und Abfragen privat.
Kostenlos und Open Source: Von der Community für die Community entwickelt.
Einfache Bereitstellung: Einfache Einrichtung über Docker oder
npx.Nahtlose Integration: Funktioniert mit MCP-kompatiblen Clients (wie Claude, Cline, Roo).
So führen Sie den Docs MCP-Server aus
Schnell einsatzbereit! Wir empfehlen die Verwendung von Docker Desktop (Docker Compose) für eine einfache Einrichtung und Verwaltung.
Empfohlen: Docker Desktop
Diese Methode ermöglicht eine dauerhafte lokale Konfiguration, indem Server und Weboberfläche mit Docker Compose ausgeführt werden. Das Repository muss geklont werden, die gemeinsame Verwaltung beider Dienste wird jedoch vereinfacht.
Stellen Sie sicher, dass Docker und Docker Compose installiert und ausgeführt werden.
Klonen Sie das Repository:
git clone https://github.com/arabold/docs-mcp-server.git cd docs-mcp-serverRichten Sie Ihre Umgebung ein: Kopieren Sie die Beispielumgebungsdatei und bearbeiten Sie sie, um Ihren OpenAI-API-Schlüssel hinzuzufügen (erforderlich):
cp .env.example .env # Edit the .env file and set your OpenAI API key:Beispiel
.env:OPENAI_API_KEY=your-api-key-hereWeitere Konfigurationsmöglichkeiten (z. B. andere Anbieter, erweiterte Einstellungen) finden Sie im Abschnitt „Konfiguration“ .
Dienste starten: Führen Sie diesen Befehl aus dem Stammverzeichnis des Repositorys aus. Er erstellt die Images (falls erforderlich) und startet den Server und die Weboberfläche im Hintergrund.
docker compose up -d-d: Führt die Container im getrennten Modus (im Hintergrund) aus. Lassen Sie diese Option weg, um die Protokolle direkt in Ihrem Terminal anzuzeigen.
Hinweis: Wenn Sie Aktualisierungen für das Repository abrufen (z. B. mithilfe von
git pull“), müssen Sie die Docker-Images neu erstellen, um die Änderungen einzuschließen, indem Siedocker compose up -d --buildausführen.Konfigurieren Sie Ihren MCP-Client: Fügen Sie Ihrer MCP-Einstellungsdatei den folgenden Konfigurationsblock hinzu (z. B. für Claude, Cline, Roo):
{ "mcpServers": { "docs-mcp-server": { "url": "http://localhost:6280/sse", // Connects via HTTP to the Docker Compose service "disabled": false, "autoApprove": [] } } }Starten Sie Ihre KI-Assistentenanwendung nach der Aktualisierung der Konfiguration neu.
Hinweis: Das Docker Compose-Setup führt den Docs MCP-Server standardmäßig im HTTP-Modus (über SSE) aus, da er als eigenständige, verbindbare Instanz konzipiert ist. Standardkommunikation wird nicht unterstützt.
Greifen Sie auf die Weboberfläche zu: Die Weboberfläche ist unter
http://localhost:6281verfügbar.
Vorteile dieser Methode:
Führt sowohl den Server als auch die Web-Benutzeroberfläche mit einem einzigen Befehl aus.
Verwendet den lokalen Quellcode (wird automatisch neu erstellt, wenn sich der Code ändert und Sie
docker compose up --buildausführen).Dauerhafte Datenspeicherung über das Docker-Volume
docs-mcp-data.Einfaches Konfigurationsmanagement über die
.envDatei.
Um die Dienste zu stoppen, führen Sie docker compose down aus dem Repository-Verzeichnis aus.
Hinzufügen von Bibliotheksdokumentation
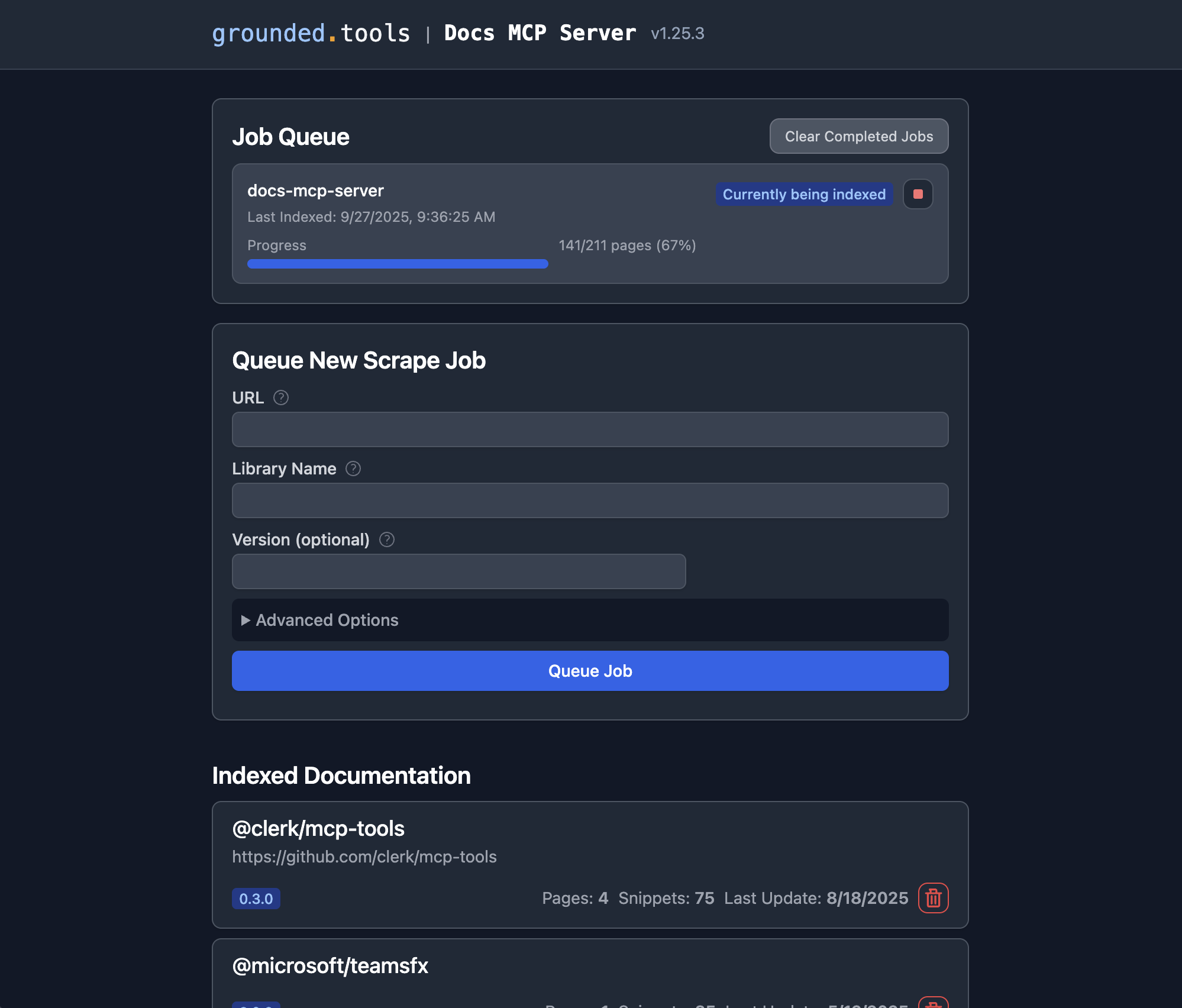
Sobald der Docs MCP-Server läuft, können Sie über die Weboberfläche neue Dokumentationen zum Indexieren hinzufügen oder vorhandene Dokumentationen durchsuchen .
Öffnen Sie die Weboberfläche: Wenn Sie das empfohlene Docker Compose-Setup verwendet haben, navigieren Sie in Ihrem Browser zu
http://localhost:6281.Suchen Sie nach dem Formular „Neuen Scrape-Job in die Warteschlange stellen“: Dieses wird normalerweise gut sichtbar auf der Hauptseite angezeigt.
Geben Sie die Details ein:
URL: Geben Sie die Start-URL für die Dokumentation an, die Sie indizieren möchten (z. B.
https://react.dev/reference/react,https://github.com/expressjs/express,https://docs.python.org/3/).Bibliotheksname: Geben Sie der Bibliothek einen kurzen, einprägsamen Namen (z. B.
react,express,python). So können Sie bei Suchvorgängen darauf verweisen.Version (optional): Wenn Sie eine bestimmte Version indizieren möchten, geben Sie diese hier ein (z. B.
18.2.0,4.17.1,3.11). Wenn dieses Feld leer bleibt, versucht der Server oft, die neueste Version zu ermitteln oder indiziert sie als unversioniert.(Optional) Erweiterte Einstellungen: Passen Sie bei Bedarf
Scope(z. B. „Unterseiten“, „Hostname“, „Domäne“),Max Pages,Max DepthundFollow Redirects. Die Standardeinstellungen sind in der Regel ausreichend.
Klicken Sie auf „Job in die Warteschlange“. Der Server startet einen Hintergrundjob, um die Dokumentation abzurufen, zu verarbeiten und zu indizieren. Sie können den Fortschritt im Bereich „Job-Warteschlange“ der Web-Benutzeroberfläche verfolgen.
Wiederholen: Wiederholen Sie die Schritte 3–4 für jede Bibliothek, deren Dokumentation der Server verwalten soll.
Das war's! Sobald ein Auftrag erfolgreich abgeschlossen ist, steht die Dokumentation für diese Bibliothek und Version zur Suche über Ihren verbundenen KI-Codierungsassistenten (mithilfe des Tools search_docs ) oder direkt in der Web-Benutzeroberfläche zur Verfügung, indem Sie im Abschnitt „Indizierte Dokumentation“ auf den Bibliotheksnamen klicken.
Alternative: Docker verwenden
Dieser Ansatz ist einfach, unkompliziert und erfordert kein Klonen des Repository.
Stellen Sie sicher, dass Docker installiert und ausgeführt wird.
Konfigurieren Sie Ihre MCP-Einstellungen:
Claude/Cline/Roo-Konfigurationsbeispiel: Fügen Sie Ihrer MCP-Einstellungsdatei den folgenden Konfigurationsblock hinzu (passen Sie den Pfad nach Bedarf an):
{ "mcpServers": { "docs-mcp-server": { "command": "docker", "args": [ "run", "-i", "--rm", "-e", "OPENAI_API_KEY", "-v", "docs-mcp-data:/data", "ghcr.io/arabold/docs-mcp-server:latest" ], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }Denken Sie daran
"sk-proj-..."durch Ihren tatsächlichen OpenAI-API-Schlüssel zu ersetzen und die Anwendung neu zu starten.Das war's! Der Server steht jetzt Ihrem KI-Assistenten zur Verfügung.
Docker-Container-Einstellungen:
-i: STDIN offen halten, entscheidend für die MCP-Kommunikation über stdio.--rm: Container beim Beenden automatisch entfernen.-e OPENAI_API_KEY: Erforderlich. Legen Sie Ihren OpenAI-API-Schlüssel fest.-v docs-mcp-data:/data: Erforderlich für die Persistenz. Mountet ein Docker-Volume namensdocs-mcp-datazur Speicherung der Datenbank. Sie können es bei Bedarf durch einen bestimmten Hostpfad ersetzen (z. B.-v /path/on/host:/data“).
Alle Konfigurationsumgebungsvariablen (siehe Konfiguration oben) können mit dem Flag -e an den Container übergeben werden. Beispiel:
Webschnittstelle starten
Sie können unter http://localhost:6281 auf eine webbasierte GUI zugreifen, um die Bibliotheksdokumentation über Ihren Browser zu verwalten und zu durchsuchen.
Wenn Sie den Server mit Docker betreiben, verwenden Sie Docker auch für die Weboberfläche:
Stellen Sie Folgendes sicher:
Verwenden Sie denselben Volumenamen (in diesem Beispiel
docs-mcp-data) wie Ihr ServerMappen Sie Port 6281 mit
-p 6281:6281Übergeben Sie alle Konfigurationsumgebungsvariablen mit dem Flag
-e
Verwenden der CLI
Sie können die CLI verwenden, um die Dokumentation direkt über Docker zu verwalten, indem Sie CLI-Befehle nach dem Image-Namen übergeben:
Beispiel:
Stellen Sie sicher, dass Sie denselben Volumenamen (in diesem Beispiel docs-mcp-data “) wie Ihr MCP-Servercontainer verwenden, wenn Sie Daten gemeinsam nutzen möchten. Alle Konfigurationsumgebungsvariablen (siehe „Konfiguration“ oben) können mit dem Flag -e übergeben werden.
Die wichtigsten verfügbaren Befehle sind:
scrape: Scrapt und indiziert Dokumentation von einer URL.search: Durchsucht die indizierte Dokumentation.list: Listet alle indizierten Bibliotheken auf.remove: Entfernt die indizierte Dokumentation.fetch-url: Ruft eine einzelne URL ab und konvertiert sie in Markdown.find-version: Sucht die am besten passende Version für eine Bibliothek.
Für eine detaillierte Befehlsverwendung führen Sie die CLI mit dem Flag --help aus (z. B. docker run ... ghcr.io/arabold/docs-mcp-server:latest --help ).
Alternative: Verwendung von npx
Dieser Ansatz ist nützlich, wenn Sie lokalen Dateizugriff benötigen (z. B. zum Indizieren von Dokumentationen aus Ihrem lokalen Dateisystem). Dies kann zwar auch durch das Einbinden von Pfaden in einen Docker-Container erreicht werden, die Verwendung von npx ist jedoch einfacher, erfordert aber eine Node.js-Installation.
Stellen Sie sicher, dass Node.js installiert ist.
Konfigurieren Sie Ihre MCP-Einstellungen:
Claude/Cline/Roo-Konfigurationsbeispiel: Fügen Sie Ihrer MCP-Einstellungsdatei den folgenden Konfigurationsblock hinzu:
{ "mcpServers": { "docs-mcp-server": { "command": "npx", "args": ["-y", "@arabold/docs-mcp-server"], // This will run the default MCP server (stdio). // To run in HTTP mode, add arguments: e.g. // "args": ["-y", "@arabold/docs-mcp-server", "--protocol", "http", "--port", "6280"], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }Denken Sie daran
"sk-proj-..."durch Ihren tatsächlichen OpenAI-API-Schlüssel zu ersetzen und die Anwendung neu zu starten.Das war's! Der Server steht jetzt Ihrem KI-Assistenten zur Verfügung.
Webschnittstelle starten
Wenn Sie den MCP-Server mit npx ausführen (wie oben gezeigt, wird er standardmäßig ausgeführt), verwenden Sie npx auch für die Weboberfläche:
Sie können mit dem Flag --port einen anderen Port für die Weboberfläche angeben.
Der npx -Ansatz verwendet das Standarddatenverzeichnis auf Ihrem System (normalerweise in Ihrem Home-Verzeichnis) und stellt so die Konsistenz zwischen Server und Weboberfläche sicher.
Verwenden der CLI
Wenn Sie den MCP-Server mit npx ausführen, können Sie npx auch für CLI-Befehle verwenden:
Beispiel:
Der npx -Ansatz verwendet das Standarddatenverzeichnis auf Ihrem System (normalerweise in Ihrem Home-Verzeichnis), um Konsistenz sicherzustellen.
Für eine detaillierte Befehlsverwendung führen Sie die CLI mit dem Flag --help aus (z. B. npx -y @arabold/docs-mcp-server --help ).
Konfiguration
Die folgenden Umgebungsvariablen werden zur Konfiguration des Einbettungsmodellverhaltens unterstützt. Geben Sie sie in Ihrer .env Datei an oder übergeben Sie sie als -e Flags, wenn Sie den Server über Docker oder npx ausführen.
Einbettungsmodellkonfiguration
DOCS_MCP_EMBEDDING_MODEL: Optional. Format:provider:model_nameoder einfachmodel_name(Standard:text-embedding-3-small). Unterstützte Anbieter und ihre erforderlichen Umgebungsvariablen:openai(Standardanbieter): Verwendet die Einbettungsmodelle von OpenAI.OPENAI_API_KEY: Ihr OpenAI-API-Schlüssel. Erforderlich, wennOPENAI_ORG_ID: Optional. Ihre OpenAI-Organisations-IDOPENAI_API_BASE: Optional. Benutzerdefinierte Basis-URL für OpenAI-kompatible APIs (z. B. Ollama).
vertex: Verwendet Google Cloud Vertex AI-EinbettungenGOOGLE_APPLICATION_CREDENTIALS: Erforderlich. Pfad zur JSON-Schlüsseldatei des Dienstkontos
gemini: Verwendet Einbettungen von Google Generative AI (Gemini)GOOGLE_API_KEY: Erforderlich. Ihr Google API-Schlüssel
aws: Verwendet AWS Bedrock-EinbettungenAWS_ACCESS_KEY_ID: Erforderlich. AWS-ZugriffsschlüsselAWS_SECRET_ACCESS_KEY: Erforderlich. AWS-GeheimschlüsselAWS_REGIONoderBEDROCK_AWS_REGION: Erforderlich. AWS-Region für Bedrock
microsoft: Verwendet Azure OpenAI-EinbettungenAZURE_OPENAI_API_KEY: Erforderlich. Azure OpenAI API-SchlüsselAZURE_OPENAI_API_INSTANCE_NAME: Erforderlich. Azure-InstanznameAZURE_OPENAI_API_DEPLOYMENT_NAME: Erforderlich. Azure-BereitstellungsnameAZURE_OPENAI_API_VERSION: Erforderlich. Azure-API-Version
Vektordimensionen
Das Datenbankschema verwendet eine feste Dimension von 1536 für eingebettete Vektoren. Es werden nur Modelle unterstützt, die Vektoren mit einer Dimension ≤ 1536 erzeugen, mit Ausnahme bestimmter Anbieter (wie Gemini), die eine Dimensionsreduzierung unterstützen.
Verwenden Sie für OpenAI-kompatible APIs (wie Ollama) den openai Anbieter mit OPENAI_API_BASE , der auf Ihren Endpunkt verweist.
Entwicklung
Dieser Abschnitt behandelt die Ausführung des Servers/der CLI direkt aus dem Quellcode für Entwicklungszwecke. Die primäre Verwendung erfolgt über das öffentliche Docker-Image ( ghcr.io/arabold/docs-mcp-server:latest ), wie im Abschnitt „Alternative: Verwendung von Docker“ beschrieben, oder über Docker Compose, wie im Abschnitt „Empfohlen: Docker Desktop“ beschrieben.
Ausführen von der Quelle
Hinweis: Playwright-Browser werden bei
npm installnicht automatisch installiert. Wenn Sie Tests ausführen oder Funktionen nutzen möchten, die Playwright erfordern, führen Sie Folgendes aus:npx playwright install --no-shell --with-deps chromium
Dies bietet eine isolierte Umgebung und stellt den Server über HTTP-Endpunkte bereit.
Diese Methode ist nützlich, um zum Projekt beizutragen oder unveröffentlichte Versionen auszuführen.
Klonen Sie das Repository:
git clone https://github.com/arabold/docs-mcp-server.git # Replace with actual URL if different cd docs-mcp-serverInstallieren Sie Abhängigkeiten:
npm installErstellen Sie das Projekt: Dadurch wird TypeScript im Verzeichnis
dist/in JavaScript kompiliert.npm run buildSetup-Umgebung: Erstellen und konfigurieren Sie Ihre
.envDatei wie im Abschnitt „Konfiguration“ beschrieben. Dies ist wichtig für die Bereitstellung desOPENAI_API_KEY.Laufen:
Standard-MCP-Server (Entwicklung):
Stdio-Modus (Standard):
npm run dev:serverHTTP-Modus:
npm run dev:server:http(verwendet Standardport)Benutzerdefiniertes HTTP:
vite-node src/index.ts -- --protocol http --port <your_port>
Webschnittstelle (Entwicklung):
npm run dev:webDadurch wird der Webserver gestartet (z. B. auf Port 6281) und auf Asset-Änderungen überwacht.
CLI-Befehle (Entwicklung):
npm run dev:cli -- <command> [options]Beispiel:
npm run dev:cli -- listBeispiel:
vite-node src/index.ts scrape <library> <url>
Produktionsmodus (nach
Standard-MCP-Server (stdio):
npm run start(odernode dist/index.js)MCP-Server (HTTP):
npm run start -- --protocol http --port <your_port>(odernode dist/index.js --protocol http --port <your_port>)Webschnittstelle:
npm run web -- --port <web_port>(odernode dist/index.js web --port <web_port>)CLI-Befehle:
npm run cli -- <command> [options](odernode dist/index.js <command> [options])
Testen
Da MCP-Server über stdio kommunizieren, wenn sie direkt über Node.js (oder vite-node ) ausgeführt werden, kann das Debuggen eine Herausforderung darstellen. Wir empfehlen die Verwendung des MCP Inspector .
Nach dem Erstellen des Projekts ( npm run build ):
Bei Verwendung von vite-node für die Entwicklung:
Der Inspector stellt eine URL für den Zugriff auf Debugging-Tools in Ihrem Browser bereit.
Architektur
Einzelheiten zur Architektur und den Designprinzipien des Projekts finden Sie unter ARCHITECTURE.md .
Bemerkenswerterweise wurde der Großteil des Codes dieses Projekts vom KI-Assistenten Cline generiert, der die Fähigkeiten dieses MCP-Servers nutzt.