
Servidor Docs MCP: el experto en documentación actualizada de su IA
Los asistentes de programación de IA suelen tener dificultades con documentación obsoleta, lo que da lugar a sugerencias incorrectas o ejemplos de código engañosos. Verificar las respuestas de la IA con versiones específicas de la biblioteca puede ser una tarea lenta e ineficiente.
El Servidor Docs MCP soluciona este problema actuando como una base de conocimiento personal y siempre actualizada para tu asistente de IA. Su objetivo principal es indexar la documentación de terceros : las bibliotecas que utilizas en tu código. Extrae información de sitios web, repositorios de GitHub, gestores de paquetes (npm, PyPI) e incluso archivos locales, catalogando la documentación localmente. A continuación, proporciona potentes herramientas de búsqueda a tu agente de programación mediante el Protocolo de Contexto de Modelo (MCP).
Esto le permite a su agente LLM acceder a la documentación oficial más reciente de cualquier biblioteca que agregue, mejorando drásticamente la calidad y confiabilidad del código generado y los detalles de integración.
Al fundamentar las respuestas de IA en un contexto preciso y que reconoce la versión, Docs MCP Server le permite recibir detalles de integración y fragmentos de código concisos y relevantes, lo que mejora la confiabilidad y la eficiencia del desarrollo asistido por LLM.
Es gratuito , de código abierto , se ejecuta localmente para mayor privacidad y se integra perfectamente en su flujo de trabajo de desarrollo.
¿Por qué utilizar el servidor Docs MCP?
La codificación asistida por LLM promete velocidad y eficiencia, pero a menudo se queda corta debido a:
🌀 Conocimientos obsoletos: los LLM se capacitan con instantáneas de Internet y se quedan rápidamente atrás de los nuevos lanzamientos de bibliotecas y los cambios de API.
👻 Alucinaciones de código: la IA puede inventar un código de apariencia plausible que sea sintácticamente correcto pero funcionalmente incorrecto o utilice API inexistentes.
❓ Ambigüedad de versión: las respuestas genéricas rara vez tienen en cuenta las dependencias de versiones específicas de su proyecto, lo que genera errores sutiles.
⏳ Verificación excesiva: los desarrolladores dedican un tiempo valioso a verificar las sugerencias de IA con la documentación oficial.
El servidor Docs MCP aborda estos problemas directamente mediante lo siguiente:
✅ Proporciona contexto siempre actualizado: obtiene e indexa documentación directamente de fuentes oficiales (sitios web, GitHub, npm, PyPI, archivos locales) a pedido.
🎯 Entrega de respuestas específicas de cada versión: las consultas de búsqueda pueden apuntar a versiones exactas de la biblioteca, lo que garantiza que la información se alinee con las dependencias de su proyecto.
💡 Reducción de alucinaciones: al basar el LLM en documentación real, proporciona ejemplos precisos y detalles de integración.
⚡ Aumente la productividad: obtenga respuestas confiables más rápido, integradas directamente en el flujo de trabajo de su asistente de IA.
Related MCP server: mcp-hn
✨ Características principales
Conocimiento actualizado: obtiene la documentación más reciente directamente de la fuente.
Búsqueda según la versión: obtenga respuestas relevantes para versiones de bibliotecas específicas (por ejemplo,
react@18.2.0vsreact@17.0.0).Fragmentos precisos: reduce las alucinaciones de la IA al utilizar el contexto de los documentos oficiales.
Interfaz web: proporciona una interfaz web fácil de usar para buscar y administrar documentación.
Amplia compatibilidad de fuentes: extrae datos de sitios web, repositorios de GitHub, sitios de administradores de paquetes (npm, PyPI) e incluso directorios de archivos locales.
Procesamiento inteligente: fragmenta automáticamente la documentación semánticamente y genera incrustaciones.
Modelos de integración flexibles: compatible con OpenAI (incluidas API compatibles como Ollama), Google Gemini/Vertex AI, Azure OpenAI, AWS Bedrock y más.
Búsqueda híbrida potente: combina la similitud vectorial con la búsqueda de texto completo para determinar relevancia.
Local y privado: se ejecuta completamente en su máquina, manteniendo sus datos y consultas privados.
Gratis y de código abierto: creado para la comunidad, por la comunidad.
Implementación simple: configuración fácil a través de Docker o
npx.Integración perfecta: funciona con clientes compatibles con MCP (como Claude, Cline, Roo).
Cómo ejecutar el servidor Docs MCP
¡Comienza a trabajar rápidamente! Recomendamos usar Docker Desktop (Docker Compose) para una configuración y administración más sencillas.
Recomendado: Docker Desktop
Este método proporciona una configuración local persistente al ejecutar el servidor y la interfaz web mediante Docker Compose. Requiere clonar el repositorio, pero simplifica la gestión conjunta de ambos servicios.
Asegúrese de que Docker y Docker Compose estén instalados y en ejecución.
Clonar el repositorio:
git clone https://github.com/arabold/docs-mcp-server.git cd docs-mcp-serverConfigure su entorno: copie el archivo de entorno de ejemplo y edítelo para agregar su clave API de OpenAI (obligatoria):
cp .env.example .env # Edit the .env file and set your OpenAI API key:Ejemplo
.env:OPENAI_API_KEY=your-api-key-herePara obtener opciones de configuración adicionales (por ejemplo, otros proveedores, configuraciones avanzadas), consulte la sección Configuración .
Iniciar los servicios: Ejecute este comando desde el directorio raíz del repositorio. Generará las imágenes (si es necesario) e iniciará el servidor y la interfaz web en segundo plano.
docker compose up -d-d: Ejecuta los contenedores en modo independiente (en segundo plano). Omítalo para ver los registros directamente en tu terminal.
Nota: Si extrae actualizaciones para el repositorio (por ejemplo, usando
git pull), deberá reconstruir las imágenes de Docker para incluir los cambios ejecutandodocker compose up -d --build.Configure su cliente MCP: agregue el siguiente bloque de configuración a su archivo de configuración MCP (por ejemplo, para Claude, Cline, Roo):
{ "mcpServers": { "docs-mcp-server": { "url": "http://localhost:6280/sse", // Connects via HTTP to the Docker Compose service "disabled": false, "autoApprove": [] } } }Reinicie su aplicación de asistente de inteligencia artificial después de actualizar la configuración.
Nota: La configuración de Docker Compose ejecuta el servidor Docs MCP en modo HTTP (vía SSE) por diseño, ya que está concebido como una instancia independiente y conectable. No admite la comunicación stdio.
Acceder a la interfaz web: La interfaz web estará disponible en
http://localhost:6281.
Beneficios de este método:
Ejecuta el servidor y la interfaz web con un solo comando.
Utiliza el código fuente local (se reconstruye automáticamente si el código cambia y ejecuta
docker compose up --build).Almacenamiento de datos persistente a través del volumen Docker
docs-mcp-data.Fácil gestión de la configuración a través del archivo
.env.
Para detener los servicios, ejecute docker compose down desde el directorio del repositorio.
Agregar documentación de la biblioteca
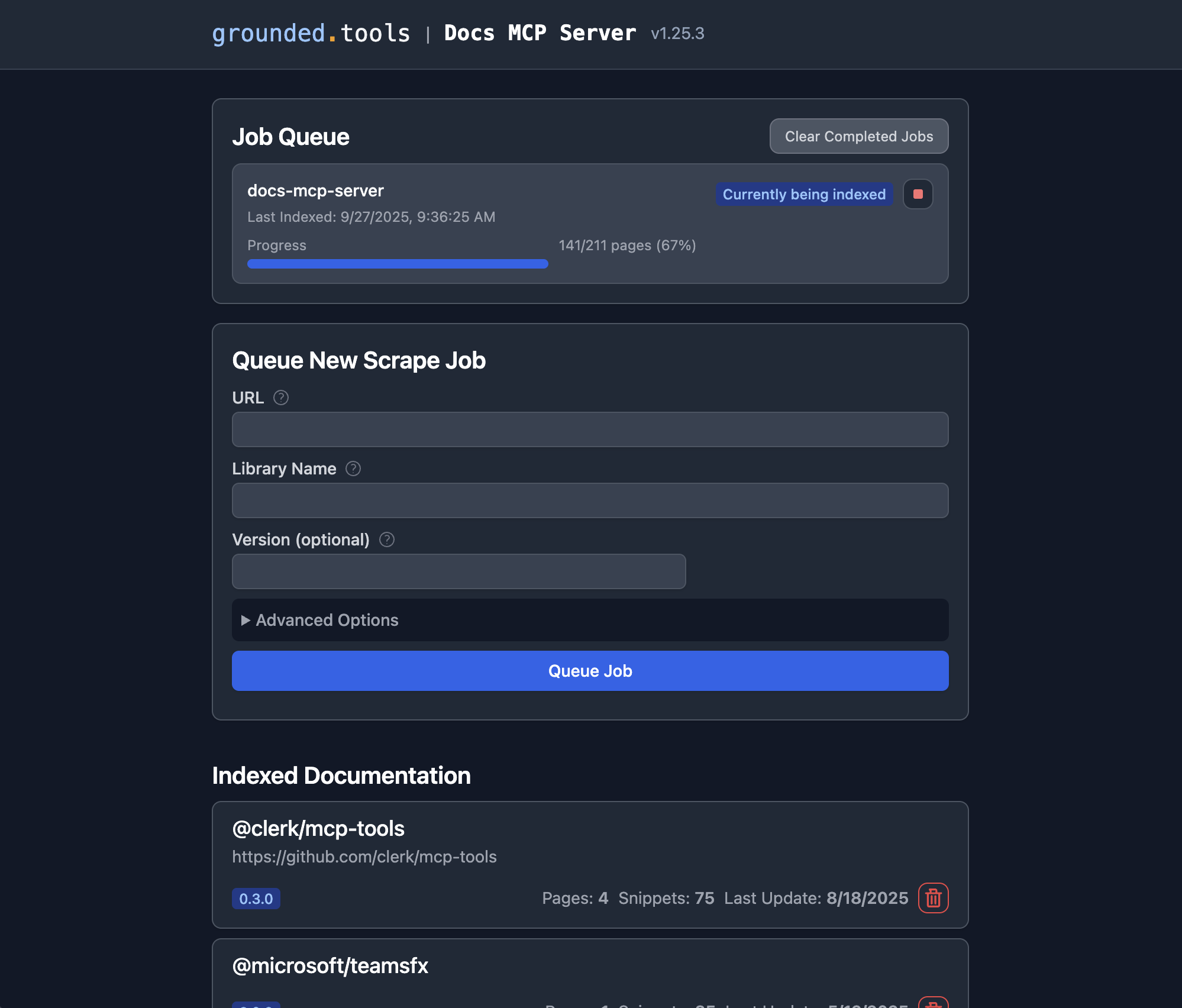
Una vez que el servidor Docs MCP esté en ejecución, puede usar la interfaz web para agregar nueva documentación para indexar o buscar documentación existente .
Abra la interfaz web: si utilizó la configuración recomendada de Docker Compose, navegue con su navegador a
http://localhost:6281.Busque el formulario "Poner en cola nuevo trabajo de scrape": este suele aparecer de forma destacada en la página principal.
Introduzca los detalles:
URL: proporcione la URL de inicio para la documentación que desea indexar (por ejemplo,
https://react.dev/reference/react,https://github.com/expressjs/express,https://docs.python.org/3/).Nombre de la biblioteca: Dale un nombre corto y fácil de recordar (p. ej.,
react,express,python). Así es como la mencionarás en las búsquedas.Versión (opcional): Si desea indexar una versión específica, introdúzcala aquí (p. ej.,
18.2.0,4.17.1,3.11). Si se deja en blanco, el servidor suele intentar detectar la última versión o indexarla como sin versionar.(Opcional) Configuración avanzada: Ajuste
Scope(p. ej., "Subpáginas", "Nombre de host", "Dominio"),Max Pages,Max DepthyFollow Redirectssi es necesario. Los valores predeterminados suelen ser suficientes.
Haga clic en "Cola de trabajos": El servidor iniciará un trabajo en segundo plano para obtener, procesar e indexar la documentación. Puede supervisar su progreso en la sección "Cola de trabajos" de la interfaz web.
Repetir: repita los pasos 3 y 4 para cada biblioteca cuya documentación desea que el servidor administre.
¡Listo! Una vez finalizado un trabajo, la documentación de esa biblioteca y versión estará disponible para su búsqueda a través del asistente de codificación de IA conectado (con la herramienta search_docs ) o directamente en la interfaz web, haciendo clic en el nombre de la biblioteca en la sección "Documentación indexada".
Alternativa: usar Docker
Este enfoque es fácil, directo y no requiere clonar el repositorio.
Asegúrese de que Docker esté instalado y en ejecución.
Configure los ajustes de su MCP:
Ejemplo de configuración de Claude/Cline/Roo: agregue el siguiente bloque de configuración a su archivo de configuración de MCP (ajuste la ruta según sea necesario):
{ "mcpServers": { "docs-mcp-server": { "command": "docker", "args": [ "run", "-i", "--rm", "-e", "OPENAI_API_KEY", "-v", "docs-mcp-data:/data", "ghcr.io/arabold/docs-mcp-server:latest" ], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }Recuerde reemplazar
"sk-proj-..."con su clave API de OpenAI real y reiniciar la aplicación.¡Listo! El servidor ya estará disponible para tu asistente de IA.
Configuración del contenedor Docker:
-i: Mantener STDIN abierto, crucial para la comunicación MCP a través de stdio.--rm: elimina automáticamente el contenedor cuando sale.-e OPENAI_API_KEY: Obligatorio. Establezca su clave de API de OpenAI.-v docs-mcp-data:/data: Obligatorio para la persistencia. Monta un Docker llamado volumendocs-mcp-datapara almacenar la base de datos. Puede reemplazarlo con una ruta de host específica si lo prefiere (p. ej.,-v /path/on/host:/data).
Cualquier variable de entorno de configuración (ver Configuración más arriba) se puede pasar al contenedor mediante el indicador -e . Por ejemplo:
Lanzamiento de la interfaz web
Puede acceder a una GUI basada en web en http://localhost:6281 para administrar y buscar documentación de la biblioteca a través de su navegador.
Si está ejecutando el servidor con Docker, utilice Docker también para la interfaz web:
Asegúrese de:
Utilice el mismo nombre de volumen (
docs-mcp-dataen este ejemplo) que su servidorAsignar el puerto 6281 con
-p 6281:6281Pase cualquier variable de entorno de configuración con indicadores
-e
Usando la CLI
Puede utilizar la CLI para administrar la documentación directamente a través de Docker pasando comandos CLI después del nombre de la imagen:
Ejemplo:
Asegúrese de usar el mismo nombre de volumen ( docs-mcp-data en este ejemplo) que el contenedor del servidor MCP si desea que compartan datos. Cualquier variable de entorno de configuración (consulte "Configuración" más arriba) se puede pasar mediante el parámetro -e .
Los principales comandos disponibles son:
scrape: raspa e indexa la documentación de una URL.search: busca en la documentación indexada.list: enumera todas las bibliotecas indexadas.remove: elimina la documentación indexada.fetch-url: obtiene una única URL y la convierte a Markdown.find-version: encuentra la mejor versión coincidente para una biblioteca.
Para obtener un uso detallado del comando, ejecute la CLI con el indicador --help (por ejemplo, docker run ... ghcr.io/arabold/docs-mcp-server:latest --help ).
Alternativa: usar npx
Este enfoque es útil cuando se necesita acceso a archivos locales (por ejemplo, para indexar documentación desde el sistema de archivos local). Si bien esto también se puede lograr montando rutas en un contenedor Docker, usar npx es más sencillo, pero requiere una instalación de Node.js.
Asegúrese de que Node.js esté instalado.
Configure los ajustes de su MCP:
Ejemplo de configuración de Claude/Cline/Roo: agregue el siguiente bloque de configuración a su archivo de configuración de MCP:
{ "mcpServers": { "docs-mcp-server": { "command": "npx", "args": ["-y", "@arabold/docs-mcp-server"], // This will run the default MCP server (stdio). // To run in HTTP mode, add arguments: e.g. // "args": ["-y", "@arabold/docs-mcp-server", "--protocol", "http", "--port", "6280"], "env": { "OPENAI_API_KEY": "sk-proj-..." // Required if using OpenAI (default) }, "disabled": false, "autoApprove": [] } } }Recuerde reemplazar
"sk-proj-..."con su clave API de OpenAI real y reiniciar la aplicación.¡Listo! El servidor ya estará disponible para tu asistente de IA.
Lanzamiento de la interfaz web
Si está ejecutando el servidor MCP con npx (como se muestra arriba, se ejecuta de manera predeterminada), use npx también para la interfaz web:
Puede especificar un puerto diferente para la interfaz web utilizando su indicador --port .
El enfoque npx utilizará el directorio de datos predeterminado de su sistema (normalmente en su directorio de inicio), lo que garantiza la coherencia entre el servidor y la interfaz web.
Usando la CLI
Si está ejecutando el servidor MCP con npx , también puede usar npx para los comandos CLI:
Ejemplo:
El enfoque npx utilizará el directorio de datos predeterminado de su sistema (normalmente, su directorio de inicio), lo que garantiza la coherencia.
Para un uso detallado del comando, ejecute la CLI con el indicador --help (por ejemplo, npx -y @arabold/docs-mcp-server --help ).
Configuración
Las siguientes variables de entorno son compatibles para configurar el comportamiento del modelo de incrustación. Especifíquelas en su archivo .env o páselas como indicadores -e al ejecutar el servidor mediante Docker o npx.
Configuración del modelo de incrustación
DOCS_MCP_EMBEDDING_MODEL: Opcional. Formato:provider:model_nameo simplementemodel_name(el valor predeterminado estext-embedding-3-small). Proveedores compatibles y sus variables de entorno requeridas:openai(proveedor predeterminado): utiliza los modelos de integración de OpenAI.OPENAI_API_KEY: Su clave API de OpenAI. Obligatoria siOPENAI_ORG_ID: Opcional. Su ID de organización de OpenAI.OPENAI_API_BASE: Opcional. URL base personalizada para API compatibles con OpenAI (p. ej., Ollama).
vertex: utiliza incrustaciones de inteligencia artificial de Google Cloud VertexGOOGLE_APPLICATION_CREDENTIALS: Obligatorio. Ruta al archivo de clave JSON de la cuenta de servicio.
gemini: utiliza incrustaciones de Google Generative AI (Gemini)GOOGLE_API_KEY: Obligatorio. Tu clave API de Google.
aws: utiliza incrustaciones de AWS BedrockAWS_ACCESS_KEY_ID: Obligatorio. Clave de acceso de AWS.AWS_SECRET_ACCESS_KEY: Obligatorio. Clave secreta de AWS.AWS_REGIONoBEDROCK_AWS_REGION: Obligatorio. Región de AWS para Bedrock.
microsoft: utiliza incrustaciones de Azure OpenAIAZURE_OPENAI_API_KEY: Obligatorio. Clave de API de Azure OpenAI.AZURE_OPENAI_API_INSTANCE_NAME: Obligatorio. Nombre de la instancia de Azure.AZURE_OPENAI_API_DEPLOYMENT_NAME: Obligatorio. Nombre de la implementación de Azure.AZURE_OPENAI_API_VERSION: Obligatorio. Versión de la API de Azure.
Dimensiones vectoriales
El esquema de la base de datos utiliza una dimensión fija de 1536 para la incrustación de vectores. Solo se admiten los modelos que generan vectores con una dimensión ≤ 1536, excepto ciertos proveedores (como Gemini) que admiten la reducción de dimensión.
Para las API compatibles con OpenAI (como Ollama), utilice el proveedor openai con OPENAI_API_BASE apuntando a su punto final.
Desarrollo
Esta sección describe la ejecución del servidor/CLI directamente desde el código fuente para fines de desarrollo. El método principal de uso es a través de la imagen pública de Docker ( ghcr.io/arabold/docs-mcp-server:latest ), como se detalla en la sección "Alternativa: Uso de Docker", o mediante Docker Compose, como se describe en la sección "Recomendación: Docker Desktop".
Corriendo desde la fuente
Nota: Los navegadores de Playwright no se instalan automáticamente durante
npm install. Si necesita ejecutar pruebas o usar funciones que requieren Playwright, ejecute:npx playwright install --no-shell --with-deps chromium
Esto proporciona un entorno aislado y expone el servidor a través de puntos finales HTTP.
Este método es útil para contribuir al proyecto o ejecutar versiones no publicadas.
Clonar el repositorio:
git clone https://github.com/arabold/docs-mcp-server.git # Replace with actual URL if different cd docs-mcp-serverInstalar dependencias:
npm installConstruir el proyecto: Esto compila TypeScript a JavaScript en el directorio
dist/.npm run buildEntorno de configuración: Cree y configure su archivo
.envcomo se describe en la sección Configuración . Esto es crucial para proporcionar laOPENAI_API_KEY.Correr:
Servidor MCP predeterminado (desarrollo):
Modo Stdio (predeterminado):
npm run dev:serverModo HTTP:
npm run dev:server:http(usa el puerto predeterminado)HTTP personalizado:
vite-node src/index.ts -- --protocol http --port <your_port>
Interfaz web (desarrollo):
npm run dev:webEsto inicia el servidor web (por ejemplo, en el puerto 6281) y observa los cambios de activos.
Comandos CLI (Desarrollo):
npm run dev:cli -- <command> [options]Ejemplo:
npm run dev:cli -- listEjemplo:
vite-node src/index.ts scrape <library> <url>
Modo de producción (después de
Servidor MCP predeterminado (stdio):
npm run start(onode dist/index.js)Servidor MCP (HTTP):
npm run start -- --protocol http --port <your_port>(onode dist/index.js --protocol http --port <your_port>)Interfaz web:
npm run web -- --port <web_port>(onode dist/index.js web --port <web_port>)Comandos CLI:
npm run cli -- <command> [options](onode dist/index.js <command> [options])
Pruebas
Dado que los servidores MCP se comunican a través de stdio cuando se ejecutan directamente con Node.js (o vite-node ), la depuración puede ser complicada. Recomendamos usar el Inspector MCP .
Después de construir el proyecto ( npm run build ):
Si utiliza vite-node para el desarrollo:
El Inspector proporcionará una URL para acceder a las herramientas de depuración en su navegador.
Arquitectura
Para obtener detalles sobre la arquitectura del proyecto y los principios de diseño, consulte ARCHITECTURE.md .
Cabe destacar que la gran mayoría del código de este proyecto fue generado por el asistente de inteligencia artificial Cline, aprovechando las capacidades de este mismo servidor MCP.