English ·简体中文
変更履歴
導入
Dingoは、データセット内のデータ品質の問題を自動検出するデータ品質評価ツールです。Dingoは、様々な組み込みルールとモデル評価手法を提供するほか、カスタム評価手法もサポートしています。Dingoは、事前学習用データセット、ファインチューニング用データセット、評価用データセットなど、一般的に使用されるテキストデータセットとマルチモーダルデータセットをサポートしています。さらに、DingoはローカルCLIやSDKなど、複数の利用方法をサポートしているため、 OpenCompassなどの様々な評価プラットフォームへの統合が容易です。
アーキテクチャ図
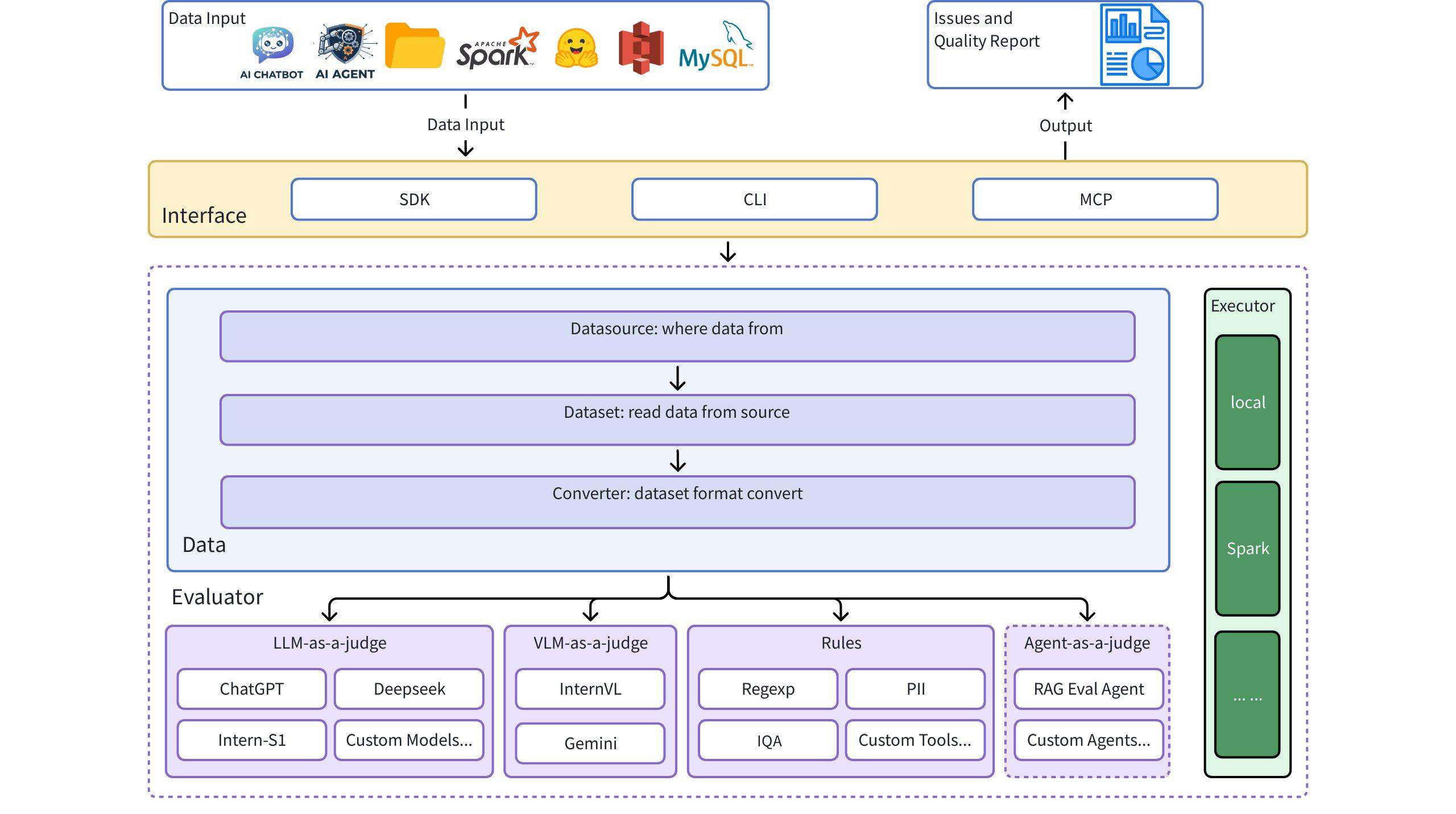
クイックスタート
インストール
使用例
1. Evaluate Coreの使用
from dingo.config.config import DynamicLLMConfig
from dingo.io.input.MetaData import MetaData
from dingo.model.llm.llm_text_quality_model_base import LLMTextQualityModelBase
from dingo.model.rule.rule_common import RuleEnterAndSpace
def llm():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
LLMTextQualityModelBase.dynamic_config = DynamicLLMConfig(
key='',
api_url='',
# model='',
)
res = LLMTextQualityModelBase.eval(data)
print(res)
def rule():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
res = RuleEnterAndSpace().eval(data)
print(res)
2. ローカルテキストファイル(プレーンテキスト)を評価する
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a plaintext file
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "data.txt", # Path to local text file
"dataset": "local",
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
3. ハグ顔データセットを評価する
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a dataset from Hugging Face
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
4. JSON/JSONL形式の評価
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a JSON file
input_data = {
"eval_group": "default", # Default rule set
"input_path": "data.json", # Path to local JSON file
"dataset": "local",
"data_format": "json", # Format: json
"column_content": "text", # Column containing the text to evaluate
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
5. LLMを用いた評価
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate using GPT model
input_data = {
"input_path": "data.jsonl", # Path to local JSONL file
"dataset": "local",
"data_format": "jsonl",
"column_content": "content",
"custom_config": {
"prompt_list": ["PromptRepeat"], # Prompt to use
"llm_config": {
"detect_text_quality": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
コマンドラインインターフェース
ルールセットで評価する
python -m dingo.run.cli --input_path data.txt --dataset local -e sft --data_format plaintext --save_data True
LLM(例:GPT-4o)で評価する
python -m dingo.run.cli --input_path data.json --dataset local -e openai --data_format json --column_content text --custom_config config_gpt.json --save_data True
例config_gpt.json :
{
"llm_config": {
"openai": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
GUI視覚化
評価後( save_data=Trueの場合)、フロントエンドページが自動的に生成されます。フロントエンドを手動で起動するには、以下の手順を実行してください。
python -m dingo.run.vsl --input output_directory
output_directoryには、 summary.jsonファイルを含む評価結果が含まれます。
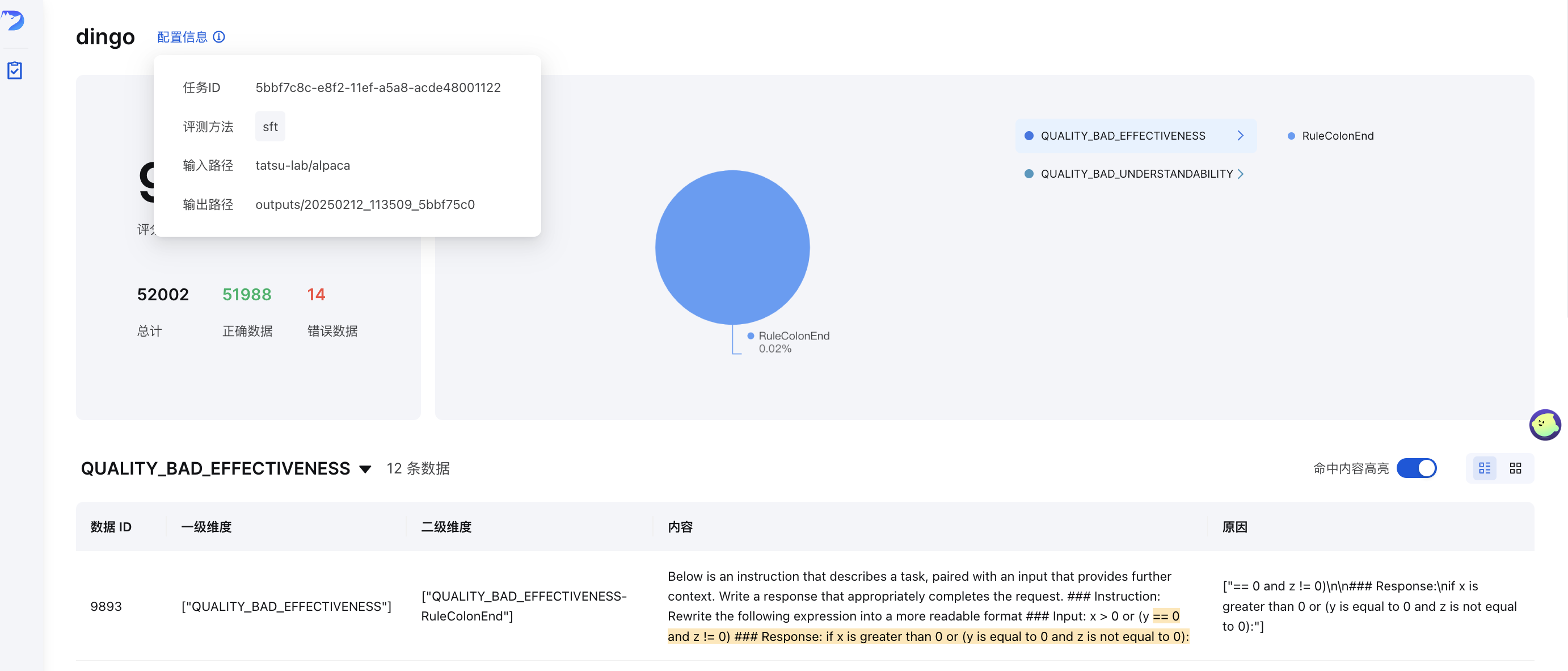
オンラインデモ
オンラインデモでDingoをお試しください: (Hugging Face)🤗
データ品質メトリクス
Dingoは、データ品質の問題を7つの品質メトリクスの次元に分類します。各次元は、ルールベースの手法とLLMベースのプロンプトの両方を使用して評価できます。
| 品質指標 | 説明 | ルールの例 | LLMプロンプトの例 |
|---|
| 完全 | データが不完全または欠落していないかを確認します | RuleColonEnd 、 RuleContentNull | テキストがコロンまたは省略記号で突然終わっているか、括弧が一致していないか、重要なコンポーネントが欠落しているかを評価します。 |
| 効果 | データが意味を持ち、適切にフォーマットされているかどうかを確認します | RuleAbnormalChar 、 RuleHtmlEntity 、 RuleSpecialCharacter | 文字化けしたテキスト、スペースなしでつながった単語、適切な句読点がないテキストを検出します |
| 流暢さ | テキストが文法的に正しく、自然に読めるかどうかを確認します | RuleAbnormalNumber 、 RuleNoPunc 、 RuleWordStuck | 長すぎる単語、句読点のないテキストの断片、または読み順が乱れたコンテンツを識別します |
| 関連性 | データ内の無関係なコンテンツを検出する | さまざまな言語のRuleHeadWordバリエーション | 引用の詳細、ヘッダー/フッター、エンティティマーカー、HTMLタグなどの無関係な情報を検査します。 |
| 安全 | 機密情報や価値観の衝突を特定する | RuleIDCard 、 RuleUnsafeWords | 個人情報、ギャンブル、ポルノ、政治問題に関連するコンテンツをチェックします |
| 類似性 | 繰り返しや類似性の高いコンテンツを検出します | RuleDocRepeat | テキスト内の連続した繰り返しコンテンツや特殊文字の複数出現を評価します |
| 理解しやすさ | データがどれだけ簡単に解釈できるかを評価する | RuleCapitalWords | LaTeX 式と Markdown が適切なセグメンテーションと改行で正しくフォーマットされていることを確認します。 |
LLM品質評価
Dingoはdingo/model/promptディレクトリ内のプロンプトで定義されたLLMベースの評価手法をいくつか提供しています。これらのプロンプトはprompt_registerデコレータを使用して登録され、LLMモデルと組み合わせて品質評価を行うことができます。
テキスト品質評価プロンプト
| プロンプトタイプ | メトリック | 説明 |
|---|
TEXT_QUALITY_V2 、 TEXT_QUALITY_V3 | さまざまな品質次元 | 有効性、関連性、完全性、理解可能性、類似性、流暢性、セキュリティを網羅した包括的なテキスト品質評価 |
QUALITY_BAD_EFFECTIVENESS | 効果 | 文字化けしたテキストやクロール対策コンテンツを検出します |
QUALITY_BAD_SIMILARITY | 類似性 | テキストの繰り返しの問題を特定します |
WORD_STICK | 流暢さ | 適切な間隔を空けずに単語がつながっていないかチェックします |
CODE_LIST_ISSUE | 完全 | コードブロックとリストのフォーマットの問題を評価する |
UNREAD_ISSUE | 効果 | エンコードの問題により判読できない文字を検出します |
3H 評価プロンプト (正直、役立つ、無害)
| プロンプトタイプ | メトリック | 説明 |
|---|
QUALITY_HONEST | 正直 | 回答が捏造や欺瞞のない正確な情報を提供しているかどうかを評価する |
QUALITY_HELPFUL | 有用性 | 回答が質問に直接答えており、指示に適切に従っているかどうかを評価する |
QUALITY_HARMLESS | 無害性 | 回答が有害な内容、差別的な言葉、危険な援助を避けているかどうかを確認します |
ドメイン固有の評価プロンプト
| プロンプトタイプ | メトリック | 説明 |
|---|
TEXT_QUALITY_KAOTI | 試験問題の質 | 数式のレンダリング、表の書式設定、段落構造、回答の書式設定に重点を置いた、試験問題の品質を評価するための専門的な評価 |
Html_Abstract | HTML抽出品質 | HTML から Markdown を抽出するさまざまな方法を比較し、完全性、フォーマットの正確性、意味の一貫性を評価します。 |
DATAMAN_ASSESSMENT | データ品質とドメイン | DataManメソッド(14の基準、15のドメイン)を用いて、事前トレーニングデータの品質を評価します。スコア(0/1)、ドメインタイプ、品質ステータス、および理由を割り当てます。 |
分類プロンプト
| プロンプトタイプ | メトリック | 説明 |
|---|
CLASSIFY_TOPIC | トピックの分類 | テキストを言語処理、ライティング、コード、数学、ロールプレイ、知識Q&Aなどのカテゴリに分類します。 |
CLASSIFY_QR | 画像分類 | 画像を CAPTCHA、QR コード、または通常の画像として識別します |
画像評価プロンプト
| プロンプトタイプ | メトリック | 説明 |
|---|
IMAGE_RELEVANCE | 画像の関連性 | 顔の数、特徴の詳細、視覚要素の観点から画像が参照画像と一致するかどうかを評価します |
評価におけるLLM評価の活用
評価でこれらの評価プロンプトを使用するには、構成で指定します。
input_data = {
# Other parameters...
"custom_config": {
"prompt_list": ["QUALITY_BAD_SIMILARITY"], # Specific prompt to use
"llm_config": {
"detect_text_quality": { # LLM model to use
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
これらのプロンプトは、特定の品質次元に焦点を当てたり、特定のドメイン要件に合わせてカスタマイズできます。適切なLLMモデルと組み合わせることで、複数の次元にわたるデータ品質の包括的な評価が可能になります。
ルールグループ
Dingo は、さまざまな種類のデータセットに対して事前設定されたルール グループを提供します。
| グループ | 使用事例 | ルールの例 |
|---|
default | 一般的なテキスト品質 | RuleColonEnd 、 RuleContentNull 、 RuleDocRepeatなど。 |
sft | データセットの微調整 | defaultのルールとRuleLineStartWithBulletpoint |
pretrain | 事前トレーニングデータセット | RuleAlphaWords 、 RuleCapitalWordsなどを含む 20 以上の包括的なルール セット。 |
特定のルール グループを使用するには:
input_data = {
"eval_group": "sft", # Use "default", "sft", or "pretrain"
# other parameters...
}
特集のハイライト
マルチソース&マルチモーダルサポート
- データソース: ローカルファイル、Hugging Face データセット、S3 ストレージ
- データタイプ: 事前トレーニング、微調整、評価データセット
- データ形式: テキストと画像
ルールベースとモデルベースの評価
- 組み込みルール: 20以上の一般的なヒューリスティック評価ルール
- LLM 統合: OpenAI、Kimi、ローカル モデル (例: Llama3)
- カスタムルール: 独自のルールとモデルで簡単に拡張できます
- セキュリティ評価:Perspective API統合
柔軟な使い方
- インターフェース: CLI および SDK オプション
- 統合: 他のプラットフォームとの簡単な統合
- 実行エンジン: ローカルと Spark
包括的なレポート
- 品質メトリクス:7次元品質評価
- トレーサビリティ: 異常追跡のための詳細なレポート
ユーザーガイド
カスタムルール、プロンプト、モデル
組み込みルールが要件を満たしていない場合は、カスタムルールを作成できます。
カスタムルールの例
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.config.config import DynamicRuleConfig
from dingo.io import MetaData
from dingo.model.modelres import ModelRes
@Model.rule_register('QUALITY_BAD_RELEVANCE', ['default'])
class MyCustomRule(BaseRule):
"""Check for custom pattern in text"""
dynamic_config = DynamicRuleConfig(pattern=r'your_pattern_here')
@classmethod
def eval(cls, input_data: MetaData) -> ModelRes:
res = ModelRes()
# Your rule implementation here
return res
カスタムLLM統合
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('my_custom_model')
class MyCustomModel(BaseOpenAI):
# Custom implementation here
pass
その他の例については以下を参照してください:
実行エンジン
ローカル実行
from dingo.io import InputArgs
from dingo.exec import Executor
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# Get results
summary = executor.get_summary() # Overall evaluation summary
bad_data = executor.get_bad_info_list() # List of problematic data
good_data = executor.get_good_info_list() # List of high-quality data
Spark実行
from dingo.io import InputArgs
from dingo.exec import Executor
from pyspark.sql import SparkSession
# Initialize Spark
spark = SparkSession.builder.appName("Dingo").getOrCreate()
spark_rdd = spark.sparkContext.parallelize([...]) # Your data as MetaData objects
input_args = InputArgs(eval_group="default", save_data=True)
executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd)
result = executor.execute()
評価レポート
評価後、Dingo は次を生成します。
- 概要レポート(
summary.json ):全体的な指標とスコア - 詳細レポート: 各ルール違反の具体的な問題
例の要約:
{
"task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac",
"task_name": "dingo",
"eval_group": "default",
"input_path": "test/data/test_local_jsonl.jsonl",
"output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac",
"create_time": "20241101_144510",
"score": 50.0,
"num_good": 1,
"num_bad": 1,
"total": 2,
"type_ratio": {
"QUALITY_BAD_COMPLETENESS": 0.5,
"QUALITY_BAD_RELEVANCE": 0.5
},
"name_ratio": {
"QUALITY_BAD_COMPLETENESS-RuleColonEnd": 0.5,
"QUALITY_BAD_RELEVANCE-RuleSpecialCharacter": 0.5
}
}
MCP サーバー (実験的)
Dingoには、実験的なModel Context Protocol(MCP)サーバーが含まれています。サーバーの実行方法やCursorなどのクライアントとの統合方法については、専用のドキュメントをご覧ください。
Dingo MCP サーバードキュメント (README_mcp.md)
研究と出版
今後の計画
- [ ] より豊富なグラフィックとテキストの評価指標
- [ ] 音声およびビデオデータのモダリティ評価
- [ ] 小規模モデルの評価(fasttext、Qurating)
- [ ] データ多様性評価
制限事項
現在組み込まれている検出ルールとモデル手法は、一般的なデータ品質の問題に重点を置いています。特殊な評価ニーズには、検出ルールをカスタマイズすることをお勧めします。
謝辞
貢献
Dingo改善と拡張にご尽力いただいたすべての貢献者の皆様に感謝申し上げます。プロジェクトへの貢献方法については、貢献ガイドをご覧ください。
ライセンス
このプロジェクトはApache 2.0 オープンソースライセンスを使用します。
引用
このプロジェクトが役に立つと思われる場合は、ツールを引用することを検討してください。
@misc{dingo,
title={Dingo: A Comprehensive Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/DataEval/dingo}},
year={2024}
}