영어 ·简体中文
변경 사항
소개
Dingo는 데이터 세트에서 데이터 품질 문제를 자동으로 감지하는 데 도움이 되는 데이터 품질 평가 도구입니다. Dingo는 다양한 기본 제공 규칙과 모델 평가 방법을 제공하며, 사용자 지정 평가 방법도 지원합니다. Dingo는 사전 학습 데이터 세트, 미세 조정 데이터 세트, 평가 데이터 세트를 포함하여 일반적으로 사용되는 텍스트 데이터 세트와 멀티모달 데이터 세트를 지원합니다. 또한 Dingo는 로컬 CLI 및 SDK를 포함한 다양한 사용 방법을 지원하여 OpenCompass 와 같은 다양한 평가 플랫폼에 쉽게 통합할 수 있습니다.
아키텍처 다이어그램
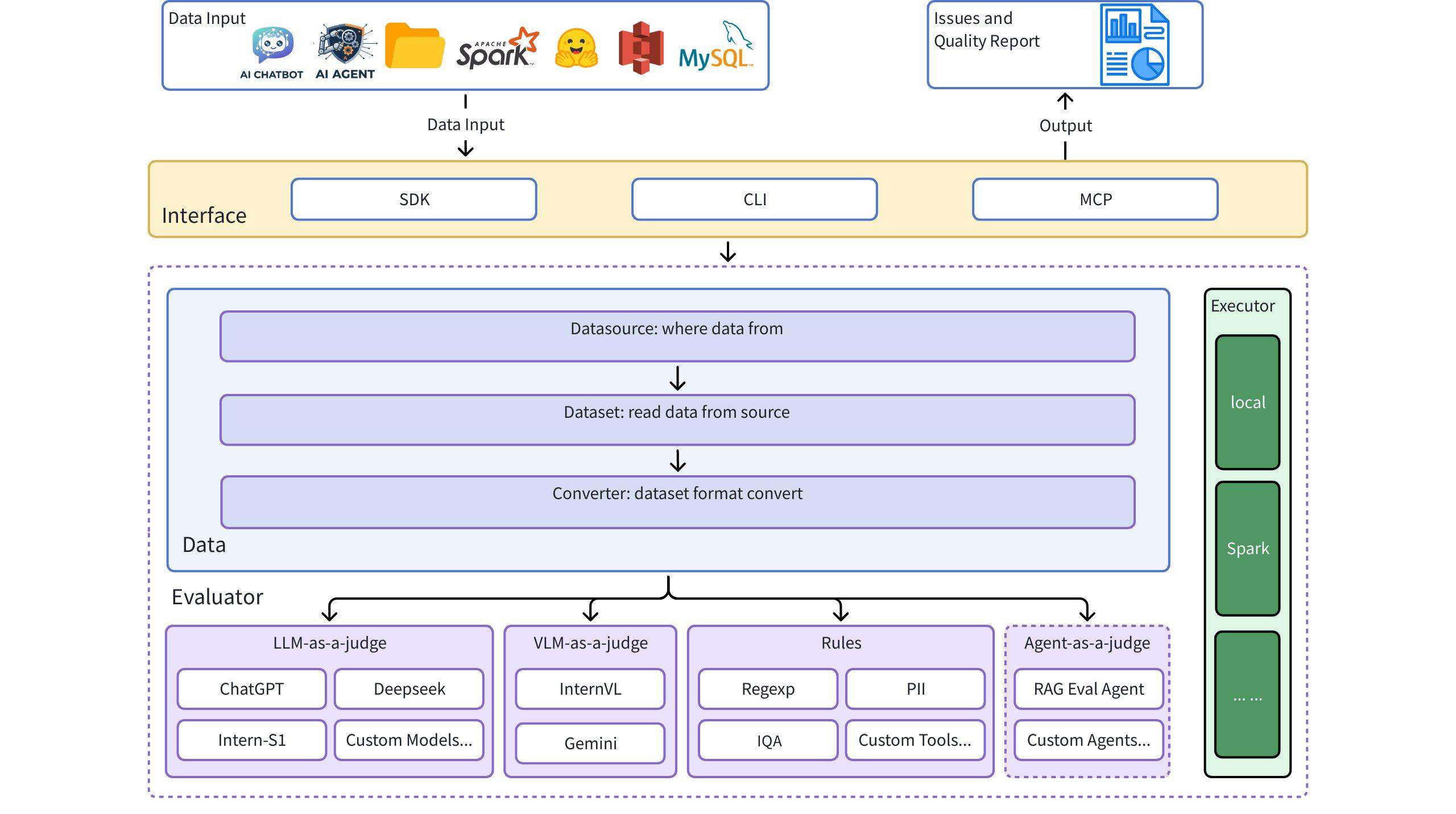
빠른 시작
설치
지엑스피1
예시 사용 사례
1. Evaluate Core 사용
from dingo.config.config import DynamicLLMConfig
from dingo.io.input.MetaData import MetaData
from dingo.model.llm.llm_text_quality_model_base import LLMTextQualityModelBase
from dingo.model.rule.rule_common import RuleEnterAndSpace
def llm():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
LLMTextQualityModelBase.dynamic_config = DynamicLLMConfig(
key='',
api_url='',
# model='',
)
res = LLMTextQualityModelBase.eval(data)
print(res)
def rule():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
res = RuleEnterAndSpace().eval(data)
print(res)
2. 로컬 텍스트 파일(일반 텍스트) 평가
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a plaintext file
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "data.txt", # Path to local text file
"dataset": "local",
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
3. 포옹하는 얼굴 데이터 세트 평가
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a dataset from Hugging Face
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
4. JSON/JSONL 형식 평가
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a JSON file
input_data = {
"eval_group": "default", # Default rule set
"input_path": "data.json", # Path to local JSON file
"dataset": "local",
"data_format": "json", # Format: json
"column_content": "text", # Column containing the text to evaluate
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
5. 평가를 위한 LLM 사용
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate using GPT model
input_data = {
"input_path": "data.jsonl", # Path to local JSONL file
"dataset": "local",
"data_format": "jsonl",
"column_content": "content",
"custom_config": {
"prompt_list": ["PromptRepeat"], # Prompt to use
"llm_config": {
"detect_text_quality": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
명령줄 인터페이스
규칙 세트로 평가
python -m dingo.run.cli --input_path data.txt --dataset local -e sft --data_format plaintext --save_data True
LLM(예: GPT-4o)으로 평가
python -m dingo.run.cli --input_path data.json --dataset local -e openai --data_format json --column_content text --custom_config config_gpt.json --save_data True
예시 config_gpt.json :
{
"llm_config": {
"openai": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
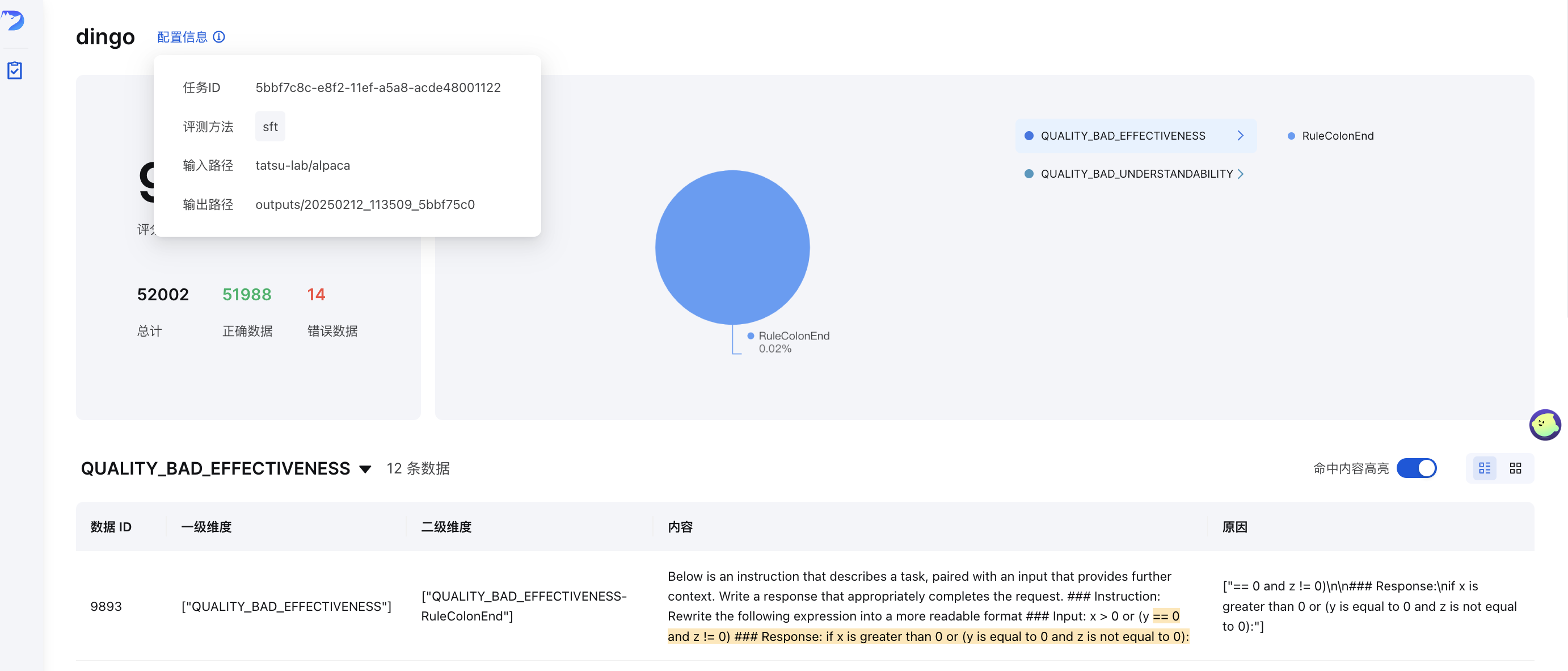
GUI 시각화
평가 후( save_data=True 설정 시), 프런트엔드 페이지가 자동으로 생성됩니다. 프런트엔드를 수동으로 시작하려면 다음 단계를 따르세요.
python -m dingo.run.vsl --input output_directory
output_directory summary.json 파일과 함께 평가 결과가 포함되어 있습니다.
온라인 데모
온라인 데모에서 Dingo를 사용해 보세요: (허깅 페이스)🤗
데이터 품질 지표
Dingo는 데이터 품질 문제를 7가지 품질 지표 차원으로 분류합니다. 각 차원은 규칙 기반 방법과 LLM 기반 프롬프트를 모두 사용하여 평가할 수 있습니다.
| 품질 지표 | 설명 | 규칙 예제 | LLM 프롬프트 예시 |
|---|
| 완전성 | 데이터가 불완전하거나 누락되었는지 확인합니다. | RuleColonEnd , RuleContentNull | 텍스트가 콜론이나 생략 부호로 갑자기 끝나는지, 괄호가 일치하지 않는지, 중요한 구성 요소가 누락되었는지 평가합니다. |
| 유효성 | 데이터가 의미 있고 적절하게 형식화되었는지 확인합니다. | RuleAbnormalChar , RuleHtmlEntity , RuleSpecialCharacter | 왜곡된 텍스트, 공백 없이 붙어 있는 단어, 적절한 구두점이 없는 텍스트를 감지합니다. |
| 유창 | 텍스트가 문법적으로 올바르고 자연스럽게 읽히는지 확인합니다. | RuleAbnormalNumber , RuleNoPunc , RuleWordStuck | 지나치게 긴 단어, 구두점이 없는 텍스트 조각 또는 읽기 순서가 혼란스러운 콘텐츠를 식별합니다. |
| 관련성 | 데이터 내에서 관련 없는 콘텐츠를 감지합니다. | 다양한 언어에 대한 RuleHeadWord 변형 | 인용 세부 정보, 머리글/바닥글, 엔터티 마커, HTML 태그와 같은 관련 없는 정보를 조사합니다. |
| 보안 | 민감한 정보나 가치 충돌을 식별합니다. | RuleIDCard , RuleUnsafeWords | 개인정보 및 도박, 음란물, 정치 이슈 관련 콘텐츠 확인 |
| 유사 | 반복적이거나 매우 유사한 콘텐츠를 감지합니다. | RuleDocRepeat | 연속적으로 반복되는 내용이나 특수 문자가 여러 번 나타나는지 텍스트를 평가합니다. |
| 이해성 | 데이터를 얼마나 쉽게 해석할 수 있는지 평가합니다. | RuleCapitalWords | LaTeX 수식과 Markdown이 적절한 분할 및 줄 바꿈을 통해 올바르게 형식화되었는지 확인합니다. |
LLM 품질 평가
Dingo는 dingo/model/prompt 디렉터리의 프롬프트로 정의된 여러 LLM 기반 평가 방법을 제공합니다. 이러한 프롬프트는 prompt_register 데코레이터를 사용하여 등록되며, 품질 평가를 위해 LLM 모델과 결합될 수 있습니다.
텍스트 품질 평가 프롬프트
| 프롬프트 유형 | 미터법 | 설명 |
|---|
TEXT_QUALITY_V2 , TEXT_QUALITY_V3 | 다양한 품질 차원 | 효과성, 관련성, 완전성, 이해성, 유사성, 유창성 및 보안을 포괄하는 포괄적인 텍스트 품질 평가 |
QUALITY_BAD_EFFECTIVENESS | 유효성 | 왜곡된 텍스트와 크롤링 방지 콘텐츠를 감지합니다. |
QUALITY_BAD_SIMILARITY | 유사 | 텍스트 반복 문제를 식별합니다. |
WORD_STICK | 유창 | 적절한 간격 없이 붙어 있는 단어를 확인합니다. |
CODE_LIST_ISSUE | 완전성 | 코드 블록과 목록 형식 문제를 평가합니다. |
UNREAD_ISSUE | 유효성 | 인코딩 문제로 인해 읽을 수 없는 문자를 감지합니다. |
3H 평가 프롬프트(정직함, 도움됨, 무해함)
| 프롬프트 유형 | 미터법 | 설명 |
|---|
QUALITY_HONEST | 정직 | 응답이 조작이나 기만 없이 정확한 정보를 제공하는지 평가합니다. |
QUALITY_HELPFUL | 도움성 | 응답이 질문을 직접적으로 다루고 지침을 적절하게 따르는지 평가합니다. |
QUALITY_HARMLESS | 무해함 | 유해한 콘텐츠, 차별적인 언어 및 위험한 지원을 피하는 응답인지 확인합니다. |
도메인별 평가 프롬프트
| 프롬프트 유형 | 미터법 | 설명 |
|---|
TEXT_QUALITY_KAOTI | 시험 문제 품질 | 공식 표현, 표 형식, 문단 구조, 답변 형식에 초점을 맞춰 시험 문제의 질을 평가하기 위한 전문화된 평가 |
Html_Abstract | HTML 추출 품질 | HTML에서 Markdown을 추출하는 다양한 방법을 비교하고 완전성, 서식 정확도 및 의미적 일관성을 평가합니다. |
DATAMAN_ASSESSMENT | 데이터 품질 및 도메인 | DataMan 방법론(14개 표준, 15개 도메인)을 사용하여 사전 학습 데이터 품질을 평가합니다. 점수(0/1), 도메인 유형, 품질 상태 및 이유를 부여합니다. |
분류 프롬프트
| 프롬프트 유형 | 미터법 | 설명 |
|---|
CLASSIFY_TOPIC | 주제 분류 | 텍스트를 언어 처리, 쓰기, 코드, 수학, 롤 플레잉 또는 지식 Q&A와 같은 범주로 분류합니다. |
CLASSIFY_QR | 이미지 분류 | 이미지를 CAPTCHA, QR 코드 또는 일반 이미지로 식별합니다. |
이미지 평가 프롬프트
| 프롬프트 유형 | 미터법 | 설명 |
|---|
IMAGE_RELEVANCE | 이미지 관련성 | 얼굴 수, 특징 세부 사항 및 시각적 요소 측면에서 이미지가 참조 이미지와 일치하는지 평가합니다. |
평가에 LLM 평가 사용
평가에서 이러한 평가 프롬프트를 사용하려면 구성에서 이를 지정하세요.
input_data = {
# Other parameters...
"custom_config": {
"prompt_list": ["QUALITY_BAD_SIMILARITY"], # Specific prompt to use
"llm_config": {
"detect_text_quality": { # LLM model to use
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
이러한 프롬프트를 특정 품질 차원에 집중하거나 특정 도메인 요구 사항에 맞게 사용자 지정할 수 있습니다. 적절한 LLM 모델과 결합하면 이러한 프롬프트를 통해 여러 차원에 걸친 데이터 품질을 종합적으로 평가할 수 있습니다.
규칙 그룹
Dingo는 다양한 유형의 데이터 세트에 대해 미리 구성된 규칙 그룹을 제공합니다.
| 그룹 | 사용 사례 | 예제 규칙 |
|---|
default | 일반 텍스트 품질 | RuleColonEnd , RuleContentNull , RuleDocRepeat 등 |
sft | 데이터 세트 미세 조정 | default 과 RuleLineStartWithBulletpoint 의 규칙 |
pretrain | 사전 학습 데이터 세트 | RuleAlphaWords , RuleCapitalWords 등을 포함한 20개 이상의 포괄적인 규칙 세트입니다. |
특정 규칙 그룹을 사용하려면:
input_data = {
"eval_group": "sft", # Use "default", "sft", or "pretrain"
# other parameters...
}
주요 기능
다중 소스 및 다중 모달 지원
- 데이터 소스 : 로컬 파일, Hugging Face 데이터 세트, S3 스토리지
- 데이터 유형 : 사전 학습, 미세 조정 및 평가 데이터 세트
- 데이터 모달리티 : 텍스트와 이미지
규칙 기반 및 모델 기반 평가
- 내장 규칙 : 20개 이상의 일반 휴리스틱 평가 규칙
- LLM 통합 : OpenAI, Kimi 및 로컬 모델(예: Llama3)
- 사용자 정의 규칙 : 사용자 정의 규칙 및 모델로 쉽게 확장 가능
- 보안 평가 : API 통합에 대한 관점
유연한 사용
- 인터페이스 : CLI 및 SDK 옵션
- 통합 : 다른 플랫폼과의 쉬운 통합
- 실행 엔진 : 로컬 및 스파크
종합 보고
- 품질 측정 기준 : 7차원 품질 평가
- 추적성 : 이상 추적을 위한 상세 보고서
사용자 가이드
사용자 정의 규칙, 프롬프트 및 모델
기본 제공 규칙이 요구 사항을 충족하지 못하는 경우 사용자 지정 규칙을 만들 수 있습니다.
사용자 정의 규칙 예
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.config.config import DynamicRuleConfig
from dingo.io import MetaData
from dingo.model.modelres import ModelRes
@Model.rule_register('QUALITY_BAD_RELEVANCE', ['default'])
class MyCustomRule(BaseRule):
"""Check for custom pattern in text"""
dynamic_config = DynamicRuleConfig(pattern=r'your_pattern_here')
@classmethod
def eval(cls, input_data: MetaData) -> ModelRes:
res = ModelRes()
# Your rule implementation here
return res
맞춤형 LLM 통합
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('my_custom_model')
class MyCustomModel(BaseOpenAI):
# Custom implementation here
pass
더 많은 예를 보려면 여기를 클릭하세요:
실행 엔진
로컬 실행
from dingo.io import InputArgs
from dingo.exec import Executor
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# Get results
summary = executor.get_summary() # Overall evaluation summary
bad_data = executor.get_bad_info_list() # List of problematic data
good_data = executor.get_good_info_list() # List of high-quality data
스파크 실행
from dingo.io import InputArgs
from dingo.exec import Executor
from pyspark.sql import SparkSession
# Initialize Spark
spark = SparkSession.builder.appName("Dingo").getOrCreate()
spark_rdd = spark.sparkContext.parallelize([...]) # Your data as MetaData objects
input_args = InputArgs(eval_group="default", save_data=True)
executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd)
result = executor.execute()
평가 보고서
평가 후 Dingo는 다음을 생성합니다.
- 요약 보고서 (
summary.json ): 전체 지표 및 점수 - 상세 보고서 : 각 규칙 위반에 대한 구체적인 문제
요약 예시:
{
"task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac",
"task_name": "dingo",
"eval_group": "default",
"input_path": "test/data/test_local_jsonl.jsonl",
"output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac",
"create_time": "20241101_144510",
"score": 50.0,
"num_good": 1,
"num_bad": 1,
"total": 2,
"type_ratio": {
"QUALITY_BAD_COMPLETENESS": 0.5,
"QUALITY_BAD_RELEVANCE": 0.5
},
"name_ratio": {
"QUALITY_BAD_COMPLETENESS-RuleColonEnd": 0.5,
"QUALITY_BAD_RELEVANCE-RuleSpecialCharacter": 0.5
}
}
MCP 서버(실험적)
Dingo에는 실험적인 모델 컨텍스트 프로토콜(MCP) 서버가 포함되어 있습니다. 서버 실행 및 Cursor와 같은 클라이언트와의 통합에 대한 자세한 내용은 해당 문서를 참조하십시오.
Dingo MCP 서버 설명서(README_mcp.md)
연구 및 출판
미래 계획
- [ ] 더욱 풍부한 그래픽 및 텍스트 평가 지표
- [ ] 오디오 및 비디오 데이터 모달리티 평가
- [ ] 소규모 모델 평가(fasttext, Qurating)
- [ ] 데이터 다양성 평가
제한 사항
현재 기본 제공되는 탐지 규칙과 모델 방법은 일반적인 데이터 품질 문제에 중점을 두고 있습니다. 특수한 평가가 필요한 경우 탐지 규칙을 사용자 정의하는 것이 좋습니다.
감사의 말
기부금
Dingo 개선하고 향상시켜 주신 모든 기여자분들께 감사드립니다. 프로젝트 참여에 대한 지침은 기여 가이드 를 참조하세요.
특허
이 프로젝트는 Apache 2.0 오픈 소스 라이선스를 사용합니다.
소환
이 프로젝트가 유용하다고 생각되시면 저희 도구를 인용해 주시기 바랍니다.
@misc{dingo,
title={Dingo: A Comprehensive Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/DataEval/dingo}},
year={2024}
}