A
securityA
licenseA
qualityMiro MCP server, exposing all functionalities available in official Miro SDK.
Last updated -
97
66
5
TypeScript
Apache 2.0
Dingo — это инструмент оценки качества данных, который помогает вам автоматически обнаруживать проблемы с качеством данных в ваших наборах данных. Dingo предоставляет множество встроенных правил и методов оценки моделей, а также поддерживает пользовательские методы оценки. Dingo поддерживает часто используемые текстовые наборы данных и мультимодальные наборы данных, включая наборы данных предварительной подготовки, наборы данных тонкой настройки и наборы данных оценки. Кроме того, Dingo поддерживает несколько методов использования, включая локальный CLI и SDK, что упрощает интеграцию в различные платформы оценки, такие как OpenCompass .
Пример config_gpt.json :
После оценки (с save_data=True ) будет автоматически сгенерирована страница frontend. Чтобы вручную запустить frontend:
Где output_directory содержит результаты оценки с файлом summary.json .
Попробуйте Dingo в нашей онлайн-демонстрации: (Обнимающее лицо)🤗
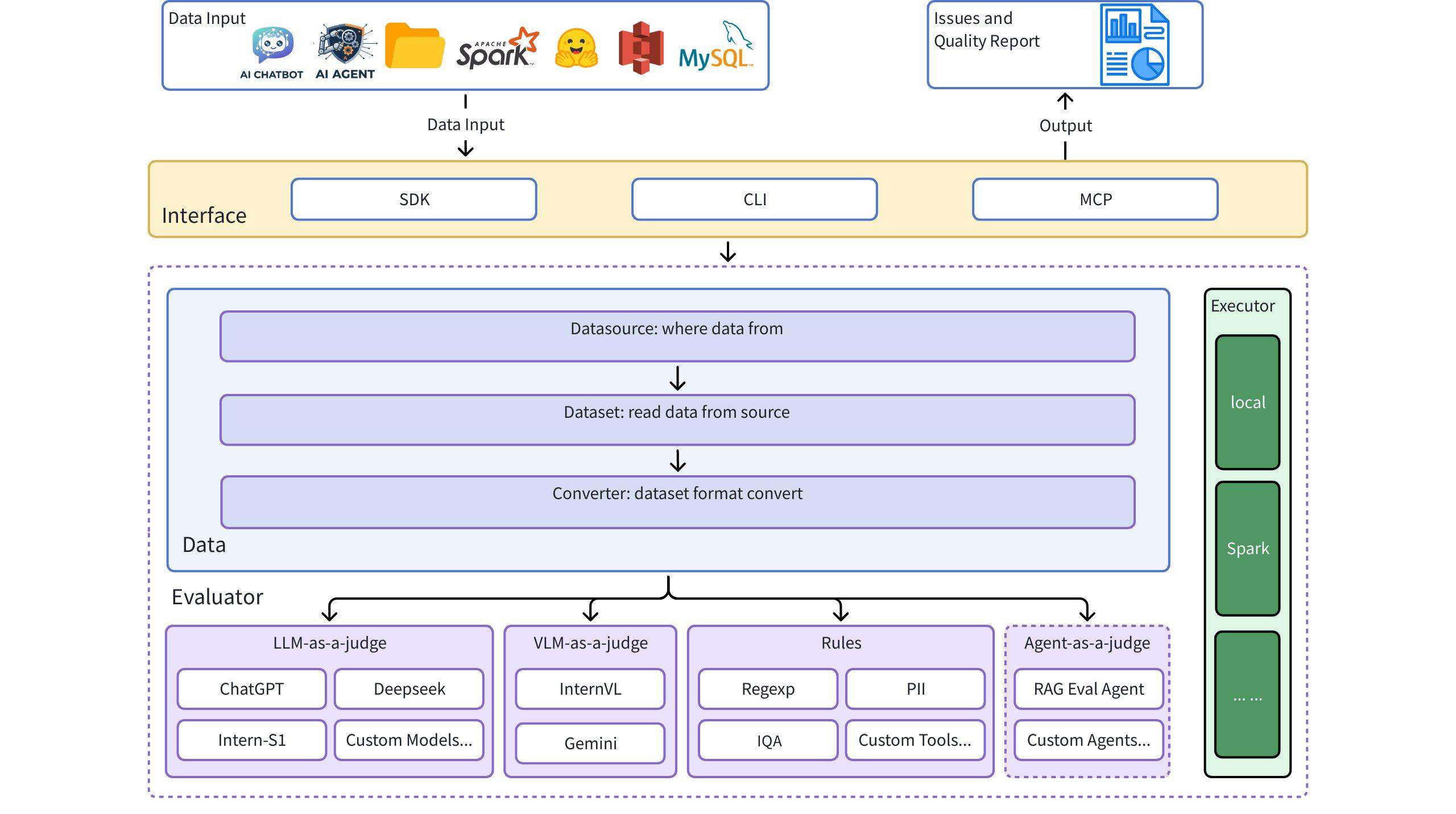
Dingo классифицирует проблемы качества данных по 7 измерениям метрик качества. Каждое измерение можно оценить с помощью как методов на основе правил, так и подсказок LLM:
| Метрика качества | Описание | Примеры правил | Примеры подсказок LLM |
|---|---|---|---|
| ПОЛНОТА | Проверяет, являются ли данные неполными или отсутствуют | RuleColonEnd , RuleContentNull | Проверяет, заканчивается ли текст двоеточием или многоточием, содержит ли он непарные скобки или отсутствуют ли в нем критические компоненты. |
| ЭФФЕКТИВНОСТЬ | Проверяет, являются ли данные значимыми и правильно ли они отформатированы. | RuleAbnormalChar , RuleHtmlEntity , RuleSpecialCharacter | Обнаруживает искаженный текст, слова, слипшиеся без пробелов, и текст с отсутствующими знаками препинания. |
| БЕГЛОСТЬ | Проверяет грамматическую правильность текста и его естественность при чтении | RuleAbnormalNumber , RuleNoPunc , RuleWordStuck | Определяет слишком длинные слова, фрагменты текста без знаков препинания или контент с хаотичным порядком чтения |
| АКТУАЛЬНОСТЬ | Обнаруживает нерелевантный контент в данных | Варианты RuleHeadWord для разных языков | Проверяет на наличие нерелевантной информации, такой как сведения о цитатах, верхние/нижние колонтитулы, маркеры сущностей, HTML-теги |
| БЕЗОПАСНОСТЬ | Выявляет конфиденциальную информацию или конфликты ценностей | RuleIDCard , RuleUnsafeWords | Проверяет персональные данные и контент, связанный с азартными играми, порнографией, политическими вопросами |
| СХОДСТВО | Обнаруживает повторяющийся или очень похожий контент | RuleDocRepeat | Оценивает текст на предмет последовательно повторяющегося содержимого или многократного использования специальных символов. |
| ПОНЯТНОСТЬ | Оценивает, насколько легко интерпретировать данные | RuleCapitalWords | Обеспечивает правильное форматирование формул LaTeX и Markdown с правильной сегментацией и переносами строк. |
Dingo предоставляет несколько методов оценки на основе LLM, определенных подсказками в каталоге dingo/model/prompt . Эти подсказки регистрируются с помощью декоратора prompt_register и могут быть объединены с моделями LLM для оценки качества:
| Тип подсказки | Метрическая | Описание |
|---|---|---|
TEXT_QUALITY_V2 , TEXT_QUALITY_V3 | Различные качественные параметры | Комплексная оценка качества текста, охватывающая эффективность, релевантность, полноту, понятность, схожесть, беглость и безопасность |
QUALITY_BAD_EFFECTIVENESS | Эффективность | Обнаруживает искаженный текст и антисканирующий контент |
QUALITY_BAD_SIMILARITY | Сходство | Выявляет проблемы повторения текста |
WORD_STICK | Беглость | Проверяет слова на наличие слипшихся слов без надлежащего интервала |
CODE_LIST_ISSUE | Полнота | Оценивает блоки кода и проблемы форматирования списков |
UNREAD_ISSUE | Эффективность | Обнаруживает нечитаемые символы из-за проблем с кодировкой |
| Тип подсказки | Метрическая | Описание |
|---|---|---|
QUALITY_HONEST | Честность | Оценивает, содержат ли ответы точную информацию без фальсификаций или обмана. |
QUALITY_HELPFUL | Полезность | Оценивает, отвечают ли ответы непосредственно на вопросы и следуют ли они соответствующим инструкциям |
QUALITY_HARMLESS | Безвредность | Проверяет, не содержат ли ответы вредоносного контента, дискриминационного языка и опасной помощи |
| Тип подсказки | Метрическая | Описание |
|---|---|---|
TEXT_QUALITY_KAOTI | Качество экзаменационных вопросов | Специализированная оценка качества экзаменационных вопросов, уделяющая особое внимание отображению формул, форматированию таблиц, структуре абзацев и форматированию ответов. |
Html_Abstract | Качество извлечения HTML | Сравнивает различные методы извлечения Markdown из HTML, оценивая полноту, точность форматирования и семантическую согласованность. |
DATAMAN_ASSESSMENT | Качество данных и домен | Оценивает качество данных до обучения с использованием методологии DataMan (14 стандартов, 15 доменов). Присваивает оценку (0/1), тип домена, статус качества и причину. |
| Тип подсказки | Метрическая | Описание |
|---|---|---|
CLASSIFY_TOPIC | Категоризация тем | Классифицирует текст по таким категориям, как языковая обработка, письмо, код, математика, ролевая игра или вопросы и ответы по знанию |
CLASSIFY_QR | Классификация изображений | Распознает изображения как CAPTCHA, QR-код или обычные изображения |
| Тип подсказки | Метрическая | Описание |
|---|---|---|
IMAGE_RELEVANCE | Релевантность изображения | Оценивает, соответствует ли изображение эталонному изображению по количеству лиц, деталям и визуальным элементам. |
Чтобы использовать эти подсказки для оценки в своих оценках, укажите их в своей конфигурации:
Вы можете настроить эти подсказки, чтобы сосредоточиться на определенных измерениях качества или адаптироваться к определенным требованиям домена. В сочетании с соответствующими моделями LLM эти подсказки позволяют проводить комплексную оценку качества данных по нескольким измерениям.
Dingo предоставляет предварительно настроенные группы правил для различных типов наборов данных:
| Группа | Вариант использования | Примеры правил |
|---|---|---|
default | Общее качество текста | RuleColonEnd , RuleContentNull , RuleDocRepeat и т. д. |
sft | Тонкая настройка наборов данных | Правила по default плюс RuleLineStartWithBulletpoint |
pretrain | Наборы данных для предварительного обучения | Полный набор из более чем 20 правил, включая RuleAlphaWords , RuleCapitalWords и т. д. |
Чтобы использовать определенную группу правил:
Если встроенные правила не соответствуют вашим требованиям, вы можете создать собственные:
Больше примеров смотрите в:
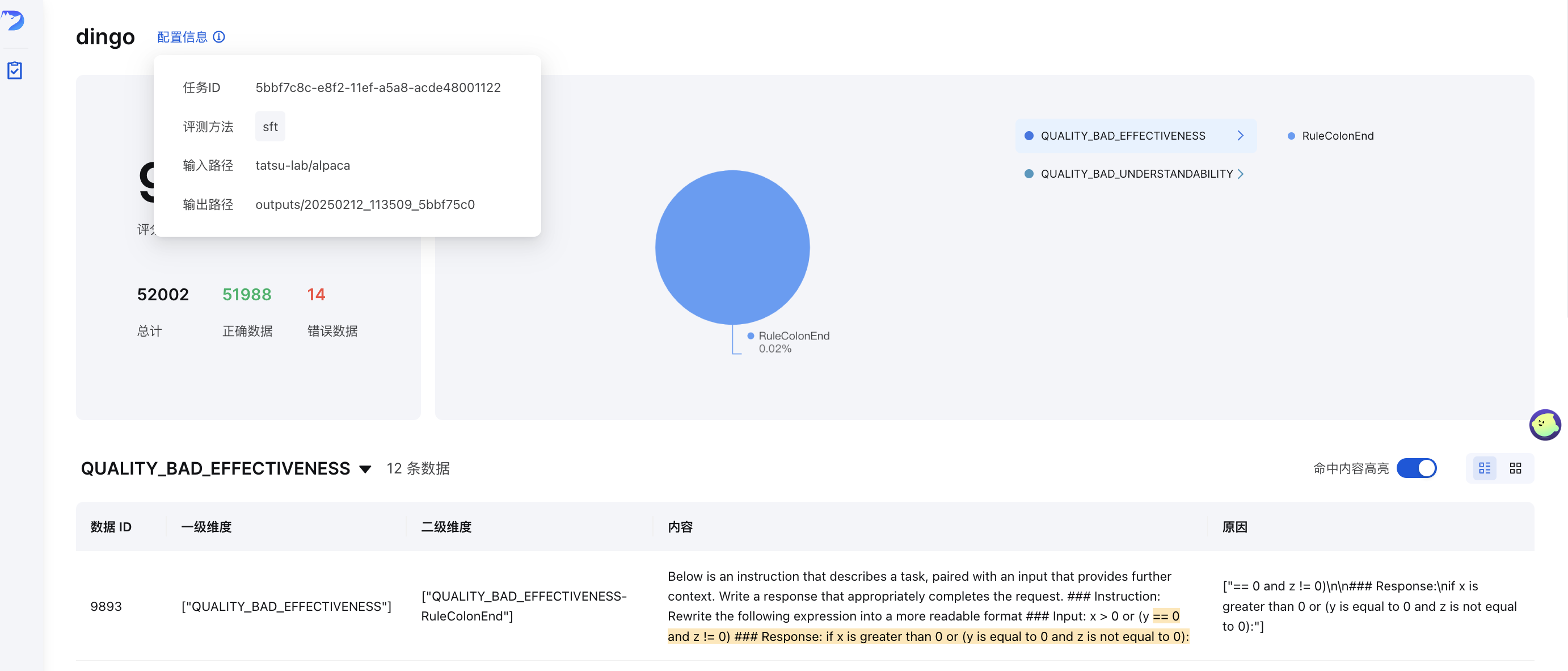
После оценки Dingo генерирует:
summary.json ): общие показатели и оценкиПример резюме:
Dingo включает экспериментальный сервер Model Context Protocol (MCP). Подробности о запуске сервера и его интеграции с такими клиентами, как Cursor, см. в специальной документации:
Документация сервера Dingo MCP (README_mcp.md)
Текущие встроенные правила обнаружения и методы модели фокусируются на общих проблемах качества данных. Для специализированных потребностей оценки мы рекомендуем настраивать правила обнаружения.
Мы ценим всех участников за их усилия по улучшению и совершенствованию Dingo . Пожалуйста, обратитесь к Руководству по внесению вклада для получения рекомендаций по внесению вклада в проект.
В этом проекте используется лицензия Apache 2.0 Open Source .
Если вы считаете этот проект полезным, пожалуйста, рассмотрите возможность цитирования нашего инструмента:
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/DataEval/dingo'
If you have feedback or need assistance with the MCP directory API, please join our Discord server