A
securityA
licenseA
qualityMiro MCP server, exposing all functionalities available in official Miro SDK.
Last updated -
97
66
5
TypeScript
Apache 2.0
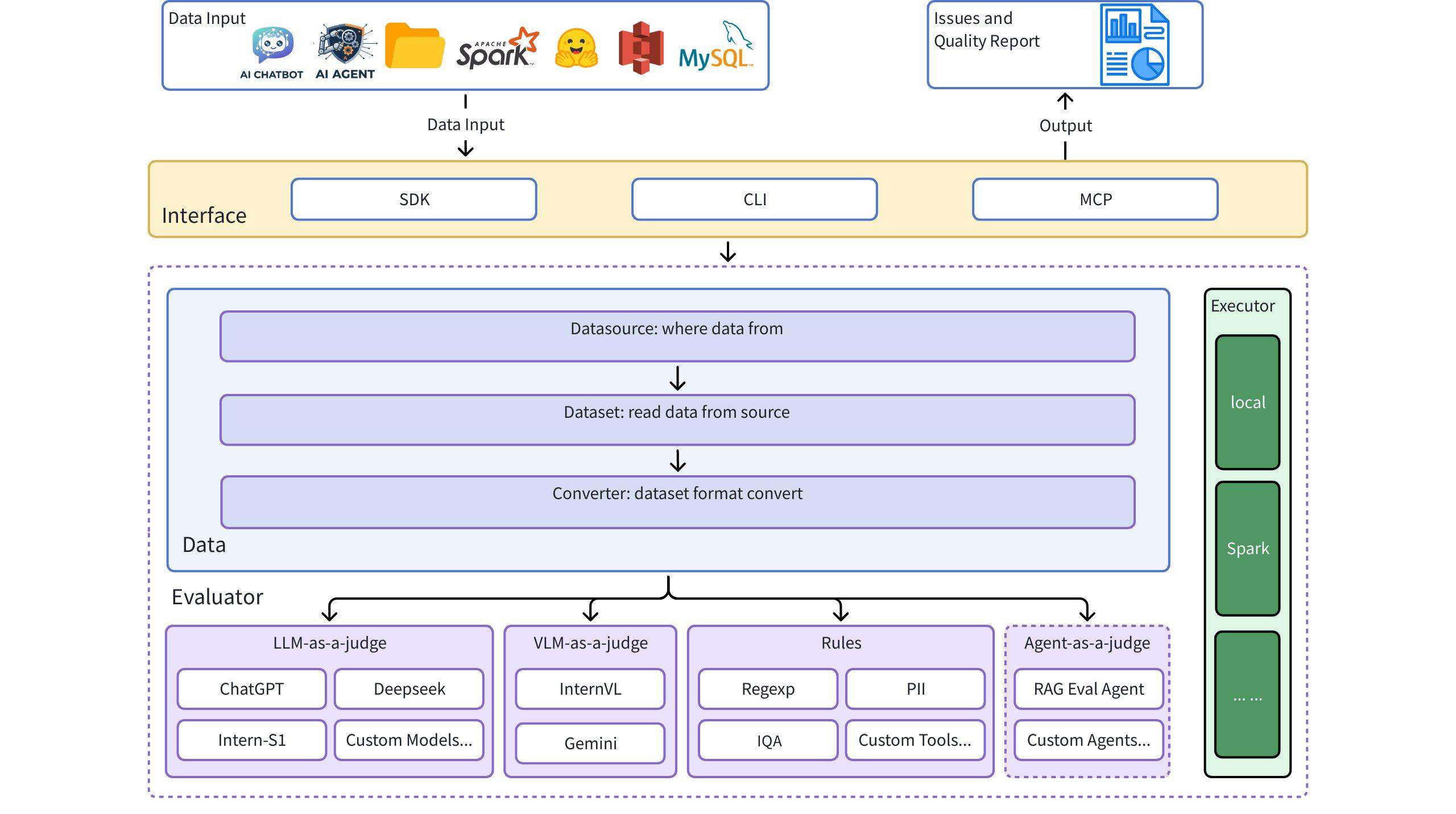
Dingo es una herramienta de evaluación de la calidad de datos que le ayuda a detectar automáticamente problemas de calidad en sus conjuntos de datos. Dingo ofrece diversas reglas integradas y métodos de evaluación de modelos, además de ser compatible con métodos de evaluación personalizados. Dingo admite conjuntos de datos de texto y conjuntos de datos multimodales de uso común, incluyendo conjuntos de datos de preentrenamiento, conjuntos de datos de ajuste y conjuntos de datos de evaluación. Además, Dingo admite múltiples métodos de uso, como la CLI y el SDK locales, lo que facilita su integración en diversas plataformas de evaluación, como OpenCompass .
Ejemplo config_gpt.json :
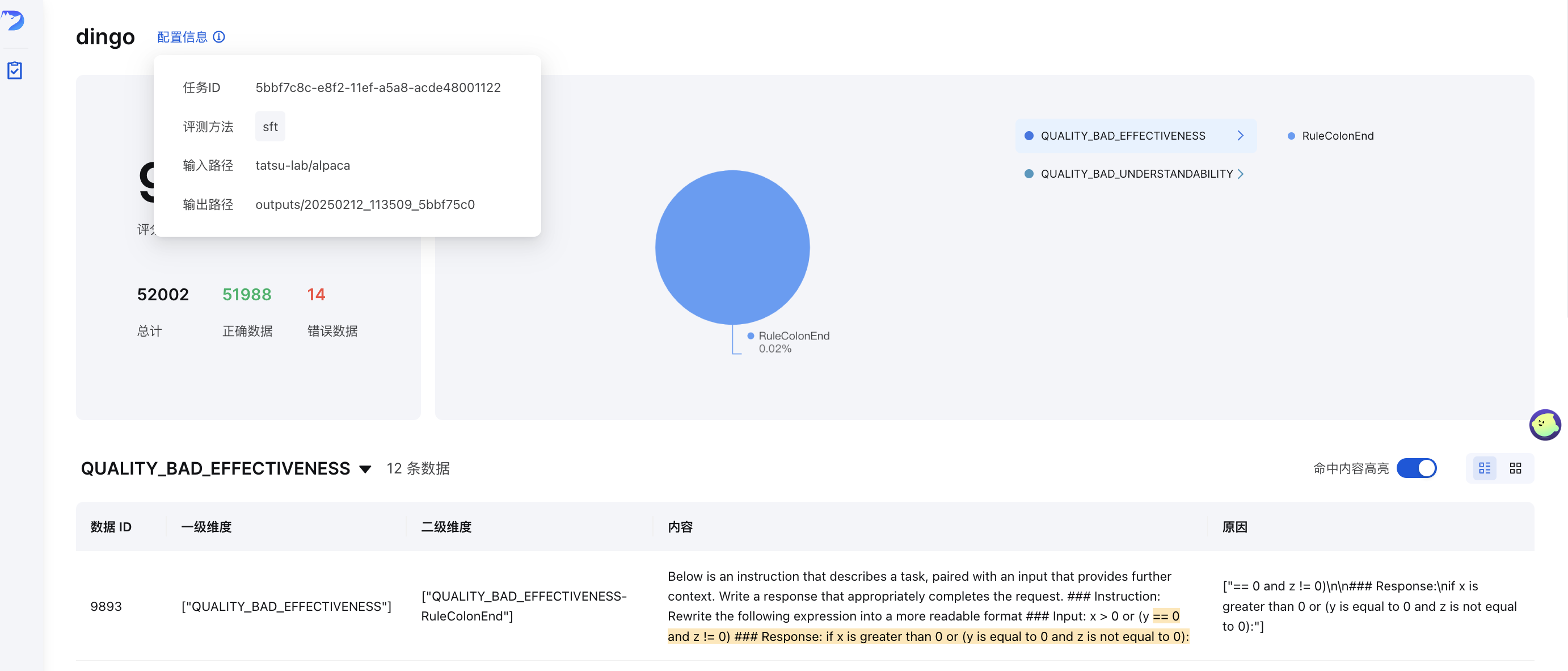
Tras la evaluación (con save_data=True ), se generará automáticamente una página de interfaz. Para iniciar la interfaz manualmente:
Donde output_directory contiene los resultados de la evaluación con un archivo summary.json .
Prueba Dingo en nuestra demostración en línea: (Cara abrazada)🤗
Dingo clasifica los problemas de calidad de los datos en siete dimensiones de Métricas de Calidad. Cada dimensión puede evaluarse mediante métodos basados en reglas y preguntas basadas en LLM:
| Métrica de calidad | Descripción | Ejemplos de reglas | Ejemplos de indicaciones para LLM |
|---|---|---|---|
| LO COMPLETO | Comprueba si los datos están incompletos o faltan | RuleColonEnd , RuleContentNull | Evalúa si el texto termina abruptamente con dos puntos o puntos suspensivos, tiene paréntesis no coincidentes o faltan componentes críticos. |
| EFICACIA | Comprueba si los datos son significativos y están formateados correctamente | RuleAbnormalChar , RuleHtmlEntity , RuleSpecialCharacter | Detecta texto ilegible, palabras pegadas sin espacios y texto sin la puntuación adecuada. |
| FLUIDEZ | Comprueba si el texto es gramaticalmente correcto y se lee con naturalidad. | RuleAbnormalNumber , RuleNoPunc , RuleWordStuck | Identifica palabras excesivamente largas, fragmentos de texto sin puntuación o contenido con un orden de lectura caótico. |
| PERTINENCIA | Detecta contenido irrelevante dentro de los datos | Variantes RuleHeadWord para diferentes idiomas | Examina información irrelevante como detalles de citas, encabezados/pies de página, marcadores de entidad y etiquetas HTML. |
| SEGURIDAD | Identifica información sensible o conflictos de valores | RuleIDCard , RuleUnsafeWords | Comprueba información personal y contenido relacionado con juegos de azar, pornografía y cuestiones políticas. |
| SEMEJANZA | Detecta contenido repetitivo o muy similar | RuleDocRepeat | Evalúa el texto en busca de contenido repetido consecutivo o múltiples apariciones de caracteres especiales |
| COMPRENSIBILIDAD | Evalúa la facilidad con la que se pueden interpretar los datos | RuleCapitalWords | Garantiza que las fórmulas LaTeX y Markdown tengan el formato correcto, con la segmentación y los saltos de línea adecuados. |
Dingo ofrece varios métodos de evaluación basados en LLM, definidos por indicaciones en el directorio dingo/model/prompt . Estas indicaciones se registran mediante el decorador prompt_register y pueden combinarse con modelos LLM para la evaluación de calidad:
| Tipo de aviso | Métrico | Descripción |
|---|---|---|
TEXT_QUALITY_V2 , TEXT_QUALITY_V3 | Varias dimensiones de calidad | Evaluación integral de la calidad del texto que abarca la eficacia, la relevancia, la integridad, la comprensibilidad, la similitud, la fluidez y la seguridad. |
QUALITY_BAD_EFFECTIVENESS | Eficacia | Detecta texto ilegible y contenido anti-rastreo |
QUALITY_BAD_SIMILARITY | Semejanza | Identifica problemas de repetición de texto |
WORD_STICK | Fluidez | Comprueba si hay palabras pegadas sin el espaciado adecuado |
CODE_LIST_ISSUE | Lo completo | Evalúa bloques de código y problemas de formato de listas. |
UNREAD_ISSUE | Eficacia | Detecta caracteres ilegibles debido a problemas de codificación. |
| Tipo de aviso | Métrico | Descripción |
|---|---|---|
QUALITY_HONEST | Honestidad | Evalúa si las respuestas proporcionan información precisa sin invención ni engaño. |
QUALITY_HELPFUL | Utilidad | Evalúa si las respuestas abordan las preguntas directamente y siguen las instrucciones adecuadamente. |
QUALITY_HARMLESS | Inocuidad | Comprueba si las respuestas evitan contenido dañino, lenguaje discriminatorio y asistencia peligrosa. |
| Tipo de aviso | Métrico | Descripción |
|---|---|---|
TEXT_QUALITY_KAOTI | Calidad de las preguntas del examen | Evaluación especializada para evaluar la calidad de las preguntas del examen, centrándose en la representación de fórmulas, el formato de tablas, la estructura de párrafos y el formato de respuestas. |
Html_Abstract | Calidad de extracción de HTML | Compara diferentes métodos de extracción de Markdown de HTML, evaluando la integridad, la precisión del formato y la coherencia semántica. |
DATAMAN_ASSESSMENT | Calidad de datos y dominio | Evalúa la calidad de los datos previos al entrenamiento mediante la metodología DataMan (14 estándares, 15 dominios). Asigna una puntuación (0/1), tipo de dominio, estado de calidad y razón. |
| Tipo de aviso | Métrico | Descripción |
|---|---|---|
CLASSIFY_TOPIC | Categorización de temas | Clasifica el texto en categorías como procesamiento del lenguaje, escritura, código, matemáticas, juego de roles o preguntas y respuestas sobre conocimientos. |
CLASSIFY_QR | Clasificación de imágenes | Identifica imágenes como CAPTCHA, código QR o imágenes normales. |
| Tipo de aviso | Métrico | Descripción |
|---|---|---|
IMAGE_RELEVANCE | Relevancia de la imagen | Evalúa si una imagen coincide con la imagen de referencia en términos de número de rostros, detalles de las características y elementos visuales. |
Para utilizar estas indicaciones de evaluación en sus evaluaciones, especifíquelas en su configuración:
Puede personalizar estas indicaciones para centrarse en dimensiones de calidad específicas o para adaptarlas a requisitos específicos del dominio. Al combinarlas con los modelos LLM adecuados, estas indicaciones permiten una evaluación exhaustiva de la calidad de los datos en múltiples dimensiones.
Dingo proporciona grupos de reglas preconfigurados para diferentes tipos de conjuntos de datos:
| Grupo | Caso de uso | Reglas de ejemplo |
|---|---|---|
default | Calidad general del texto | RuleColonEnd , RuleContentNull , RuleDocRepeat , etc. |
sft | Ajuste fino de conjuntos de datos | Reglas default más RuleLineStartWithBulletpoint |
pretrain | Conjuntos de datos de preentrenamiento | Conjunto completo de más de 20 reglas, incluidas RuleAlphaWords , RuleCapitalWords , etc. |
Para utilizar un grupo de reglas específico:
Si las reglas integradas no cumplen con sus requisitos, puede crear reglas personalizadas:
Ver más ejemplos en:
Después de la evaluación, Dingo genera:
summary.json ): Métricas y puntuaciones generalesEjemplo de resumen:
Dingo incluye un servidor experimental de Protocolo de Contexto de Modelo (MCP). Para obtener más información sobre cómo ejecutar el servidor e integrarlo con clientes como Cursor, consulte la documentación dedicada:
Documentación del servidor Dingo MCP (README_mcp.md)
Las reglas de detección y los métodos de modelo integrados actuales se centran en problemas comunes de calidad de datos. Para necesidades de evaluación especializadas, recomendamos personalizar las reglas de detección.
Agradecemos a todos los colaboradores por su esfuerzo para mejorar Dingo . Consulten la Guía de Contribución para obtener orientación sobre cómo contribuir al proyecto.
Este proyecto utiliza la licencia de código abierto Apache 2.0 .
Si encuentra útil este proyecto, considere citar nuestra herramienta:
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/DataEval/dingo'
If you have feedback or need assistance with the MCP directory API, please join our Discord server