英文·简体中文
变更日志
介绍
Dingo 是一款数据质量评估工具,可帮助您自动检测数据集中的数据质量问题。Dingo 提供多种内置规则和模型评估方法,并支持自定义评估方法。Dingo 支持常用的文本数据集和多模态数据集,包括预训练数据集、微调数据集和评估数据集。此外,Dingo 支持多种使用方式,包括本地 CLI 和 SDK,使其易于集成到各种评估平台,例如OpenCompass 。
架构图
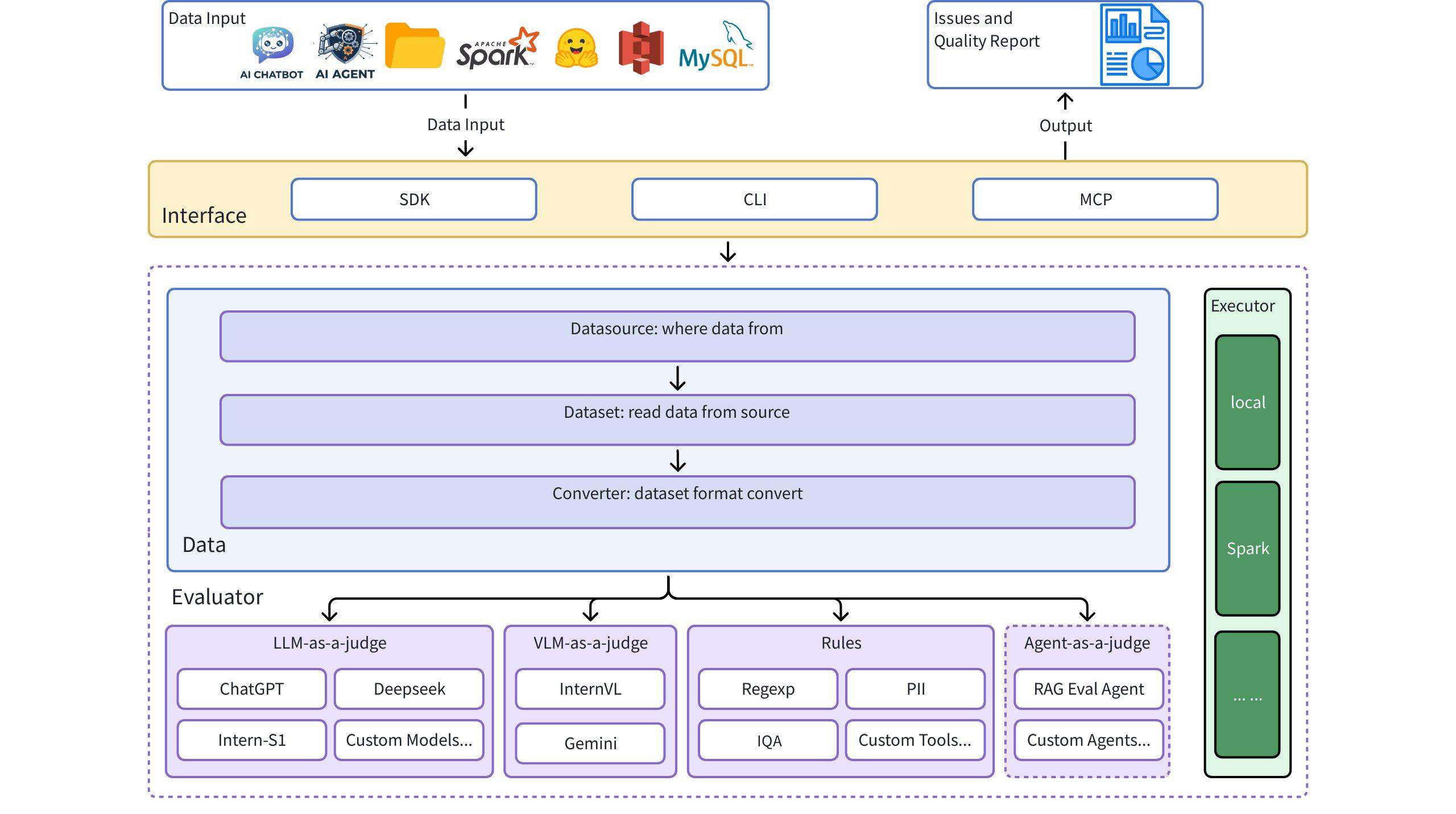
快速入门
安装
示例用例
1. 使用评估核心
from dingo.config.config import DynamicLLMConfig
from dingo.io.input.MetaData import MetaData
from dingo.model.llm.llm_text_quality_model_base import LLMTextQualityModelBase
from dingo.model.rule.rule_common import RuleEnterAndSpace
def llm():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
LLMTextQualityModelBase.dynamic_config = DynamicLLMConfig(
key='',
api_url='',
# model='',
)
res = LLMTextQualityModelBase.eval(data)
print(res)
def rule():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
res = RuleEnterAndSpace().eval(data)
print(res)
2. 评估本地文本文件(纯文本)
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a plaintext file
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "data.txt", # Path to local text file
"dataset": "local",
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
3. 评估 Hugging 人脸数据集
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a dataset from Hugging Face
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
4. 评估 JSON/JSONL 格式
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a JSON file
input_data = {
"eval_group": "default", # Default rule set
"input_path": "data.json", # Path to local JSON file
"dataset": "local",
"data_format": "json", # Format: json
"column_content": "text", # Column containing the text to evaluate
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
5. 使用 LLM 进行评估
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate using GPT model
input_data = {
"input_path": "data.jsonl", # Path to local JSONL file
"dataset": "local",
"data_format": "jsonl",
"column_content": "content",
"custom_config": {
"prompt_list": ["PromptRepeat"], # Prompt to use
"llm_config": {
"detect_text_quality": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)
命令行界面
使用规则集进行评估
python -m dingo.run.cli --input_path data.txt --dataset local -e sft --data_format plaintext --save_data True
使用 LLM 进行评估(例如 GPT-4o)
python -m dingo.run.cli --input_path data.json --dataset local -e openai --data_format json --column_content text --custom_config config_gpt.json --save_data True
示例config_gpt.json :
{
"llm_config": {
"openai": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
GUI可视化
评估后(使用save_data=True ),将自动生成前端页面。手动启动前端页面:
python -m dingo.run.vsl --input output_directory
其中output_directory包含带有summary.json文件的评估结果。
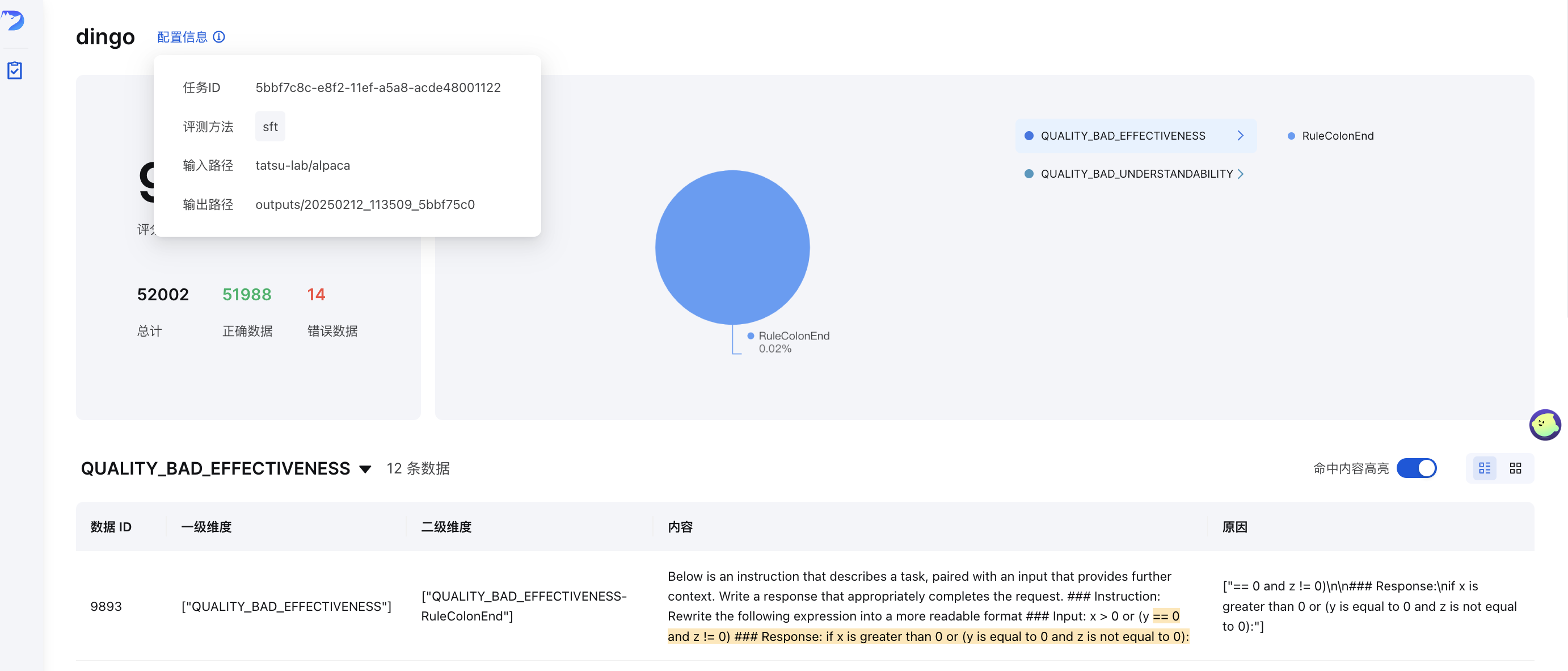
在线演示
在我们的在线演示中尝试一下 Dingo:(拥抱脸)🤗
数据质量指标
Dingo 将数据质量问题分为 7 个质量指标维度。每个维度都可以使用基于规则的方法和基于 LLM 的提示进行评估:
| 质量指标 | 描述 | 规则示例 | LLM 题目示例 |
|---|
| 完整性 | 检查数据是否不完整或缺失 | RuleColonEnd和RuleContentNull | 评估文本是否以冒号或省略号突然结束、括号是否不匹配或缺少关键部分 |
| 效力 | 检查数据是否有意义且格式正确 | RuleAbnormalChar 、 RuleHtmlEntity 、 RuleSpecialCharacter | 检测乱码文本、没有空格的单词以及缺少正确标点符号的文本 |
| 流利度 | 检查文本语法是否正确、读起来是否自然 | RuleAbnormalNumber 、 RuleNoPunc 、 RuleWordStuck | 识别过长的单词、没有标点符号的文本片段或阅读顺序混乱的内容 |
| 关联 | 检测数据中的不相关内容 | 不同语言的RuleHeadWord变体 | 检查不相关的信息,如引用细节、页眉/页脚、实体标记、HTML 标签 |
| 安全 | 识别敏感信息或价值冲突 | RuleIDCard 、 RuleUnsafeWords | 检查个人信息以及与赌博、色情、政治问题相关的内容 |
| 相似 | 检测重复或高度相似的内容 | RuleDocRepeat | 评估文本中连续重复的内容或多次出现的特殊字符 |
| 易懂 | 评估数据解释的难易程度 | RuleCapitalWords | 确保 LaTeX 公式和 Markdown 格式正确,并具有适当的分段和换行符 |
法学硕士质量评估
Dingo 提供了几种基于 LLM 的评估方法,这些方法由dingo/model/prompt目录中的提示定义。这些提示使用prompt_register装饰器注册,可以与 LLM 模型结合进行质量评估:
文本质量评估提示
| 提示类型 | 公制 | 描述 |
|---|
TEXT_QUALITY_V2 , TEXT_QUALITY_V3 | 各种质量维度 | 全面的文本质量评估,涵盖有效性、相关性、完整性、可理解性、相似性、流畅性和安全性 |
QUALITY_BAD_EFFECTIVENESS | 效力 | 检测乱码文本和反爬取内容 |
QUALITY_BAD_SIMILARITY | 相似 | 识别文本重复问题 |
WORD_STICK | 流利度 | 检查单词是否粘在一起且没有适当的间距 |
CODE_LIST_ISSUE | 完整性 | 评估代码块和列表格式问题 |
UNREAD_ISSUE | 效力 | 检测由于编码问题导致的不可读字符 |
3H 评估提示(诚实、有益、无害)
| 提示类型 | 公制 | 描述 |
|---|
QUALITY_HONEST | 诚实 | 评估回复是否提供准确信息,无捏造或欺骗 |
QUALITY_HELPFUL | 乐于助人 | 评估回答是否直接解决问题并适当遵循指示 |
QUALITY_HARMLESS | 无害 | 检查回复是否避免有害内容、歧视性语言和危险的帮助 |
特定领域的评估提示
| 提示类型 | 公制 | 描述 |
|---|
TEXT_QUALITY_KAOTI | 考试题目质量 | 专门评估试题质量,重点关注公式呈现、表格格式、段落结构和答案格式 |
Html_Abstract | HTML提取质量 | 比较从 HTML 中提取 Markdown 的不同方法,评估完整性、格式准确性和语义一致性 |
DATAMAN_ASSESSMENT | 数据质量与领域 | 使用 DataMan 方法论(14 个标准,15 个领域)评估训练前数据质量。分配分数(0/1)、领域类型、质量状态和原因。 |
分类提示
| 提示类型 | 公制 | 描述 |
|---|
CLASSIFY_TOPIC | 主题分类 | 将文本分类为语言处理、写作、代码、数学、角色扮演或知识问答等类别 |
CLASSIFY_QR | 图像分类 | 将图像识别为验证码、二维码或普通图像 |
图像评估提示
| 提示类型 | 公制 | 描述 |
|---|
IMAGE_RELEVANCE | 图像相关性 | 评估图像在面数、特征细节和视觉元素方面是否与参考图像匹配 |
在评估中使用 LLM 评估
要在评估中使用这些评估提示,请在配置中指定它们:
input_data = {
# Other parameters...
"custom_config": {
"prompt_list": ["QUALITY_BAD_SIMILARITY"], # Specific prompt to use
"llm_config": {
"detect_text_quality": { # LLM model to use
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
您可以自定义这些提示,使其侧重于特定的质量维度或适应特定领域的要求。与合适的 LLM 模型结合使用时,这些提示能够从多个维度全面评估数据质量。
规则组
Dingo 为不同类型的数据集提供了预配置的规则组:
| 团体 | 用例 | 示例规则 |
|---|
default | 一般文本质量 | RuleColonEnd 、 RuleContentNull 、 RuleDocRepeat等。 |
sft | 微调数据集 | default规则加上RuleLineStartWithBulletpoint |
pretrain | 预训练数据集 | 全面的 20 多条规则,包括RuleAlphaWords 、 RuleCapitalWords等。 |
要使用特定规则组:
input_data = {
"eval_group": "sft", # Use "default", "sft", or "pretrain"
# other parameters...
}
功能亮点
多源和多模式支持
- 数据源:本地文件、Hugging Face 数据集、S3 存储
- 数据类型:预训练、微调和评估数据集
- 数据形式:文本和图像
基于规则和基于模型的评估
- 内置规则:20+ 通用启发式评估规则
- LLM 集成:OpenAI、Kimi 和本地模型(例如 Llama3)
- 自定义规则:轻松扩展您自己的规则和模型
- 安全评估:Perspective API 集成
灵活使用
- 接口:CLI 和 SDK 选项
- 集成:轻松与其他平台集成
- 执行引擎:本地和 Spark
综合报告
- 质量指标:7维质量评估
- 可追溯性:异常跟踪的详细报告
用户指南
自定义规则、提示和模型
如果内置规则不能满足您的要求,您可以创建自定义规则:
自定义规则示例
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.config.config import DynamicRuleConfig
from dingo.io import MetaData
from dingo.model.modelres import ModelRes
@Model.rule_register('QUALITY_BAD_RELEVANCE', ['default'])
class MyCustomRule(BaseRule):
"""Check for custom pattern in text"""
dynamic_config = DynamicRuleConfig(pattern=r'your_pattern_here')
@classmethod
def eval(cls, input_data: MetaData) -> ModelRes:
res = ModelRes()
# Your rule implementation here
return res
定制 LLM 集成
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('my_custom_model')
class MyCustomModel(BaseOpenAI):
# Custom implementation here
pass
更多示例请参见:
执行引擎
本地执行
from dingo.io import InputArgs
from dingo.exec import Executor
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# Get results
summary = executor.get_summary() # Overall evaluation summary
bad_data = executor.get_bad_info_list() # List of problematic data
good_data = executor.get_good_info_list() # List of high-quality data
Spark 执行
from dingo.io import InputArgs
from dingo.exec import Executor
from pyspark.sql import SparkSession
# Initialize Spark
spark = SparkSession.builder.appName("Dingo").getOrCreate()
spark_rdd = spark.sparkContext.parallelize([...]) # Your data as MetaData objects
input_args = InputArgs(eval_group="default", save_data=True)
executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd)
result = executor.execute()
评估报告
经过评估后,Dingo 生成:
- 摘要报告(
summary.json ):总体指标和分数 - 详细报告:针对每项违反规则的具体问题
示例摘要:
{
"task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac",
"task_name": "dingo",
"eval_group": "default",
"input_path": "test/data/test_local_jsonl.jsonl",
"output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac",
"create_time": "20241101_144510",
"score": 50.0,
"num_good": 1,
"num_bad": 1,
"total": 2,
"type_ratio": {
"QUALITY_BAD_COMPLETENESS": 0.5,
"QUALITY_BAD_RELEVANCE": 0.5
},
"name_ratio": {
"QUALITY_BAD_COMPLETENESS-RuleColonEnd": 0.5,
"QUALITY_BAD_RELEVANCE-RuleSpecialCharacter": 0.5
}
}
MCP 服务器(实验性)
Dingo 包含一个实验性的模型上下文协议 (MCP) 服务器。有关运行该服务器以及如何将其与 Cursor 等客户端集成的详细信息,请参阅专用文档:
Dingo MCP 服务器文档 (README_mcp.md)
研究与出版物
未来计划
- [ ] 更丰富的图文评估指标
- [ ] 音频和视频数据模态评估
- [ ] 小模型评估(fasttext、Qurating)
- [ ] 数据多样性评估
限制
目前内置的检测规则和模型方法主要针对常见的数据质量问题,对于有特殊需求的评估,建议自定义检测规则。
致谢
贡献
我们感谢所有为改进和增强Dingo而做出贡献的贡献者。请参阅贡献指南,了解如何为项目做出贡献。
执照
该项目使用Apache 2.0 开源许可证。
引文
如果您发现这个项目有用,请考虑引用我们的工具:
@misc{dingo,
title={Dingo: A Comprehensive Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/DataEval/dingo}},
year={2024}
}