
MCTS MCP 服务器
模型上下文协议 (MCP) 服务器公开了用于 AI 辅助分析和推理的高级贝叶斯蒙特卡洛树搜索 (MCTS) 引擎。
概述
此 MCP 服务器使 Claude 能够使用蒙特卡洛树搜索 (MCTS) 算法对主题、问题或文本输入进行深入的探索性分析。MCTS 算法采用贝叶斯方法系统地探索不同的角度和解释,并通过多次迭代得出富有洞察力的分析结果。
Related MCP server: mcp-server-tree-sitter
特征
贝叶斯 MCTS :使用概率方法在分析过程中平衡探索与利用
多次迭代分析:支持多次迭代思考,每次迭代进行多次模拟
状态持久性:记住同一聊天中的关键结果、不合适的方法和回合之间的先验
方法分类法:将产生的思想分为不同的哲学方法和家族
汤普森抽样:可以使用汤普森抽样或UCT进行节点选择
意外检测:识别令人惊讶或新颖的分析方向
意图分类:了解用户何时想要开始新的分析或继续之前的分析
用法
服务器以可复制粘贴的格式向您的 LLM 公开了许多工具,详见下文,以供系统提示。
当你要求 Claude 对某个主题或问题进行深入分析时,它将自动利用这些工具,使用 MCTS 算法和分析工具探索不同的角度。
工作原理
MCTS MCP 服务器使用本地推理方法,而不是尝试直接调用 LLM。这与 MCP 协议兼容,该协议旨在供 AI 助手(如 Claude)调用工具,而不是供工具自行调用 AI 模型。
当 Claude 要求服务器执行分析时,服务器:
使用问题初始化 MCTS 系统
使用 MCTS 算法运行多次探索迭代
为各种分析任务生成确定性响应
返回搜索过程中找到的最佳分析
安装
克隆存储库:
该设置使用 UV(Astral UV),它是 pip 的更快替代方案,可提供改进的依赖关系解析。
确保已安装 Python 3.10+
运行安装脚本:
./setup.sh这将:
如果尚未安装,请安装 UV
使用 UV 创建虚拟环境
使用 UV 安装所需的软件包
创建必要的状态目录
或者,您可以手动设置:
# Install UV if not already installed
curl -fsSL https://astral.sh/uv/install.sh | bash# Create and activate a virtual environment
uv venv .venv
source .venv/bin/activate
# Install dependencies
uv pip install -r requirements.txtClaude 桌面集成
与 Claude Desktop 集成:
从此存储库复制
claude_desktop_config.json的内容将其添加到您的 Claude Desktop 配置中(通常位于
~/.claude/claude_desktop_config.json)如果配置文件尚不存在,请创建它并添加该项目的
claude_desktop_config.json中的内容重启Claude桌面
示例配置:
{
"mcpServers": {
"MCTSServer": {
"command": "uv",
"args": [
"run",
"--directory", "/home/ty/Repositories/ai_workspace/mcts-mcp-server/src/mcts_mcp_server",
"server.py"
],
"env": {
"PYTHONPATH": "/home/ty/Repositories/ai_workspace/mcts-mcp-server"
}
}
}
}
确保更新路径以匹配系统上 MCTS MCP 服务器的位置。
建议的系统提示和更新工具(包括 Ollama 集成),即将以下块放置在项目说明中:
MCTS server and usage instructions:
MCTS server and usage instructions:
list_ollama_models() # Check what models are available
set_ollama_model("cogito:latest") # Set the model you want to use
initialize_mcts(question="Your question here", chat_id="unique_id") # Initialize analysis
run_mcts(iterations=1, simulations_per_iteration=5) # Run the analysis
After run_mcts is called it can take wuite a long time ie minutes to hours
- so you may discuss any ideas or questions or await user confirmation of the process finishing,
- then proceed to synthesis and analysis tools on resumption of chat.
## MCTS-MCP Tools Overview
### Core MCTS Tools:
- `initialize_mcts`: Start a new MCTS analysis with a specific question
- `run_mcts`: Run the MCTS algorithm for a set number of iterations/simulations
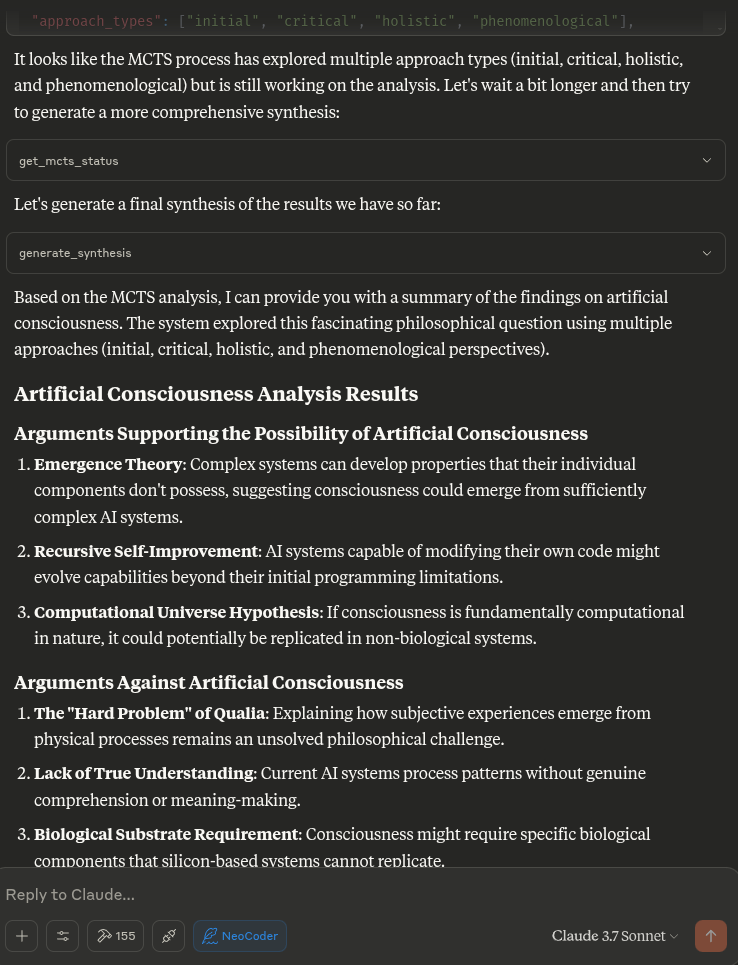
- `generate_synthesis`: Generate a final summary of the MCTS results
- `get_config`: View current MCTS configuration parameters
- `update_config`: Update MCTS configuration parameters
- `get_mcts_status`: Check the current status of the MCTS system
Default configuration prioritizes speed and exploration, but you can customize parameters like exploration_weight, beta_prior_alpha/beta, surprise_threshold.
## Configuration
You can customize the MCTS parameters in the config dictionary or through Claude's `update_config` tool. Key parameters include:
- `max_iterations`: Number of MCTS iterations to run
- `simulations_per_iteration`: Number of simulations per iteration
- `exploration_weight`: Controls exploration vs. exploitation balance (in UCT)
- `early_stopping`: Whether to stop early if a high-quality solution is found
- `use_bayesian_evaluation`: Whether to use Bayesian evaluation for node scores
- `use_thompson_sampling`: Whether to use Thompson sampling for selection
Articulating Specific Pathways:
Delving into the best_path nodes (using mcts_instance.get_best_path_nodes() if you have the instance) and examining the sequence of thought and content
at each step can provide a fascinating micro-narrative of how the core insight evolved.
Visualizing the tree (even a simplified version based on export_tree_summary) could also be illuminating and I will try to set up this feature.
Modifying Parameters: This is a great way to test the robustness of the finding or explore different "cognitive biases" of the system.
Increasing Exploration Weight: Might lead to more diverse, less obviously connected ideas.
Decreasing Exploration Weight: Might lead to deeper refinement of the initial dominant pathways.
Changing Priors (if Bayesian): You could bias the system towards certain approaches (e.g., increase alpha for 'pragmatic') to see how it influences the
outcome.
More Iterations/Simulations: Would allow for potentially deeper convergence or exploration of more niche pathways.
### Ollama Integration Tools:
- `list_ollama_models`: Show all available local Ollama models
- `set_ollama_model`: Select which Ollama model to use for MCTS
- `run_model_comparison`: Run the same MCTS process across multiple models
### Results Collection:
- Automatically stores results in `/home/ty/Repositories/ai_workspace/mcts-mcp-server/results`
- Organizes by model name and run ID
- Stores metrics, progress info, and final outputs
# MCTS Analysis Tools
This extension adds powerful analysis tools to the MCTS-MCP Server, making it easy to extract insights and understand results from your MCTS runs.
The MCTS Analysis Tools provide a suite of integrated functions to:
1. List and browse MCTS runs
2. Extract key concepts, arguments, and conclusions
3. Generate comprehensive reports
4. Compare results across different runs
5. Suggest improvements for better performance
## Available Run Analysis Tools
### Browsing and Basic Information
- `list_mcts_runs(count=10, model=None)`: List recent MCTS runs with key metadata
- `get_mcts_run_details(run_id)`: Get detailed information about a specific run
- `get_mcts_solution(run_id)`: Get the best solution from a run
### Analysis and Insights
- `analyze_mcts_run(run_id)`: Perform a comprehensive analysis of a run
- `get_mcts_insights(run_id, max_insights=5)`: Extract key insights from a run
- `extract_mcts_conclusions(run_id)`: Extract conclusions from a run
- `suggest_mcts_improvements(run_id)`: Get suggestions for improvement
### Reporting and Comparison
- `get_mcts_report(run_id, format='markdown')`: Generate a comprehensive report (formats: 'markdown', 'text', 'html')
- `get_best_mcts_runs(count=5, min_score=7.0)`: Get the best runs based on score
- `compare_mcts_runs(run_ids)`: Compare multiple runs to identify similarities and differences
## Usage Examples
# To list your recent MCTS runs:
list_mcts_runs()
# To get details about a specific run:
get_mcts_run_details('cogito:latest_1745979984')
### Extracting Insights
# To get key insights from a run:
get_mcts_insights(run_id='cogito:latest_1745979984')
### Generating Reports
# To generate a comprehensive markdown report:
get_mcts_report(run_id='cogito:latest_1745979984', format='markdown')
### Improving Results
# To get suggestions for improving a run:
suggest_mcts_improvements(run_id='cogito:latest_1745979984')
### Comparing Runs
To compare multiple runs:
compare_mcts_runs(['cogito:latest_1745979984', 'qwen3:0.6b_1745979584'])
## Understanding the Results
The analysis tools extract several key elements from MCTS runs:
1. **Key Concepts**: The core ideas and frameworks in the analysis
2. **Arguments For/Against**: The primary arguments on both sides of a question
3. **Conclusions**: The synthesized conclusions or insights from the analysis
4. **Tags**: Automatically generated topic tags from the content
## Troubleshooting
If you encounter any issues with the analysis tools:
1. Check that your MCTS run completed successfully (status: "completed")
2. Verify that the run ID you're using exists and is correct
3. Try listing all runs to see what's available: `list_mcts_runs()`
4. Make sure the `.best_solution.txt` file exists in the run's directory
## Advanced Example Usage
### Customizing Reports
You can generate reports in different formats:
# Generate a markdown report
report = get_mcts_report(run_id='cogito:latest_1745979984', format='markdown')
# Generate a text report
report = get_mcts_report(run_id='cogito:latest_1745979984', format='text')
# Generate an HTML report
report = get_mcts_report(run_id='cogito:latest_1745979984', format='html')
### Finding the Best Runs
To find your best-performing runs:
best_runs = get_best_mcts_runs(count=3, min_score=8.0)
This returns the top 3 runs with a score of at least 8.0.
## Simple Usage Instructions
1. **Changing Models**:
list_ollama_models() # See available models
set_ollama_model("qwen3:0.6b") # Set to fast small model
2. **Starting a New Analysis**:
initialize_mcts(question="Your question here", chat_id="unique_identifier")
3. **Running the Analysis**:
run_mcts(iterations=3, simulations_per_iteration=10)
4. **Comparing Performance**:
run_model_comparison(question="Your question", iterations=2)
5. **Getting Results**:
generate_synthesis() # Final summary of results
get_mcts_status() # Current status and metrics
示例提示
“分析人工智能对人类创造力的影响”
“继续探索这个话题的伦理层面”
“您在上次运行中发现的最佳分析是什么?”
“这个 MCTS 流程是如何运作的?”
“显示当前的 MCTS 配置”

对于开发人员
# Activate virtual environment
source .venv/bin/activate
# Run the server directly (for testing)
uv run server.py
# OR use the MCP CLI tools
uv run -m mcp dev server.py测试服务器
测试服务器是否正常工作:
# Activate the virtual environment
source .venv/bin/activate
# Run the test script
python test_server.py这将测试 LLM 适配器以确保其正常工作。
贡献
欢迎为改进 MCTS MCP 服务器做出贡献。以下是一些潜在的改进领域:
改进本地推理适配器以实现更复杂的分析
添加更复杂的思维模式和评估策略
增强树可视化和结果报告
优化MCTS算法参数
{kind=link}
{kind=link}
{kind=link}
{kind=link}