
Backlog MCP Server
The Backlog MCP Server is a task management system for LLM agents that enables tracking, organizing, and collaborating on work items with a real-time web viewer.
Core Capabilities:
Task Management: Create, update, delete, and list tasks, epics, folders, artifacts, and milestones with statuses:
open,in_progress,blocked,done,cancelledRich Context Retrieval: Get a comprehensive snapshot of any task — parent epics, siblings, children, cross-references, reverse references, ancestors, descendants, semantically similar items, and recent activity — in a single call
Advanced Search: Hybrid full-text + semantic search across all content with relevance scoring and filtering by type, status, or parent
Organization: Link items hierarchically via parent-child relationships, epic groupings, and folder structures
Evidence & Reference Tracking: Attach external URLs, task references, local files, and proof of completion (PRs, docs, notes) to items
File Editing: Modify markdown files using str_replace, line insertion, or append operations while preserving YAML frontmatter
Web Viewer: Real-time web UI with split-pane layout, spotlight search, activity timeline, and filtering
Flexible Deployment: Run locally or self-host on Cloudflare Workers (free) for remote access across any device or MCP client
Multi-Client Support: Share the same backlog across multiple MCP clients (Claude, ChatGPT, etc.) and agent sessions
CLI Management: Check server status, version, task counts, uptime, and start/stop the background process
Uses Markdown as the primary storage and data format for task entities, providing tools to create, retrieve, and edit task content through Markdown files.
The web viewer supports rendering Mermaid diagrams within task descriptions for visualizing workflows and architectural decisions.
Utilizes YAML frontmatter within task files to manage structured metadata, including status, IDs, relationships, and custom attributes.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@Backlog MCP Serverlist all open tasks"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
backlog-mcp
A task backlog MCP server for LLM agents. Works with any MCP client — Claude, Kiro, Cursor, Codex, etc.
Agents create tasks, track progress, attach artifacts, and search across everything. Humans get a real-time web viewer to see what agents are doing.
Runs locally out of the box. Can also be self-hosted on Cloudflare Workers + D1 for a free, always-on remote backlog accessible from any device or MCP client.
Quick start: Tell your LLM:
Add backlog-mcp to .mcp.json and use it to track tasks
Live demo: backlog-mcp-viewer.pages.dev — the viewer UI connected to a real hosted instance
What's Inside
This is a monorepo with 3 packages:
Package | npm | What it does |
MCP server, HTTP API, CLI | ||
— | Web UI built on | |
— | Shared entity types and ID utilities |
The viewer is built with Nisli, a zero-dependency reactive Web Component framework published as @nisli/core. Nisli started in this repo and now lives separately.
Related MCP server: Task Manager MCP Server
Installation
Add to your MCP config (.mcp.json or your MCP client config):
{
"mcpServers": {
"backlog": {
"command": "npx",
"args": ["-y", "backlog-mcp"]
}
}
}Self-Hosting on Cloudflare (Optional)
Host your own always-on remote backlog for free using Cloudflare Workers + D1. Accessible from any device or MCP client — no local server process required.
Prerequisites: Cloudflare account (free tier is enough), wrangler CLI, a GitHub OAuth App.
# 1. Clone and install
git clone https://github.com/gkoreli/backlog-mcp.git
cd backlog-mcp
pnpm install
# 2. Create the D1 database
cd packages/server
npx wrangler d1 create backlog
# Copy the database_id into packages/server/wrangler.jsonc
# 3. Apply the D1 migrations
npx wrangler d1 execute backlog --remote --file=migrations/0001_initial.sql
npx wrangler d1 execute backlog --remote --file=migrations/0002_oauth_refresh_tokens.sql
# 4. Set secrets
npx wrangler secret put JWT_SECRET # any strong random string
npx wrangler secret put API_KEY # your personal API key (for Claude Desktop)
npx wrangler secret put GITHUB_CLIENT_ID # GitHub OAuth App client ID
npx wrangler secret put GITHUB_CLIENT_SECRET
npx wrangler secret put ALLOWED_GITHUB_USERNAMES # comma-separated: "you,youralt"
# 5. Deploy
npx wrangler deployGitHub OAuth App setup: go to GitHub → Settings → Developer settings → OAuth Apps → New.
Set the callback URL to https://<your-worker>.workers.dev/oauth/github/callback.
Once deployed, add to your MCP client config:
{
"mcpServers": {
"backlog": {
"command": "npx",
"args": ["-y", "mcp-remote", "https://<your-worker>.workers.dev/mcp"]
}
}
}Claude.ai and ChatGPT can connect directly via the remote MCP URL — no local process needed. GitHub OAuth sessions use rotating refresh tokens so clients can renew access without daily re-authentication.
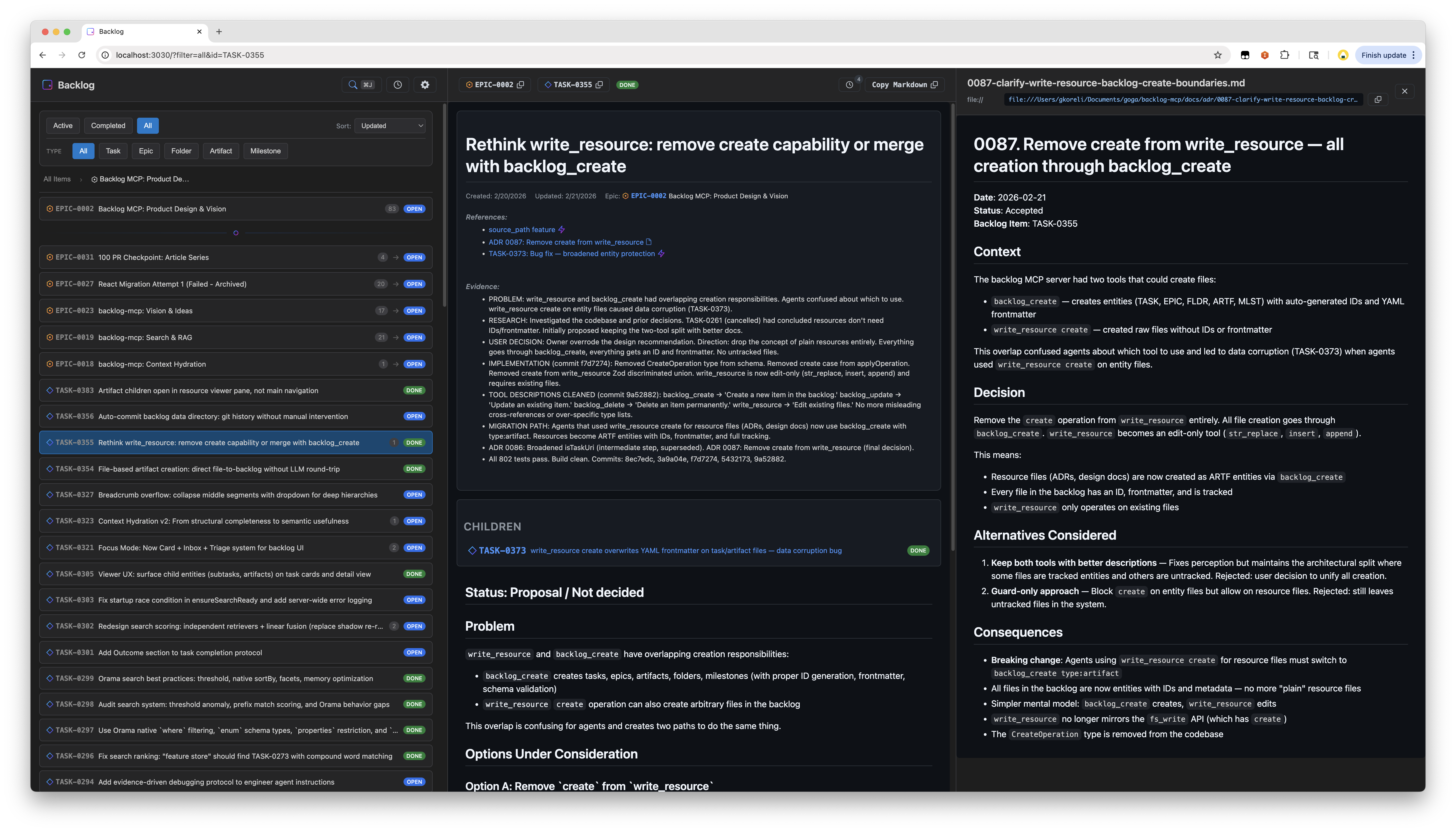
Web Viewer
Open http://localhost:3030 — always available when the server is running.
Features:
Split pane layout with task list and detail view
Spotlight search with hybrid text + semantic matching
Real-time updates via SSE
Activity timeline
Filter by status, type, epic
Dark/light theme toggle (Tsa design system)
Syntax highlighting via Shiki (VS Code-quality, dual-theme CSS variables)
GitHub-flavored markdown rendering with Mermaid diagrams
URL state persistence
The viewer UI is built with Nisli (@nisli/core) and styled with Tsa (ცა, Georgian for "sky") — our design system that pairs with Nisli.
Entity Types
5 entity types, all stored as markdown files with YAML frontmatter:
Type | Prefix | Purpose |
Task |
| Work items |
Epic |
| Groups of related tasks |
Folder |
| Organizational containers |
Artifact |
| Attached outputs (research, designs, logs) |
Milestone |
| Time-bound targets with due dates |
Status values: open, in_progress, blocked, done, cancelled
Example task file:
---
id: TASK-0001
title: Fix authentication flow
status: open
epic_id: EPIC-0002
parent_id: FLDR-0001
references:
- url: https://github.com/org/repo/issues/123
title: Related issue
evidence:
- Fixed in PR #45
---
The authentication flow has an issue where...MCP Tools
backlog_list
backlog_list # Active tasks (open, in_progress, blocked)
backlog_list status=["done"] # Completed tasks
backlog_list type="epic" # Only epics
backlog_list epic_id="EPIC-0002" # Tasks in an epic
backlog_list parent_id="FLDR-0001" # Items in a folder
backlog_list query="authentication" # Search across all fields
backlog_list counts=true # Include counts by status/type
backlog_list limit=50 # Limit resultsbacklog_get
backlog_get id="TASK-0001" # Single item
backlog_get id=["TASK-0001","EPIC-0002"] # Batch getbacklog_create
backlog_create title="Fix bug"
backlog_create title="Fix bug" content="Details..." epic_id="EPIC-0002"
backlog_create title="Q1 Goals" type="epic"
backlog_create title="Research notes" type="artifact" parent_id="TASK-0001"
backlog_create title="v2.0 Release" type="milestone" due_date="2026-03-01"
backlog_create title="Fix bug" source_path="/path/to/spec.md" # Read content from filebacklog_update
backlog_update id="TASK-0001" status="done"
backlog_update id="TASK-0001" status="blocked" blocked_reason=["Waiting on API"]
backlog_update id="TASK-0001" evidence=["Fixed in PR #45"]
backlog_update id="TASK-0001" parent_id="FLDR-0001"
backlog_update id="MLST-0001" due_date="2026-04-01"backlog_delete
backlog_delete id="TASK-0001" # Permanent deletebacklog_search
Full-text + semantic hybrid search with relevance scoring:
backlog_search query="authentication bug"
backlog_search query="design decisions" types=["artifact"]
backlog_search query="blocked tasks" status=["blocked"] limit=10
backlog_search query="framework" sort="recent"
backlog_search query="search ranking" include_content=truebacklog_context
Get rich context for a task — parent epic, siblings, children, cross-references, reverse references, recent activity, and semantically related items:
backlog_context task_id="TASK-0001"
backlog_context task_id="TASK-0001" depth=2 # Grandparent/grandchildren
backlog_context query="search ranking improvements" # Find by content
backlog_context task_id="TASK-0001" include_related=false # Skip semantic searchwrite_resource
Edit existing files on the MCP server. All creation goes through backlog_create.
# Edit task body (use str_replace — protects frontmatter)
write_resource uri="mcp://backlog/tasks/TASK-0001.md" \
operation={type: "str_replace", old_str: "old text", new_str: "new text"}
# Insert after a specific line
write_resource uri="mcp://backlog/tasks/TASK-0001.md" \
operation={type: "insert", insert_line: 5, new_str: "inserted line"}
# Append to a file
write_resource uri="mcp://backlog/resources/log.md" \
operation={type: "append", new_str: "New entry"}Operations: str_replace (exact match, must be unique), insert (after line number), append (end of file).
How It Works
Running npx -y backlog-mcp (the default MCP config) does the following:
Starts a persistent HTTP server as a detached background process — serves both the MCP endpoint (
/mcp) and the web viewer (/) on port 3030Bridges stdio to it — your MCP client communicates via stdio, which gets forwarded to the HTTP server via
mcp-remoteAuto-updates:
npx -yalways pulls the latest published version. If the running server is an older version, it's automatically shut down and restarted with the new oneResilient recovery: If the bridge loses connection, a supervisor restarts it with exponential backoff (up to 10 retries). Connection errors like
ECONNREFUSEDare detected and handled automatically
The HTTP server persists across agent sessions — multiple MCP clients can share it. The web viewer is always available at http://localhost:3030.
CLI
All commands via npx:
npx backlog-mcp # Start stdio bridge + auto-spawn HTTP server (default)
npx backlog-mcp status # Check server status
npx backlog-mcp stop # Stop the server
npx backlog-mcp version # Show version
npx backlog-mcp serve # Run HTTP server in foreground (optional, see below)Sample outputs:
$ npx backlog-mcp status
Server is running on port 3030
Version: 0.44.0
Data directory: /Users/you/.backlog
Task count: 451
Uptime: 3515s
Viewer: http://localhost:3030/
MCP endpoint: http://localhost:3030/mcp
$ npx backlog-mcp stop
Stopping server on port 3030...
Server stopped
$ npx backlog-mcp status
Server is not runningThe CLI exists for humans to inspect and manage the background server that agents use. Since the default mode spawns a detached process, you need status to check it and stop to shut it down.
serve runs the HTTP server in the foreground instead of detached — useful for debugging, Docker containers, or running without an MCP client. In normal usage you never need it; the default command handles everything.
Configuration
BACKLOG_DATA_DIR=~/.backlog # Where to store tasks (default: data/tasks/)
BACKLOG_VIEWER_PORT=3030 # HTTP server portCreate a .env file for local development — see .env.example.
Development
git clone https://github.com/gkoreli/backlog-mcp.git
cd backlog-mcp
pnpm install
pnpm build # Build all packages
pnpm test # Run all workspace tests
pnpm dev # Vite dev server (SPA + API on one port, HMR)pnpm dev runs a single Vite process that serves the viewer (with granular component HMR) and the Hono backend (API, SSE, MCP) on one origin — edit a component and it hot-swaps in the browser without a page reload. The architecture mirrors prod: one server, one port, same dispatch.
Architecture
packages/
├── server/ # MCP server, search, context hydration, storage
├── viewer/ # Web UI built with @nisli/core
└── shared/ # Entity types, ID utilities
docs/
├── adr/ # backlog-mcp architecture decision records
└── framework-adr/ # Pointer to Nisli ADRsBacklog ADRs document significant design decisions. See docs/adr/README.md for the full index. Nisli ADRs live in the Nisli repository.
License
MIT
{kind=link}
Maintenance
Latest Blog Posts
- Your AI Chatbot Just Exposed Your CEO's Salary to an InternBy Om-Shree-0709 on .Agent IdentityMCP SecurityOAuth Delegation
- Why MCP Servers Need Execution Sandboxing (And Why Your Current Stack Isn't Enough)By Om-Shree-0709 on .Agentic AiPrompt InjectionWebAssembly
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/gkoreli/backlog-mcp'
If you have feedback or need assistance with the MCP directory API, please join our Discord server