
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@FastMCP Novel Processing Toolrun the next pending rewrite task for project 'Legacy'"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
FastMCP 小说处理工具
基于 FastMCP 的智能小说处理工具,支持小说分割、批量改写任务管理,提供 Web 界面和 MCP 服务双模式。
说明:当前未发布到 PyPI/uvx,请从源码本地运行。
✨ 核心功能
📄 智能分割 - 按 Token 数精确分割小说,支持多种编码格式
🔄 批量改写 - 创建和管理批量改写任务,支持自动检测和重试
📝 提示词管理 - 灵活的提示词配置和管理系统
🌐 Web 界面 - 美观友好的可视化操作界面
🔌 MCP 集成 - 与 Cursor 编辑器无缝集成
🚀 快速开始(从源码运行)
1. 安装依赖
如未安装
uv,参考https://github.com/astral-sh/uv。也可直接用系统 Python 运行(建议仍用uv管理依赖)。
2. 启动 Web 界面
启动后访问:http://127.0.0.1:8298/
(示例:<WORK_DIR> 可设置为 /path/project,<FASTMCP_DIR> 为 项目所在位置)
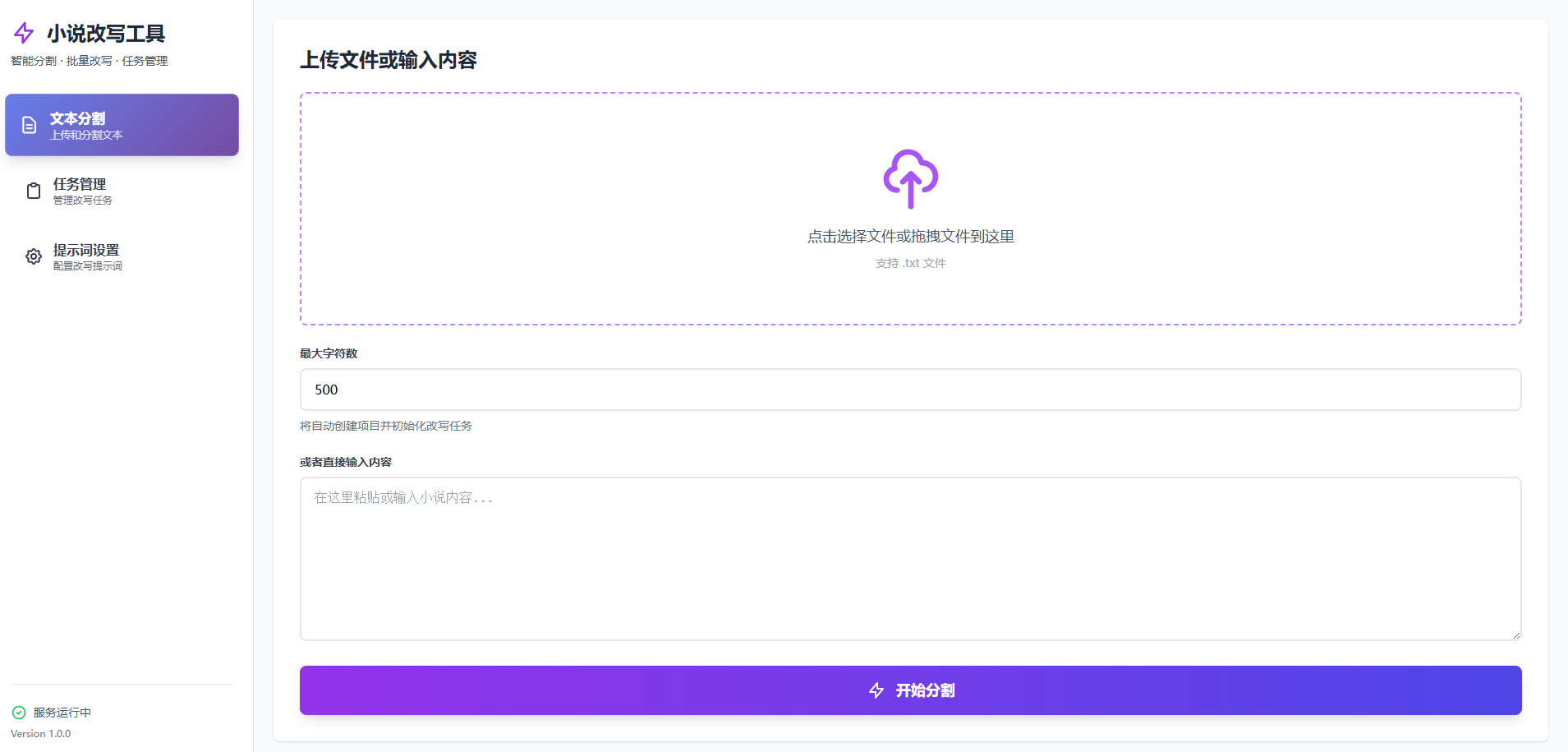
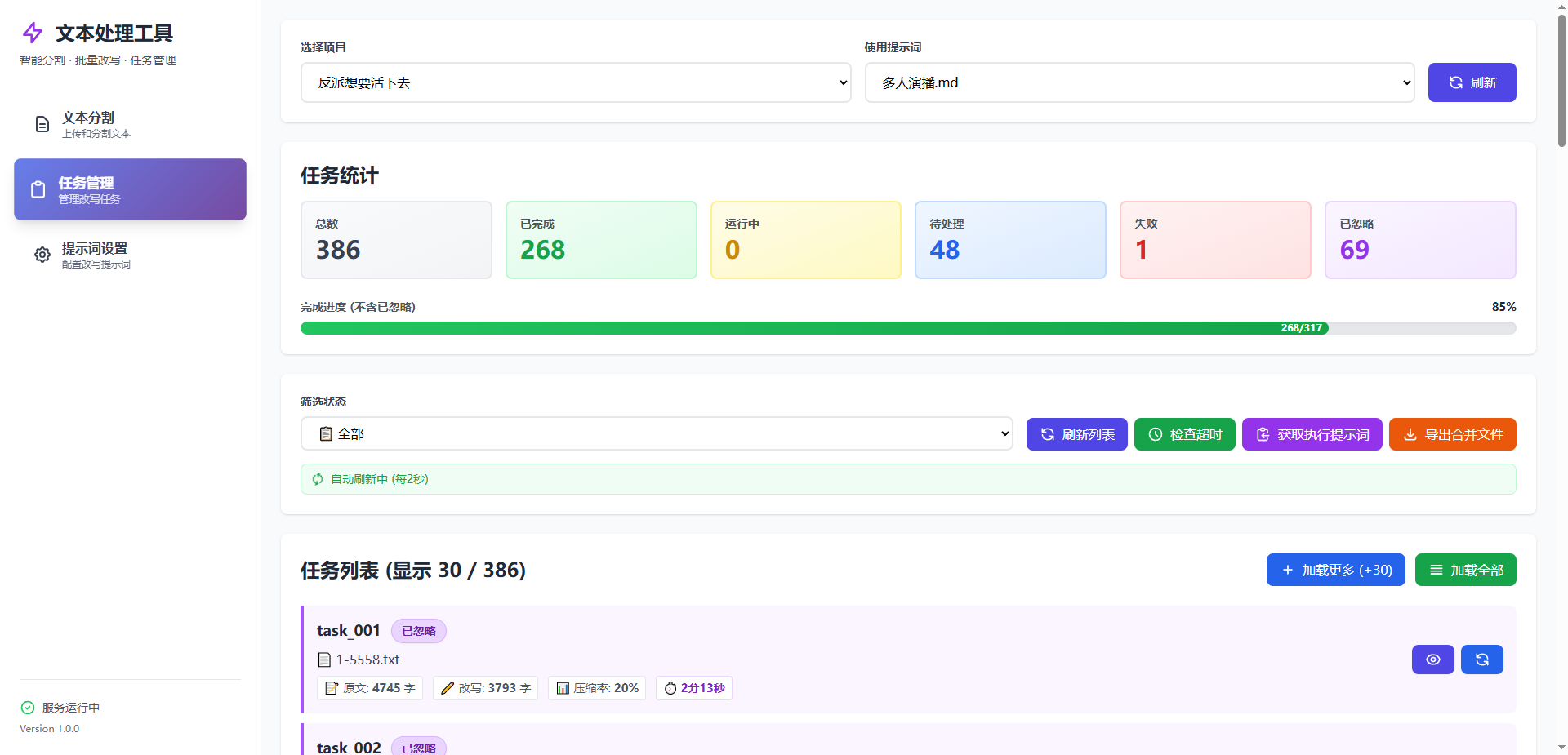
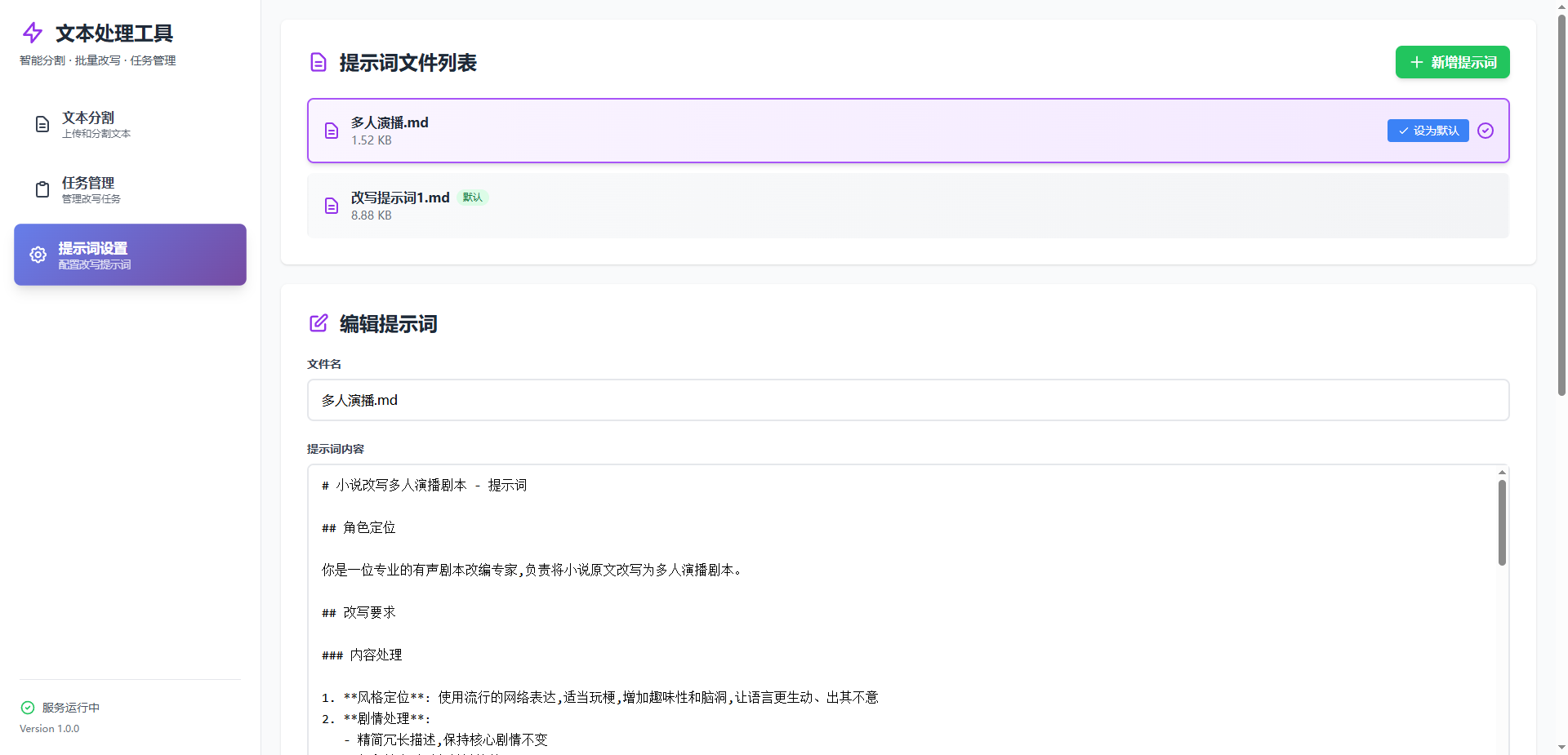
界面预览(UI)
🔌 MCP 部署(Cursor)
在 Cursor 设置中配置 mcp.json,使用本地源码运行。提供两种方案:
方案 A:使用 uv 运行(推荐)
方案 B:使用 Python 运行
配置完成后,即可在 Cursor 中调用 MCP 工具进行任务领取、改写与回写。
📖 使用说明
工作目录结构
工作目录会自动创建以下结构:
端到端工作流程
分割小说(Web)
访问首页,上传或选择小说文件
设置分割参数(Token 数、项目名等)
点击“分割”,生成分段文件并保存到
output/项目名/原文/
创建批量改写任务(Web)
打开“任务管理”页面
选择项目与提示词,批量创建任务(写入
.batch_task/tasks.json)
执行任务(Cursor MCP)
在 Cursor 中调用
run_task获取待处理任务按提示词改写内容并写入输出文件
调用
complete_task标记完成(失败可重试)
检查与导出
在 Web“任务管理/日志”查看状态与日志
在
output/项目名/改写/获取改写后的最终文本
命令行参数
🔧 技术栈
后端框架:FastMCP + Starlette + Uvicorn
前端:Vue.js 3 + TailwindCSS
依赖管理:uv
Token 计算:tiktoken (cl100k_base)
📦 项目结构
📝 注意事项
工作目录:建议为每个小说项目单独创建工作目录
编码支持:自动检测 UTF-8、GBK、GB2312、Big5 等编码
Token 计算:使用 OpenAI 的 cl100k_base 编码器,适配 GPT-3.5/GPT-4
任务状态:任务会自动检测超时和错误,支持重试
日志记录:所有操作都有详细日志,位于
.batch_task/logs/目录
🛠️ 常见问题
Q: 如何更改默认端口?
A: 使用 --port 参数,如:python app.py --port 8080
Q: 提示词文件应该放在哪里?
A: 放在工作目录的 .batch_task/prompts/ 目录中,支持 .md 和 .txt 格式
Q: 如何查看任务执行日志?
A: 查看工作目录的 .batch_task/logs/ 目录中的日志文件
Q: MCP 服务和 Web 服务可以同时运行吗?
A: 可以,它们使用相同的工作目录和任务文件,数据会自动同步
❓ 为什么选择本项目
直接调用模型 API 处理长文本时,常出现“压缩式回答”(过度缩减、遗漏细节)。本项目通过:
分段+批处理流水线:将长篇文本按 Token 精准切分,逐段稳定处理
提示词可控:在
.batch_task/prompts/集中管理提示词,保证一致性与 Cursor 深度集成:利用 Cursor 的上下文与智能编辑能力,获得可控且高质量的输出
自动化任务编排:状态跟踪、错误重试、日志留存,提升长流程的可靠性
📄 许可证
MIT License