
Integrates with Baidu Intelligent Cloud Xiling Digital Human Open Platform, providing tools for digital human video generation, timbre cloning, speech synthesis, and portrait creation. Supports uploading files, querying voices and figures, and generating digital human videos with customizable parameters.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@Baidu Digital Human MCP Servergenerate a digital human video introducing our new product features"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
Baidu Digital Human MCP Server
中文 | English
Overview
Baidu Intelligent Cloud Xiling Digital Human Open Platform has now been fully adapted to the MCP protocol. Creators are welcome to join the experience. The MCP Server provided by Xiling Digital Human contains 13 API interfaces that comply with MCP protocol standards, including basic video generation, advanced video generation, timbre cloning, etc. Relying on the MCP Python SDK development, any agent assistant that supports the MCP protocol (such as Claude, Cursor, Cline, and Qianfan AppBuilder) can be quickly accessed.


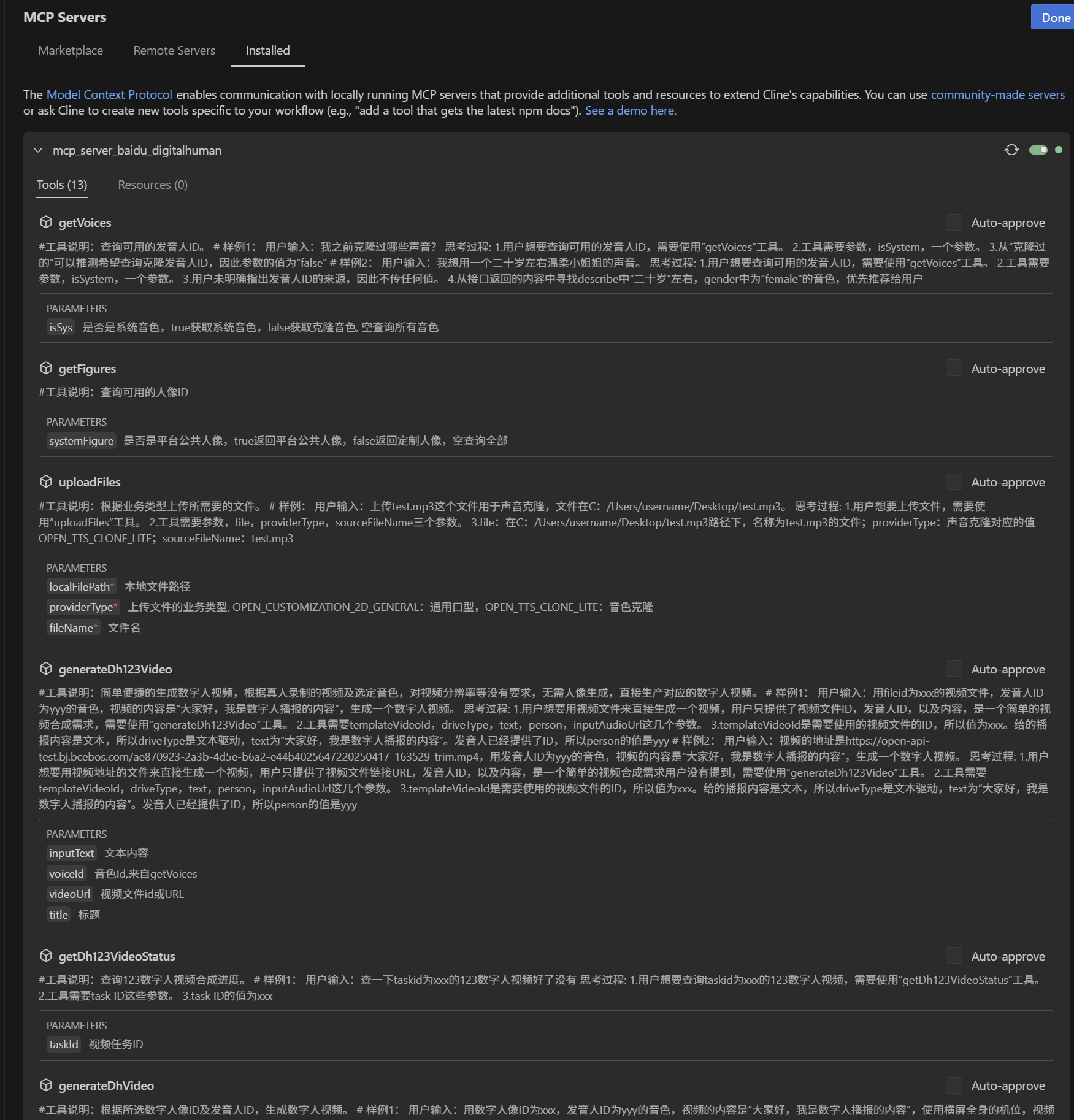
Tools
We provide a variety of tools to meet the needs of different scenarios. It allows you to quickly integrate digital human services in large models and easily build digital human applications. If you have more expectations for digital humans and want to integrate digital human services more deeply, please visit Baidu Intelligent Cloud Xiling Digital Human Open Platform to contact us. More features will also be gradually opened in MCP, so stay tuned.
Function | Function Description | contains tools |
2D few-shot digital human | Generate a digital portrait based on the uploaded video recorded by a real person, which can only be used for basic video production, and the digital human uses a universal lip drive. | • generateLite2dGeneralVideo • getLite2dGeneralStatus |
Digital human video synthesis | Generate digital human video based on the selected digital portrait and timbre | • generateDhVideo • getDhVideoStatus |
123 Digital Human Video | Providing a 10 second to 4-minute live streaming video of saying "123", the corresponding digital human video can be directly produced without the need for portrait generation | • generateDh123Video • getDh123VideoStatus |
Speech synthesis | Based on the text content provided and the selected timbre, no video is needed to generate the corresponding audio | • generateText2Audioo • getText2AudioStatus |
File Upload | Upload the required files based on the service type. | • uploadFiles |
Voice Query | Query available system voice talent. | • getVoices |
Figure Query | Query available figure | • getFigures |
Voice Clone | Generate timbres based on uploaded audio, which can be used for speech synthesis and video production. | • generateVoiceClone • getVoiceCloneStatus |
1. 2D few-shot digital human
Function description: Generate a digital portrait based on the uploaded video recorded by a real person, which can only be used for basic video production, and the digital human uses a universal lip drive. (webm videos with transparent backgrounds)
Sample prompt words:
Use a video file with fileid xxx to generate a digital person, named "zhangsan", which is the image of a boy.
Check the digital person with the ID xxx, okay?
What portraits can I use.
Tool details:
Tool name | Tool description | Input parameters | Output content |
generateLite2dGeneralVideo | Generate a digital portrait based on the uploaded video recorded by a real person, which can only be used for basic video production, and the digital human uses a universal lip drive. | • name: The name of the generated digital portrait, the length of which does not exceed 50 • gender: the gender of the digital person • keepBackground: whether to keep the video background, true is retained, false is removed, and the default value is false • templateVideoId: the file ID of the video used to generate the digital portrait | • figureId: The digital portrait ID generated based on the uploaded video recorded by a real person |
getLite2dGeneralStatus | • Query the progress of the generation of digital portraits • It can also be used to query which system 2D portraits are available. | • figureId: Specify the portrait ID query, if it is empty, query all portraits under the account • systemFigure: query the public portraits of the platform, empty: query all, true: returns the public portrait of the platform, false: returns the custom portrait • trainSuccess: whether to query whether the training is completed and the status of the available portrait (empty: no filtering, true: only returns the available portrait (the public portrait of the platform and the customized portrait of the training success state), false: returns only the custom portrait that is in the queue, during training, or failed training) • pageNo: the page number, Default is 1 • pageSize: The size of each page, default is 10 | • figureId: The digital portrait ID generated based on the uploaded video recorded by a real person • name: The name of the generated digital portrait, the length of which does not exceed 50 • gender: the gender of the digital human • keepBackground: whether to keep the background of the video, true is retained, false is removed, and the default value is false • status: status (LINE_UP (queued), GENERATING, SUCCESS, FAILED) • failedCode: Failure error code<br% 3E • failedMessage: Reason for failure to make a product |
2. Digital human video compositing
Function description: Generate a digital human video based on the selected digital portrait and timbre
Sample prompt words:
Use the voice of the digital portrait ID xxx and the voice voice person ID as yyy, the content of the video is "Hello everyone, I am the content broadcast by the digital person", use the camera position of the whole body of the horizontal screen, use the video background with "https://digital-human-material.bj.bcebos.com/-%5BLjava.lang.String%3B%4046f6cc1e.png", turn on the automatic action added, turn on the subtitles, Generate a 1080P digital human video.
Check the digital human video with a taskid of xxx.
Tool details:
Tool name | Tool description | Input parameters | Output content |
generateDhVideo | Generate a digital human video based on the selected digital portrait and timbre. | • figureId: digital portrait ID • driveType: the data type that drives the digital human, which supports text-driven or audio-driven • text: If the driver type is text-driven, the required video content should not exceed 20000 • person: When the driver type is text-driven, the required voice talent ID • inputAudioUrl: When the driver type is audio driver, the required audio link URL • width: the width of the output video resolution • hight: the high of the output video resolution • cameraId: the camera setting of the system portrait, 0: horizontal half-body, 1: vertical half-body, 2: horizontal full-body, 3: vertical full-body • enabled: whether to enable subtitles, true to enable subtitles, default false is not enabled. • backgroundImageUrl: URL of the background image • autoAnimoji: The system portrait is automatically added, true is automatically added, and the default value is false | • taskId: the ID of the current video synthesis task |
getDhVideoStatus | Query the progress of digital human video composition. | • taskId: the ID of the current video synthesis task | • taskId: the task ID of the current video composition • status: SUBMIT(submitted for synthesis), GENERATING (compositing), SUCCESS(synthesis successful), FAILED(synthesis failed) • failedCode: Error code • failedMessage: Reason for production failure • videoUrl: The address of the successfully synthesized video file corresponding to the task ID, which will be saved for 7 days |
3. 123 digital human video compositing
Function description: Providing a 10 second to 4-minute live streaming video of saying "123", the corresponding digital human video can be directly produced without the need for portrait generation
Sample prompt words:
Use a video file with fileid as xxx and a voice voice with the voice talent ID of yyy, and the content of the video is "Hello everyone, I am the content broadcast by a digital human", and generate a digital human video.
The address of the video is https://open-api-test.bj.bcebos.com/ae870923-2a3b-4d5e-b6a2-e44b4025647220250417_163529_trim.mp4, the voice voice is yyy, and the content of the video is "Hello everyone, I am the content broadcast by the digital human", and a digital human video is generated.
Check the 123 digital human video with a taskid of xxx.
You can check the guide on the website
Tool details:
Tool name | Tool description | Input parameters | Output content |
generateDh123Video | According to the video recorded by the real person and the selected timbre, it can be directly generated into a digital human video without the need for portrait generation. | • templateVideoId: the file ID corresponding to the video used to generate the digital human video • driveType: the data type that drives the digital human, supports text-driven or audio-driven • text: If the driver type is text-driven, the required video content must be filled in length, and the length cannot exceed 20000 • person: If the driver type is text-driven, the required voice talent ID • inputAudioUrl: If the driver type is audio driver, the required audio link URL | • taskId: the ID of the current video synthesis task |
getDh123VideoStatus | Query the progress of video synthesis of 123 digital humans. | • taskId: the ID of the task of the current video composition | • taskId: the task ID of the current video composition • status: Status: SUBMIT (submitted for synthesis), RATING (compositing), SUCCESS (synthesis successful), FAILED • failedCode: Error code • failedMessage: Reason for production failure • videoUrl: The address of the successfully synthesized video file corresponding to the task ID, which will be saved for 7 days |
4. Speech synthesis
Function description: According to the text content provided and the selected timbre, there is no need to generate a video, and the corresponding audio can be generated.
Sample prompt words:
Audio is generated with the voice voice person's ID xxx and the content is "Hello everyone, I am the content broadcast by a digital human".
Check if the speech synthesis with taskid xxx is good.
Tool details:
Tool name | Tool description | Input parameters | Output content |
generateText2Audio | The root does not need to generate a video based on the provided text content and the selected timbre, and produces the corresponding audio. | • text: The required text content, the length of which does not exceed 2000 • person: the required voice talent ID | • taskId: The task ID of the current audio synthesis |
getText2AudioStatus | query the progress of audio composition. | • taskId: the ID of the current video synthesis task | • status: SUBMIT, GENERATING, SUCCESS, FAILED • failedCode: Failure code • failedMessage: Reason for production failure • audioUrl: The address of the successfully synthesized audio file corresponding to the task ID, which will be stored for 7 days |
5. File upload
Function description: The platform supports uploading audio and video files for subsequent sound cloning, digital human production, 123 digital human video production, etc.
Sample prompt words:
Upload test.mp3 this file for sound cloning in C:/Users/username/Desktop/test.mp3.
Tool details:
Tool name | Tool description | Input parameters | Output content |
uploadFiles | Upload the required files according to the service type. | • file: The file to be uploaded • providerType: The service type that uses this file is currently limited to three service types: "2D few-shot digital human production", "sound cloning", and "123 digital human video production". • sourceFileName: the name of the uploaded file, which must be filled in with the correct file name and suffix, for example, :test.mp3. | • fileId: file ID • fileName: the name of the uploaded file |
6. Voice queries
Function description: Query available system voices
Sample prompt words:
What sounds have I cloned before?
I want to use the voice of a gentle young lady in her twenties.
Tool details:
Tool name | Tool description | Input parameters | Output content |
getVoices | Query available voice IDs. | • isSystem:"true" query system voice talent ID, "false" query clone voice talent ID, without passing any value, query available voice talent ID | • perId: voice talent ID • name: voice talent name • describe: description of timbre characteristics • gender: gender • systemProvided: whether it is a system tone |
7. Figure query
Function description: Query the available 2D digital portrait IDs.
Sample prompt words:
What portraits have I generated before?
What portraits are available?
Tool details:
Tool name | Tool description | Input parameters | Output content |
getFigures | query available figures. | • isSystem:"true" query system figure, "false" query generates figures, without passing any value, query all available figures | • figureId:2D figure ID • name:2D figure name • gender:gender • systemProvided: Whether it is a system figure |
8. Sound cloning
Function description: Generate timbre based on the uploaded audio, which can be used for speech synthesis and video production.
Sample prompt words:
Clone the sound with an audio file with a file ID of xxx. Named "zhangsan", it is the timbre of a middle-aged male in his thirties, and I will listen to it with the text "This is my cloned voice".
Check if the voice with ID xxx has been cloned.
Tool details:
Tool name | Tool description | Input parameters | Output content |
generateVoiceClone | Generate voices based on uploaded audio, which can be used in speech synthesis and video production. | • name: The name of the cloned voice, no more than 50% in length3Cbr> •gender: the gender of the voice talent • describe: A description of the cloned voice, no more than 100 • uploadAudioId: the file ID of the audio used to clone the sound •example: the text used for audition, the length of which cannot exceed 100 | • perId; The voice talent ID of the cloned voice is |
getVoiceCloneStatus | Query the current status of a voice clone task based on the voice speaker ID of the task. | • isSuccess: whether to query only the successfully cloned tasks (true: query only successful tasks, false: query all cloned tasks) • perId; : Query the task of specifying the voice talent ID | • perId; ID of the voice talent of the cloned voice • name: name of the voice talent • describe: description of the cloned voice • exampleText: text used for audition • examplAudioUrl: link to an audio file synthesized using the text of the audition • status: the status of the current task, PREPARING, CLONING, SUCCESS, FAIL • reason: If the clone fails, the reason for the failure is described here • gender: the gender of the voice talent whose voice is cloned |
Upload test.mp3 this file for sound cloning in C:/Users/username/Desktop/test.mp3.
Related MCP server: Feishu MCP Server
Get started
1 Claim your trial credit
Log in to Baidu Intelligent Cloud Xiling Digital Human Open Platform Click on the bottom left corner
Go to Component Management to view the obtained component quota
2 Obtain the API key and secret key
Go to Application Management to configure the components that need to be used.
After the creation is complete, you can get the API Key (AppID) and Key and Secret Key (AppKey)
3 MCP configuration
Prerequisites
Python 3.12 or higher
API Key and Secret Key from Xiling Open Platform
You can use Python to join the Baidu Xiling Digital Human MCP Server, and it is recommended to use the uv.
Source Code Access
If you want to customize the capabilities of Xiling Digital Human, you can use the source code to access:
Install the UV
Refer to the uv installation guide to make sure that the command line can execute the 'uvx' command, or that the installed 'uvx' tool can be found through the pathCheckout the code to your local computer
Use the agent assistant that supports MCP to add MCP configuration
Replace ${path/to/dh-mcp-server} with your actual local path
Replace ${API Key} and ${Secret Key} with your actual 'API Key' and 'Secret Key'
Python package plug-in
We have released Baidu Xiling MCP Server: "mcp-server-baidu-digitalhuman" on the pypi, which you can use any Python package management tool to get it
Use UV mounting
Install with pip
pip install mcp-server-baidu-digitalhumanUse the agent assistant that supports MCP to add MCP configuration
4 usage declaration
Before you use the above tools, please read the Xiling Digital Human Custom Component Cloning Protocol. When you use the above tools, you agree to this agreement.
Development
To run the server locally with the MCP Inspector for testing and debugging:npx @modelcontextprotocol/inspector uvx ${path/to/dh-mcp-server}
This will start the server in development mode and allow you to use the MCP Inspector to test the available tools and functionality.
Testing
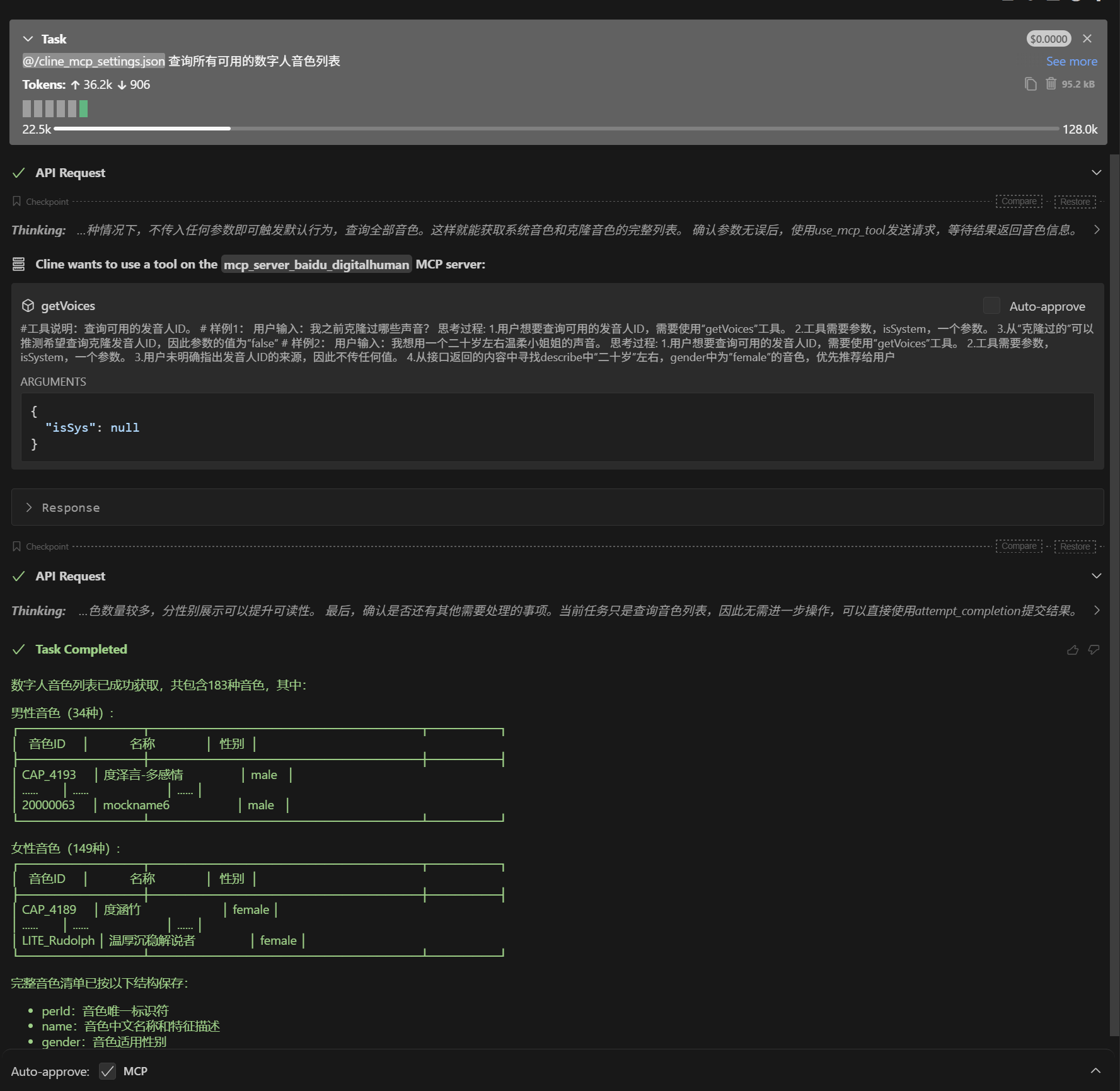
Once the environment is configured, the MCP agent will automatically get a list of all available tools
In the dialog box, enter prompt: "Query the list of all available digital human voices"
license
This project is licensed under the MIT License - see the LICENSE file for details.
Discussion & Feedback
If you have any questions or suggestions, please feel free to contact us. You can contact us in the following ways:
Customer Service Phone:400-920-8999
Cooperation consultation: Baidu Intelligent Cloud Xiling Digital Human Open Platform Consulting
Problem ticket: [Create Ticket] (https://console.bce.baidu.com/support/#/ticket/#/ticket/create)
Official Assistants:
