
The Tavily MCP Server enhances AI systems with tools for web search, content extraction, mapping, and crawling capabilities:
Perform real-time, customizable web searches using Tavily's AI search engine with options for query parameters, time ranges, result count, domain filtering, and topic specification (general/news)
Extract and process content from specified URLs with control over extraction depth and image inclusion
Map website structures systematically
Combine these tools to comprehensively gather, explore, and analyze web data
Can be combined with Neo4j MCP server as mentioned in the tutorial for building a knowledge graph assistant
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@Tavily MCP Serversearch for latest AI research papers on arXiv"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
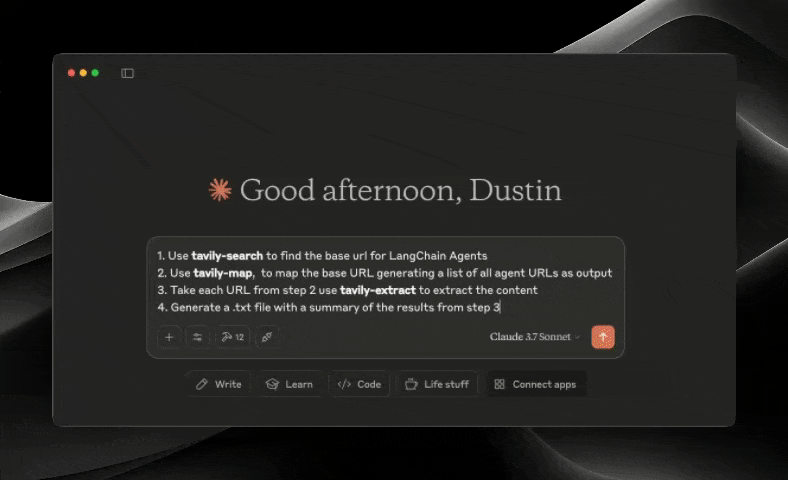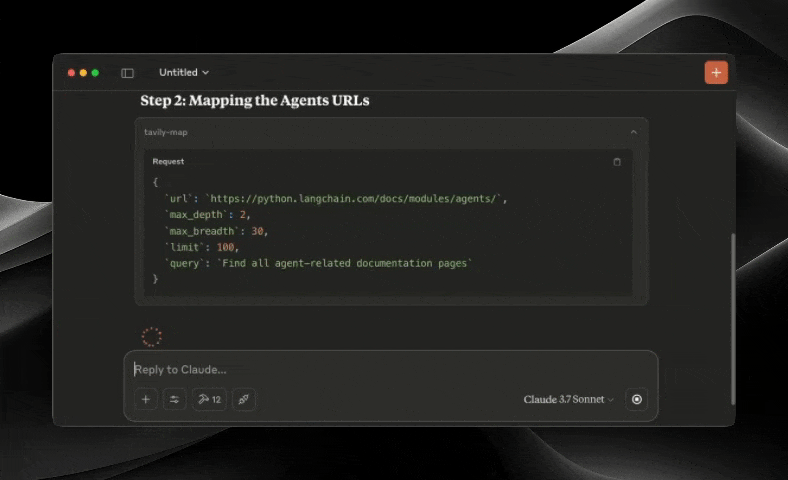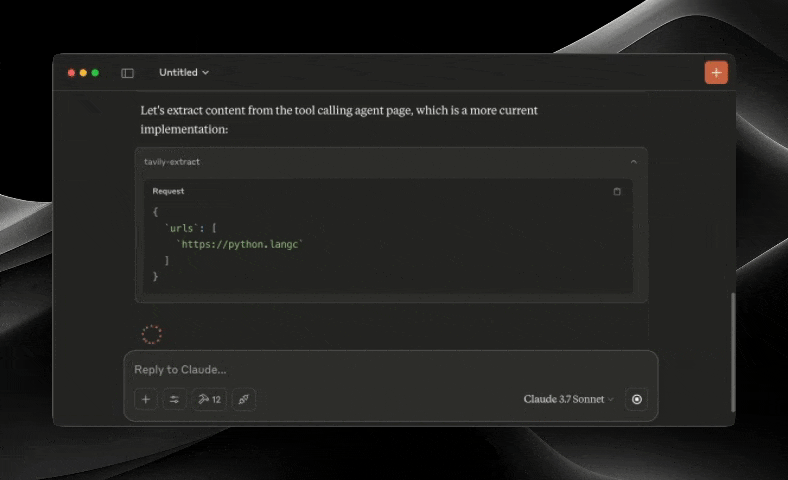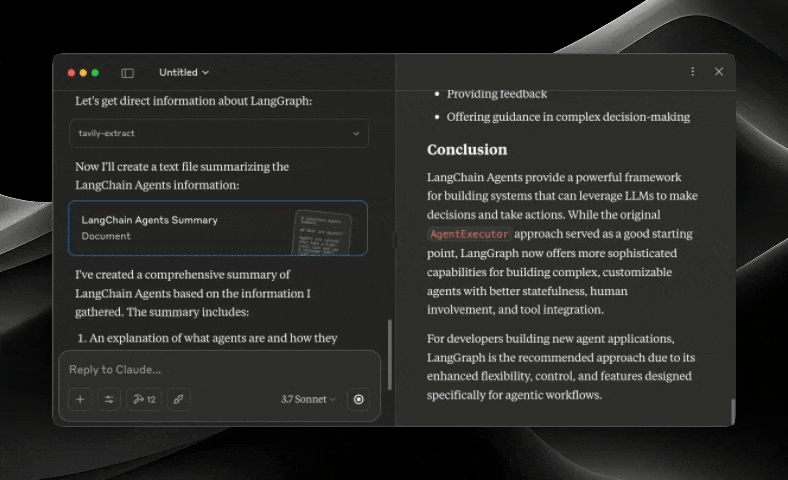
The Tavily MCP server provides:
search, extract, map, crawl tools
Real-time web search capabilities through the tavily-search tool
Intelligent data extraction from web pages via the tavily-extract tool
Powerful web mapping tool that creates a structured map of website
Web crawler that systematically explores websites
📚 Helpful Resources
Tutorial on combining Tavily MCP with Neo4j MCP server
Tutorial on integrating Tavily MCP with Cline in VS Code
Remote MCP Server
Connect directly to Tavily's remote MCP server instead of running it locally. This provides a seamless experience without requiring local installation or configuration.
Simply use the remote MCP server URL with your Tavily API key:
Get your Tavily API key from tavily.com.
Alternatively, you can pass your API key through an Authorization header if the MCP client supports this:
Note: When using the remote MCP, you can specify default parameters for all requests by including a DEFAULT_PARAMETERS header containing a JSON object with your desired defaults. Example:
Related MCP server: Tavily MCP Server
Connect to Claude Code
Claude Code is Anthropic's official CLI tool for Claude. You can add the Tavily MCP server using the claude mcp add command. There are two ways to authenticate:
Option 1: API Key in URL
Pass your API key directly in the URL. Replace <your-api-key> with your actual Tavily API key:
Option 2: OAuth Authentication Flow
Add the server without an API key in the URL:
After adding, you'll need to complete the authentication flow:
Run
claudeto start Claude CodeType
/mcpto open the MCP server managementSelect the Tavily server and complete the authentication process
Tip: Add --scope user to either command to make the Tavily MCP server available globally across all your projects:
Once configured, you'll have access to the Tavily search, extract, map, and crawl tools.
Connect to Cursor

Click the ⬆️ Add to Cursor ⬆️ button, this will do most of the work for you but you will still need to edit the configuration to add your API-KEY. You can get a Tavily API key here.
once you click the button you should be redirect to Cursor ...
Step 1
Click the install button

Step 2
You should see the MCP is now installed, if the blue slide is not already turned on, manually turn it on. You also need to edit the configuration to include your own Tavily API key.

Step 3
You will then be redirected to your mcp.json file where you have to add your-api-key.
Local MCP
Prerequisites 🔧
Before you begin, ensure you have:
If you don't have a Tavily API key, you can sign up for a free account here
Node.js (v20 or higher)
You can verify your Node.js installation by running:
node --version
Git installed (only needed if using Git installation method)
On macOS:
brew install gitOn Linux:
Debian/Ubuntu:
sudo apt install gitRedHat/CentOS:
sudo yum install git
On Windows: Download Git for Windows
Running with NPX
Default Parameters Configuration ⚙️
You can set default parameter values for the tavily-search tool using the DEFAULT_PARAMETERS environment variable. This allows you to configure default search behavior without specifying these parameters in every request.
Example Configuration
Example usage from Client
Acknowledgments ✨
Model Context Protocol for the MCP specification
Anthropic for Claude Desktop