A
licenseA
qualityB
maintenanceA token-efficient MCP server that gives AI agents structured access to the web, returning compact page summaries and targeted queries instead of full accessibility dumps.
Last updated
23
334
169
MIT

touch-browser is an evidence-first web browsing and claim verification MCP server for AI agents, enabling structured research, policy enforcement, and citation-ready reporting.
Status & Telemetry: Check runtime/daemon status (tb_status), view telemetry summaries and recent events.
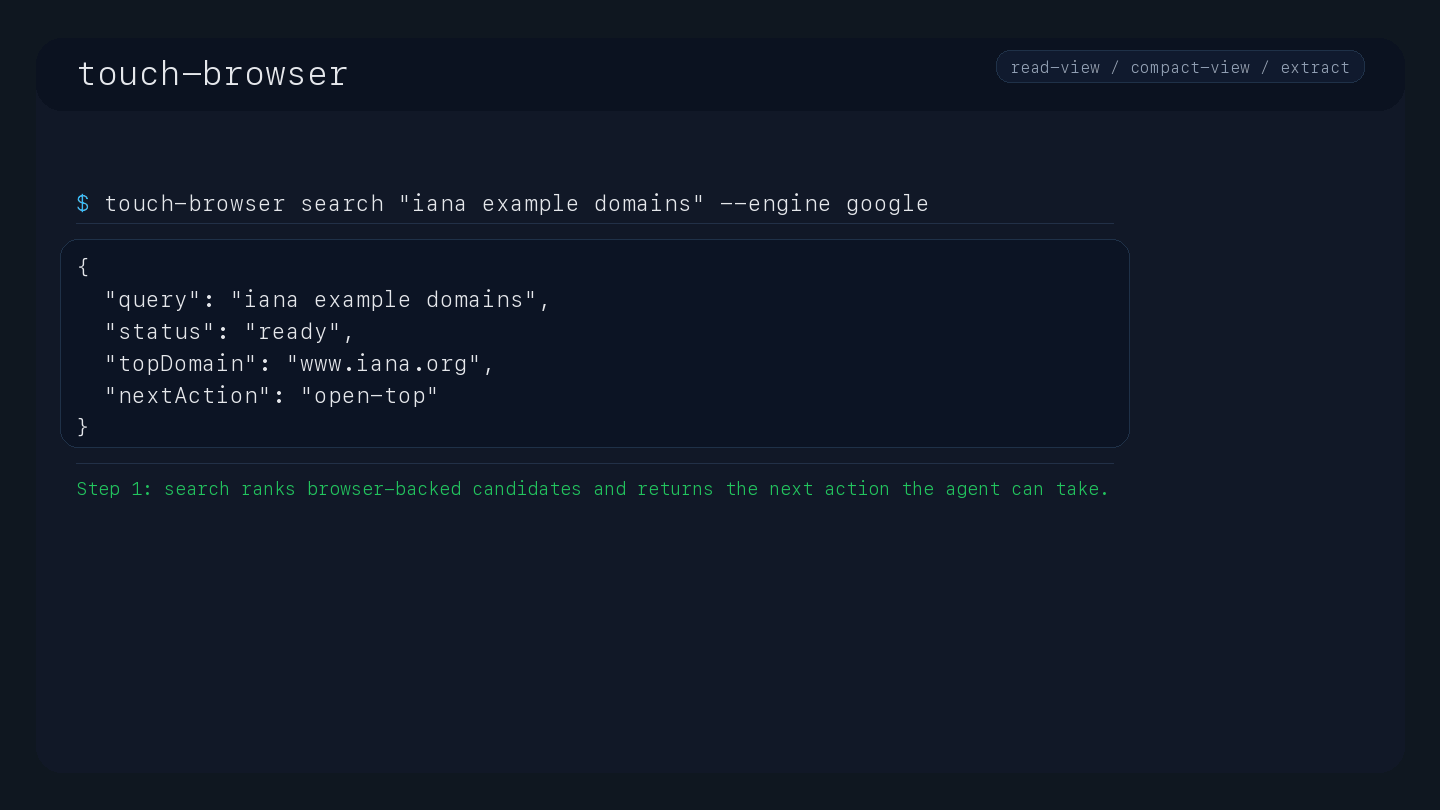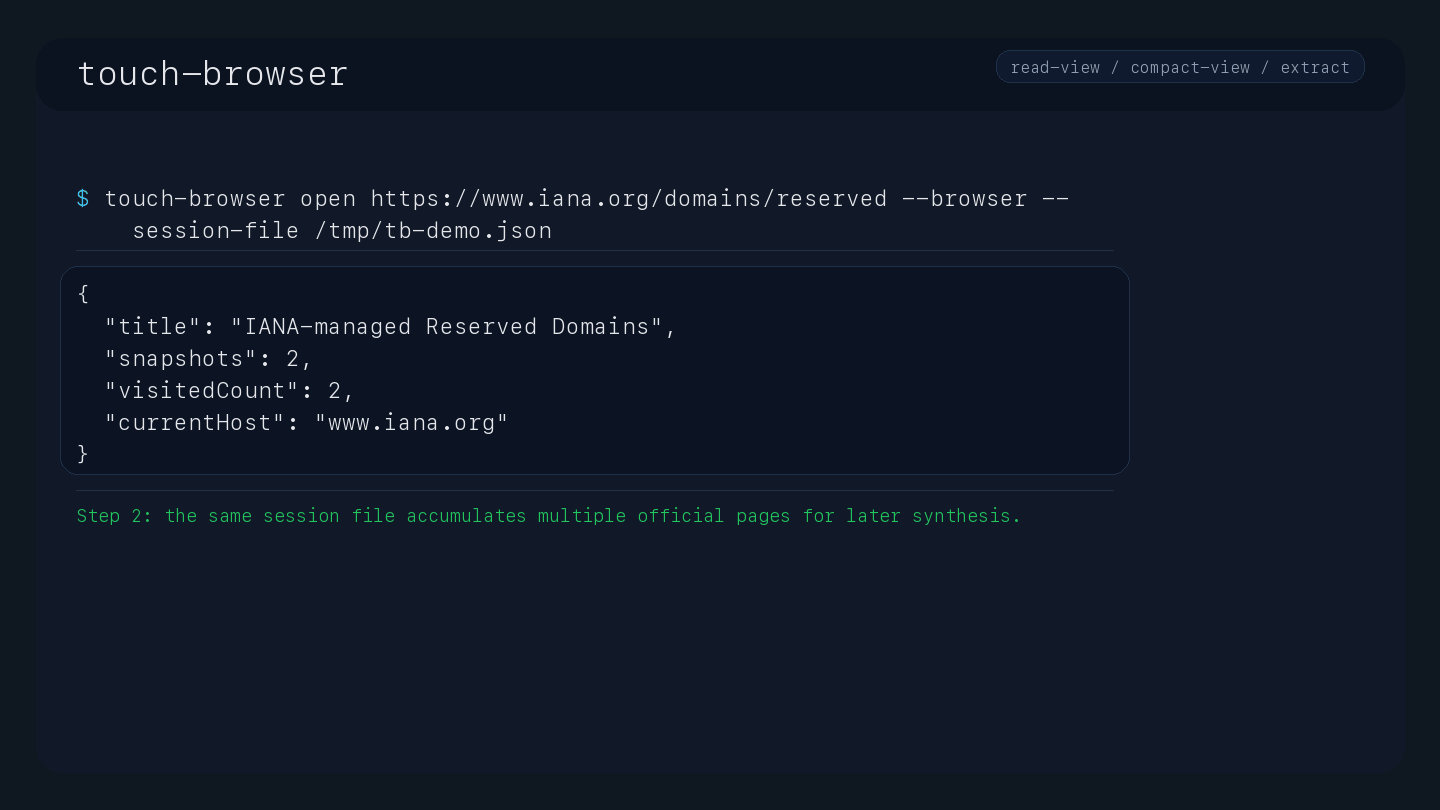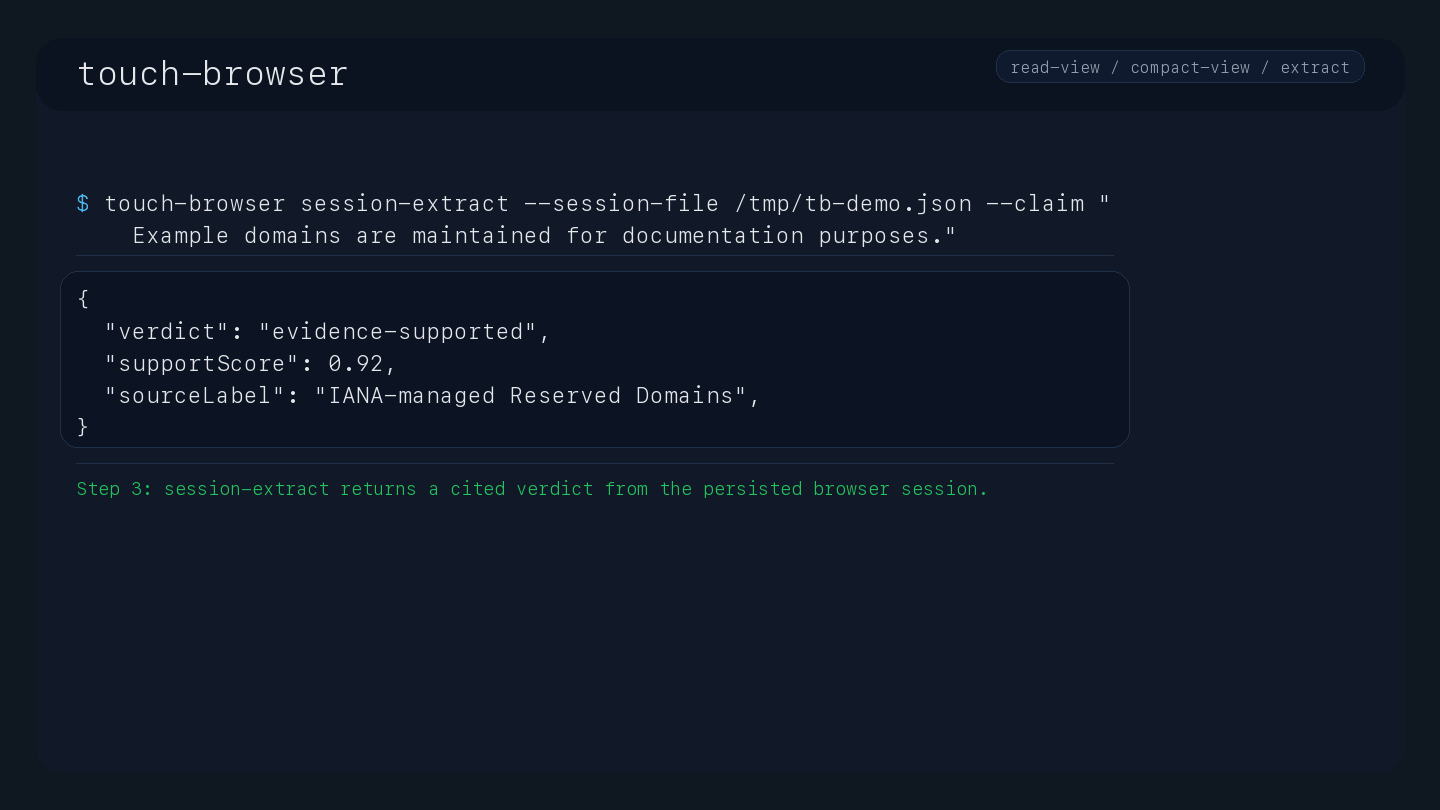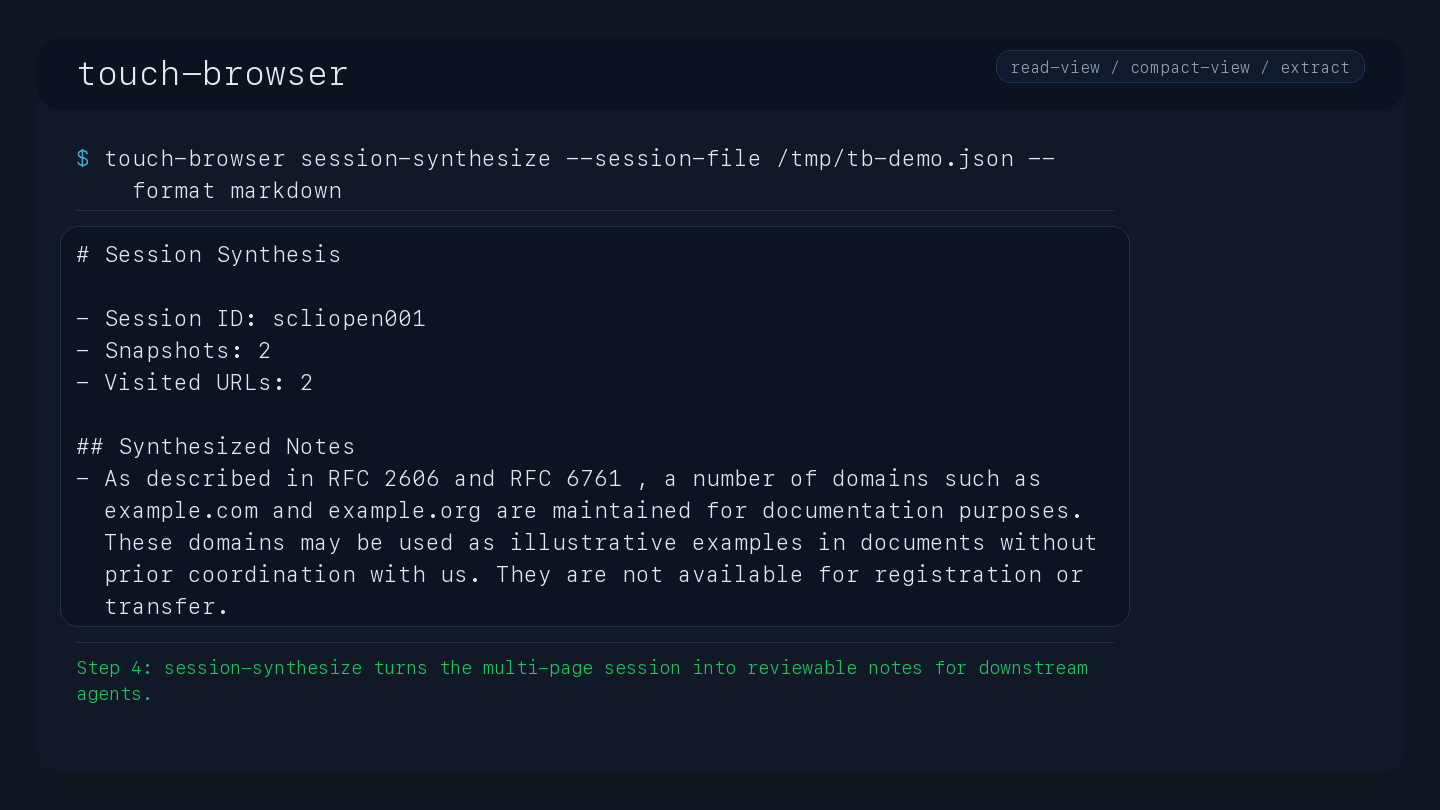
Session Management: Create and close headless research sessions; synthesize multi-tab sessions into citation-ready JSON or Markdown reports (tb_session_synthesize).
Tab Management: Open, list, select, and close individual tabs within a session.
Web Browsing & Search: Open pages by URL (tb_open), perform web searches (tb_search), and open top or ranked results (tb_search_open_top, tb_search_open_result).
Content Reading: Get a readable Markdown view of any page (tb_read_view) for scope checking before extraction.
Claim Extraction & Verification: Verify claims against page content (tb_extract), receiving structured verdicts (evidence-supported, contradicted, insufficient-evidence, needs-more-browsing) with confidence levels, support snippets, and explanations.
Policy Evaluation: Classify pages/actions as allow, review, or block (tb_policy); manage policy profiles (tb_profile, tb_profile_set); review supervised checkpoint guidance (tb_checkpoint).
Interactive Actions: Click elements, type into fields, submit forms, and refresh pages.
Risk & Approval Management: Approve supervised risks once per session (tb_approve).
Secret Handling: Store sensitive values in daemon memory only (tb_secret_store), type stored secrets into fields without persisting to disk (tb_type_secret), and clear secrets (tb_secret_clear).
Uses Brave as a search engine for evidence gathering, with a persistent browser search profile.
Downloads standalone runtime bundles from GitHub Releases during MCP package setup.
Distributes standalone runtime bundles via GitHub Releases, which are verified and installed automatically.
Uses Google as a search engine for evidence gathering, with a persistent browser search profile.
Generates readable Markdown views of web pages for human review and citation-ready synthesis reports.


Ask a claim. Get page-grounded evidence, verdicts, and citations.
touch-browser is an evidence verification layer for AI agents. It does more than fetch a page or convert HTML to Markdown. It opens a page, compiles a structured snapshot, and tells you whether the current page supports a claim, contradicts it, or still needs more browsing.
Use it when you need:
source-linked evidence instead of raw HTML dumps
support snippets and verdict explanations that an agent can inspect before answering
a safe unresolved path for borderline claims instead of bluffing
policy-gated browsing instead of blind automation
replayable, auditable multi-page research sessions
Evidence-first, not fact-final:
touch-browser helps an AI collect page-local evidence and trace where it came from
a higher-level model or human still decides what is true across pages or across the wider world
Before the first browser-backed run, check the local runtime:
touch-browser quickstart
touch-browser doctorquickstart shows the safe local first-use flow, success signals, and common pitfalls. doctor verifies the installed executable, runtime resources, data root, Node runtime, Playwright Chromium, MCP bridge entrypoint, and semantic model readiness. If it reports attention-required, repair those local dependencies before judging browser behavior.
After installing, run one command to see the product difference from a raw fetch:
touch-browser quick https://www.iana.org/help/example-domains \
--claim "As described in RFC 2606 and RFC 6761, a number of domains such as example.com and example.org are maintained for documentation purposes."Decision path for the output:
Check top-level status.
Check summary.reusableClaims and reuseSummary.allClaimsReusable.
Check each claimOutcomes[].verdict.
Check claimOutcomes[].reviewRecommended.
Quote claimOutcomes[].primarySupportSnippet when you need one evidence line.
Use claimOutcomes[].citation.url and citation.retrievedAt when handing evidence to another system.
Expected shape:
{
"status": "succeeded",
"summary": {
"claimCount": 1,
"supportedClaims": 1,
"reusableClaims": 1
},
"claimOutcomes": [
{
"verdict": "evidence-supported",
"confidenceBand": "high",
"reviewRecommended": false,
"reuseAllowed": true,
"primarySupportSnippet": {
"snippet": "..."
},
"citation": {
"url": "https://www.iana.org/help/example-domains",
"retrievedAt": "..."
}
}
]
}The important signal is not that the page was fetched. It is that the claim was routed into a verdict, a confidence band, a reusable snippet, and a source citation.
MCP hosts do not expose the quick CLI command directly. For MCP, use the same idea as a tool loop: tb_session_create -> tb_open -> tb_extract.
Related MCP server: agentify-desktop
extract ReturnsAbbreviated claimOutcome shape from the current extractor:
{
"statement": "The Starter plan costs $29 per month.",
"verdict": "evidence-supported",
"confidenceBand": "high",
"reviewRecommended": false,
"supportSnippets": [
{
"blockId": "b4",
"stableRef": "rmain:table:plan-monthly-price-snapshots-starter-29-10-000-t",
"snippet": "Starter | $29 | 10,000"
}
],
"verdictExplanation": "Matched direct support in 3 page block(s). Review the attached snippets before reusing the claim."
}The extractor returns four verdicts:
evidence-supported: the current page surfaced usable support
contradicted: the current page surfaced conflicting evidence
insufficient-evidence: the current page did not provide enough direct support
needs-more-browsing: the current page is not specific enough yet, so the next step is another page
confidenceBand, reviewRecommended, supportSnippets, verdictExplanation, and matchSignals are there so an agent can decide what to do next without blindly trusting the first match.
claimOutcomeFirst-time users should ignore most fields at first and use this order:
Read verdict.
If reviewRecommended is true, do not reuse the claim without a human or second-pass verifier.
If you need one quote-like evidence line, use primarySupportSnippet.
If you need the reason for the verdict, read verdictExplanation.
If the verdict is not enough to answer, follow nextActionHint.
Use matchSignals only when you are debugging or comparing evidence quality. It is not the first field to read.
claimOutcomes is the per-call decision log for every submitted claim. evidenceSupportedClaims, contradictedClaims, insufficientEvidenceClaims, and needsMoreBrowsingClaims are status-grouped views of the same extraction result. session-synthesize aggregates those grouped views across opened tabs in a session.
Primary local-host MCP path:
npm package: @nangman-infra/touch-browser-mcp
scope: public docs and research web
MCP contract: headless-only, automatic search-engine selection, supervised recovery handoff for challenge/auth/MFA
Recommended host config:
{
"mcpServers": {
"touch-browser": {
"command": "npx",
"args": ["-y", "@nangman-infra/touch-browser-mcp"]
}
}
}On first launch, the package downloads the matching standalone runtime bundle from GitHub Releases, verifies the published .sha256, installs it under ~/.touch-browser/npm-mcp/versions/, and then starts touch-browser mcp.
Use this package when you want a local MCP host such as Claude Desktop, Cursor, or Codex to attach without a separate manual runtime install.
Tagged v* pushes now build standalone macOS and Linux bundles in the Standalone Release workflow. Each bundle includes:
bin/touch-browser
the optimized Rust binary under runtime/touch-browser-bin
a bundled Node runtime and Playwright adapter
the default semantic runner scripts with lazy semantic/NLI model download
Browser actions keep the Playwright adapter as the zero-config compatibility default. For new CLI deployments, the main recommended browser engine is the Rust CDP path. Enable it with:
TOUCH_BROWSER_BROWSER_ADAPTER=cdp-rust touch-browser open <target> --browser --session-file /tmp/tb.json
pnpm run fixtures:browser-adapter-parityThe CDP adapter reports browser-backed captures as sourceType: "cdp-rust",
reuses persistent browser context directories, applies the search identity
profile for search-result captures, and is covered by parity fixtures plus CLI
E2E validation for follow, click, type, submit, pagination, expand, iframe,
shadow DOM, SPA updates, download clicks, persistent-session actions, and
cross-origin nested shadow interactions. It still requires Chrome or Chromium.
Set TOUCH_BROWSER_CDP_BROWSER=/absolute/path/to/chrome when it is not
installed in a standard location.
The slim bundle profile is now the default release profile. It includes Playwright Chromium for zero-config browser actions, skips semantic model caches, and downloads semantic/NLI models lazily on first use. This keeps the installed browser path usable on first run while still reducing model-cache weight:
pnpm run build:standalone-bundle -- local-devUse the full profile only when an offline bundle must also include warm model caches:
pnpm run build:standalone-bundle:full -- local-devWhen a tagged release is published, download the matching tarball from GitHub Releases, unpack it, and run:
./touch-browser-<version>-<platform>-<arch>/install.sh
touch-browser telemetry-summary
touch-browser update --checkTo build the same portable bundle locally:
pnpm install --frozen-lockfile
pnpm run build:standalone-bundle -- v0.1.0-rc1
# Then install the bundled command into PATH
./dist/standalone/touch-browser-v0.1.0-rc1-<platform>-<arch>/install.sh
touch-browser telemetry-summary
touch-browser update --checkThe standalone path is still the official CLI, operations, offline, and fallback install path:
unpack a standalone bundle
run install.sh
use the installed touch-browser command for every CLI and serve operation
The installer now performs a managed install:
managed versions live under ~/.touch-browser/install/versions/<bundle-name>
the active version is ~/.touch-browser/install/current
the PATH command points at ~/.touch-browser/install/current/bin/touch-browser
touch-browser update swaps current to a newly verified release bundle
touch-browser uninstall --purge-all --yes removes the managed install and all stored data
This is the command-only proof path that matches the installed user experience:
touch-browser open https://www.iana.org/help/example-domains --browser --session-file /tmp/tb-first-run.json
touch-browser session-read --session-file /tmp/tb-first-run.json --main-only
touch-browser session-extract --session-file /tmp/tb-first-run.json \
--claim "As described in RFC 2606 and RFC 6761, a number of domains such as example.com and example.org are maintained for documentation purposes."
touch-browser session-synthesize --session-file /tmp/tb-first-run.json --format markdown
touch-browser session-close --session-file /tmp/tb-first-run.jsonInstalled search now keeps an engine-level persistent trust profile by default:
Google: ~/.touch-browser/browser-search/profiles/google-default
Brave: ~/.touch-browser/browser-search/profiles/brave-default
profile state metadata: ~/.touch-browser/browser-search/<engine>.profile-state.json
Prerequisites: rustup, Node.js 18+, pnpm.
bash scripts/bootstrap-local.sh
cargo build --release -p touch-browser-cli
pnpm run build:standalone-bundle -- local-dev
./dist/standalone/touch-browser-local-dev-<platform>-<arch>/install.shSource checkout is a contributor workflow. Release and operations docs still assume the installed touch-browser command from the standalone bundle.
bootstrap-local.sh installs the default semantic models under:
~/.touch-browser/models/evidence/embedding
~/.touch-browser/models/evidence/nli
Use TOUCH_BROWSER_EVIDENCE_EMBEDDING_MODEL_PATH or TOUCH_BROWSER_EVIDENCE_NLI_MODEL_PATH only when you need to override those default locations.
touch-browser is not trying to replace every crawler or browser tool. Its job starts after page acquisition.
Need | Markdown-only fetch | touch-browser |
Read the page | yes | yes |
Keep source-linked block refs | partial | yes |
Judge whether the page supports a claim | no | yes |
Return contradiction and unresolved states | no | yes |
Give support snippets and verdict explanations | no | yes |
Tell the agent to escalate instead of answering | no | yes |
These are the latest local benchmark rerun signals from 2026-05-05, not a promise about every future public page:
Benchmark | Current generated signal |
Public web benchmark |
|
Real-user research benchmark | average supported claim rate |
Adversarial benchmark | verified exact verdict accuracy |
Citation metrics | classification, citation, unsupported-claim, and support-ref precision/recall |
Tool comparison benchmark | extract false-positive rate |
Evidence-grounded web research benchmark | current seed |
See benchmarks/README.md for the benchmark map and generated report locations.
Primary surface:
extract: verify claims against the current page and return structured claim outcomes
Supporting read surfaces:
read-view: readable Markdown for a human reviewer or verifier model
compact-view: low-token semantic state for agent loops
search: structured discovery before opening candidate pages
Safety and audit surfaces:
policy: classify pages and actions as allow, review, or block
session-synthesize: turn a multi-page session into JSON or Markdown with citations
serve: expose the runtime over stdio JSON-RPC for MCP or agent integration
an evidence-first extractor
a selective prediction surface
a verifier-friendly routing layer
a universal truth oracle
a generic crawler replacement
a guarantee that every unsupported claim is false
Recommended MCP setup for local hosts:
{
"mcpServers": {
"touch-browser": {
"command": "npx",
"args": ["-y", "@nangman-infra/touch-browser-mcp"]
}
}
}The MCP package is intentionally narrower than the full CLI:
scope is public docs and research web
recommended loop is tb_search -> tb_search_open_top -> tb_read_view -> tb_extract
tb_session_create accepts an optional caller-provided sessionId for external correlation
tb_open needs target for stateless use; with sessionId, it can omit target to reopen the active tab URL
tb_read_view, tb_extract, and tb_policy can omit target when sessionId points at an opened active tab
tb_extract always needs claims
tb_session_synthesize needs sessionId and at least one opened tab
long-running MCP calls emit notifications/progress when the host provides _meta.progressToken
tb_cancel can reset the daemon; use MCP notifications/cancelled for an in-flight request
engine is not exposed over MCP
headed is not exposed over MCP
if the page indicates challenge, auth, MFA, or other supervised recovery, stop and hand off to a human instead of retrying with different browser settings
Alternative MCP bridge setup for an installed standalone command:
{
"mcpServers": {
"touch-browser": {
"command": "touch-browser",
"args": ["mcp"]
}
}
}The bridge starts touch-browser serve underneath and exposes tools like tb_search, tb_search_open_top, tb_open, tb_read_view, tb_extract, tb_tab_open, and tb_session_synthesize.
Repository checkout integration asset:
{
"mcpServers": {
"touch-browser": {
"command": "node",
"args": ["integrations/mcp/bridge/index.mjs"]
}
}
}The standalone bundle ships touch-browser mcp and touch-browser serve. The checked-in Node launcher remains a repository integration asset for repo checkouts or container images.
By default the bridge prefers an explicit TOUCH_BROWSER_SERVE_COMMAND, then an explicit binary path, then an installed or packaged touch-browser binary, then repo-local target/{release,debug} binaries. If none are available, it fails fast with an install/build instruction instead of dropping back to cargo run.
Use TOUCH_BROWSER_SERVE_COMMAND if you want to force a specific built binary or wrapper command.
Query / URL / fixture / browser tab
-> browser-first search result parsing
-> Acquisition
-> Observation compiler
-> read-view / compact-view
-> extract (evidence + citations + optional verifier)
-> policy
-> session synthesis / replay
-> CLI / JSON-RPC serve / MCPquick start and operations: doc/INSTALL_AND_OPERATIONS.md
command surface: doc/CLI_SURFACE_SPEC.md
evidence operating model: doc/EVIDENCE_OPERATING_MODEL.md
npm MCP package: packages/mcp/README.md
examples: examples/README.md
integrations: integrations/README.md
benchmarks and positioning: doc/README.md
pilot and operations package: doc/PILOT_PACKAGE_SPEC.md, doc/OPERATIONS_SECURITY_PACKAGE_SPEC.md
This repository now uses MPL-2.0.
commercial and non-commercial use are allowed
if you distribute modified MPL-covered files, those covered files stay under MPL-2.0
separate files in a larger work can use different terms
full legal text: LICENSE
plain-language policy: LICENSE-POLICY.md
Unclaimed servers have limited discoverability.
If you are the server author, to access and configure the admin panel.

A paid remote MCP for AI agent browser approval MCP, built to return verdicts, receipts, usage logs,
Read-only MCP over an agentic SLR workspace with per-claim citation verification
Read-only MCP over an agentic SLR workspace with per-claim citation verification
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/nangman-infra/touch-browser'
If you have feedback or need assistance with the MCP directory API, please join our Discord server