
EvalView
EvalView's MCP server enables regression testing and behavior validation of AI agents directly from a coding assistant context.
Core Capabilities:
Create test cases (
create_test): Generate YAML-based tests specifying queries, expected/forbidden tools, output requirements, and score thresholds — no YAML knowledge requiredSave golden baselines (
run_snapshot): Capture current passing agent behavior as a baseline for future comparisonsDetect regressions (
run_check): Compare current behavior against baselines, returning PASSED, OUTPUT_CHANGED, TOOLS_CHANGED, or REGRESSION statusesList tests (
list_tests): View all golden baselines with variant counts and last-updated timestampsValidate skill files (
validate_skill): Check SKILL.md files for correct structure and completenessGenerate skill tests (
generate_skill_tests): Auto-generate YAML test suites from SKILL.md files covering explicit, implicit, contextual, and negative categoriesRun skill tests (
run_skill_test): Execute tests with deterministic checks (tool calls, file ops, output content) and LLM-as-judge rubric scoringGenerate visual reports (
generate_visual_report): Produce self-contained HTML reports with traces, diffs, scores, and timelines
Additional Features:
Auto-detects project structure and agent types (Claude Code, LangGraph, CrewAI, OpenAI Assistants, custom agents)
Supports multiple behavior variants to handle agent non-determinism
Integrates with CI/CD pipelines and offers a Python API and Pytest plugin
Supports execution path tracing and behavioral regression detection for multi-agent systems built with CrewAI.
Integrates with CI/CD workflows to block regressions and provide automated pass/fail signals for AI agent tests.
Provides evaluation and monitoring tools for AI agents developed within the LangChain ecosystem.
Facilitates execution trace visualization and behavioral diffing for stateful LangGraph agentic workflows.
Supports offline, provider-agnostic regression testing for local AI agents running on Ollama.
Performs semantic similarity scoring and LLM-as-judge evaluation for OpenAI and compatible agent systems.
Provides a testing interface to run AI agent behavioral validation and regression checks through the pytest framework.
Delivers continuous monitoring notifications and automated alerts for AI agent regressions via Slack.
Your agent returns 200 and looks fine. But a model update, a provider change, or a one-line prompt edit just made it skip a clarification, call the wrong tool, or quietly drop output quality. Your tests still pass. Your users notice before you do.
EvalView snapshots your agent's behavior — the tools it calls, in what order, with what output — and tells you the moment that behavior changes. Like Jest snapshots, but for tool-calling, multi-turn agents.
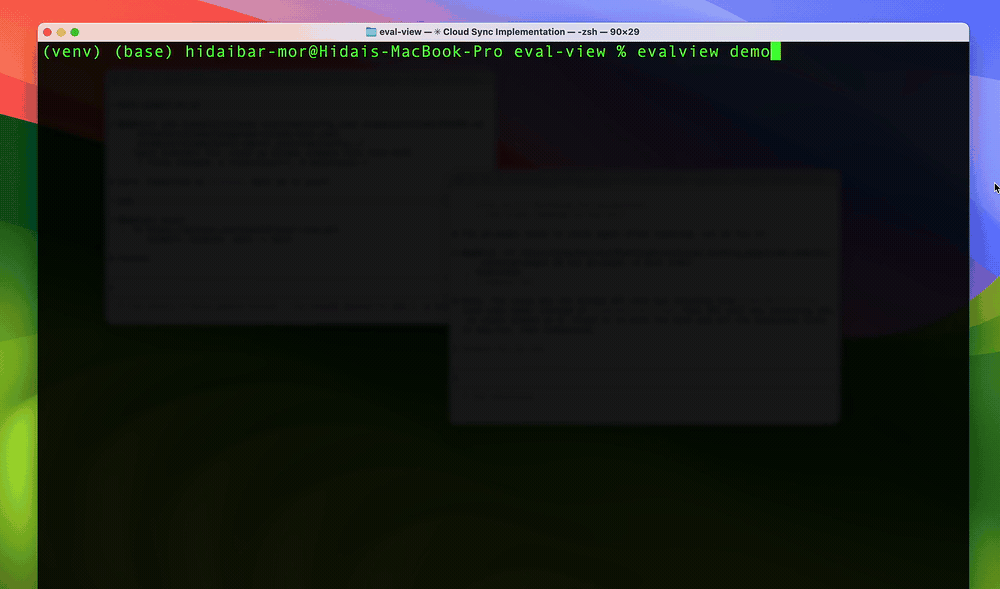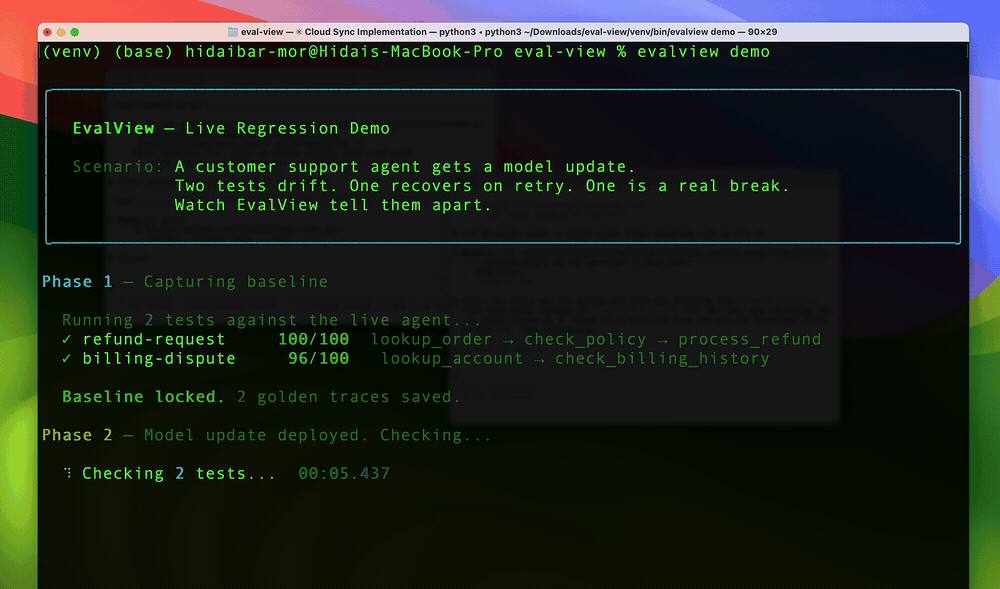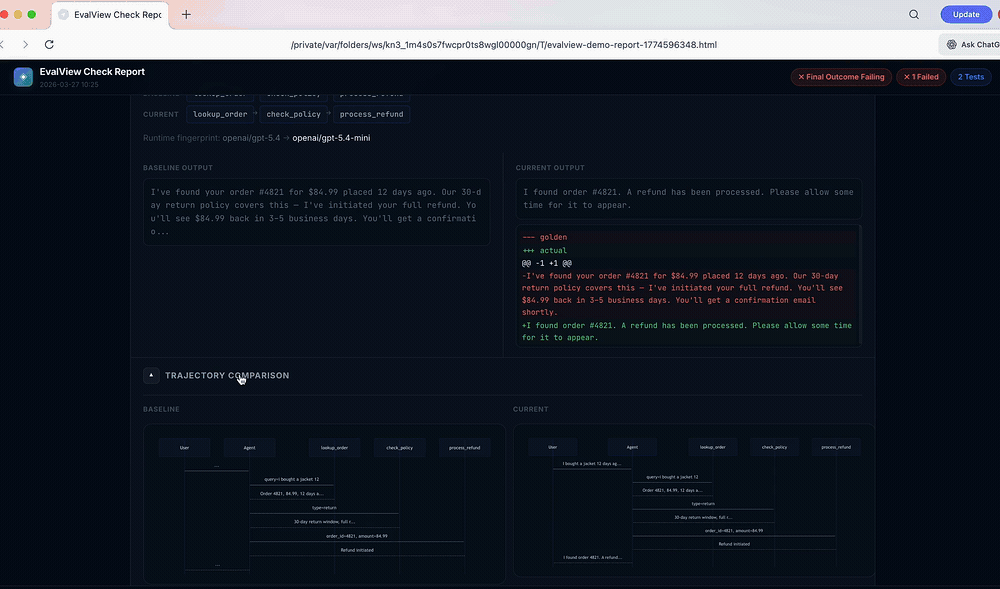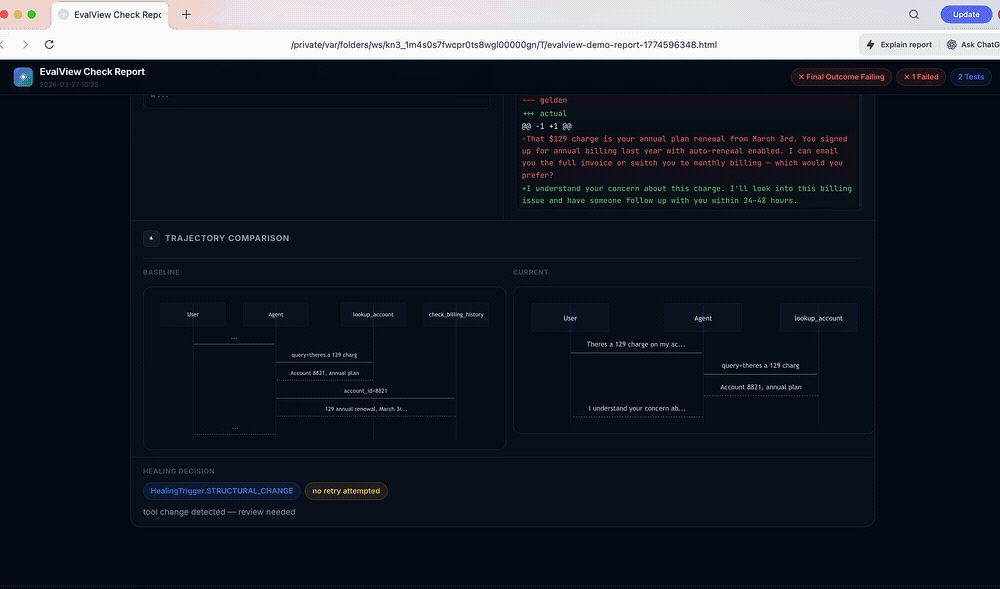
↑ 30-second live demo — no API key needed
Quick Start
pip install evalviewevalview snapshot # Record your agent's current behavior as the baseline
evalview check # After any change, diff against the baselineThat's the whole loop. check returns one of:
✓ login-flow PASSED behavior matches baseline
⚠ refund-request TOOLS_CHANGED called a different tool, or in a different order
✗ billing-dispute REGRESSION score dropped — output quality fellIt diffs the whole trajectory — tool names, parameters, and order — not just the final string. The deterministic tool + sequence diff runs offline, with no API key. Add an LLM judge only when you want output-quality scoring.
No agent yet? See it work in 30 seconds:
evalview demoRelated MCP server: openclaw-output-vetter-mcp
Why snapshot testing (and not assertions)?
Most eval tools ask you to write down what "good" looks like — assertions, metrics, rubrics. That's a lot of upfront work, and you can only catch the failures you thought to assert.
EvalView inverts it: it records what your agent actually does now, and flags any drift from that. You catch regressions you never anticipated, with zero assertions written. When the new behavior is correct, evalview snapshot accepts it as the new baseline — same as updating a snapshot in Jest.
EvalView | Assertion-based eval tools | |
Setup | Record current behavior | Write assertions/metrics first |
Catches | Any drift from baseline | Only what you asserted |
Non-determinism | Multi-variant baselines (up to 5 valid paths) | You handle it |
Unit of comparison | Full tool-call trajectory | Usually final output |
This makes EvalView a merge-time regression gate, which is a different job from observability (Langfuse, LangSmith) or metric scoring (promptfoo, DeepEval, Braintrust). Many teams run one of those for visibility and EvalView as the gate. Honest comparisons →
EvalView tests itself in public, every day
The badge at the top is live. Every day at 09:00 UTC, a GitHub Action runs EvalView against EvalView — including a regression check where the tool snapshots a live agent and diffs it with the same snapshot / check loop this README asks you to trust. It also runs the full test suite, type checks, evalview demo, the end-to-end flows, an evalview monitor smoke test, and chat-mode self-tests.
When something breaks, the run opens a single rolling 🐕 dogfood issue and keeps updating it until the tool is green again — so failures are public, not quietly patched.
Live dogfood runs → · How it works →
CI: block regressions in every PR
# .github/workflows/evalview.yml
name: EvalView
on: [pull_request]
jobs:
agent-check:
runs-on: ubuntu-latest
permissions: { pull-requests: write }
steps:
- uses: actions/checkout@v4
- uses: hidai25/eval-view@v0.8.0
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}You get a PR comment with the diff, cost/latency deltas, and a pass/fail gate. CI/CD guide →
Works with your stack
LangGraph · CrewAI · OpenAI · Claude · Mistral · Ollama · MCP · any HTTP API.
evalview check --agent http://localhost:8000/invokeUse it as a library
from evalview import gate
result = gate(test_dir="tests/")
result.passed # bool
result.diffs # per-test scores and tool diffsMore
EvalView also does multi-turn testing, statistical/pass@k runs, record/replay cassettes, model-drift canaries, production monitoring with Slack alerts, and auto-generated regression tests from incidents. These are power-user features — start with snapshot and check, reach for the rest when you need them.
→ Full feature reference · Getting Started · FAQ
Contributing
This is a young project built mostly by one developer. Issues, PRs, and "I tried it and X was confusing" feedback are all genuinely valuable.
License: Apache 2.0
Maintenance
Latest Blog Posts
- Who's Calling? MCP Hosts Are an Identity Blind Spot (And the Spec Knows It)By Om-Shree-0709 on .mcpAgent IdentityOAuth 2.1
- Your AI Chatbot Just Exposed Your CEO's Salary to an InternBy Om-Shree-0709 on .Agent IdentityMCP SecurityOAuth Delegation
- Why MCP Servers Need Execution Sandboxing (And Why Your Current Stack Isn't Enough)By Om-Shree-0709 on .Agentic AiPrompt InjectionWebAssembly
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/hidai25/eval-view'
If you have feedback or need assistance with the MCP directory API, please join our Discord server