
MCP-ArcKnowledge
Provides tools for managing and querying custom knowledge base webhook endpoints, allowing users to register sources, list available knowledge bases, and perform searches across one or multiple sources.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@MCP-ArcKnowledgesearch for recent product updates across all knowledge bases"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
MCP ArcKnowledge

How it works?
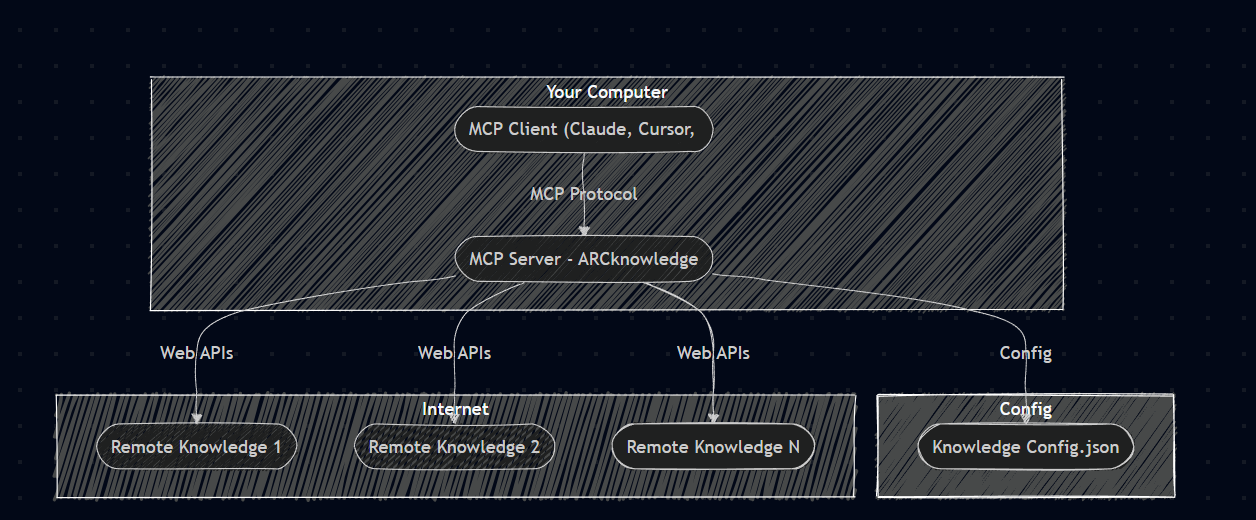
This is a Model Context Protocol (MCP) server for your custom webhook endpoints (knowledgebase).
With this you can you can easily manage and query your list of knowledge base(webhook endpoints). You can add new document sources by registering their URLs, and optionally provide a description and API key.
You can also list all the registered document sources and view their details.
When you're ready to ask/search, you can query the knowledge base with a text question , specifying which sources to search or leaving it blank to search all of them.
The tool will then aggregate the results from the queried sources and provide them to you.
Prerequisites
Go
Python 3.6+
Anthropic Claude Desktop app (or Cursor or Cline)
UV (Python package manager), install with
curl -LsSf https://astral.sh/uv/install.sh | sh
Related MCP server: SourceSync.ai MCP Server
Concept
Imagine being able to bridge 1 unified setup where you can connect all your custom knowledge base endpoints webhook in one configuration, eliminating the need for multiple MCP servers.
Demo

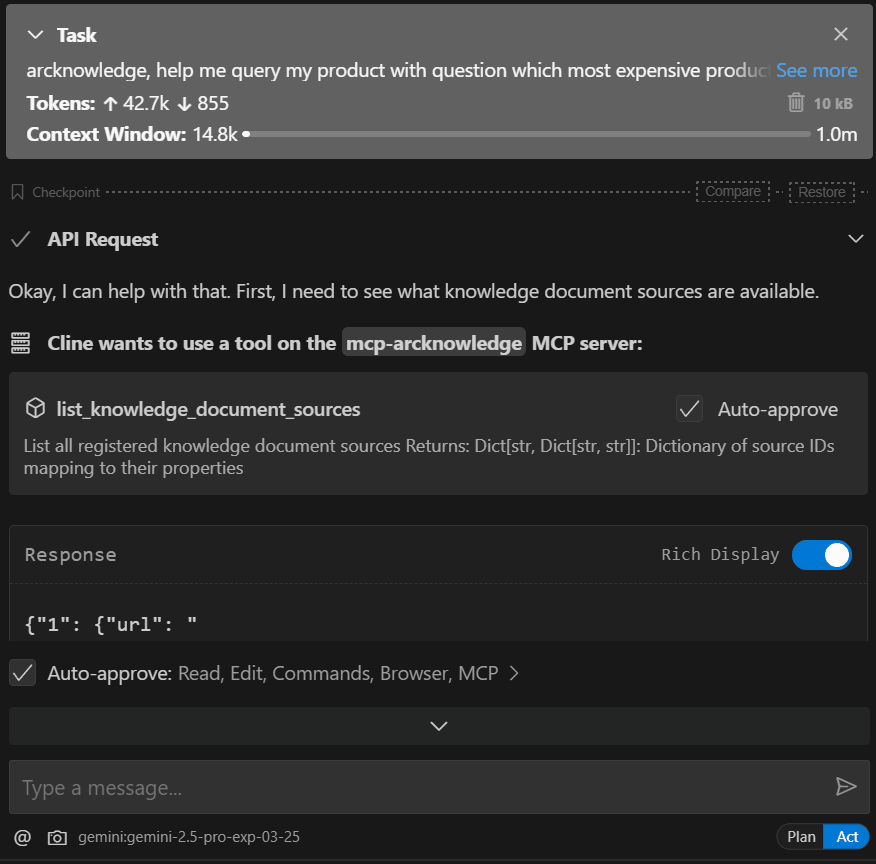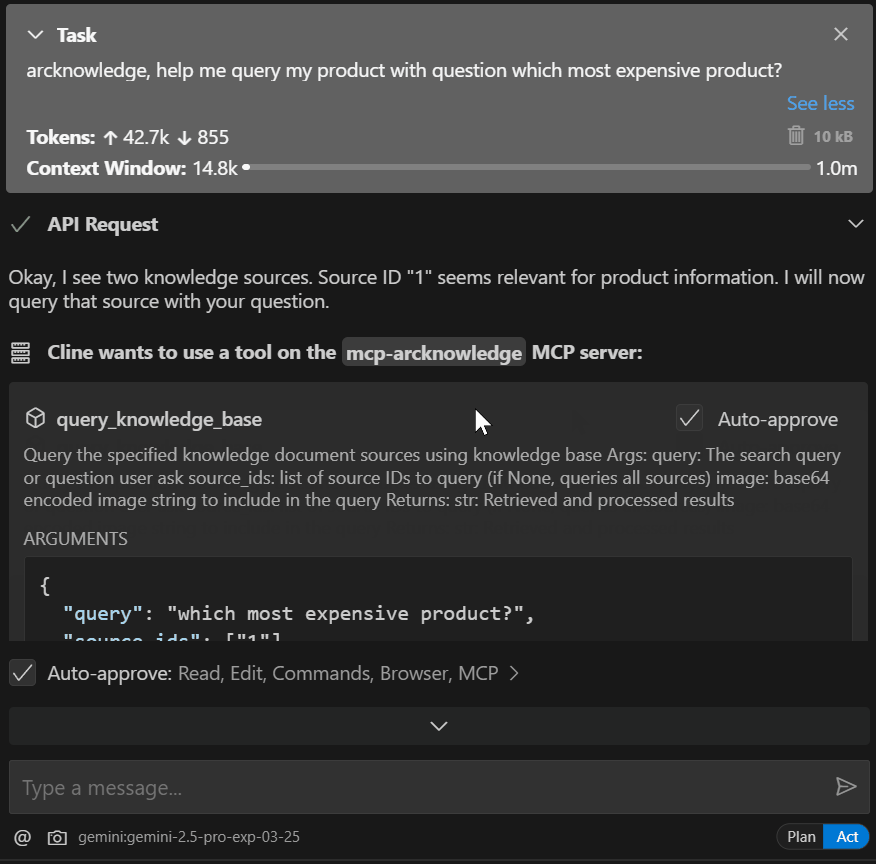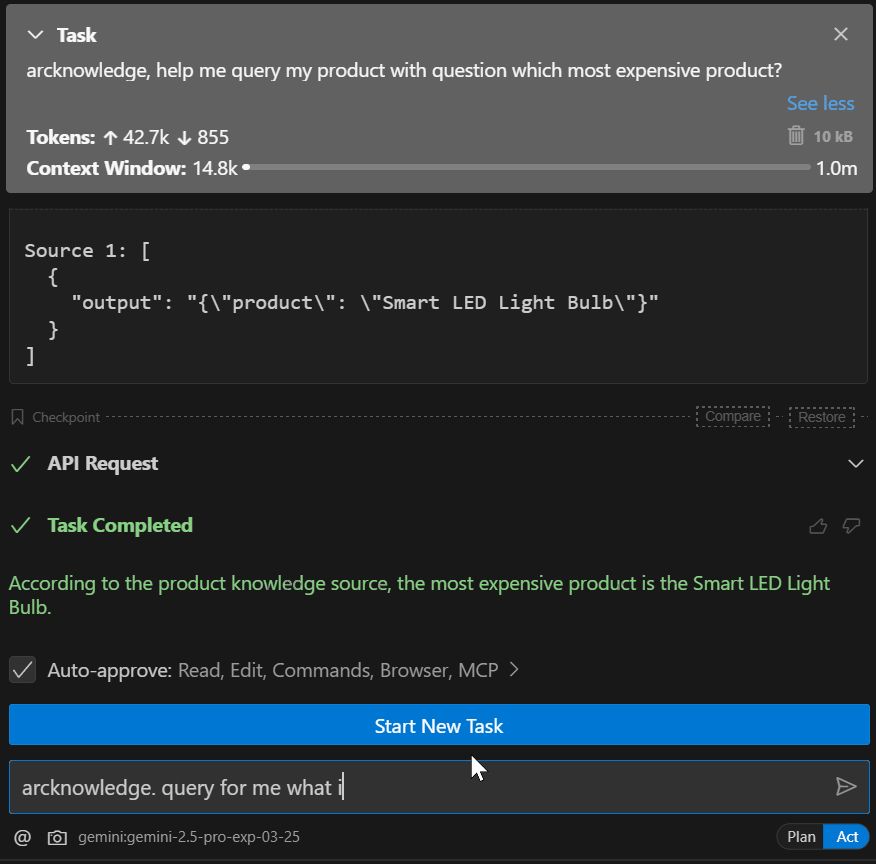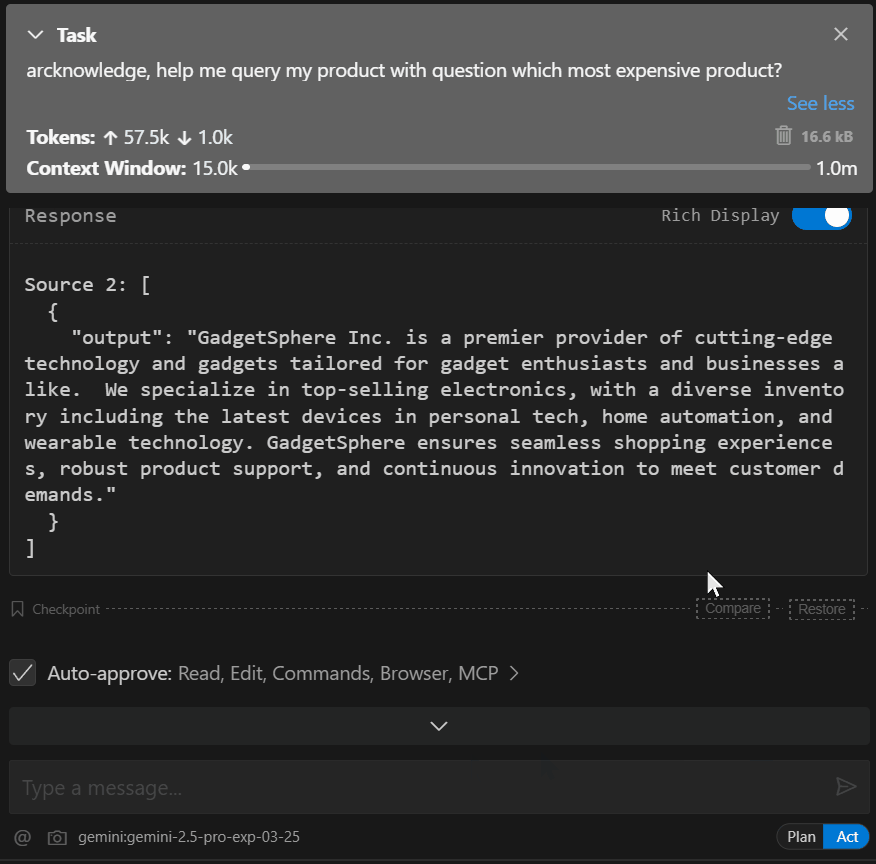
Setup Installation
Installing via Smithery
To install ArcKnowledge for Claude Desktop automatically via Smithery:
npx -y @smithery/cli install @dragonjump/mcp-ARCknowledge --client claude1.Clone repo
git clone https://github.com/dragonjump/mcp-arcknowledge
cd mcp-arcknowledgeConfigure endpoints Make a copy or change
knowledge_document_sources.json. Seesample_endpointfolder for references on current knowledge endpoints api schema supported. You may change the code as you wish to fit your need.Connect to the MCP server
Copy the below json with the appropriate {{PATH}} values:
{ "mcpServers": { "mcp-arcknowledge": { "command": "cmd /c uv", "args": [ "--directory", "C:/Users/Acer/OneDrive/GitHub/YourDrive", "run", "main.py" ], "env": { "DOCUMENT_SOURCES_PATH": "C:/Users/Acer/OneDrive/GitHub/YourDrive/testcustomother.json" } } } }
For Claude, save this as claude_desktop_config.json in your Claude Desktop configuration directory at:
~/Library/Application Support/Claude/claude_desktop_config.json
For Cursor, save this as mcp.json in your Cursor configuration directory at:
~/.cursor/mcp.jsonFor cline, save this as cline_mcp_settings.json in your configuration
Restart Client: Claude Desktop / Cursor / Cline / Windsurf Open and restart your client ide for mcp. eg Claude/Cursor/Cline/etc
Windows Compatibility
If you're running this project on Windows, be aware that go-sqlite3 requires CGO to be enabled in order to compile and work properly. By default, CGO is disabled on Windows, so you need to explicitly enable it and have a C compiler installed.
Steps to get it working:
Install a C compiler
We recommend using MSYS2 to install a C compiler for Windows. After installing MSYS2, make sure to add theucrt64\binfolder to yourPATH.
→ A step-by-step guide is available here.
Architecture Overview
This application consists of simple main component:
Python MCP Server (main.py): A Python server implementing the Model Context Protocol (MCP), which provides standardized tools client to interact with data and invoke api call.
Data Storage
All storage is runtime local main python server.
Technical Details
Client sends requests to the Python MCP server
The MCP server lookup its runtime config knowledge base.
Then based on your queries, it calls your knowledge base endpoint api,
Troubleshooting
If you encounter permission issues when running uv, you may need to add it to your PATH or use the full path to the executable.
Make sure both the Go application and the Python server are running for the integration to work properly.
Starting the Server
Config Run the server in development mode:
fastmcp dev main.pyOr install it for use with Claude:
fastmcp install main.pyAvailable Tools
1. Default Loads knowledge list from knowledge_document_sources.json
Default loads knowledge sources from config
knowledge_document_sources.json
You may Load custom knowledge from mcp.json environment config
"env": {
"DOCUMENT_SOURCES_PATH": "C:/Users/Acer/OneDrive/Somewhere/YourDrive/your-custom.json"
}2. List all currently registered knowledge sources
Shows and explains the list of all registered knowledge sources.
eg. Show me my arcknowledge list
3. Add New Knowledge Document Source
Add new arcknowledge endpoint url document sources. Provide url, description purpose and apikey(if any)
eg. Add new arcknowledge data source. Endpoint is http://something.com/api/123.
Purpose is to handle questions on 123 topic. Api key is 'sk-2123123'
4. Querying Specific Knowledge Doc Source
Query the arcknowledge base built from these sources using query_knowledge_base.
eg. Query for me my knowledge base for product. Question is : Which is most expensive product?
eg. Query for me my arcknowledge base for business. Question is :When is the business established?
eg. Query for me all my arcknowledge base . Question is :When is the business established? Which is most expensive product?Tool Functions
add_new_knowledge_document_source(url: str, description:str = None, apikey:str = None) -> strRegisters a new document source URL, optionally with a description and API key.
Returns: Confirmation message with the new source ID.
list_knowledge_document_sources() -> Dict[str, Dict[str, str]]Lists all registered document sources.
Returns: Dictionary mapping source IDs to their details (URL, description, API key).
query_knowledge_base(query: str, source_ids: List[str] = [], image: str = '') -> strQueries specified document sources (or all if none specified) with a text query and optional image data.
Returns: Aggregated results from the queried sources.
Development
Crucial filesProject Structure
mcp-arcknowledge/
├── main.py # Main server implementation
├── README.md # Documentation
├── requirements.txt # Project dependenciesCursor AI MCP Configuration
Create an
mcp.jsonfile in your project root:
{
"name": "mcp-webhook-ai-agent",
"version": "1.0.0",
"description": "Webhook AI agent with RAG capabilities",
"main": "main.py",
"tools": [
{
"name": "set_document_source",
"description": "Register a new document source URL for RAG operations"
},
{
"name": "list_document_sources",
"description": "List all registered document sources"
},
{
"name": "query_rag",
"description": "Query the specified document sources using RAG"
},
{
"name": "process_post_query",
"description": "Process a POST request with a query payload"
}
],
"dependencies": {
"fastmcp": ">=0.4.0",
"requests": ">=2.31.0",
"pydantic": ">=2.0.0"
}
}Configure Cursor AI:
Open Cursor AI settings
Navigate to the MCP section
Add the path to your
mcp.jsonfileRestart Cursor AI to apply changes
Verify Configuration:
# Check if MCP is properly configured
fastmcp check mcp.json
# List available tools
fastmcp listAdding New Features
Define new models in
main.pyAdd new tools using the
@mcp.tool()decoratorUpdate documentation as needed
License
MIT
Contributing
Fork the repository
Create your feature branch
Commit your changes
Push to the branch
Create a new Pull Request
{kind=link}
{kind=link}
{kind=link}
This server cannot be installed
Maintenance
Appeared in Searches
Latest Blog Posts
- Who's Calling? MCP Hosts Are an Identity Blind Spot (And the Spec Knows It)By Om-Shree-0709 on .mcpAgent IdentityOAuth 2.1
- Your AI Chatbot Just Exposed Your CEO's Salary to an InternBy Om-Shree-0709 on .Agent IdentityMCP SecurityOAuth Delegation
- Why MCP Servers Need Execution Sandboxing (And Why Your Current Stack Isn't Enough)By Om-Shree-0709 on .Agentic AiPrompt InjectionWebAssembly
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/dragonjump/mcp-arcknowledge'
If you have feedback or need assistance with the MCP directory API, please join our Discord server