
Supports downloading and using models from Hugging Face Hub for various computer vision tasks like object detection.
Uses Imgur for image hosting and sharing in the demonstration examples, displaying the results of image processing operations.
Utilizes NumPy for image manipulation operations, particularly for the cropping functionality through OpenCV's NumPy slicing approach.
Uses OpenCV for core image manipulation operations like cropping, resizing, and drawing text and shapes on images.
Leverages Ultralytics models for object detection and image analysis, allowing users to identify and locate objects in images with configurable confidence thresholds.
Integrates YOLO object detection models for identifying and locating objects in images with customizable confidence settings.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@🪄 ImageSorcery MCPremove the background from my profile photo.png"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
🪄 ImageSorcery MCP
ComputerVision-based 🪄 sorcery of local image recognition and editing tools for AI assistants
Official website: imagesorcery.net
✅ With ImageSorcery MCP
🪄 ImageSorcery empowers AI assistants with powerful image processing capabilities:
✅ Crop, resize, and rotate images with precision
✅ Remove background
✅ Draw text and shapes on images
✅ Add logos and watermarks
✅ Detect objects using state-of-the-art models
✅ Extract text from images with OCR
✅ Use a wide range of pre-trained models for object detection, OCR, and more
✅ Do all of this locally, without sending your images to any servers
Just ask your AI to help with image tasks:
"copy photos with pets from folder
photosto folderpets"
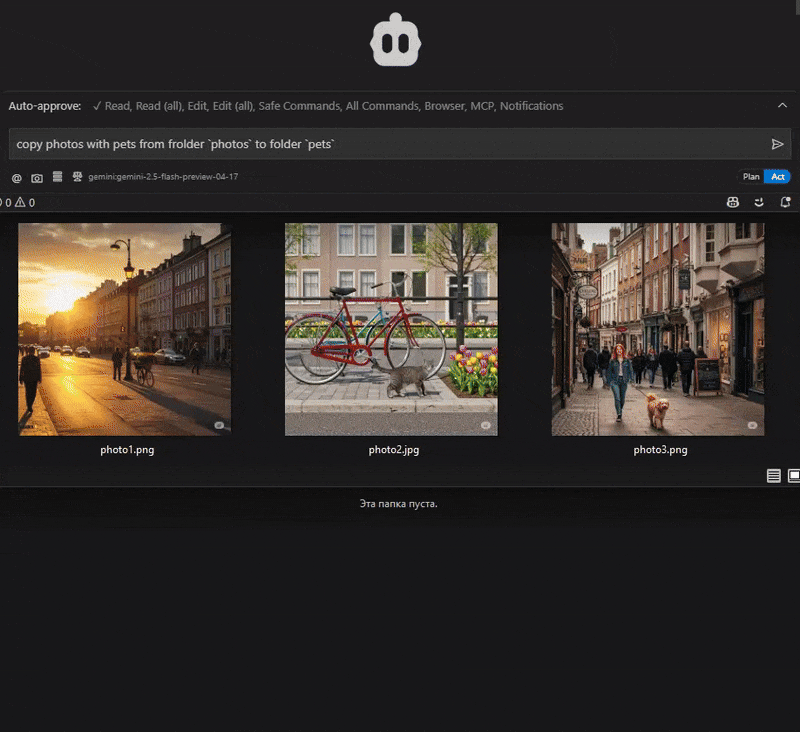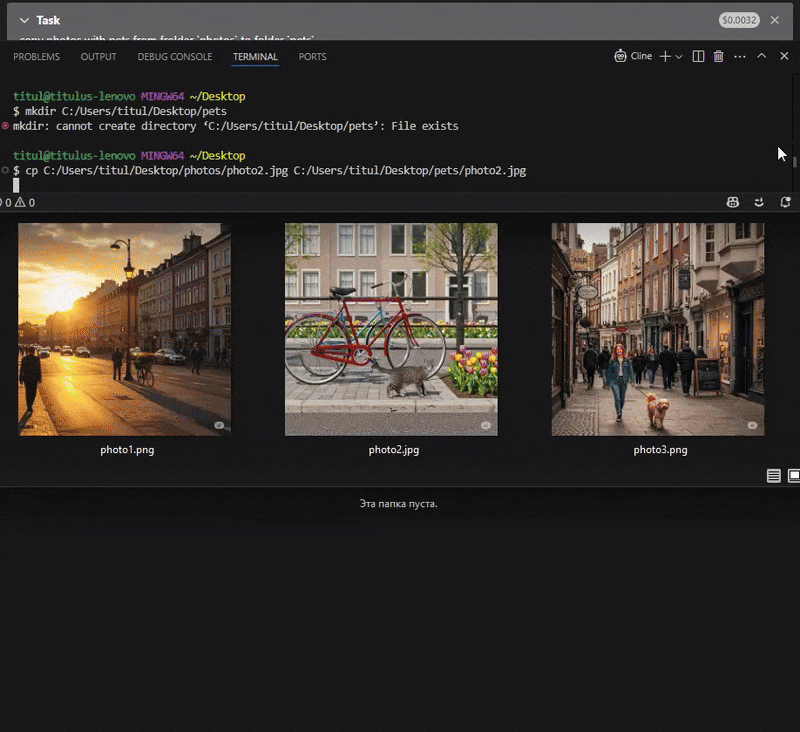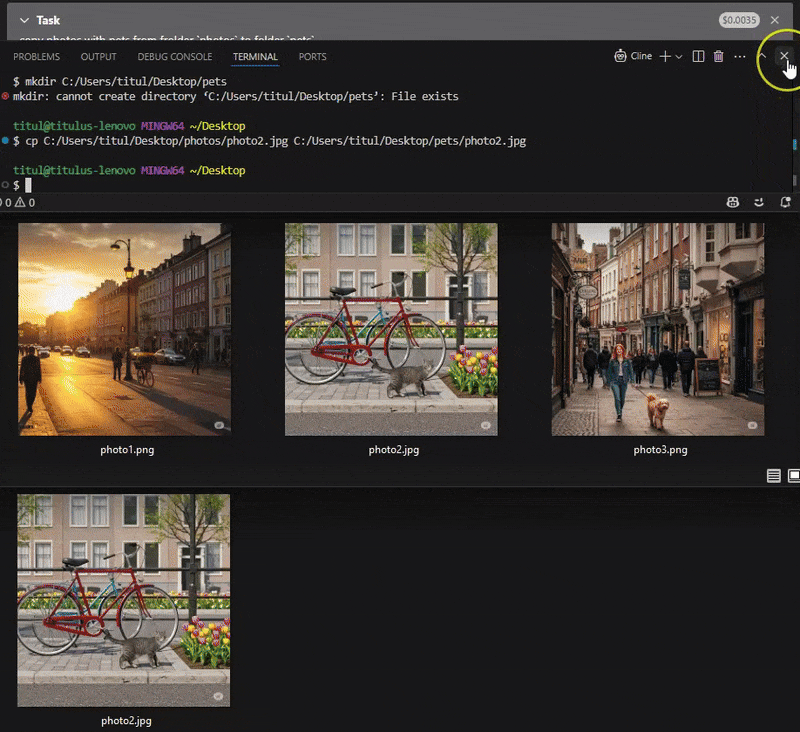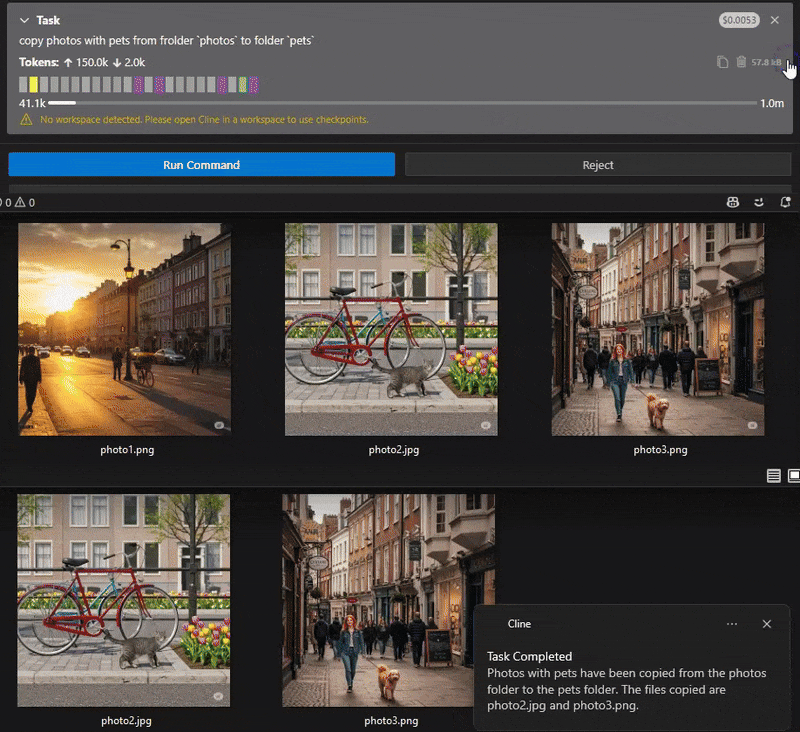
"Find a cat at the photo.jpg and crop the image in a half in height and width to make the cat be centered"
😉 Hint:
"Enumerate form fields on this
form.jpgwithfoduucom/web-form-ui-field-detectionmodel and fill theform.mdwith a list of described fields"😉 Hint:
😉 Hint:
Your tool will combine multiple tools listed below to achieve your goal.
Related MCP server: AI Development Assistant MCP Server
🛠️ Available Tools
Tool | Description | Example Prompt |
| Blurs specified rectangular or polygonal areas of an image using OpenCV. Can also invert the provided areas e.g. to blur background. | "Blur the area from (150, 100) to (250, 200) with a blur strength of 21 in my image 'test_image.png' and save it as 'output.png'" |
| Changes the color palette of an image | "Convert my image 'test_image.png' to sepia and save it as 'output.png'" |
| View and update ImageSorcery MCP configuration settings | "Show me the current configuration" or "Set the default detection confidence to 0.8" |
| Crops an image using OpenCV's NumPy slicing approach | "Crop my image 'input.png' from coordinates (10,10) to (200,200) and save it as 'cropped.png'" |
| Detects objects in an image using models from Ultralytics. Can return segmentation masks (as PNG files) or polygons. | "Detect objects in my image 'photo.jpg' with a confidence threshold of 0.4" |
| Draws arrows on an image using OpenCV | "Draw a red arrow from (50,50) to (150,100) on my image 'photo.jpg'" |
| Draws circles on an image using OpenCV | "Draw a red circle with center (100,100) and radius 50 on my image 'photo.jpg'" |
| Draws lines on an image using OpenCV | "Draw a red line from (50,50) to (150,100) on my image 'photo.jpg'" |
| Draws rectangles on an image using OpenCV | "Draw a red rectangle from (50,50) to (150,100) and a filled blue rectangle from (200,150) to (300,250) on my image 'photo.jpg'" |
| Draws text on an image using OpenCV | "Add text 'Hello World' at position (50,50) and 'Copyright 2023' at the bottom right corner of my image 'photo.jpg'" |
| Fills specified rectangular, polygonal, or mask-based areas of an image with a color and opacity, or makes them transparent. Can also invert the provided areas e.g. to remove background. | "Fill the area from (150, 100) to (250, 200) with semi-transparent red in my image 'test_image.png'" |
| Finds objects in an image based on a text description. Can return segmentation masks (as PNG files) or polygons. | "Find all dogs in my image 'photo.jpg' with a confidence threshold of 0.4" |
| Gets metadata information about an image file | "Get metadata information about my image 'photo.jpg'" |
| Performs Optical Character Recognition (OCR) on an image using EasyOCR | "Extract text from my image 'document.jpg' using OCR with English language" |
| Overlays one image on top of another, handling transparency | "Overlay 'logo.png' on top of 'background.jpg' at position (10, 10)" |
| Resizes an image using OpenCV | "Resize my image 'photo.jpg' to 800x600 pixels and save it as 'resized_photo.jpg'" |
| Rotates an image using imutils.rotate_bound function | "Rotate my image 'photo.jpg' by 45 degrees and save it as 'rotated_photo.jpg'" |
😉 Hint:
📚 Available Resources
Resource URI | Description | Example Prompt |
| Lists all available models in the models directory | "Which models are available in ImageSorcery?" |
😉 Hint:
💬 Available Prompts
Prompt Name | Description | Example Usage |
| Guides the AI through a comprehensive background removal workflow using object detection and masking tools | "Use the remove-background prompt to remove the background from my photo 'portrait.jpg', keeping only the person" |
😉 Hint:
🚀 Getting Started
Requirements
Python 3.10or higherpipx(recommended) - for easy installation and virtual environment managementffmpeg,libsm6,libxext6,libgl1-mesa-glx- system libraries required by OpenCVClaude.app,Cline, or another MCP client
These dependencies are typically included with OpenCV installation and don't require separate installation. But they might be missing in some virtual environments like Docker.
For Ubuntu/Debian systems:
For Docker containers: Add this line to your Dockerfile:
Installation
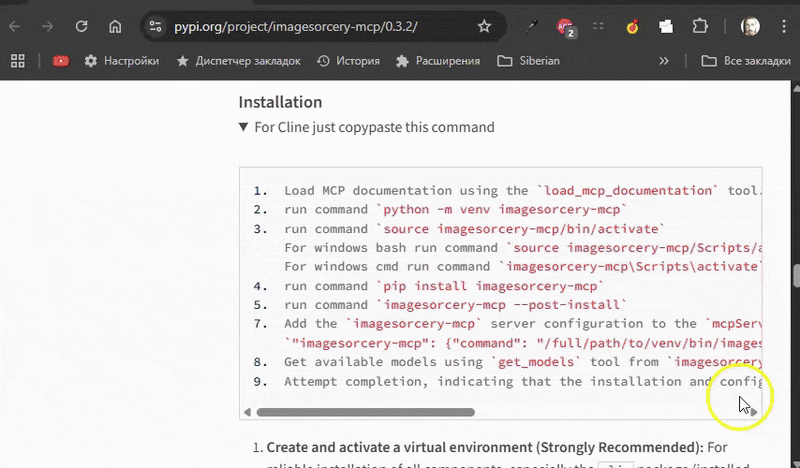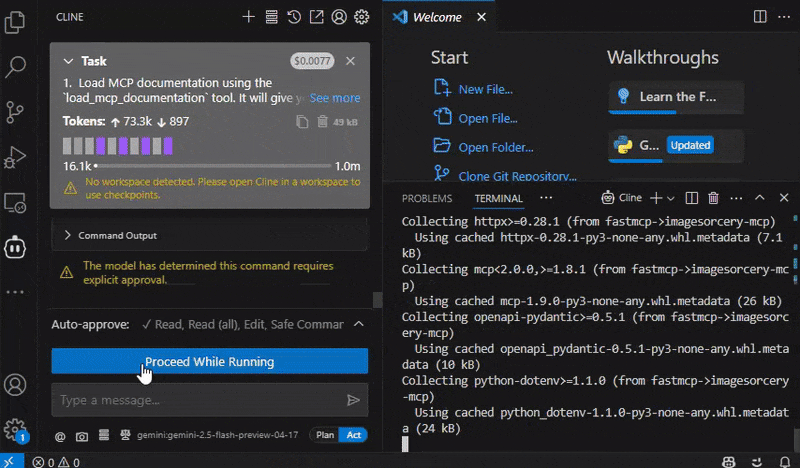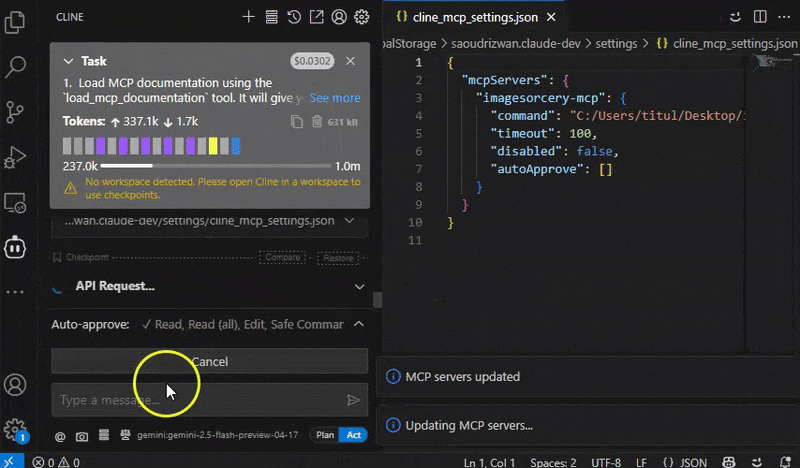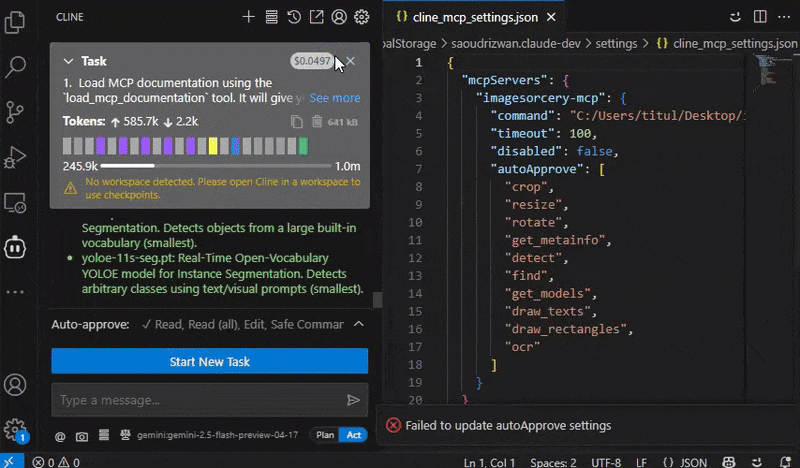
Method 1: Using pipx (Recommended)
pipx is the recommended way to install ImageSorcery MCP as it automatically handles virtual environment creation and management, making the installation process much simpler.
Install pipx (if not already installed):
# On macOS with Homebrew: brew install pipx # On Ubuntu/Debian: sudo apt update && sudo apt install pipx # On other systems with pip: pip install --user pipx pipx ensurepath
Install ImageSorcery MCP with pipx:
pipx install imagesorcery-mcpRun the post-installation script: This step is crucial. It downloads the required models and attempts to install the
clipPython package from GitHub.imagesorcery-mcp --post-install
Method 2: Manual Virtual Environment (Plan B)
For reliable installation of all components, especially the clip package (installed via the post-install script), it is strongly recommended to use Python's built-in .
Create and activate a virtual environment:
python -m venv imagesorcery-mcp source imagesorcery-mcp/bin/activate # For Linux/macOS # source imagesorcery-mcp\Scripts\activate # For WindowsInstall the package into the activated virtual environment: You can use
piporuv pip.pip install imagesorcery-mcp # OR, if you prefer using uv for installation into the venv: # uv pip install imagesorcery-mcpRun the post-installation script: This step is crucial. It downloads the required models and attempts to install the
clipPython package from GitHub into the active virtual environment.imagesorcery-mcp --post-install
Note: When using this method, you'll need to provide the full path to the executable in your MCP client configuration (e.g., /full/path/to/venv/bin/imagesorcery-mcp).
Additional Notes
Creates a in the current directory, allowing users to customize default tool parameters.
Creates a
modelsdirectory (usually within the site-packages directory of your virtual environment, or a user-specific location if installed globally) to store pre-trained models.Generates an initial
models/model_descriptions.jsonfile there.Downloads default YOLO models (
yoloe-11l-seg-pf.pt,yoloe-11s-seg-pf.pt,yoloe-11l-seg.pt,yoloe-11s-seg.pt) required by thedetecttool into thismodelsdirectory.Attempts to install the from Ultralytics' GitHub repository directly into the active Python environment. This is required for text prompt functionality in the
findtool.Downloads the CLIP model file required by the
findtool into themodelsdirectory.
You can run this process anytime to restore the default models and attempt clip installation.
Using Based on testing, virtual environments created with
uv venvmay not includepipin a way that allows theimagesorcery-mcp --post-installscript to automatically install theclippackage from GitHub (it might result in a "No module named pip" error during theclipinstallation step). If you choose to useCreate and activate your
uv venv.Install
imagesorcery-mcp:uv pip install imagesorcery-mcp.Manually install the
clippackage into your activeuv venv:uv pip install git+https://github.com/ultralytics/CLIP.gitRun
imagesorcery-mcp --post-install. This will download models but may fail to install theclipPython package. For a smoother automatedclipinstallation via the post-install script, usingpython -m venv(as described in step 1 above) is the recommended method for creating the virtual environment.
Using Running the post-installation script directly with
uvx(e.g.,uvx imagesorcery-mcp --post-install) will likely fail to install theclipPython package. This is because the temporary environment created byuvxtypically does not havepipavailable in a way the script can use. Models will be downloaded, but theclippackage won't be installed by this command. If you intend to useuvxto run the mainimagesorcery-mcpserver and requireclipfunctionality, you'll need to ensure theclippackage is installed in an accessible Python environment thatuvxcan find, or consider installingimagesorcery-mcpinto a persistent environment created withpython -m venv.
⚙️ Configure MCP client
Add to your MCP client these settings.
For pipx installation (recommended):
For manual venv installation:
For pipx installation (recommended):
For manual venv installation:
📦 Additional Models
Some tools require specific models to be available in the models directory:
When downloading models, the script automatically updates the models/model_descriptions.json file:
For Ultralytics models: Descriptions are predefined in
src/imagesorcery_mcp/scripts/create_model_descriptions.pyand include detailed information about each model's purpose, size, and characteristics.For Hugging Face models: Descriptions are automatically extracted from the model card on Hugging Face Hub. The script attempts to use the model name from the model index or the first line of the description.
After downloading models, it's recommended to check the descriptions in models/model_descriptions.json and adjust them if needed to provide more accurate or detailed information about the models' capabilities and use cases.
Running the Server
ImageSorcery MCP server can be run in different modes:
STDIO- defaultStreamable HTTP- for web-based deploymentsServer-Sent Events (SSE)- for web-based deployments that rely on SSE
STDIO Mode (Default) - This is the standard mode for local MCP clients:
imagesorcery-mcpStreamable HTTP Mode - For web-based deployments:
imagesorcery-mcp --transport=streamable-httpWith custom host, port, and path:
imagesorcery-mcp --transport=streamable-http --host=0.0.0.0 --port=4200 --path=/custom-path
Available transport options:
--transport: Choose between "stdio" (default), "streamable-http", or "sse"--host: Specify host for HTTP-based transports (default: 127.0.0.1)--port: Specify port for HTTP-based transports (default: 8000)--path: Specify endpoint path for HTTP-based transports (default: /mcp)
🔒 Privacy & Telemetry
We are committed to your privacy. ImageSorcery MCP is designed to run locally, ensuring your images and data stay on your machine.
To help us understand which features are most popular and fix bugs faster, we've included optional, anonymous telemetry.
It is disabled by default. You must explicitly opt-in to enable it.
What we collect: Anonymized usage data, including features used (e.g.,
crop,detect), application version, operating system type (e.g., 'linux', 'win32'), and tool failures.What we NEVER collect: We do not collect any personal or sensitive information. This includes image data, file paths, IP addresses, or any other personally identifiable information.
How to enable/disable: You can control telemetry by setting
enabled = trueorenabled = falsein the[telemetry]section of yourconfig.tomlfile.
⚙️ Configuring the Server
The server can be configured using a config.toml file in the current directory. The file is created automatically during installation with default values. You can customize the default tool parameters in this file. More in CONFIG.md.
🤝 Contributing
Directory Structure
This repository is organized as follows:
Development Setup
Clone the repository:
(Recommended) Create and activate a virtual environment:
Install the package in editable mode along with development dependencies:
This will install imagesorcery-mcp and all dependencies from [project.dependencies] and [project.optional-dependencies].dev (including build and twine).
Rules
These rules apply to all contributors: humans and AI.
Read all the
README.mdfiles in the project. Understand the project structure and purpose. Understand the guidelines for contributing. Think through how it relates to your task, and how to make changes accordingly.Read
pyproject.toml. Pay attention to sections:[tool.ruff],[tool.ruff.lint],[project.optional-dependencies]and[project]dependencies. Strictly follow code style defined inpyproject.toml. Stick to the stack defined inpyproject.tomldependencies and do not add any new dependencies without a good reason.Write your code in new and existing files. If new dependencies are needed, update
pyproject.tomland install them viapip install -e .orpip install -e ".[dev]". Do not install them directly viapip install. Check out existing source codes for examples (e.g.src/imagesorcery_mcp/server.py,src/imagesorcery_mcp/tools/crop.py). Stick to the code style, naming conventions, input and output data formats, code structure, architecture, etc. of the existing code.Update related
README.mdfiles with your changes. Stick to the format and structure of the existingREADME.mdfiles.Write tests for your code. Check out existing tests for examples (e.g.
tests/test_server.py,tests/tools/test_crop.py). Stick to the code style, naming conventions, input and output data formats, code structure, architecture, etc. of the existing tests.Run tests and linter to ensure everything works:
In case of failures - fix the code and tests. It is strictly required to have all new code to comply with the linter rules and pass all tests.
Coding hints
Use type hints where appropriate
Use pydantic for data validation and serialization
📝 Questions?
If you have any questions, issues, or suggestions regarding this project, feel free to reach out to:
You can also open an issue in the repository for bug reports or feature requests.
📜 License
This project is licensed under the MIT License. This means you are free to use, modify, and distribute the software, subject to the terms and conditions of the MIT License.