
Utilizes LangChain for document chunking and processing, with configurable parameters for chunk size and overlap
Converts PDF content to Markdown format for better processing and stores it in a parsing cache for efficient retrieval
Uses OpenAI embeddings for semantic search capabilities, allowing for intelligent document search and retrieval from PDF collections
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@PDF Knowledgebase MCP Serverfind the section about semiconductor specifications in the datasheets"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
PDF Knowledgebase MCP Server
A powerful Model Context Protocol (MCP) server that transforms your PDF and Markdown document collection into an intelligent, searchable knowledge base. Built for seamless integration with Claude Desktop, VS Code, Continue, and other MCP-enabled AI assistants.
Description
pdfkb-mcp processes your documents using advanced PDF parsing, creates semantic embeddings, and provides sophisticated search capabilities through the Model Context Protocol. Whether you're managing research papers, technical documentation, or business reports, pdfkb-mcp makes your document collection instantly searchable and accessible to your AI assistant.
Motivation
I built pdfkb-mcp because I needed a way to efficiently index and search through hundreds of semiconductor datasheets and technical documents. Traditional file search wasn't sufficient—I needed semantic understanding, context preservation, and the ability to ask complex questions about technical specifications across multiple documents. This tool has transformed how I work with technical documentation, and I'm sharing it so others can benefit from intelligent document search in their workflows.
Related MCP server: doc-lib-mcp
✨ Features
🤖 Intelligent Document Processing
Multiple PDF Parsers: PyMuPDF4LLM (fast), Marker (balanced), Docling (tables), MinerU (academic), LLM (complex layouts)
Markdown Support: Native processing of .md and .markdown files with metadata extraction
Smart Chunking: LangChain, semantic, page-based, and unstructured chunking strategies
Background Processing: Non-blocking document processing with intelligent caching
🔍 Advanced Search & AI
Hybrid Search: Combines semantic similarity with keyword matching (BM25) for superior results
AI Reranking: Qwen3-Reranker models improve search relevance by 15-30%
Local & Remote Embeddings: Privacy-focused local models or high-performance API-based options
Document Summarization: Auto-generates rich metadata with titles, descriptions, and summaries
🌐 Multi-Client & Remote Access
MCP Protocol Support: Works with Claude Desktop, VS Code, Continue, Cline, and other MCP clients
Web Interface: Modern web UI for document management, search, and analysis
HTTP/SSE Transport: Remote access from multiple clients simultaneously
Docker Deployment: Production-ready containerized deployment
🔒 Privacy & Performance
Local-First Option: Run completely offline with local embeddings—no API costs, full privacy
Quantized Models: GGUF models use 50-70% less memory with maintained quality
Best Practices: Background processing, health checks, monitoring, and scalability
🌐 Web Interface Preview
Once your setup is complete, you'll have access to a modern web interface for document management and search:
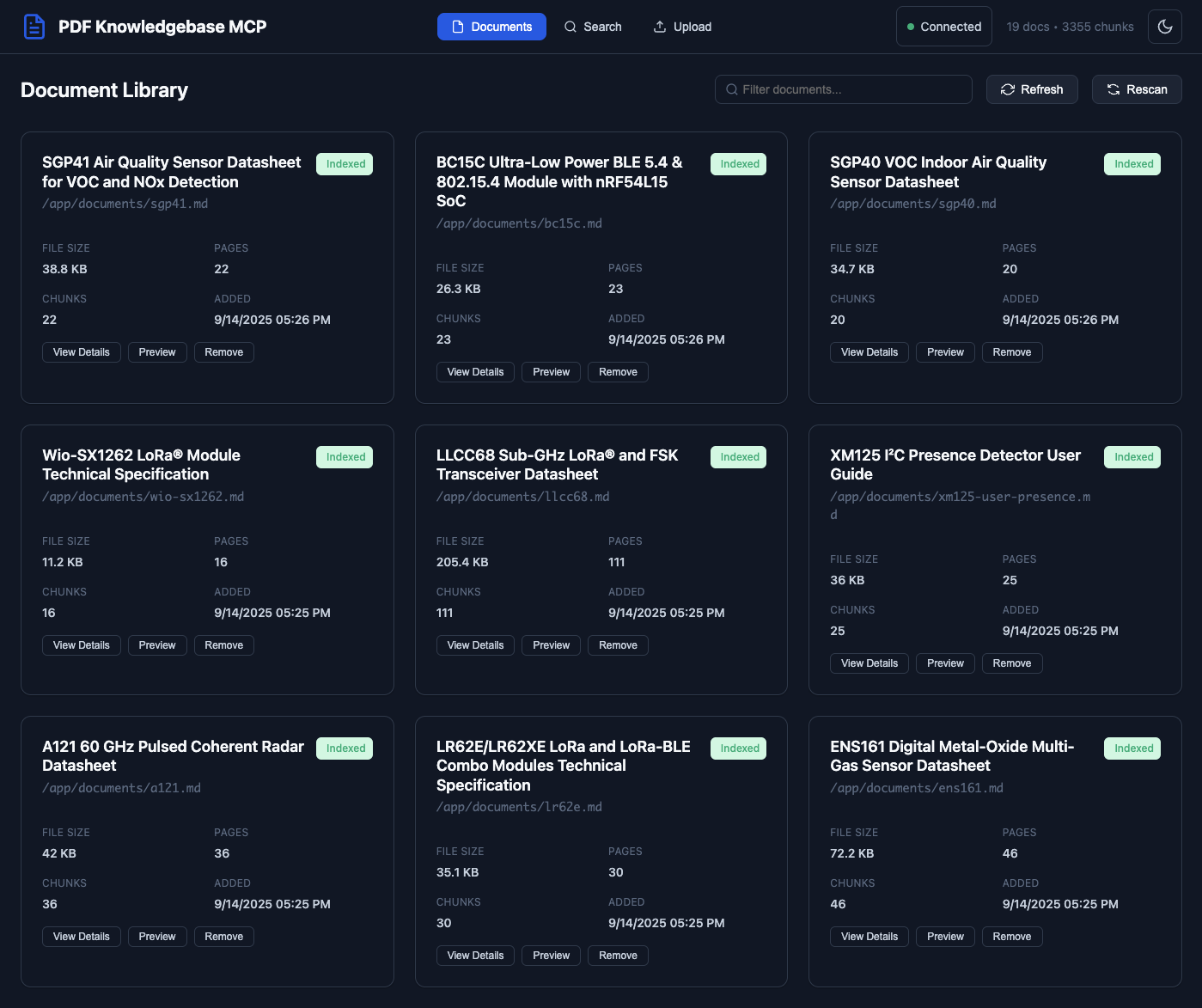
The web interface provides document upload, real-time processing status, semantic search, and comprehensive document management capabilities.
Key Features:
🔍 Real-time Search: Instant semantic and hybrid search
📊 Processing Status: Live updates on document processing
📈 Document Analytics: View chunks, metadata, and summaries
⚙️ System Monitoring: Server performance and resource usage
🚀 Quick Start
Get up and running in minutes using Docker/Podman with DeepInfra as your AI provider.
Prerequisites
Container Runtime: Docker or Podman installed
DeepInfra API Key: Get your free key (recommended for cost-effectiveness)
Documents: A folder with PDF or Markdown files to index
1. Set Up Docker Compose
2. Start the Server
Access Points:
Web Interface: http://localhost:8000
MCP Endpoint: http://localhost:8000/mcp/
Health Check: http://localhost:8000/health
3. Configure Your MCP Client
Claude Desktop - Add to claude_desktop_config.json:
VS Code with Continue - Add to .continue/config.json:
4. Add Your Documents
Web Interface: Open http://localhost:8000
File System: Copy files to your documents directory — they're automatically detected
5. Start Searching
Ask your AI assistant to search your documents:
"What register do I need to configure to reset charging in the nPM1300?"
"Is XYZ a clock capable pin according to the nRF54L15 datasheet?"
"What is the conversion formula to interpret temperature as celcius according to the XYZ datashet?"
The setup includes:
✅ DeepInfra AI: Cost-effective embeddings, reranking, and document summarization
✅ Hybrid Search: Semantic + keyword matching
✅ Document Summarization: Auto-generated metadata (i.e. title, description)
✅ Web Interface: Document management UI
✅ Persistent Storage: Documents and cache preserved
📚 User Guide
For complete documentation, configuration options, and advanced features:
👉
The user guide includes:
📦 Installation Options - uvx, pip, Docker setup
⚙️ Configuration - Environment variables and settings
🔍 Search Features - Hybrid search, reranking, semantic chunking
🤖 Embeddings - Local, OpenAI, and HuggingFace options
🔌 MCP Clients - Setup guides for all MCP clients
🐳 Docker Deployment - Production deployment guide
🔧 Troubleshooting - Common issues and performance tuning
🎯 Advanced Features - Document summarization and enterprise features
License
This project is licensed under the MIT License - see the LICENSE file for details.
Appeared in Searches
- A server for searching and retrieving information using keyword, semantic, or hybrid search methods
- Document analysis tools for legal documents and evidence
- Semantic search, RAG, and memory systems
- A server for searching research papers, Kaggle datasets, and websites for ML/AI model training data
- Information about RAG (Retrieval-Augmented Generation) or rag-related topics