
Umami 分析 MCP 服务器
模型上下文协议 (MCP) 服务器,通过提供 Umami 网站分析数据的访问权限,增强了 Claude 的功能。该服务器允许 Claude 分析用户行为、跟踪网站性能并提供数据驱动的洞察。
代码库从头到尾都是使用 Claude Sonnet 3.5 和 Cursor 生成的。
它的作用
该服务器将 Claude 连接到您的 Umami 分析平台,使其能够:
分析用户旅程和行为模式
跟踪网站性能指标
监控实时访客活动
捕获并分析网页内容
从历史分析数据中获取见解
Related MCP server: Google Ads MCP
工作原理
该服务器向Claude提供以下工具来分析网站数据:
可用工具
get_websites :检索 Umami 帐户中的网站及其 ID 列表
get_website_stats :获取网站的关键指标,例如页面浏览量、访客数量、跳出率
get_website_metrics :分析特定指标,例如 URL、引荐来源、浏览器、国家/地区
get_pageview_series :获取具有可自定义间隔的时间序列页面浏览数据
get_active_visitors :监控网站当前活跃访客数量
get_session_ids :检索特定事件或时间段的会话 ID
get_tracking_data :获取特定会话 ID 的详细活动数据
get_docs :对许多用户旅程执行语义搜索,返回给定问题最相关的块
get_screenshot :捕获网页的视觉快照
get_html :检索并分析网页 HTML 源代码
每个工具都有其描述和可传递给它的参数列表。这些参数用于提供上下文和信息,以便 Claude 有效地选择合适的工具,并提供正确的参数。
大多数此类工具直接从 Umami API 将数据提取到 Claude Desktop,但 get_docs 添加了语义搜索步骤,以避免 Claude 出现上下文窗口问题,并节省 token 使用量。使用 Umami API 检索给定事件的所有用户旅程,然后将其分块成更小的部分,并使用来自 Hugging Face 的开源句子转换器模型进行嵌入。然后,根据问题检索最相关的块并将其返回给 Claude,从而可以分析用户在网站上执行的特定操作和行为,这是传统数据可视化工具难以复制的功能。此嵌入和语义搜索的实现位于src/analytics_service/embeddings.py文件中。
此外,get_screenshot 和 get_html 工具使用开源Crawl4AI网络爬虫来检索指定网站的 HTML 源代码和屏幕截图。屏幕截图必须进行下采样以减小其大小,以避免 Claude 出现上下文窗口问题。这允许您向 Claude 提供有关网站结构和外观的上下文信息,从而提供更准确、更相关的网站性能改进建议。网络爬虫的实现位于src/analytics_service/crawler.py文件中。
设置指南
先决条件
安装 uv:
pip install uv
Claude桌面配置
将以下内容添加到您的 Claude Desktop 配置文件:
MacOS:
~/Library/Application Support/Claude/claude_desktop_config.jsonWindows:
%APPDATA%/Claude/claude_desktop_config.json
{ "mcpServers": { "analytics_service": { "command": "uv", "args": [ "--directory", "/path/to/analytics_service", "run", "analytics-service" ], "env": { "UMAMI_API_URL": "https://example.com", "UMAMI_USERNAME": "yourUmamiUsername", "UMAMI_PASSWORD": "yourUmamiPassword", "UMAMI_TEAM_ID": "yourUmamiTeamId" } } } }将
/path/to/analytics_service替换为您的 analytics_service 目录的实际路径。对于 UMAMI_API_URL,请将
https://example.com替换为您所使用的 Umami 版本的 URL(无论是自托管还是托管在 Umami Cloud 上)。对于 UMAMI_USERNAME 和 UMAMI_PASSWORD,请将yourUmamiUsername和yourUmamiPassword替换为您的 Umami 帐户凭据。对于 UMAMI_TEAM_ID,请将yourUmamiTeamId替换为您要分析的团队的 ID。打开Claude桌面
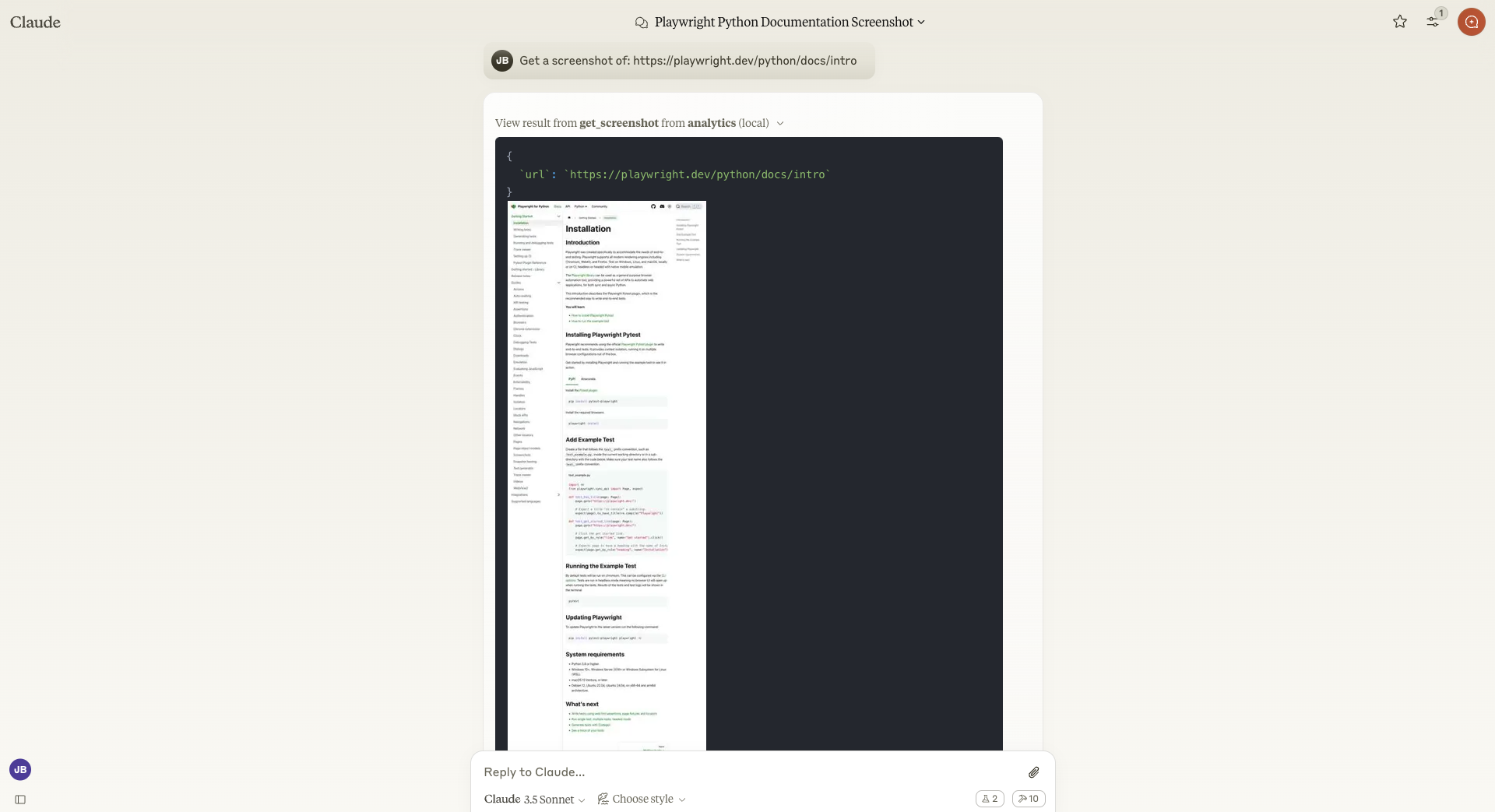
当您打开 Claude Desktop 时,它将自动连接到 analytics_service MCP 服务器。服务器初始化并安装正确的软件包可能需要几分钟时间。服务器准备就绪后,您将在聊天窗口右下角看到 10 个可用的 MCP 工具。它们以小锤子图标和旁边的数字 10 表示。
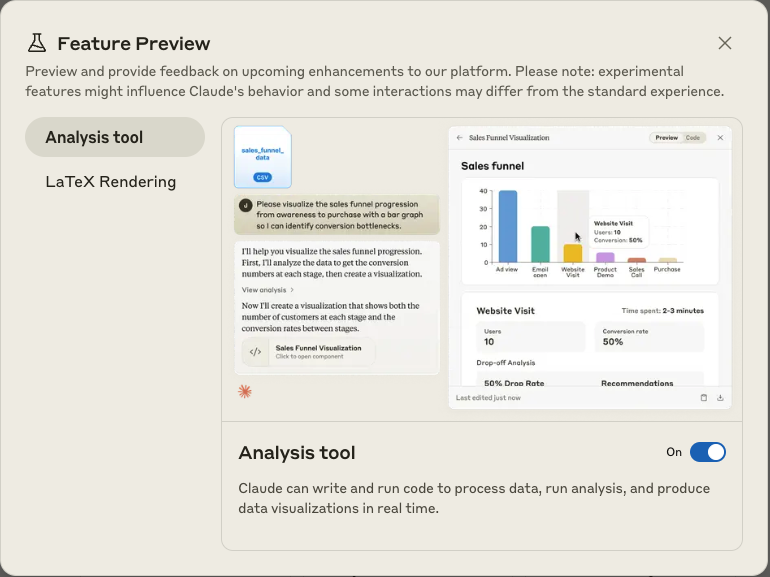
此外,如果您尚未启用,强烈建议您在 Claude Desktop 的功能预览中启用“分析工具”。这将允许 Claude 为您的数据构建仪表板以及其他可视化效果。为此,请在左侧面板中找到“功能预览”选项卡,并在其中启用“分析工具”。您也可以在同一部分中启用 LaTeX 渲染。
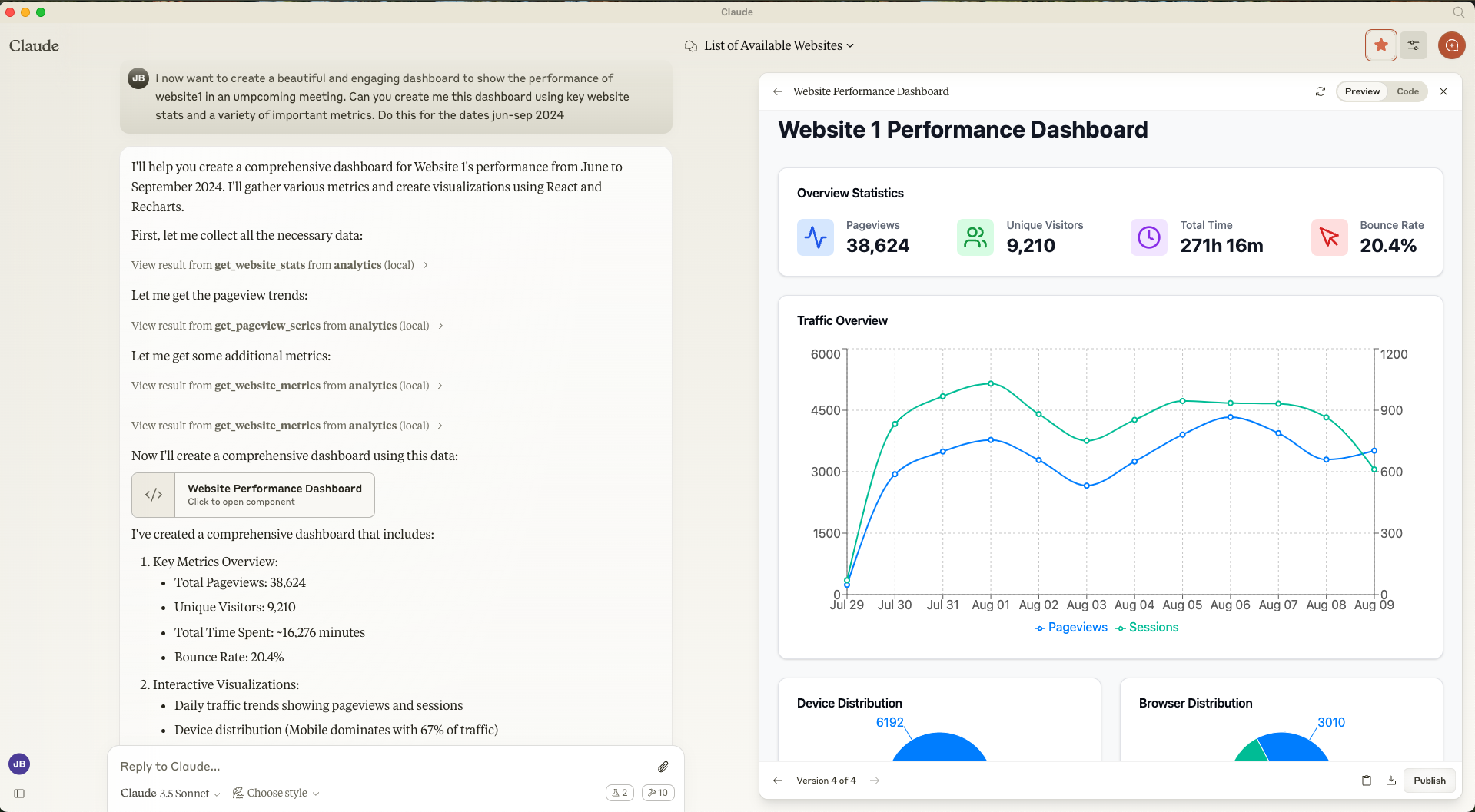
如何使用服务器
入门
最简单的方法是使用服务器提供的“创建仪表盘提示” 。点击聊天窗口左下角的“从 MCP 附加”附件按钮即可选择。然后选择“选择实现”,再选择“创建仪表盘提示”。
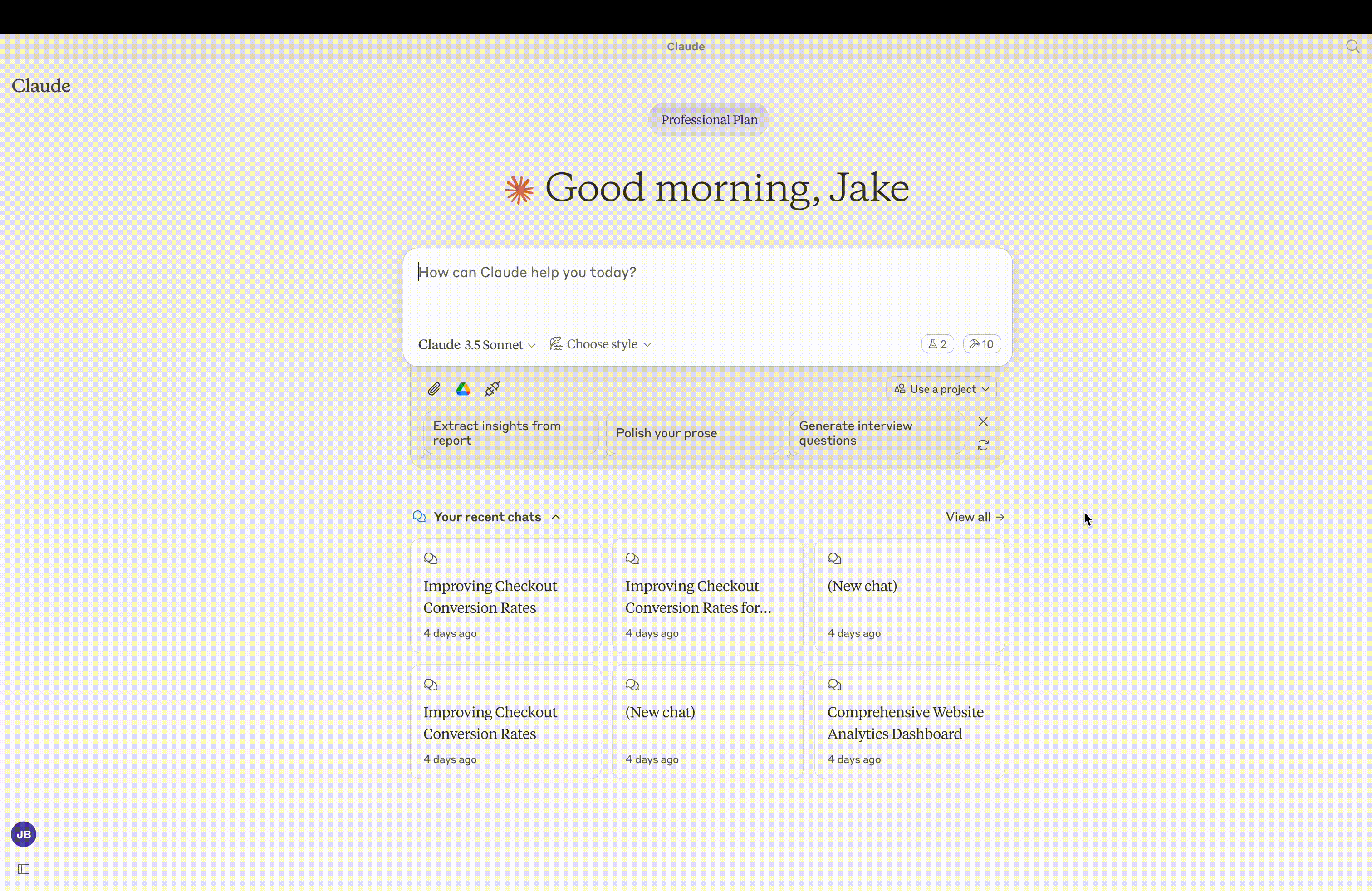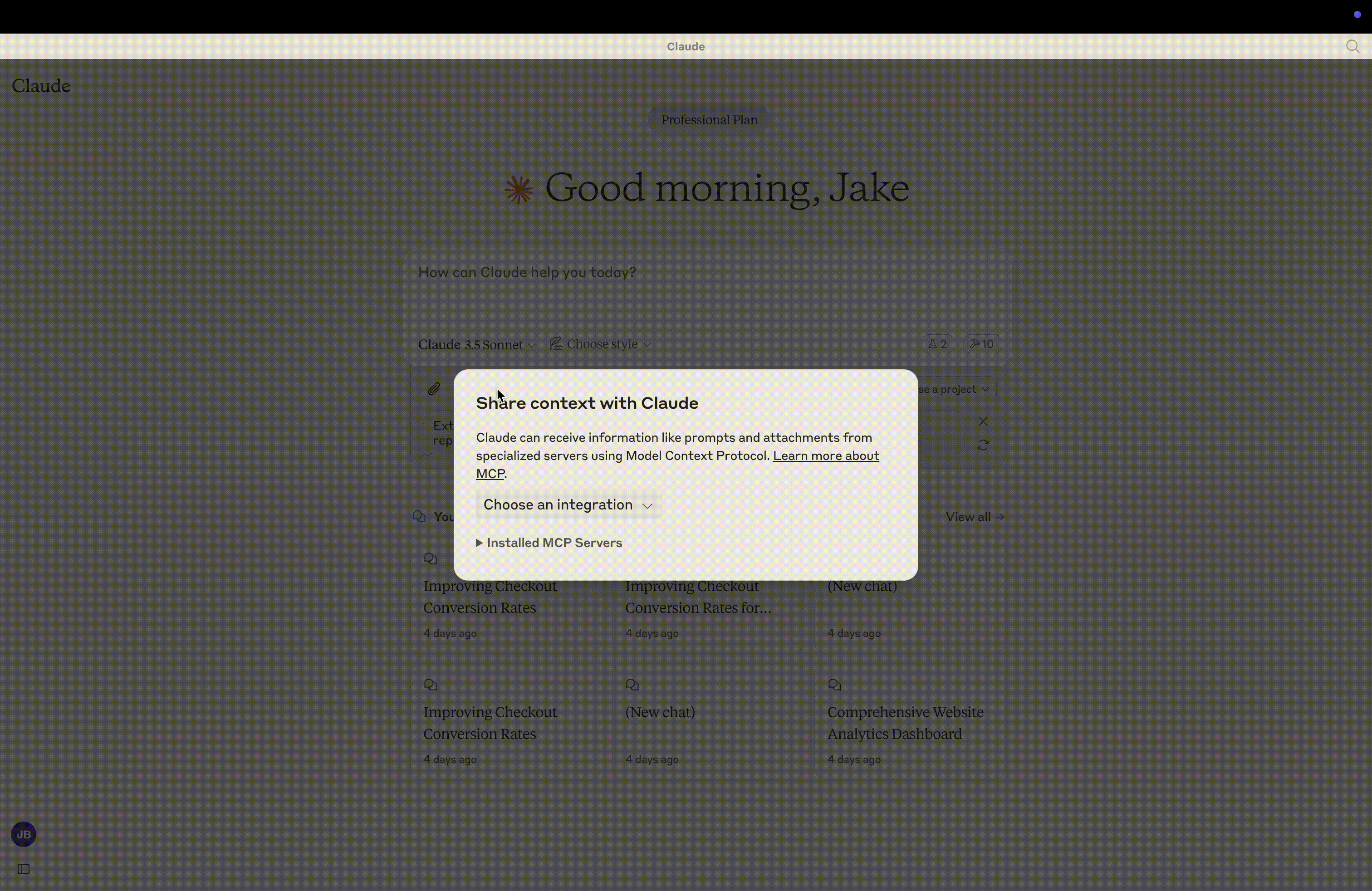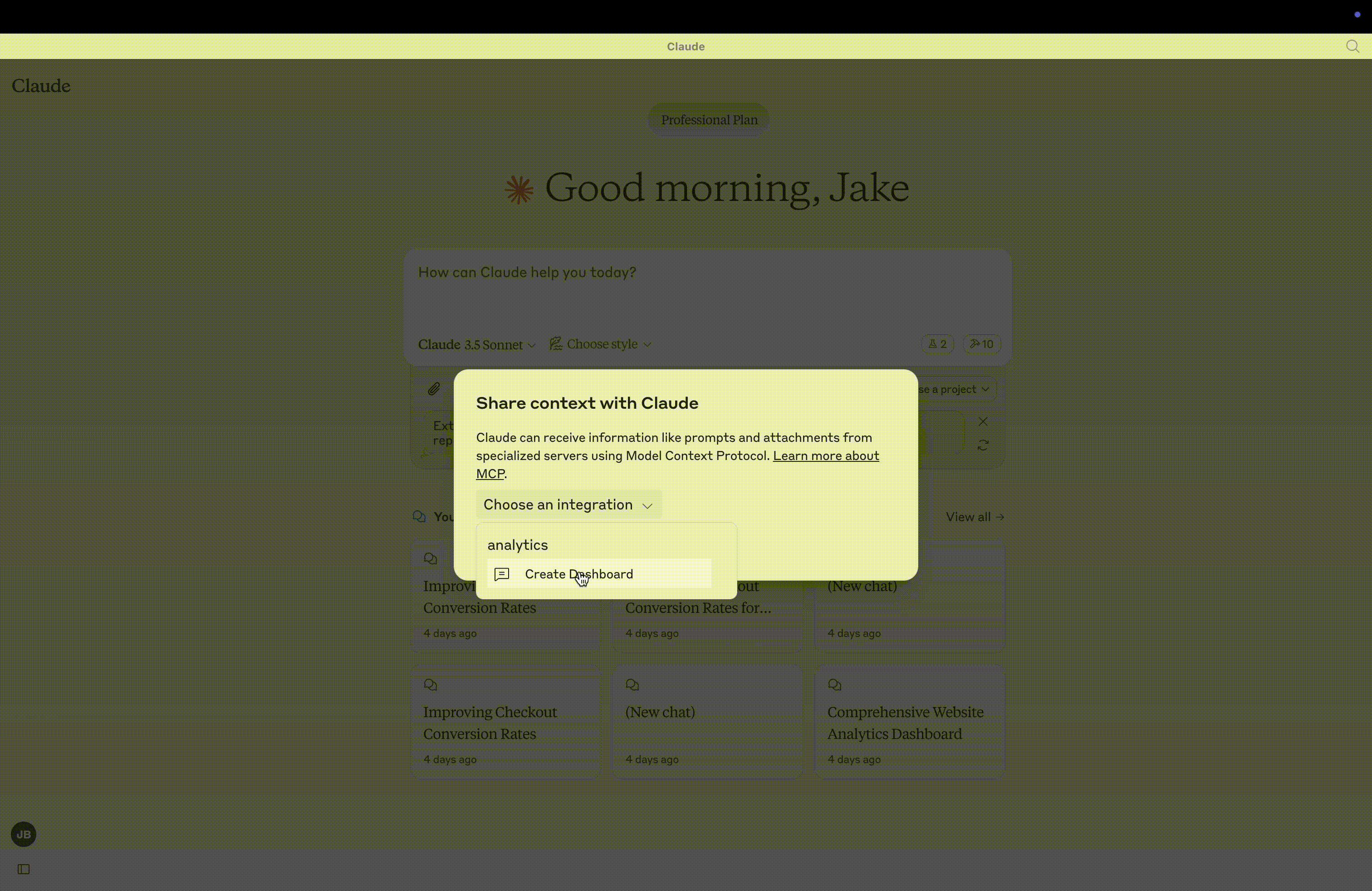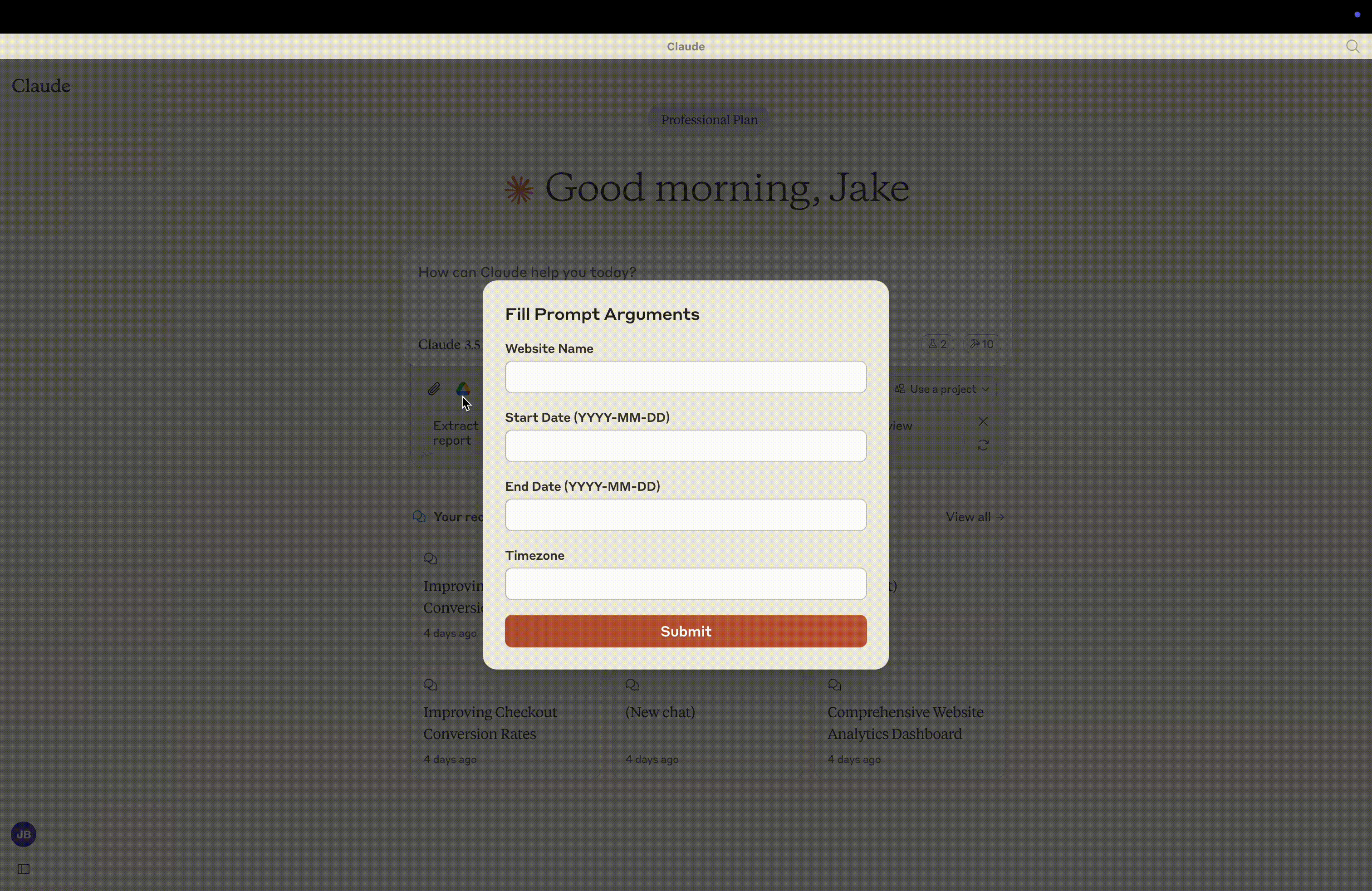
这将指导您完成为您的网站创建仪表板的过程,要求:
您要分析的网站名称
分析的开始和结束日期
网站的时区
提供这些信息后,服务器将生成一个 txt 文件,指导 Claude 如何构建仪表板。在聊天窗口中按下 Enter 键,Claude 将完成剩下的工作。然后,您可以要求 Claude 对仪表板进行任何更改或添加任何其他可视化效果。
自然语言的使用
为了获得更个性化的体验,您可以直接与 Claude 联系,并明确您的具体需求,例如您希望在仪表板上显示哪些数据以及希望使用哪些可视化效果。此外,您还可以分析用户旅程,精准定位具体的痛点,并添加您网站的屏幕截图,为 Claude 提供更多背景信息。
Claude 将自动使用完成您请求所需的工具。只需用自然语言提出请求,Claude 就会决定使用哪些工具。如果您想查看所有可用工具的列表,您可以让 Claude 为您列出,或者点击聊天窗口右下角的锤子图标。

创建您自己的提示
您还可以为常用的工作流程创建自己的提示。为此,您需要:
定义提示结构创建一个提示定义,其中包括:
name:提示的唯一标识符description:对提示的作用的清晰解释arguments:提示所需的输入参数列表
将其添加到
src/analytics_service/server.py中的list_prompts()函数中:示例结构:
@app.list_prompts() async def list_prompts(): return [ # ... existing prompts ... { "name": "Your Prompt Name", "description": "Your prompt description", "arguments": [ { "name": "Parameter Name 1", "description": "Parameter description", "required": True/False }, { "name": "Parameter Name 2", "description": "Parameter description", "required": True/False } ] } ]实现提示在
src/analytics_service/server.py中的get_prompt()函数中添加提示处理逻辑:@app.get_prompt() async def get_prompt(name: str, arguments: Any): # ... existing prompts ... if name == "Your Prompt Name": return { "messages": [ { "role": "user", "content": { "type": "text", "text": f"Your prompt template with {arguments['Parameter Name']}" } } ] }在提示中定义消息时,
role字段对于构建对话至关重要:使用
"role": "user"来模拟用户输入或问题的消息使用
"role": "assistant"来表示克劳德的回应或指示使用
"role": "system"来设置上下文或提供高级指令的消息
每条消息中的
content字段必须指定一个type。可用的类型有:"type": "text"- 用于纯文本内容"type": "resource"- 用于包含外部资源,例如文件、日志或其他数据。必须包含具有以下内容的resource对象:uri:资源标识符text:实际内容mimeType:内容的 MIME 类型(例如,“text/plain”、“text/x-python”)
虽然资源确实在
text字段中包含其内容,但使用resource类型提供了几个重要的好处:内容类型感知:
mimeType字段告诉 Claude 如何解释内容(例如,Python 代码、纯文本或其他格式)源跟踪:
uri字段维护对内容来源的引用,这可用于:追踪数据来源
如果源发生变化则启用更新
提供有关资源位置和用途的背景信息
结构化数据处理:资源格式允许一致处理不同类型的内容,同时维护有关每个资源的元数据
以下是显示不同角色和内容类型的示例:
"messages": [ { "role": "system", "content": { "type": "text", "text": "Analyze the following log file and code for potential issues." } }, { "role": "user", "content": { "type": "resource", "resource": { "uri": "logs://recent", "text": "[2024-03-14 15:32:11] ERROR: Connection timeout", "mimeType": "text/plain" } } }, { "role": "assistant", "content": { "type": "text", "text": "I notice a connection timeout error. Let me examine the related code." } }, { "role": "user", "content": { "type": "resource", "resource": { "uri": "file:///code.py", "text": "def example():\n pass", "mimeType": "text/x-python" } } } ]对于大多数提示,带有用户角色的文本类型已经足够,并且能够让 Claude 在响应方面拥有更多控制权和创造力。然而,对于更复杂的工作流程,具有不同角色和类型的多条消息可以实现更结构化的对话流程,并让用户更好地控制响应。
创建提示的最佳实践
让你的提示有针对性且具体
包括对参数的明确验证要求
对参数使用描述性名称
在参数描述中包含示例值
构建提示模板以有效地指导克劳德
考虑错误处理和边缘情况
使用各种输入测试提示