
Änderungsprotokoll
27.12.2024: Projektinitialisierung
Einführung
Dingo ist ein Tool zur Datenqualitätsbewertung, mit dem Sie Qualitätsprobleme in Ihren Datensätzen automatisch erkennen können. Dingo bietet eine Vielzahl integrierter Regeln und Modellbewertungsmethoden und unterstützt auch benutzerdefinierte Bewertungsmethoden. Dingo unterstützt häufig verwendete Textdatensätze und multimodale Datensätze, darunter Vortrainingsdatensätze, Feinabstimmungsdatensätze und Bewertungsdatensätze. Darüber hinaus unterstützt Dingo verschiedene Verwendungsmethoden, darunter lokale CLI und SDK, und erleichtert so die Integration in verschiedene Bewertungsplattformen wie OpenCompass .
Architekturdiagramm
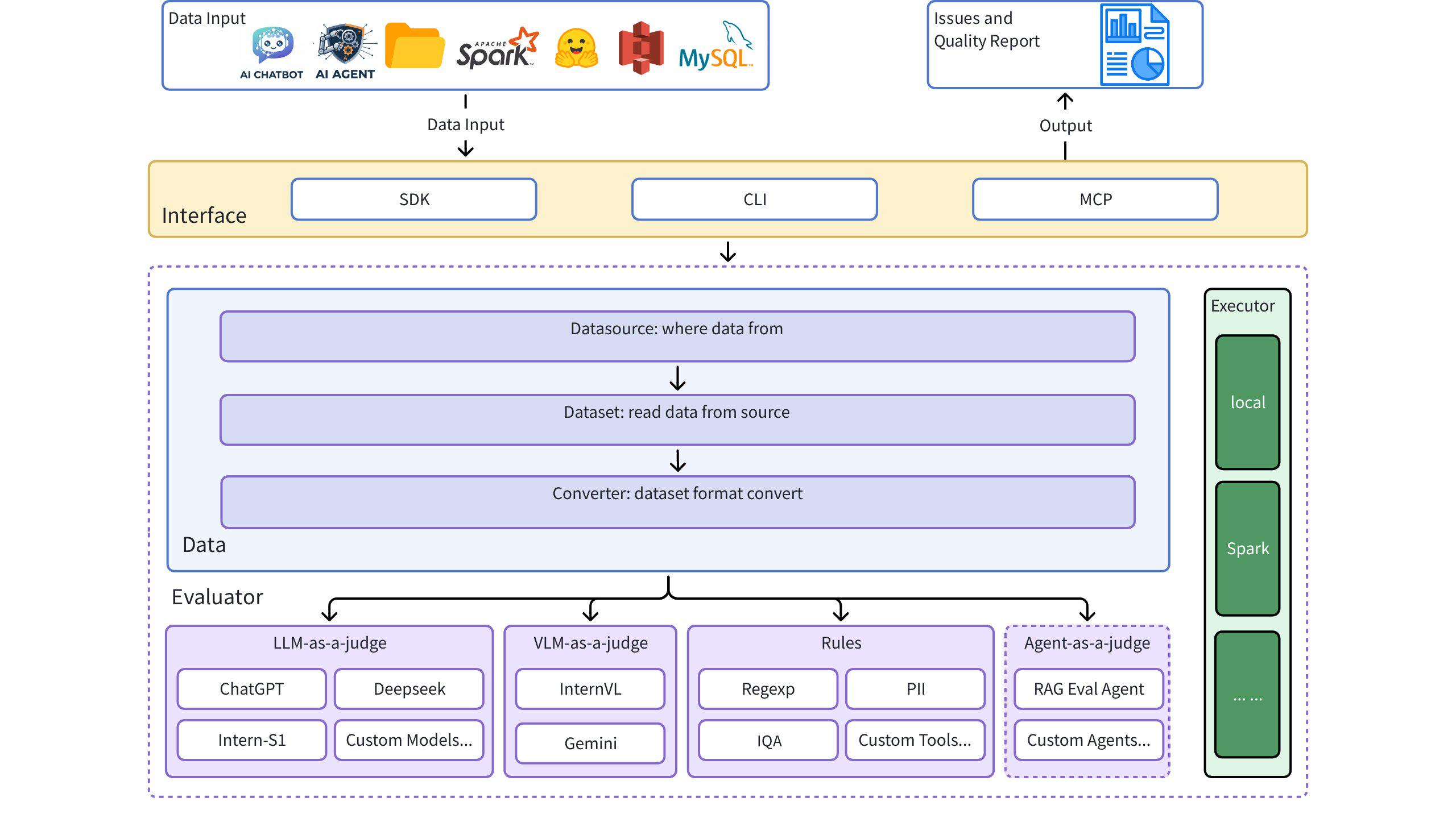
Schnellstart
Related MCP server: Tigris MCP Server
Installation
Beispiel-Anwendungsfälle
1. Verwenden von Evaluate Core
2. Lokale Textdatei (Klartext) auswerten
3. Bewerten Sie den Hugging Face-Datensatz
4. Evaluieren Sie das JSON/JSONL-Format
5. LLM zur Auswertung verwenden
Befehlszeilenschnittstelle
Auswerten mit Regelsätzen
Evaluieren mit LLM (zB GPT-4o)
Beispiel config_gpt.json :
GUI-Visualisierung
Nach der Auswertung (mit save_data=True ) wird automatisch eine Frontend-Seite generiert. So starten Sie das Frontend manuell:
Dabei enthält output_directory die Auswertungsergebnisse mit einer Datei summary.json .
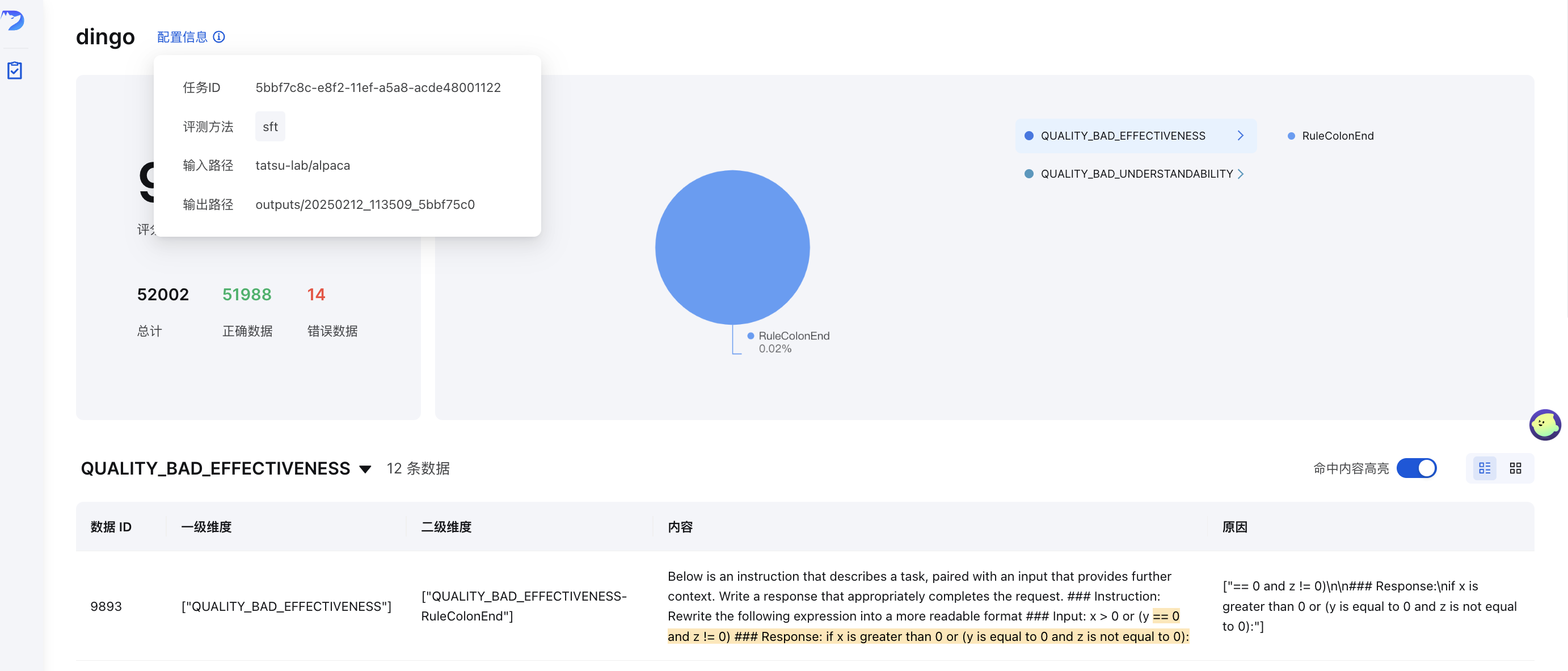
Online-Demo
Probieren Sie Dingo in unserer Online-Demo aus: (Umarmungsgesicht)🤗
Datenqualitätsmetriken
Dingo klassifiziert Datenqualitätsprobleme in sieben Dimensionen von Qualitätsmetriken. Jede Dimension kann sowohl mit regelbasierten Methoden als auch mit LLM-basierten Eingabeaufforderungen ausgewertet werden:
Qualitätsmetrik | Beschreibung | Regelbeispiele | Beispiele für LLM-Eingabeaufforderungen |
VOLLSTÄNDIGKEIT | Überprüft, ob Daten unvollständig sind oder fehlen |
| Prüft, ob der Text abrupt mit einem Doppelpunkt oder Auslassungspunkten endet, ob Klammern nicht übereinstimmen oder ob wichtige Komponenten fehlen |
WIRKSAMKEIT | Überprüft, ob die Daten aussagekräftig und richtig formatiert sind |
| Erkennt unleserlichen Text, Wörter, die ohne Leerzeichen aneinandergereiht sind, und Text ohne korrekte Zeichensetzung |
FLÜSSIGKEIT | Überprüft, ob der Text grammatikalisch korrekt ist und sich natürlich liest |
| Identifiziert übermäßig lange Wörter, Textfragmente ohne Zeichensetzung oder Inhalte mit chaotischer Lesereihenfolge |
RELEVANZ | Erkennt irrelevante Inhalte in den Daten |
| Untersucht irrelevante Informationen wie Zitatdetails, Kopf-/Fußzeilen, Entitätsmarkierungen, HTML-Tags |
SICHERHEIT | Identifiziert vertrauliche Informationen oder Wertekonflikte |
| Überprüfung auf persönliche Informationen und Inhalte im Zusammenhang mit Glücksspiel, Pornografie und politischen Themen |
ÄHNLICHKEIT | Erkennt sich wiederholende oder sehr ähnliche Inhalte |
| Prüft Text auf aufeinanderfolgende Wiederholungen oder mehrfaches Vorkommen von Sonderzeichen |
VERSTÄNDLICHKEIT | Bewertet, wie einfach Daten interpretiert werden können |
| Stellt sicher, dass LaTeX-Formeln und Markdown korrekt formatiert sind, mit richtiger Segmentierung und Zeilenumbrüchen |
LLM-Qualitätsbewertung
Dingo bietet verschiedene LLM-basierte Bewertungsmethoden, die durch Eingabeaufforderungen im Verzeichnis dingo/model/prompt definiert sind. Diese Eingabeaufforderungen werden mit dem Dekorator prompt_register registriert und können zur Qualitätsbewertung mit LLM-Modellen kombiniert werden:
Eingabeaufforderungen zur Bewertung der Textqualität
Eingabeaufforderungstyp | Metrisch | Beschreibung |
| Verschiedene Qualitätsdimensionen | Umfassende Bewertung der Textqualität hinsichtlich Effektivität, Relevanz, Vollständigkeit, Verständlichkeit, Ähnlichkeit, Flüssigkeit und Sicherheit |
| Wirksamkeit | Erkennt verstümmelten Text und Anti-Crawling-Inhalte |
| Ähnlichkeit | Identifiziert Probleme mit Textwiederholungen |
| Flüssigkeit | Prüft auf Wörter, die ohne den richtigen Abstand aneinander kleben |
| Vollständigkeit | Bewertet Codeblöcke und listet Formatierungsprobleme auf |
| Wirksamkeit | Erkennt unlesbare Zeichen aufgrund von Kodierungsproblemen |
3H-Beurteilungsaufforderungen (ehrlich, hilfreich, harmlos)
Eingabeaufforderungstyp | Metrisch | Beschreibung |
| Ehrlichkeit | Bewertet, ob die Antworten genaue Informationen ohne Fälschung oder Täuschung liefern |
| Hilfsbereitschaft | Bewertet, ob die Antworten direkt auf die Fragen eingehen und die Anweisungen angemessen befolgen |
| Harmlosigkeit | Überprüft, ob Antworten schädliche Inhalte, diskriminierende Sprache und gefährliche Hilfe vermeiden |
Domänenspezifische Bewertungsaufforderungen
Eingabeaufforderungstyp | Metrisch | Beschreibung |
| Qualität der Prüfungsfragen | Spezialisiertes Assessment zur Beurteilung der Qualität von Prüfungsfragen mit Fokus auf Formeldarstellung, Tabellenformatierung, Absatzstruktur und Antwortformatierung |
| HTML-Extraktionsqualität | Vergleicht verschiedene Methoden zum Extrahieren von Markdown aus HTML und bewertet Vollständigkeit, Formatierungsgenauigkeit und semantische Kohärenz |
| Datenqualität und -domäne | Bewertet die Datenqualität vor dem Training mithilfe der DataMan-Methode (14 Standards, 15 Domänen). Es werden eine Punktzahl (0/1), Domänentyp, Qualitätsstatus und ein Grund zugewiesen. |
Klassifizierungsaufforderungen
Eingabeaufforderungstyp | Metrisch | Beschreibung |
| Themenkategorisierung | Klassifiziert Text in Kategorien wie Sprachverarbeitung, Schreiben, Code, Mathematik, Rollenspiel oder Wissensfragen und -antworten |
| Bildklassifizierung | Identifiziert Bilder als CAPTCHA, QR-Code oder normale Bilder |
Eingabeaufforderungen zur Bildbewertung
Eingabeaufforderungstyp | Metrisch | Beschreibung |
| Bildrelevanz | Bewertet, ob ein Bild hinsichtlich der Anzahl der Gesichter, der Merkmalsdetails und der visuellen Elemente mit dem Referenzbild übereinstimmt |
Verwendung der LLM-Bewertung bei der Bewertung
Um diese Bewertungsaufforderungen in Ihren Auswertungen zu verwenden, geben Sie sie in Ihrer Konfiguration an:
Sie können diese Eingabeaufforderungen individuell anpassen, um bestimmte Qualitätsdimensionen zu fokussieren oder an spezifische Domänenanforderungen anzupassen. In Kombination mit geeigneten LLM-Modellen ermöglichen diese Eingabeaufforderungen eine umfassende Bewertung der Datenqualität über mehrere Dimensionen hinweg.
Regelgruppen
Dingo bietet vorkonfigurierte Regelgruppen für verschiedene Arten von Datensätzen:
Gruppe | Anwendungsfall | Beispielregeln |
| Allgemeine Textqualität |
|
| Feinabstimmung von Datensätzen | Regeln aus |
| Vorabtraining von Datensätzen | Umfassender Satz mit über 20 Regeln, darunter |
So verwenden Sie eine bestimmte Regelgruppe:
Funktionshighlights
Multi-Source- und Multi-Modal-Support
Datenquellen : Lokale Dateien, Hugging Face-Datensätze, S3-Speicher
Datentypen : Datensätze für Vortraining, Feinabstimmung und Auswertung
Datenmodalitäten : Text und Bild
Regelbasierte und modellbasierte Auswertung
Integrierte Regeln : Über 20 allgemeine heuristische Bewertungsregeln
LLM-Integration : OpenAI, Kimi und lokale Modelle (z. B. Llama3)
Benutzerdefinierte Regeln : Einfache Erweiterung mit Ihren eigenen Regeln und Modellen
Sicherheitsbewertung : Perspective API-Integration
Flexible Nutzung
Schnittstellen : CLI- und SDK-Optionen
Integration : Einfache Integration mit anderen Plattformen
Ausführungs-Engines : Lokal und Spark
Umfassende Berichterstattung
Qualitätsmetriken : 7-dimensionale Qualitätsbewertung
Rückverfolgbarkeit : Detaillierte Berichte zur Anomalieverfolgung
Benutzerhandbuch
Benutzerdefinierte Regeln, Eingabeaufforderungen und Modelle
Wenn die integrierten Regeln Ihren Anforderungen nicht entsprechen, können Sie benutzerdefinierte Regeln erstellen:
Beispiel für eine benutzerdefinierte Regel
Benutzerdefinierte LLM-Integration
Weitere Beispiele finden Sie in:
Ausführungs-Engines
Lokale Ausführung
Spark-Ausführung
Evaluierungsberichte
Nach der Auswertung generiert Dingo:
Zusammenfassender Bericht (
summary.json): Gesamtmetriken und BewertungenDetaillierte Berichte : Spezifische Probleme für jeden Regelverstoß
Beispielzusammenfassung:
MCP-Server (experimentell)
Dingo enthält einen experimentellen Model Context Protocol (MCP)-Server. Details zum Betrieb des Servers und zur Integration mit Clients wie Cursor finden Sie in der entsprechenden Dokumentation:
Dingo MCP Server-Dokumentation (README_mcp.md)
Forschung & Publikationen
„Umfassende Bewertung der Datenqualität für mehrsprachige Webdaten“ : WanJuanSiLu: Ein hochwertiger Open-Source-Webtext-Datensatz für ressourcenarme Sprachen
„Datenqualität vor dem Training mit der DataMan-Methodik“ : DataMan: Datenmanager für das Vortraining großer Sprachmodelle
Zukunftspläne
[ ] Umfangreichere grafische und textuelle Bewertungsindikatoren
[ ] Auswertung der Audio- und Videodatenmodalität
[ ] Kleine Modellbewertung (Fasttext, Qurating)
[ ] Bewertung der Datenvielfalt
Einschränkungen
Die aktuell integrierten Erkennungsregeln und Modellmethoden konzentrieren sich auf häufige Datenqualitätsprobleme. Für spezielle Auswertungsanforderungen empfehlen wir die Anpassung der Erkennungsregeln.
Danksagung
Beitrag
Wir danken allen Mitwirkenden für ihre Bemühungen, Dingo zu verbessern und zu erweitern. Weitere Informationen zur Mitarbeit am Projekt finden Sie im Beitragsleitfaden .
Lizenz
Dieses Projekt verwendet die Apache 2.0 Open Source-Lizenz .
Zitat
Wenn Sie dieses Projekt nützlich finden, denken Sie bitte darüber nach, unser Tool zu zitieren: