
Provides integration with Hugging Face Hub for downloading and caching transformer models locally for embedding generation, eliminating the need for external API calls
Supports OpenAI's embedding API for generating vector embeddings of code, enabling semantic search capabilities across indexed codebases
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@CodeGraph CLI MCP Serverfind all functions that call the authentication middleware"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.

CodeGraph
Your codebase, understood.
CodeGraph transforms your entire codebase into a semantically searchable knowledge graph that AI agents can actually reason about—not just grep through.
Ready to get started? Jump to the Installation Guide for step-by-step setup instructions.
Already set up? See the Usage Guide for tips on getting the most out of CodeGraph with your AI assistant.
The Problem
AI coding assistants are powerful, but they're flying blind. They see files one at a time, grep for patterns, and burn tokens trying to understand your architecture. Every conversation starts from zero.
What if your AI assistant already knew your codebase?
What CodeGraph Does Differently
1. Graph + Embeddings = True Understanding
Most semantic search tools create embeddings and call it a day. CodeGraph builds a real knowledge graph:
When you search, you don't just get "similar code"—you get code with its relationships intact. The function that matches your query, plus what calls it, what it depends on, and where it fits in the architecture.
Indexing enrichment adds:
Module nodes and module-level import/containment edges for cross-file navigation
Rust-local dataflow edges (
defines,uses,flows_to,returns,mutates) for impact analysisDocument/spec nodes linked to backticked symbols in
README.md,docs/**/*.md, andschema/**/*.surqlArchitecture signals (package cycles + optional boundary violations)
Indexing tiers (speed vs richness)
Indexing is tiered so you can choose between speed/storage and graph richness. The default is fast.
Tier | What it enables | Typical use |
| AST nodes + core edges only (no LSP or enrichment) | Quick indexing, low storage |
| LSP symbols + docs/enrichment + module linking | Good agentic results without full cost |
| All analyzers + LSP definitions + dataflow + architecture | Maximum accuracy/richness |
Tier behavior details:
fast: disables build context, LSP, enrichment, module linking, dataflow, docs/contracts, and architecture; filters outUses/Referencesedges.balanced: enables build context, LSP symbols, enrichment, module linking, and docs/contracts; filters outReferencesedges.full: enables all analyzers and LSP definitions; no edge filtering.
Configure the tier:
CLI:
codegraph index --index-tier balancedEnv:
CODEGRAPH_INDEX_TIER=balancedConfig:
[indexing] tier = "balanced"
Indexing prerequisites (LSP-enabled tiers)
When the tier enables LSP (balanced/full), indexing fails fast if required external tools are missing.
Required tools by language:
Rust:
rust-analyzerTypeScript/JavaScript:
nodeandtypescript-language-serverPython:
nodeandpyright-langserverGo:
goplsJava:
jdtlsC/C++:
clangd
If indexing appears to stall during LSP resolution, you can adjust the per-request timeout:
CODEGRAPH_LSP_REQUEST_TIMEOUT_SECS(default600, minimum5)
If LSP resolution fails immediately and the error includes something like Unknown binary 'rust-analyzer' in official toolchain ..., your rust-analyzer is a rustup shim without an installed binary. Install a runnable rust-analyzer (e.g. via brew install rust-analyzer or by switching to a toolchain that provides it).
Optional architecture boundary rules
If you want CodeGraph to flag forbidden package dependencies, add codegraph.boundaries.toml at the project root:
Indexing will emit violates_boundary edges when a depends_on relationship matches a deny rule.
2. Agentic Tools, Not Just Search
CodeGraph doesn't return a list of files and wish you luck. It ships 4 consolidated agentic tools that do the thinking:
Tool | What It Actually Does |
| Gathers the context you need—searches code, builds comprehensive context, answers semantic questions |
| Maps change impact—dependency chains, call flows, what breaks if you touch something |
| The big picture—system structure, API surfaces, architectural patterns |
| Risk assessment—complexity hotspots, coupling metrics, refactoring priorities |
Each tool accepts an optional focus parameter for precision when needed:
Tool | Focus Values | Default Behavior |
|
| Auto-selects based on query |
|
| Analyzes both |
|
| Provides both |
|
| Comprehensive assessment |
Each tool runs a reasoning agent that plans, searches, analyzes graph relationships, and synthesizes an answer. Not a search result—an answer.
View Agent Context Gathering Flow - Interactive diagram showing how agents use graph tools to gather context.
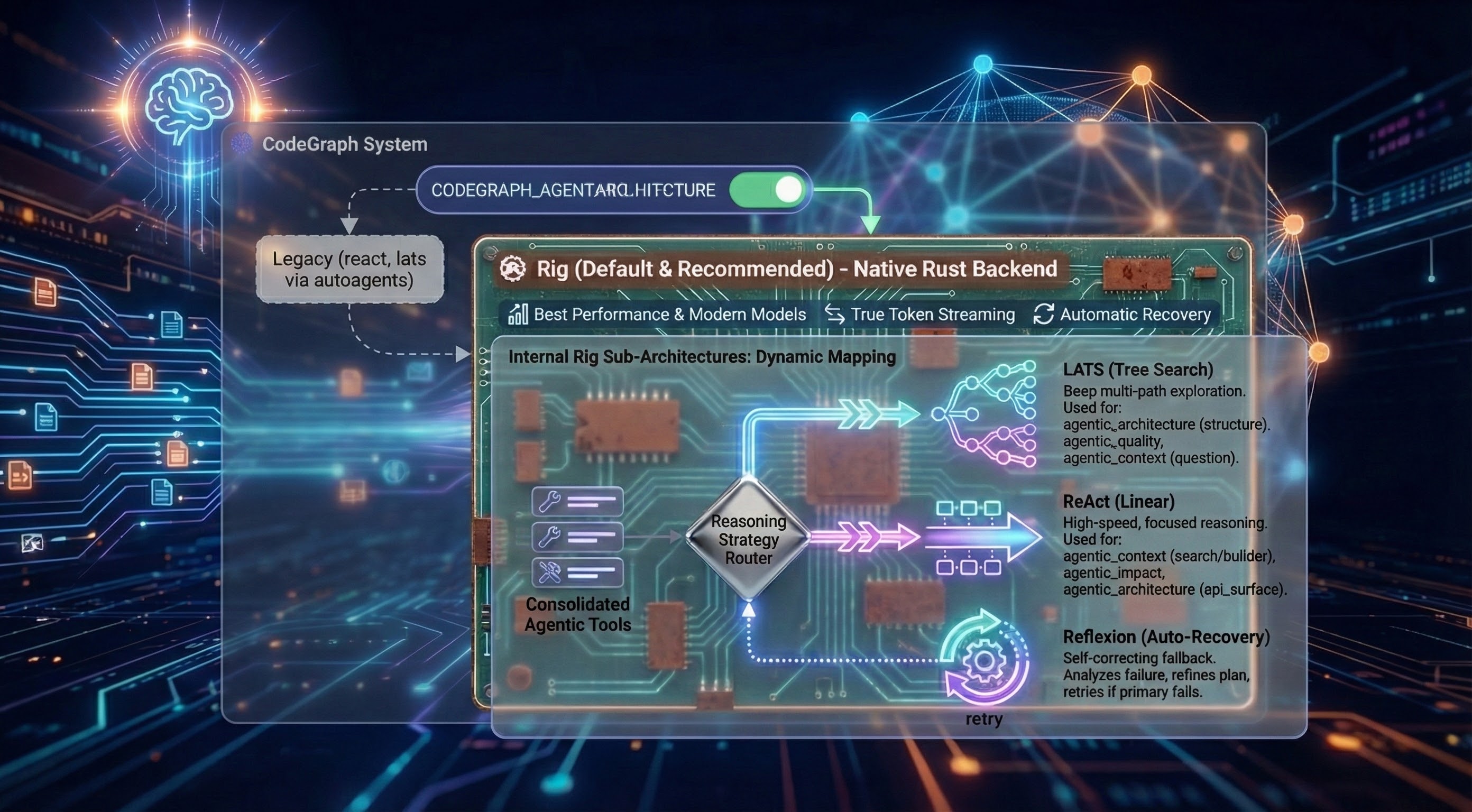
Agent Architectures
CodeGraph implements agents using Rig the default and recommended choice (legacy react and lats implemented with autoagents still work). Selectable at runtime via CODEGRAPH_AGENT_ARCHITECTURE=rig:
Why Rig is Default: The Rig-based backend delivers the best performance with modern thinking and reasoning models. It is a native Rust implementation that supports internal sub-architectures and provides features like True Token Streaming and Automatic Recovery.
Internal Rig Sub-Architectures:
When using the rig backend, the system automatically maps the consolidated agentic tools to the most effective reasoning strategy:
LATS (Tree Search): Deep multi-path exploration for complex, non-linear tasks.
Automatically used for:
agentic_architecture(structure),agentic_quality, andagentic_context(question).
ReAct (Linear): High-speed, focused reasoning for direct data lookups.
Automatically used for:
agentic_context(search/builder),agentic_impact, andagentic_architecture(api_surface).
Reflexion (Auto-Recovery): A self-correcting fallback that kicks in automatically if the primary strategy fails to find an answer. It analyzes the failure and retries with a refined plan.
Agent Bootstrap Context
Agents can start with lightweight project context so their first tool calls are not blind. Enable via env:
CODEGRAPH_ARCH_BOOTSTRAP=true— includes a brief directory/structure bootstrap + contents of README.md and CLAUDE.md+AGENTS.md or GEMINI.md (if present) in the agent’s initial context.CODEGRAPH_ARCH_PRIMER="<primer text>"— optional custom primer injected into startup instructions (e.g., areas to focus on).
Why? Faster, more relevant early steps, fewer wasted graph/semantic queries, and better architecture answers on large repos.
Notes:
Bootstrap is small (top directories summary), not a replacement for graph queries.
Uses the same project selection as indexing (
CODEGRAPH_PROJECT_IDor current working directory).
All architectures use the same 4 consolidated agentic tools (backed by 6 internal graph analysis tools) and tier-aware prompting—only the reasoning strategy differs.
3. Tier-Aware Intelligence
Here's something clever: CodeGraph automatically adjusts its behavior based on the LLM's context window that you configured for the codegraph agent.
Running a small local model? Get focused, efficient queries.
Using GPT-5.1 or Claude with 200K context? Get comprehensive, exploratory analysis.
Using grok-4-1-fast-reasoning with 2M context? Get detailed analysis with intelligent result management.
The Agent only uses the amount of steps that it requires to produce the answer so tool execution times vary based on the query and amount of data indexed in the database.
During development the agent used 3-6 steps on average to produce answers for test scenarios.
The Agent is stateless it only has conversational memory for the span of tool execution it does not accumulate context/memory over multiple chained tool calls this is already handled by your client of choice, it accumulates that context so codegraph needs to just provide answers.
Your Model | CodeGraph's Behavior |
< 50K tokens | Terse prompts, max 3 steps |
50K-150K | Balanced analysis, max 5 steps |
150K-500K | Detailed exploration, max 6 steps |
> 500K (Grok, etc.) | Comprehensive analysis, max 8 steps |
Hard cap: Maximum 8 steps regardless of tier (10 with env override). This prevents runaway costs and context overflow while still allowing thorough analysis.
Same tool, automatically optimized for your setup.
4. Context Overflow Protection
CodeGraph includes multi-layer protection against context overflow—preventing expensive failures when tool results exceed your model's limits.
Per-Tool Result Truncation:
Each tool result is limited based on your configured context window
Large results (e.g., dependency trees with 1000+ nodes) are intelligently truncated
Truncated results include
_truncated: truemetadata so the agent knows data was cutArray results keep the most relevant items that fit within limits
Context Accumulation Guard:
Monitors total accumulated context across multi-step reasoning
Fails fast with clear error message if accumulated tool results exceed safe threshold
Threshold: 80% of context window × 4 (conservative estimate for token overhead)
Configure via environment:
Why this matters: Without these guards, a single agentic_impact query on a large codebase could return 6M+ tokens—far exceeding most models' limits and causing expensive failures.
5. Hybrid Search That Actually Works
We don't pick sides in the "embeddings vs keywords" debate. CodeGraph combines:
70% vector similarity (semantic understanding)
30% lexical search (exact matches matter)
Graph traversal (relationships and context)
Optional reranking (cross-encoder precision)
The result? You find handleUserAuth when you search for "login logic"—but also when you search for "handleUserAuth".
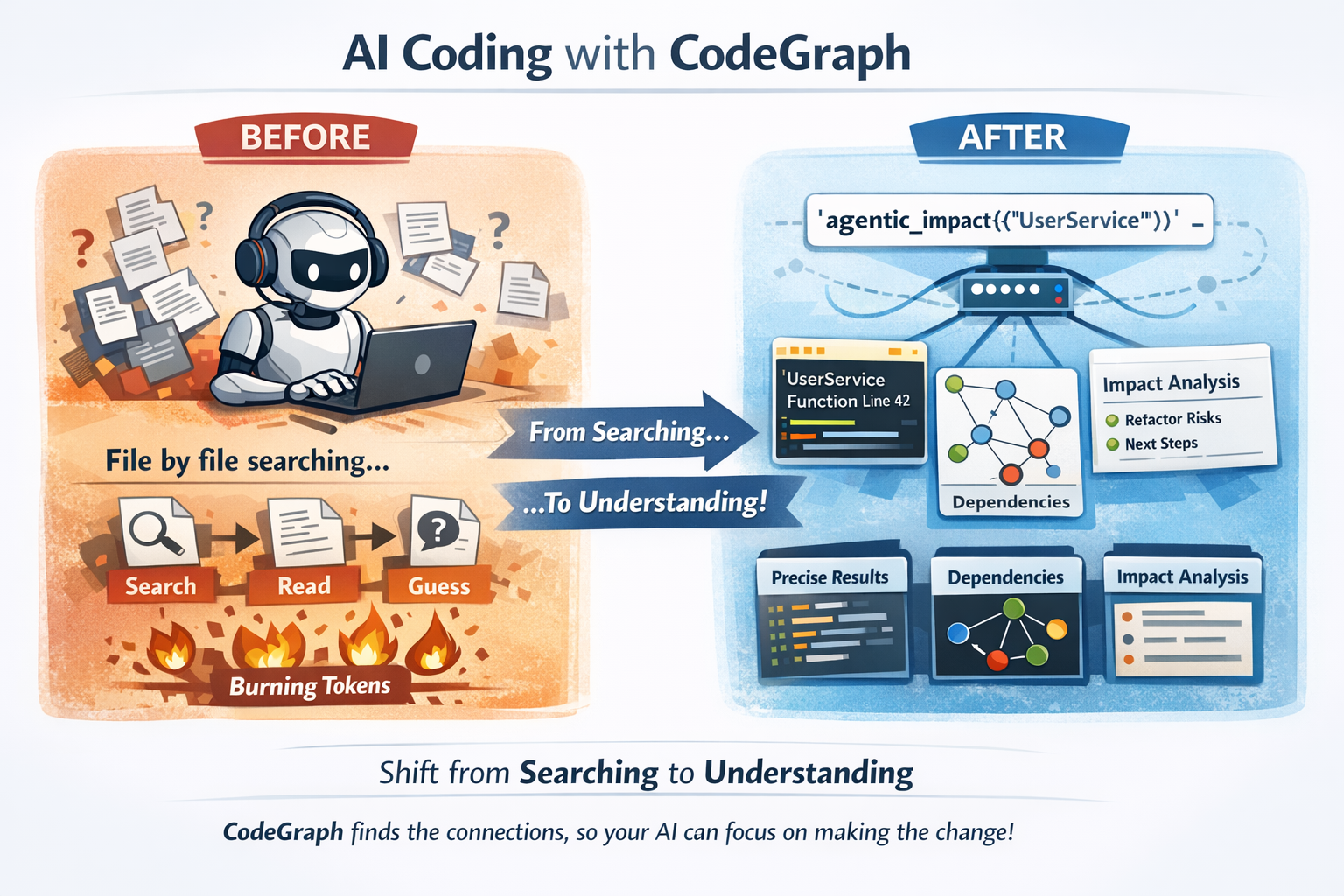
Why This Matters for AI Coding
When you connect CodeGraph to Claude Code, Cursor, or any MCP-compatible agent:
Before: Your AI reads files one by one, grepping around, burning tokens on context-gathering.
After: Your AI calls agentic_impact({"query": "UserService"}) and instantly knows what breaks if you refactor it.
This isn't incremental improvement. It's the difference between an AI that searches your code and one that understands it.
Why this is powerful for code agents
CodeGraph shifts the cognitive load (search + relevance + dependency reasoning) into CodeGraph’s agentic tools, so your code agent can spend its context budget on making the change, not discovering what to change.
What an agentic tool returns (example)
agentic_impact returns structured output (file paths, line numbers, and bounded snippets/highlights) plus analysis:
What a code agent would otherwise have to do
Without CodeGraph’s agentic tools, a code agent typically needs multiple “single-purpose” calls to reach the same confidence:
search for the symbol (often multiple strategies: text + semantic + ripgrep-style search)
open and read multiple files (definition + usages + callers + related modules)
reconstruct dependency/call graphs mentally from partial evidence
repeat when a guess is wrong (more reads, more tokens)
This burns context quickly: reading “just” a handful of medium-sized files + surrounding context can easily consume tens of thousands of tokens, and larger repos can push into hundreds of thousands depending on how much code gets pulled into context.
With CodeGraph, the agent gets pinpointed locations and relationships (plus bounded context) and can keep far more of the context window available for planning and implementing changes.
Quick Start
1. Install
macOS faster builds (LLVM lld)
If you develop on macOS, you can opt into LLVM's lld linker for faster linking:
2. Start SurrealDB
3. Apply Schema
4. Index Your Code
🔒 Security Note: Indexing automatically respects
.gitignoreand filters out common secrets patterns (.env,credentials.json,*.pem, API keys, etc.). Your secrets won't be embedded or exposed to the agent.
5. Connect to Claude Code
Add to your MCP config:
That's it. Your AI now understands your codebase.
The Architecture
View Interactive Architecture Diagram - Explore the full workspace structure with clickable components and layer filtering.
Key insight: The agentic tools don't just call one function. They reason about which graph operations to perform, chain them together, and synthesize results. A single agentic_impact call might:
Search for the target component semantically
Get its direct dependencies
Trace transitive dependencies
Check for circular dependencies
Calculate coupling metrics
Identify hub nodes that might be affected
Synthesize all findings into an actionable answer
Supported Languages
CodeGraph uses tree-sitter for initial parsing and enhances results with FastML algorithms and supports:
Rust • Python • TypeScript • JavaScript • Go • Java • C++ • C • Swift • Kotlin • C# • Ruby • PHP • Dart
Provider Flexibility
Embeddings
Use any model with dimensions 384-4096:
Local: Ollama, LM Studio, ONNX Runtime
Cloud: OpenAI, Jina AI
LLM (for agentic reasoning)
Local: Ollama, LM Studio
Cloud: Anthropic Claude, OpenAI, xAI Grok, OpenAI Compliant
Database
SurrealDB with HNSW vector index (2-5ms queries)
Free cloud tier available at surrealdb.com/cloud
Configuration
Global config in ~/.codegraph/config.toml:
See INSTALLATION_GUIDE.md for complete configuration options.
Experimental graph schema (optional)
CodeGraph can run against an experimental SurrealDB graphdb-style schema (schema/codegraph_graph_experimental.surql) that is interoperable with the existing CodeGraph tools and indexing pipeline.
Compared to the relational/vanilla schema (schema/codegraph.surql), the experimental schema is designed for faster and more efficient graph-query operations (traversals, neighborhood expansion, and tool-driven graph analytics) on large codebases.
To use it:
Load the schema into a dedicated database (once):
Point CodeGraph at that database:
Notes:
The schema file defines HNSW indexes for multiple embedding dimensions (384–4096) so you can switch embedding models without reworking the DB.
Schema loading is not currently performed automatically at runtime; you must apply the
.surqlfile to the target database before indexing.CODEGRAPH_GRAPH_DB_DATABASEcontrols which Surreal database indexing/tools use whenCODEGRAPH_USE_GRAPH_SCHEMA=true.
Daemon Mode
Keep your index fresh automatically:
Changes are detected, debounced, and re-indexed in the background.
What's Next
More language support
Cross-repository analysis
Custom graph schemas
Plugin system for custom analyzers
Philosophy
CodeGraph exists because we believe AI coding assistants should be augmented, not replaced. The best AI-human collaboration happens when the AI has deep context about what you're working with.
We're not trying to replace your IDE, your type checker, or your tests. We're giving your AI the context it needs to actually help.
Your codebase is a graph. Let your AI see it that way.
License
MIT
Links
SurrealDB Cloud (free tier)
Jina AI (free API tokens)
Ollama (local models)
Appeared in Searches
- Code intelligence tools for LLMs to understand codebase structure and locate functionality
- Tools to generate Lucidchart diagrams from Java code
- A tool for managing entire project code context
- MCP server for contextual codebase analysis and task-focused code understanding
- A programming resource or code repository index