
The npm-search-mcp-server allows you to search for npm packages via the Model Context Protocol (MCP).
Search for npm packages: The server provides a tool called
search_npm_packagesthat takes aquerystring as input to find relevant npm packages.Integration with tools: Can be installed and configured in applications like Claude and Zed.
Debugging support: Includes an MCP inspector for debugging.
Cross-platform installation: Supports installation via npm, uv, or Docker.
Allows searching for npm packages by executing the npm search command, enabling users to find and explore available packages in the npm registry with their name, description, version, author, and license information.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@npm-search-mcp-serversearch for react packages"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
npm-search MCP Server
A Model Context Protocol server that allows you to search for npm packages by calling the npm search command.
Available Tools
search_npm_packages- Search for npm packages.Required arguments:
query(string): The search query.
Installation
Installing via Smithery
To install npm-search for Claude Desktop automatically via Smithery:
Using NPM (recommended)
Alternatively you can install npm-search-mcp-server via npm:
After installation, you can run it as a command using:
Using uv
When using uv no specific installation is needed. We will
use uvx to directly run npm-search-mcp-server.
Related MCP server: mcp-registry-server
Configuration
Configure for Claude.app
Add to your Claude settings:
Configure for Zed
Add to your Zed settings.json:
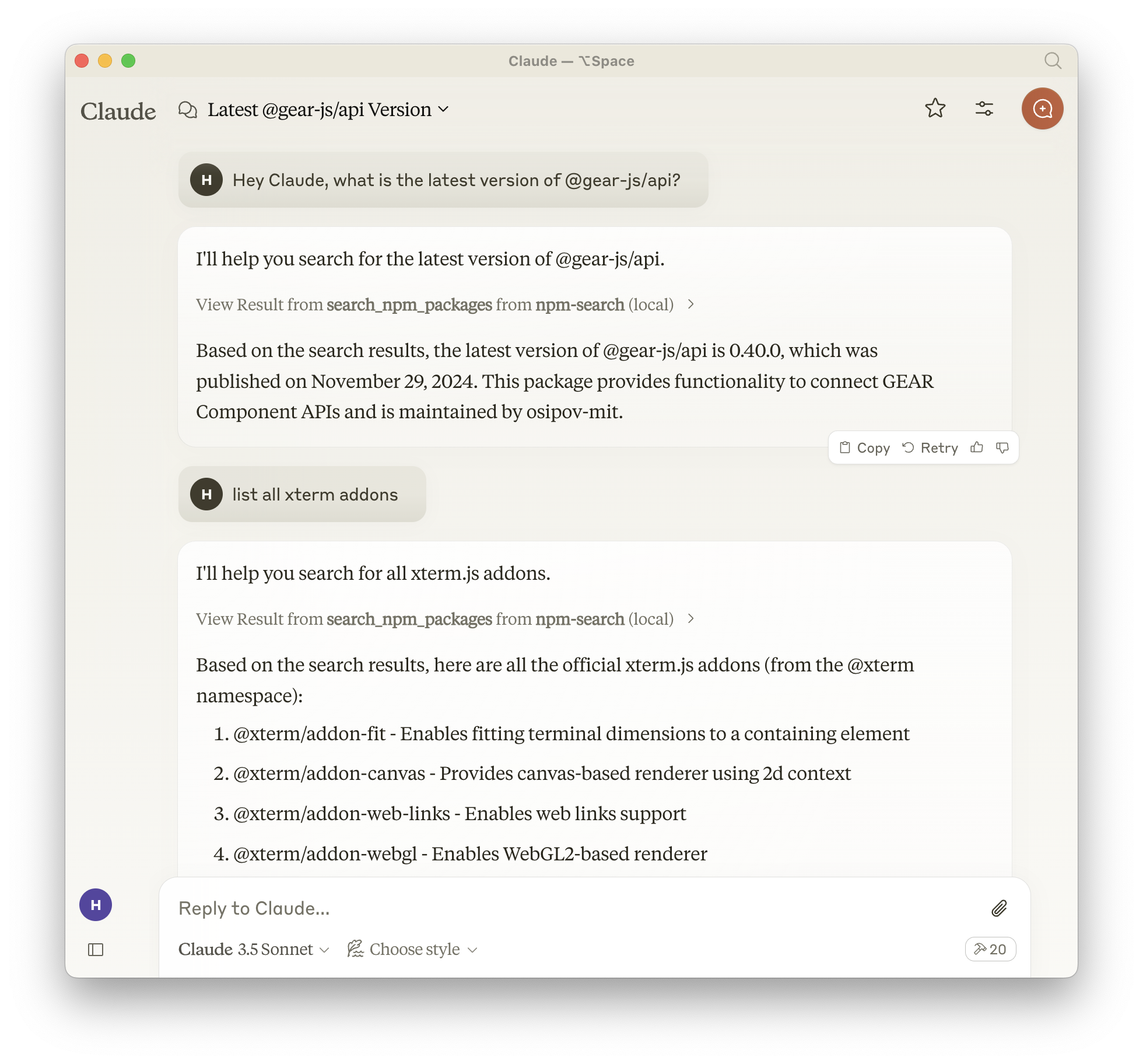
Example Interactions
Search for npm packages:
Response:
Debugging
You can use the MCP inspector to debug the server. For uvx installations:
Or if you've installed the package in a specific directory or are developing on it:
Examples of Questions for Claude
"Search for express package on npm"
"Find packages related to react"
"Show me npm packages for web development"
Build
Docker build:
Contributing
We encourage contributions to help expand and improve npm-search-mcp-server. Whether you want to add new npm-related tools, enhance existing functionality, or improve documentation, your input is valuable.
For examples of other MCP servers and implementation patterns, see: https://github.com/modelcontextprotocol/servers
Pull requests are welcome! Feel free to contribute new ideas, bug fixes, or enhancements to make npm-search-mcp-server even more powerful and useful.
License
npm-search-mcp-server is licensed under the MIT License. This means you are free to use, modify, and distribute the software, subject to the terms and conditions of the MIT License. For more details, please see the LICENSE file in the project repository.
{kind=link}
{kind=link}