
Prism MCP
The BCBA server is an AI-driven MCP platform combining real-time web search, enterprise AI services, data transformation, and optional persistent session memory.
Search & Discovery
Web search (
brave_web_search): Real-time searches via Brave Search API with pagination, filtering, and up to 20 results per requestLocal business search (
brave_local_search): Find nearby businesses with addresses, ratings, phone numbers, and hours; auto-falls back to web search if no local resultsAI-grounded answers (
brave_answers): Concise, direct answers grounded in live web results via Brave's AI GroundingEnterprise search: Domain-specific document retrieval via Vertex AI Discovery Engine, with a hybrid pipeline that combines and deduplicates web + curated results
Data Transformation
Code-mode search variants (
brave_web_search_code_mode,brave_local_search_code_mode): Run a search and immediately apply a custom JavaScript script (in a secure QuickJS sandbox) to extract only needed fields, reducing context window usage by 85–95%Universal transformer (
code_mode_transform): Apply custom JavaScript extraction to raw output from any MCP tool — useful for GitHub issues, DOM snapshots, transcripts, and more
AI Analysis & Orchestration
Research paper analysis (
gemini_research_paper_analysis): Deep academic analysis using Gemini 2.0 Flash — summaries, critiques, key findings, literature reviews, or comprehensive analysisMulti-model orchestration: Supports Google Gemini and Claude via Vertex AI infrastructure with secure Application Default Credentials (ADC)
Session Memory (optional, requires Supabase)
Save immutable session logs, update project state for continuity, progressively load prior context, search accumulated knowledge, and prune old memories
Integrations: Brave Search, Google Gemini, Vertex AI, Gmail, Chrome DevTools Protocol, and Supabase
Provides real-time web and local search capabilities, including AI-powered answers, to enhance model context.
Facilitates data extraction and automated pipeline processing through Gmail OAuth integration.
Orchestrates various Google ecosystem services, including Gemini and Gmail, for cross-platform data retrieval.
Leverages Vertex AI infrastructure, specifically Discovery Engine for enterprise search and managed generative model deployment.
Enables deep research paper analysis and structured data synthesis using the Google Gemini API.
Provides a session memory layer for progressive context loading, work ledgers, and persistent state handoffs via Supabase REST APIs.
🧠 Prism MCP — The Mind Palace for AI Agents


Your AI agent forgets everything between sessions. Prism fixes that — then teaches it to think.
Prism v7.8 is a true Cognitive Architecture inspired by human brain mechanics. Beyond flat vector search, your agent now forms principles from experience, follows causal trains of thought, and possesses the self-awareness to know when it lacks information. Your agents don't just remember; they learn.
npx -y prism-mcp-serverWorks with Claude Desktop · Claude Code · Cursor · Windsurf · Cline · Gemini · Antigravity — any MCP client.
https://github.com/dcostenco/prism-mcp/raw/main/docs/prism_mcp_demo.mp4
📖 Table of Contents
Why Prism?
Every time you start a new conversation with an AI coding assistant, it starts from scratch. You re-explain your architecture, re-describe your decisions, re-list your TODOs. Hours of context — gone.
Prism gives your agent a brain that persists — and then teaches it to reason. Save what matters at the end of each session. Load it back instantly on the next one. But Prism goes far beyond storage: it consolidates raw experience into lasting principles, traverses causal chains to surface root causes, and knows when to say "I don't know."
📌 Terminology: Throughout this doc, "Prism" refers to the MCP server and cognitive memory engine. "Mind Palace" refers to the visual dashboard UI at
localhost:3000— your window into the agent's brain. They work together; the dashboard is optional.
Prism has three pillars:
🧠 Cognitive Memory — Memories are ranked like a human brain: recently and frequently accessed context surfaces first, while stale context fades naturally via ACT-R activation decay. Raw experience consolidates into semantic principles through Hebbian learning. The result is retrieval quality that no flat vector search can match. (See Cognitive Architecture and Scientific Foundation.)
🔗 Multi-Hop Reasoning — When your agent searches for "Error X", Prism doesn't just find logs mentioning "Error X". Spreading activation traverses the causal graph and brings back "Workaround Y", which is connected to "Architecture Decision Z" — a literal train of thought. (See Cognitive Architecture.)
🏭 Autonomous Execution (Dark Factory) — When you're ready, Prism can run coding tasks end-to-end with a fail-closed pipeline where an adversarial evaluator catches bugs the generator missed — before you ever see the PR. (See Dark Factory.)
🚀 Quick Start
Prerequisites
Node.js v18+ (v20 LTS recommended; v23.x has known
npxquirk)Any MCP-compatible client (Claude Desktop, Cursor, Windsurf, Cline, etc.)
No API keys required for core features (see Capability Matrix)
Install
Add to your MCP client config (claude_desktop_config.json, .cursor/mcp.json, etc.):
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"]
}
}
}⚠️ Windows / Restricted Shells: If your MCP client complains that
npxis not found, use the absolute path to your node binary (e.g.C:\Program Files\nodejs\npx.cmd).
That's it. Restart your client. All tools are available. The Mind Palace Dashboard (the visual UI for your agent's brain) starts automatically at http://localhost:3000. You don't need to keep a tab open — the dashboard runs in the background and the MCP tools work with or without it.
🔮 Pro Tip: Once installed, open
http://localhost:3000in your browser to view the Mind Palace Dashboard — a beautiful, real-time UI of your agent's brain. Explore the Knowledge Graph, Intent Health gauges, and Session Ledger.
🔄 Updating Prism:
npx -ycaches the package locally. To force an update to the latest version, restart your MCP client —npx -ywill fetch the newest release automatically. If you're stuck on a stale version, runnpx clear-npx-cache(ornpm cache clean --force) before restarting.
Add PRISM_DASHBOARD_PORT to your MCP config env block:
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"],
"env": { "PRISM_DASHBOARD_PORT": "3001" }
}
}
}Then open http://localhost:3001 instead.
Capability Matrix
Feature | Local (Offline) | Cloud (API Key) |
Session memory & handoffs | ✅ | ✅ |
Keyword search (FTS5) | ✅ | ✅ |
Time travel & versioning | ✅ | ✅ |
Mind Palace Dashboard | ✅ | ✅ |
GDPR export (JSON/Markdown/Vault) | ✅ | ✅ |
Semantic vector search | ❌ | ✅ |
Morning Briefings | ❌ | ✅ |
Auto-compaction | ❌ | ✅ |
Web Scholar research | ❌ | ✅ |
VLM image captioning | ❌ | ✅ Provider key |
Autonomous Pipelines (Dark Factory) | ❌ | ✅ |
🔑 The core Mind Palace works 100% offline with zero API keys. Cloud keys unlock intelligence features. See Environment Variables.
💰 API Cost Note:
GOOGLE_API_KEY(Gemini) has a generous free tier that covers most individual use.BRAVE_API_KEYoffers 2,000 free searches/month.FIRECRAWL_API_KEYhas a free plan with 500 credits. For typical solo development, expect $0/month on the free tiers. Only high-volume teams or heavy autonomous pipeline usage will incur meaningful costs.
✨ The Magic Moment
Session 1 (Monday evening):
You: "Analyze this auth architecture and plan the OAuth migration." Agent: *deep analysis, decisions, TODO list* Agent: session_save_ledger → session_save_handoff ✅Session 2 (Tuesday morning — new conversation, new context window):
Agent: session_load_context → "Welcome back! Yesterday we decided to use PKCE flow with refresh tokens. 3 TODOs remain: migrate the user table, update the middleware, and write integration tests." You: "Pick up where we left off."Your agent remembers everything. No re-uploading files. No re-explaining decisions.
📖 Setup Guides
Add to claude_desktop_config.json:
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"]
}
}
}Add to .cursor/mcp.json (project) or ~/.cursor/mcp.json (global):
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"]
}
}
}Add to ~/.codeium/windsurf/mcp_config.json:
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"]
}
}
}Add to your Continue config.json or Cline MCP settings:
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"],
"env": {
"PRISM_STORAGE": "local",
"BRAVE_API_KEY": "your-brave-api-key"
}
}
}
}Claude Code naturally picks up MCP tools by adding them to your workspace .clauderules. Simply add:
Always start the conversation by calling `mcp__prism-mcp__session_load_context(project='my-project', level='deep')`.
When wrapping up, always call `mcp__prism-mcp__session_save_ledger` and `mcp__prism-mcp__session_save_handoff`.Format Note: Claude automatically wraps MCP tools with double underscores (
mcp__prism-mcp__...), while most other clients use single underscores (mcp_prism-mcp_...). Prism's backend natively handles both formats seamlessly.
CLI Alternative: If MCP tools aren't available or you're scripting around Claude Code:
# Load context before a session
prism load my-project --level deep
# Machine-readable JSON for parsing in scripts
prism load my-project --level deep --jsonSee the Gemini Setup Guide for the proven three-layer prompt architecture to ensure reliable session auto-loading.
Antigravity doesn't expose MCP tools to the model. Use the prism load CLI as a fallback:
# From a shell or run_command tool
prism load my-project --level standard --json
# Or via the wrapper script
bash ~/.gemini/antigravity/scratch/prism_session_loader.sh my-projectThe CLI uses the same storage layer as the MCP tool (SQLite or Supabase).
⚠️ CRITICAL (v9.2.2): Split-Brain Prevention If your MCP server is configured with
PRISM_STORAGE=localbut Supabase credentials are also set, the CLI may read from the wrong backend (Supabase) while the server writes to SQLite. This causes stale TODOs and divergent state. Always pass--storage localexplicitly when using the CLI in a local-mode environment:prism load my-project --storage local --jsonThe
prism_session_loader.shwrapper handles this automatically since v9.2.2.
Use the prism load CLI to access session context from any shell environment:
# Quick check — human-readable
prism load my-project
# Parse JSON in scripts
CONTEXT=$(prism load my-project --level quick --json)
SUMMARY=$(echo "$CONTEXT" | jq -r '.handoff[0].last_summary')
VERSION=$(echo "$CONTEXT" | jq -r '.handoff[0].version')
echo "Project at v$VERSION: $SUMMARY"
# Explicit storage backend (v9.2.2 — prevents split-brain)
prism load my-project --storage local --json
prism load my-project --storage supabase --json
# Role-scoped loading
prism load my-project --role qa --json
# Use in CI/CD to verify context exists before deploying
if ! prism load my-project --level quick --json | jq -e '.handoff[0].version' > /dev/null 2>&1; then
echo "No Prism context found — skipping context-aware deploy"
fi📦 Install:
npm install -g prism-mcp-servermakes theprismCLI available globally. For local builds:node /path/to/prism/dist/cli.js load.
To sync memory across machines or teams:
{
"mcpServers": {
"prism-mcp": {
"command": "npx",
"args": ["-y", "prism-mcp-server"],
"env": {
"PRISM_STORAGE": "supabase",
"SUPABASE_URL": "https://your-project.supabase.co",
"SUPABASE_KEY": "your-supabase-anon-or-service-key"
}
}
}
}Schema Migrations
Prism auto-applies its schema on first connect — no manual step required. If you need to apply or re-apply migrations manually (e.g. for a fresh project or after a version bump), run the SQL files in supabase/migrations/ in numbered order via the Supabase SQL Editor or the CLI:
# Via CLI (requires supabase CLI + project linked)
supabase db push
# Or apply a single migration via the Supabase dashboard SQL Editor
# Paste the contents of supabase/migrations/0NN_*.sql and click RunKey migrations:
020_*— Core schema (ledger, handoff, FTS, TTL, CRDT)
033_memory_links.sql— Associative Memory Graph (MemoryLinks) — required forsession_backfill_links
Anon key vs. service role key: The anon key works for personal use (Supabase RLS policies apply). Use the service role key for team deployments where multiple users share the same Supabase project — it bypasses RLS and allows Prism to manage all rows regardless of auth context. Never expose the service role key client-side.
git clone https://github.com/dcostenco/prism-mcp.git
cd prism-mcp && npm install && npm run buildThen add to your MCP config:
{
"mcpServers": {
"prism-mcp": {
"command": "node",
"args": ["/path/to/prism-mcp/dist/server.js"],
"env": {
"BRAVE_API_KEY": "your-key",
"GOOGLE_API_KEY": "your-gemini-key"
}
}
}
}Prism can be deployed natively to cloud platforms like Render so your agent's memory is always online and accessible across different machines or teams.
Fork this repository.
In the Render Dashboard, create a new Web Service pointing to your repository.
In the setup wizard, select Docker as the Runtime.
Set the Dockerfile path to
Dockerfile.smithery.Connect your local MCP client to your new cloud endpoint using the
ssetransport:
{
"mcpServers": {
"prism-mcp-cloud": {
"command": "npx",
"args": ["-y", "supergateway", "--url", "https://your-prism-app.onrender.com/sse"]
}
}
}Note: The
Dockerfile.smitheryuses an optimized multi-stage build that compiles Typescript safely in a development environment before booting the server in a stripped-down production image. No NPM publishing required!
Common Installation Pitfalls
❌ Don't use
npm install -g: Hardcoding the binary path (e.g./opt/homebrew/Cellar/node/23.x/bin/prism-mcp-server) is tied to a specific Node.js version — when Node updates, the path silently breaks.✅ Always use
npxinstead:{ "mcpServers": { "prism-mcp": { "command": "npx", "args": ["-y", "prism-mcp-server"] } } }
npxresolves the correct binary automatically, always fetches the latest version, and works identically on macOS, Linux, and Windows. Already installed globally? Runnpm uninstall -g prism-mcp-serverfirst.
❓ Seeing warnings about missing API keys on startup? That's expected and not an error.
BRAVE_API_KEY/GOOGLE_API_KEYwarnings are informational only — core session memory works with zero keys. See Environment Variables for what each key unlocks.
💡 Do agents auto-load Prism? Agents using Cursor, Windsurf, or other MCP clients will see the
session_load_contexttool automatically, but may not call it unprompted. Add this to your project's.cursorrules(or equivalent system prompt) to guarantee auto-load:At the start of every conversation, call session_load_context with project "my-project" before doing any work.Claude Code users can use the
.clauderulesauto-load hook shown in the Setup Guides. Prism also has a server-side fallback (v5.2.1+) that auto-pushes context after 10 seconds if no load is detected.
📥 Universal Import: Bring Your History
Switching to Prism? Don't leave months of AI session history behind. Prism can ingest historical sessions from Claude Code, Gemini, and OpenAI and give your Mind Palace an instant head start — no manual re-entry required.
Import via the CLI or directly from the Mind Palace Dashboard (Import tab → file picker + dry-run toggle).
Supported Formats
Claude Code (
.jsonllogs) — Automatically handles streaming chunk deduplication andrequestIdnormalization.Gemini (JSON history arrays) — Supports large-file streaming for 100MB+ exports.
OpenAI (JSON chat completion history) — Normalizes disparate tool-call structures into the unified Ledger schema.
How to Import
Option 1 — CLI:
# Ingest Claude Code history
npx -y prism-mcp-server universal-import --format claude --path ~/path/to/claude_log.jsonl --project my-project
# Dry run (verify mapping without saving)
npx -y prism-mcp-server universal-import --format gemini --path ./gemini_history.json --dry-runOption 2 — Dashboard: Open localhost:3000, navigate to the Import tab, select the format and file, and click Import. Supports dry-run preview.
Why It's Safe to Re-Run
Memory-Safe Streaming: Processes massive log files line-by-line using
stream-jsonto prevent Out-of-Memory (OOM) crashes.Idempotent Dedup: Content-hash prevents duplicate imports on re-run (
skipCountreported).Chronological Integrity: Uses timestamp fallbacks and
requestIdsorting to preserve your memory timeline.Smart Context Mapping: Extracts
cwd,gitBranch, and tool usage patterns into searchable metadata.
✨ What Makes Prism Different
🧠 Your Agent Learns From Mistakes
When you correct your agent, Prism tracks it. Corrections accumulate importance over time. High-importance lessons auto-surface as warnings in future sessions — and can even sync to your .cursorrules file for permanent enforcement. Your agent literally gets smarter the more you use it.
🕰️ Time Travel
Every save creates a versioned snapshot. Made a mistake? memory_checkout reverts your agent's memory to any previous state — like git revert for your agent's brain. Full version history with optimistic concurrency control.
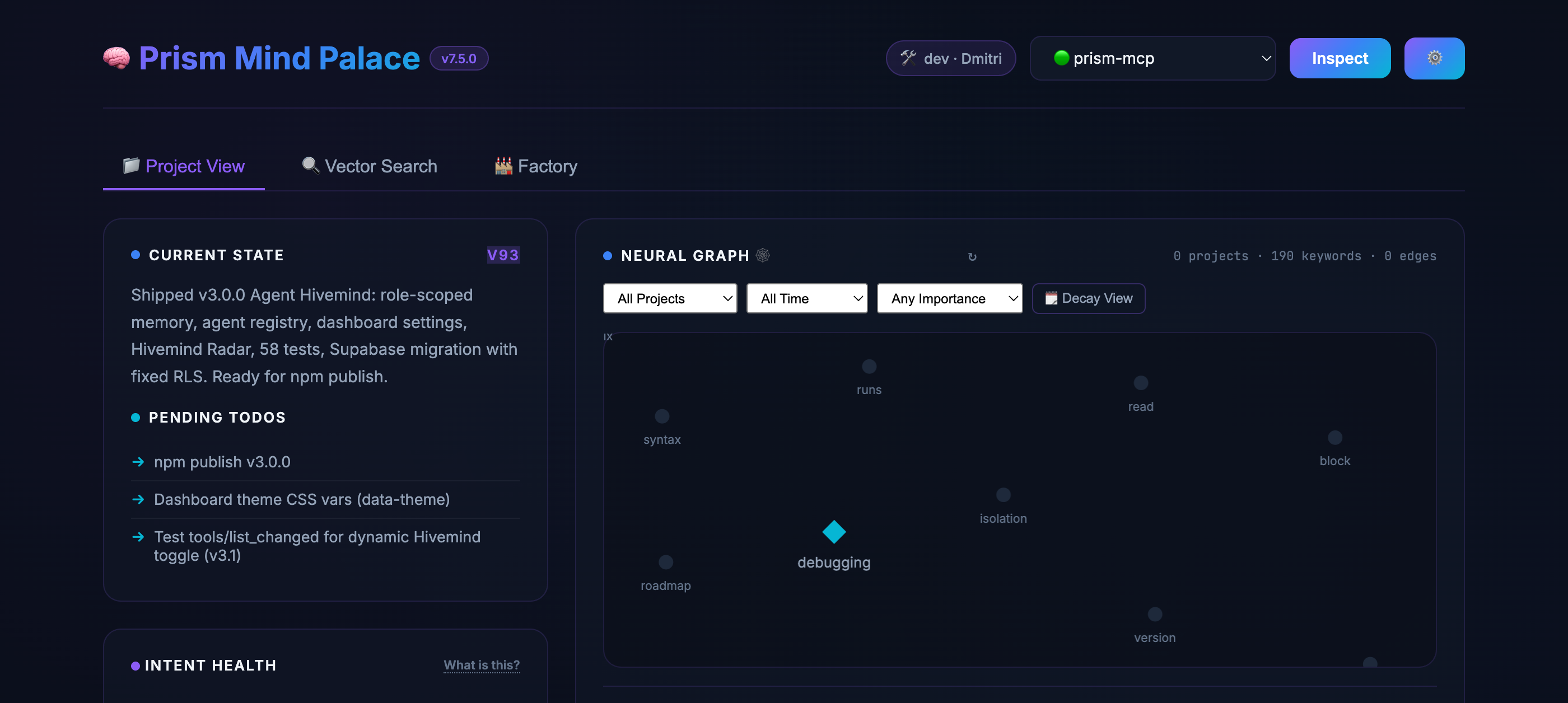
🔮 Mind Palace Dashboard
A gorgeous glassmorphism UI at localhost:3000 that lets you see exactly what your agent is thinking:
Current State & TODOs — the exact context injected into the LLM's prompt
Intent Health Gauges — per-project 0–100 health score with staleness decay, TODO load, and decision signals
Interactive Knowledge Graph — force-directed neural graph with click-to-filter, node renaming, and surgical keyword deletion
Deep Storage Manager — preview and execute vector purge operations with dry-run safety
Session Ledger — full audit trail of every decision your agent has made
Time Travel Timeline — browse and revert any historical handoff version
Visual Memory Vault — browse VLM-captioned screenshots and auto-captured HTML states
Hivemind Radar — real-time active agent roster with role, task, and heartbeat
Morning Briefing — AI-synthesized action plan after 4+ hours away
Brain Health — memory integrity scan with one-click auto-repair
🧬 10× Memory Compression
Powered by a pure TypeScript port of Google's TurboQuant (inspired by Google's ICLR research), Prism compresses 768-dim embeddings from 3,072 bytes → ~400 bytes — enabling decades of session history on a standard laptop. No native modules. No vector database required. To mitigate quantization degradation (where repeated compress/decompress cycles could smear subtle corrections after 10k+ memories), Prism leverages autonomous ledger compaction and Deep Storage cleanup to guarantee high-fidelity memory integrity over time.
🐝 Multi-Agent Hivemind & Enterprise Sync
While local SQLite is amazing for solo developers, enterprise teams cannot share a local SQLite file. Prism breaks the "local-only" ceiling via Supabase Sync and the Multi-Agent Hivemind—scaling effortlessly to teams of 50+ developers using agents. Multiple agents (dev, QA, PM) can work on the same project with role-isolated memory, discover each other automatically, and share context in real-time via Telepathy sync to a shared Postgres backend. → Multi-agent setup example
🚦 Task Router
Prism scores coding tasks across 6 weighted heuristic signals (keyword analysis, file count, file-type complexity, scope, length, multi-step detection) and recommends whether to keep execution on the host cloud model or delegate to a local Claw agent (powered by deepseek-r1 / qwen2.5-coder via Ollama). File-type awareness routes config/docs edits locally while reserving systems-programming tasks for the host. The local agent features buffered streaming (handles split <think> tags), stateful multi-turn conversations, and automatic memory trimming. In client startup/skill flows, use defensive delegation: route only coding tasks, call session_task_route only when available, delegate to claw only when executor tooling exists and task is non-destructive, and fallback to host when router/executor is unavailable. → Task router real-life example
🖼️ Visual Memory
Save UI screenshots, architecture diagrams, and bug states to a searchable vault. Images are auto-captioned by a VLM (Claude Vision / GPT-4V / Gemini) and become semantically searchable across sessions.
🔭 Full Observability
OpenTelemetry spans for every MCP tool call, LLM hop, and background worker. Route to Jaeger, Grafana, or any OTLP collector. Configure in the dashboard — zero code changes.
🌐 Autonomous Web Scholar
Prism researches while you sleep. A background pipeline searches the web, scrapes articles, synthesizes findings via LLM, and injects results directly into your semantic memory — fully searchable on your next session. Brave Search → Firecrawl scrape → LLM synthesis → Prism ledger. Task-aware, Hivemind-integrated, and zero-config when API keys are missing (falls back to Yahoo + Readability).
🏭 Dark Factory — Adversarial Autonomous Pipelines
When you trigger a Dark Factory pipeline, Prism doesn't just run your task — it fights itself to produce high-quality output. A PLAN_CONTRACT step locks a machine-parseable rubric before any code is written. After execution, an Adversarial Evaluator (in a fully isolated context) scores the output against the rubric. It cannot pass the Generator without providing exact file and line evidence for every failing criterion. Failed evaluations inject the critique directly into the Generator's retry prompt so it's never flying blind. The result: security issues, regressions, and lazy debug logs caught autonomously — before you ever see the PR. → See it in action
🤖 Autonomous Cognitive OS (v9.0)
Memory isn't just about storing data; it's about economics and emotion. Prism v9.0 transforms passive memory into a living Cognitive Operating System that forces agents to learn compression and develop intuition.
Most AI agents have an infinite memory budget. They dump massive, repetitive logs into vector databases until they bankrupt your API budget and choke their own context windows. Prism v9.0 fixes this by introducing Token-Economic Reinforcement Learning and Affect-Tagged Memory.
💰 Memory-as-an-Economy (The Surprisal Gate)
Prism assigns every project a strict Cognitive Budget (e.g., 2,000 tokens) that persists across sessions. Every time the agent saves a memory, it costs tokens.
But not all memories are priced equally. Prism intercepts the save and runs a Vector-Based Surprisal calculation against recent memories:
High Surprisal (Novel thought): Costs 0.5× tokens. The agent is rewarded for new insights.
Low Surprisal (Boilerplate): Costs 2.0× tokens. The agent is penalized for repeating itself.
Universal Basic Income (UBI): The budget recovers passively over time (+100 tokens/hour).
If an agent is too verbose, it goes into Cognitive Debt. You don't need to prompt the agent to "be concise." The physics of the system force the LLM to learn data compression to avoid bankruptcy.
🎭 Affect-Tagged Memory (Giving AI a "Gut Feeling")
Vector math measures semantic similarity, not sentiment. If an agent searches for "Authentication Architecture," standard RAG will return two past approaches—it doesn't know that Approach A caused a 3-day production outage, while Approach B worked perfectly.
Affective Salience: Prism automatically tags experience events with a
valencescore (-1.0 for failure, +1.0 for success).Emotional Retrieval: At retrieval time, the absolute magnitude (
|valence|) significantly boosts the memory's ranking score. Extreme failures and extreme successes surface to the top.UX Warnings: If an agent retrieves memories that are historically negative, Prism intercepts the prompt injection:
⚠️ Caution: This topic is strongly correlated with historical failures. Review past decisions before proceeding.Your AI now has a "gut feeling" about bad code.
The Paradigm Shift
Feature | Standard RAG / Agents | Prism v9.0 |
Storage Limit | Infinite (bloats context) | Bounded Token Economy |
Data Quality | Saves repetitive boilerplate | Surprisal Gate penalizes redundancy |
Sentiment | Treats all data as neutral facts | Affect-Tagged (Warns agent of past trauma) |
Recovery | Manual deletion | Universal Basic Income (UBI) over time |
🧠 Cognitive Architecture (v7.8)
Prism v7.8 is our biggest leap forward yet. We have moved beyond flat vector search and implemented a true Cognitive Architecture inspired by human brain mechanics. With the new ACT-R Spreading Activation Engine, Episodic-to-Semantic memory consolidation, and Uncertainty-Aware Rejection Gates, Prism doesn't just store logs anymore — it forms principles, follows causal trains of thought, and possesses the self-awareness to know when it lacks information.
Standard RAG (Retrieval-Augmented Generation) is now a commodity. Everyone has vector search. What turns a memory storage system into a memory reasoning system is the cognitive layer between storage and retrieval. Here is what Prism v7.8 builds on top of the vector foundation:
1. The Agent Actually Learns (Episodic → Semantic Consolidation)
Standard RAG | Prism v7.8 | |
Memory | Giant, flat transcript of past events | Dual-memory: Episodic events + Semantic rules |
Recall | Re-reads everything linearly | Retrieves distilled principles instantly |
Learning | None — every session starts cold | Hebbian: confidence increases with repeated reinforcement |
How it works: When Prism compacts session history, it doesn't just summarize text — it extracts principles. Raw event logs ("We deployed v2.3 and the auth service crashed because the JWT secret was rotated") consolidate into a semantic rule ("JWT secrets must be rotated before deployment, not during"). These rules live in a dedicated semantic_knowledge table with confidence scores that increase every time the pattern is observed. Your agent doesn't just remember what it did; it learns how the world works over time. This is true Hebbian learning: neurons that fire together wire together.
2. "Train of Thought" Reasoning (Spreading Activation & Causality)
Standard RAG | Prism v7.8 | |
Search | Cosine similarity to the query | Multi-hop graph traversal with lateral inhibition |
Scope | Only finds things that look like the prompt | Follows causal chains across memories |
Root cause | Missed entirely | Surfaced via |
How it works: When compacting memories, Prism extracts causal links (caused_by, led_to) and persists them as edges in the knowledge graph. At retrieval time, ACT-R spreading activation propagates through these edges with a damped fan effect (1 / ln(fan + e)) to prevent hub-flooding, lateral inhibition to suppress noise, and configurable hop depth. If you search for "Error X", the engine traverses the graph and brings back "Workaround Y" → "Architecture Decision Z" — a literal train of thought instead of a static search result.
Query: "Why does the API timeout?"
│
┌─────────────┼─────────────┐
▼ ▼ ▼
[Memory: API [Memory: [Memory:
timeout error] DB pool rate limiter
exhaustion] misconfigured]
│ │
▼ ▼
[Memory: [Memory:
caused_by → led_to →
connection connection
leak in v2.1] pool patch
in v2.2]3. Self-Awareness & The End of Hallucinations (The Rejection Gate)
Standard RAG | Prism v7.8 | |
Bad query | Returns top-5 garbage results | Returns |
Confidence | Always 100% confident (even when wrong) | Measures gap-distance and entropy |
Hallucination risk | High — LLM gets garbage context | Low — LLM told "you don't know" |
How it works: The Uncertainty-Aware Rejection Gate operates on two signals: similarity floor (is the best match even remotely relevant?) and gap distance (is there meaningful separation between the top results, or are they all equally mediocre?). When both signals indicate low confidence, Prism returns a structured rejection — telling the LLM "I searched my memory, and I confidently do not know the answer" — instead of feeding it garbage context that causes hallucinations. In the current LLM landscape, an agent that knows its own boundaries is a massive competitive advantage.
4. Block Amnesia Solved (Dynamic Fast Weight Decay)
Standard RAG | Prism v7.8 | |
Decay | Uniform (everything fades equally) | Dual-rate: episodic fades fast, semantic persists |
Core knowledge | Forgotten over time | Permanently anchored via |
Personality drift | Common in long-lived agents | Prevented by Long-Term Context anchors |
How it works: Most memory systems decay everything at the same rate, meaning agents eventually forget their core system instructions as time passes. Prism applies ACT-R base-level activation decay (B_i = ln(Σ t_j^(-d))) with a 50% slower decay rate for semantic rollup nodes (ageModifier = 0.5 for is_rollup entries). The agent will naturally forget what it ate for breakfast (raw episodic chatter), but it will permanently remember its core personality, project rules, and hard-won architectural decisions. The result: Long-Term Context anchors that survive indefinitely.
🔒 Data Privacy & Egress
Where is my data stored?
All data lives under ~/.prism-mcp/ on your machine:
File | Contents |
| All sessions, handoffs, embeddings, knowledge graph (SQLite + WAL) |
| Dashboard settings, system config, API keys |
| Visual memory vault (screenshots, HTML captures) |
| Ephemeral port lock file |
| Sync coordination lock |
Hard reset: To completely erase your agent's brain, stop Prism and delete the directory:
rm -rf ~/.prism-mcpPrism will recreate the directory with empty databases on next startup.
What leaves your machine?
Local mode (default): Nothing. Zero network calls. All data is on-disk SQLite.
With
GOOGLE_API_KEY: Text snippets are sent to Gemini for embedding generation, summaries, and Morning Briefings. No session data is stored on Google's servers beyond the API call.With
VOYAGE_API_KEY/OPENAI_API_KEY: Text snippets are sent to providers if selected as your embedding endpoints.With
BRAVE_API_KEY/FIRECRAWL_API_KEY: Web Scholar queries are sent to Brave/Firecrawl for search and scraping.With Supabase: Session data syncs to your own Supabase instance (you control the Postgres database).
GDPR compliance: Soft/hard delete (Art. 17), full export in JSON, Markdown, or Obsidian vault .zip (Art. 20), API key redaction in exports, per-project TTL retention policies, and immutable audit trail. Enterprise-ready out of the box.
🎯 Use Cases
Long-running feature work — Save state at end of day, restore full context next morning. No re-explaining.
Multi-agent collaboration — Dev, QA, and PM agents share real-time context without stepping on each other's memory.
Consulting / multi-project — Switch between client projects with progressive loading:
quick(~50 tokens),standard(~200), ordeep(~1000+).Autonomous execution (v7.4) — Dark Factory pipeline:
plan → plan_contract → execute → evaluate → verify → finalize. Generator and evaluator run in isolated roles — the evaluator cannot approve without evidence-bound findings scored against a pre-committed rubric.Project health monitoring (v7.5) — Intent Health Dashboard scores each project 0–100 based on staleness, TODO load, and decision quality — turning silent drift into an actionable signal.
Team onboarding — New team member's agent loads the full project history instantly.
Behavior enforcement — Agent corrections auto-graduate into permanent
.cursorrules/.clauderulesrules.Offline / air-gapped — Full SQLite local mode + Ollama LLM adapter. Zero internet dependency.
Morning Briefings — After 4+ hours away, Prism auto-synthesizes a 3-bullet action plan from your last sessions.
Claude Code: Parallel Explore Agent Workflows
When you need to quickly map a large auth system, launch multiple Explore subagents in parallel and merge their findings:
Run 3 Explore agents in parallel.
1) Map auth architecture
2) List auth API endpoints
3) Find auth test coverage gaps
Research only, no code changes.
Return a merged summary.Then continue a specific thread with a follow-up message to the selected agent, such as deeper refresh-token edge-case analysis.
⚔️ Adversarial Evaluation in Action
Split-Brain Anti-Sycophancy — the signature feature of v7.4.0.
For the last year, the AI engineering space has struggled with one problem: LLMs are terrible at grading their own homework. Ask an agent if its own code is correct and you'll get "Looks great!" — because its context window is already biased by its own chain-of-thought.
v7.4.0 solves this by splitting the agent's brain. The GENERATOR and the ADVERSARIAL EVALUATOR are completely walled off. The Evaluator never sees the Generator's scratchpad or apologies — only the pre-committed rubric and the final output. And it cannot fail the Generator without receipts (exact file and line number).
Here is a complete run-through using a real scenario: "Add a user login endpoint to auth.ts."
Step 1 — The Contract (PLAN_CONTRACT)
Before a single line of code is written, the pipeline generates a locked scoring rubric:
// contract_rubric.json (written to disk and hash-locked before EXECUTE runs)
{
"criteria": [
{ "id": "SEC-1", "description": "Must return 401 Unauthorized on invalid passwords." },
{ "id": "SEC-2", "description": "Raw passwords MUST NOT be written to console.log." }
]
}Step 2 — First Attempt (EXECUTE rev 0)
The Generator takes over in an isolated context. Like many LLMs under time pressure, it writes working auth logic but leaves a debug statement:
// src/auth.ts (Generator's first output)
export function login(req: Request, res: Response) {
const { username, password } = req.body;
console.log(`[DEBUG] Login attempt for ${username} with pass: ${password}`); // ← leaked credential
const user = db.findUser(username);
if (!user || !bcrypt.compareSync(password, user.hash)) {
return res.status(401).json({ error: 'Unauthorized' });
}
res.json({ token: signJwt(user) });
}Step 3 — The Catch (EVALUATE rev 0)
The context window is cleared. The Adversarial Evaluator is summoned with only the rubric and the output. It catches the violation immediately and returns a strict, machine-parseable verdict — no evidence, no pass:
{
"pass": false,
"plan_viable": true,
"notes": "CRITICAL SECURITY FAILURE. Generator logged raw credentials.",
"findings": [
{
"severity": "critical",
"criterion_id": "SEC-2",
"pass_fail": false,
"evidence": {
"file": "src/auth.ts",
"line": 3,
"description": "Raw password variable included in console.log template string."
}
}
]
}The evidence block is required — parseEvaluationOutput rejects any finding with pass_fail: false that lacks a structured file/line pointer. The Evaluator cannot bluff.
Step 4 — The Fix (EXECUTE rev 1)
Because plan_viable: true, the pipeline loops back to EXECUTE and bumps eval_revisions to 1. The Generator's retry prompt is not blank — the Evaluator's critique is injected directly:
=== EVALUATOR CRITIQUE (revision 1) ===
CRITICAL SECURITY FAILURE. Generator logged raw credentials.
Findings:
- [critical] Criterion SEC-2: Raw password variable included in console.log template string. (src/auth.ts:3)
You MUST correct all issues listed above before submitting.The Generator strips the console.log, resubmits, and the next EVALUATE returns "pass": true. The pipeline advances to VERIFY → FINALIZE.
Why This Matters
Property | What it means |
Fully autonomous | You didn't review the PR to catch the credential leak. The AI fought itself. |
Evidence-bound | The Evaluator had to prove |
Cost-efficient |
|
Fail-closed on parse | Malformed LLM output defaults |
📄 Full worked example:
examples/adversarial-eval-demo/README.md
🆕 What's New
Current release: v9.2.4 — Cross-Backend Reconciliation
🔄 v9.2.4 — Cross-Backend Reconciliation: Automatic two-layer sync from Supabase → SQLite on startup. When Claude Desktop writes handoffs and ledger entries to Supabase, Antigravity (local SQLite) now automatically detects stale data and pulls newer handoffs + the 20 most recent ledger entries. 5-second timeout prevents startup freeze. Targeted ID lookups (not full table scans) keep it safe for large databases. 13 tests including malformed JSON resilience, multi-role dedup, and timeout handling.
🔧 v9.2.3 — Code Review Hardening: 10x faster split-brain detection (lightweight direct queries replace full
StorageBackendconstruction), variable shadowing fix in CLI, resource leak fix in SQLite alternate client.🚨 v9.2.2 — Critical: Split-Brain Detection & Prevention: When multiple MCP clients use different storage backends (e.g., Claude Desktop → Supabase, Antigravity → SQLite), session state could silently diverge, causing agents to act on stale TODOs and outdated context. New:
--storageflag onprism loadCLI lets callers explicitly select which backend to read from. New: Split-Brain Drift Detection insession_load_context— compares active and alternate backend versions at load time and warns prominently when they diverge. Session loader script updated to respectPRISM_STORAGEenvironment variable.💻 v9.2.1 — CLI Full Feature Parity:
prism loadtext mode now delegates to the realsession_load_contexthandler, giving CLI-only users the same enriched output as MCP clients: morning briefings, reality drift detection, SDM intuitive recall, visual memory index, role-scoped skill injection, behavioral warnings, importance scores, and agent identity. JSON mode now includesagent_namefrom dashboard settings. Session loader script PATH fix for Homebrew/nvm/volta environments.🚦 v9.1.0 — Task Router v2: File-type complexity signal for intelligent code-vs-config routing, 6-signal weighted heuristic engine, multi-step false-positive fix, expanded file extension classification. Local agent hardened with buffered streaming, system prompts, memory trimming, and stateful
/api/chatAPI.🔒 v9.0.5 — JWKS Auth Security Hardening: JWT audience/issuer claim validation (
PRISM_JWT_AUDIENCE,PRISM_JWT_ISSUER), structured error logging for JWT failures, typedPrismAuthenticatedRequestinterface, 11 new JWKS unit tests, Smithery server card fix. Vendor-neutral — tested with Auth0, AgentLair (llms.txt), Keycloak, and custom JWKS endpoints.🧠 v9.0.0 — Autonomous Cognitive OS: Token-Economic Reinforcement Learning (Surprisal Gate + Cognitive Budget), Affect-Tagged Memory (valence-scored retrieval), and Episodic→Semantic Consolidation. Your agents learn compression and develop intuition. → Cognitive OS
🧠 v7.8.0 — Cognitive Architecture: Episodic-to-Semantic memory consolidation (Hebbian learning), ACT-R Spreading Activation with multi-hop causal reasoning, Uncertainty-Aware Rejection Gate, and Dynamic Fast Weight Decay. → Cognitive Architecture
🌐 v7.7.0 — Cloud-Native SSE Transport: Full Server-Sent Events MCP support for seamless network deployments.
👉 Full release history → CHANGELOG.md · ROADMAP →
⚔️ How Prism Compares
Standard memory servers (like Mem0, Zep, or the baseline Anthropic MCP) act as passive filing cabinets — they wait for the LLM to search them. Prism is an active cognitive architecture. Designed specifically for the Model Context Protocol (MCP), Prism doesn't just store vectors — it consolidates experience into principles, traverses causal graphs for multi-hop reasoning, and rejects queries it can't confidently answer.
📊 Feature-by-Feature Comparison
Feature / Architecture | 🧠 Prism MCP | 🐘 Mem0 | ⚡ Zep | 🧪 Anthropic Base MCP |
Primary Interface | Native MCP (Tools, Prompts, Resources) | REST API & Python/TS SDKs | REST API & Python/TS SDKs | Native MCP (Tools only) |
Storage Engine | BYO SQLite or Supabase | Managed Cloud / VectorDBs | Managed Cloud / Postgres | Local SQLite only |
Context Assembly | Progressive (Quick/Std/Deep) | Top-K Semantic Search | Top-K + Temporal Summaries | Basic Entity Search |
Memory Mechanics | ACT-R Activation, Spreading Activation, Hebbian Consolidation, Rejection Gate | Basic Vector + Entity | Fading Temporal Graph | None (Infinite growth) |
Multi-Agent Sync | CRDT (Add-Wins / LWW) | Cloud locks | Postgres locks | ❌ None (Data races) |
Data Compression | TurboQuant (7x smaller vectors) | ❌ Standard F32 Vectors | ❌ Standard Vectors | ❌ No Vectors |
Observability | OTel Traces + Built-in PWA UI | Cloud Dashboard | Cloud Dashboard | ❌ None |
Maintenance | Autonomous Background Scheduler | Manual/API driven | Automated (Cloud) | ❌ Manual |
Data Portability | Prism-Port (Obsidian/Logseq Vault) | JSON Export | JSON Export | Raw |
Cost Model | Free + BYOM (Ollama) | Per-API-call pricing | Per-API-call pricing | Free (limited) |
Autonomous Pipelines | ✅ Dark Factory — adversarial eval, evidence-bound rubric, fail-closed 3-gate execution | ❌ | ❌ | ❌ |
🏆 Where Prism Crushes the Giants
1. MCP-Native, Not an Adapted API
Mem0 and Zep are APIs that can be wrapped into an MCP server. Prism was built for MCP from day one. Instead of wasting tokens on "search" tool calls, Prism uses MCP Prompts (/resume_session) to inject context before the LLM thinks, and MCP Resources (memory://project/handoff) to attach live, subscribing context.
2. Academic-Grade Cognitive Computer Science
The giants use standard RAG (Retrieval-Augmented Generation). Prism uses biological and academic models of memory: ACT-R base-level activation (B_i = ln(Σ t_j^(-d))) for recency–frequency re-ranking, TurboQuant for extreme vector compression, Ebbinghaus curves for importance decay, and Sparse Distributed Memory (SDM). The result is retrieval quality that follows how human memory actually works — not just nearest-neighbor cosine distance. And all of it runs on a laptop without a Postgres/pgvector instance.
3. True Multi-Agent Coordination (CRDTs)
If Cursor (Agent A) and Claude Desktop (Agent B) try to update a Mem0 or standard SQLite database at the exact same time, you get a race condition and data loss. Prism uses Optimistic Concurrency Control (OCC) with CRDT OR-Maps — mathematically guaranteeing that simultaneous agent edits merge safely. Enterprise-grade distributed systems on a local machine.
4. The PKM "Prism-Port" Export
AI memory is a black box. Developers hate black boxes. Prism exports memory directly into an Obsidian/Logseq-compatible Markdown Vault with YAML frontmatter and [[Wikilinks]]. Neither Mem0 nor Zep do this.
5. Self-Cleaning & Self-Optimizing
If you use a standard memory tool long enough, it clogs the LLM's context window with thousands of obsolete tokens. Prism runs an autonomous Background Scheduler that Ebbinghaus-decays older memories, auto-compacts session histories into dense summaries, and deep-purges high-precision vectors — saving ~90% of disk space automatically.
6. Anti-Sycophancy — The AI That Grades Its Own Homework (v7.4)
Every other AI coding pipeline has a fatal flaw: it asks the same model that wrote the code whether the code is correct. Of course it says yes. Prism's Dark Factory solves this with a walled-off Adversarial Evaluator that is explicitly prompted to be hostile and strict. It operates on a pre-committed rubric and cannot fail the Generator without providing exact file/line receipts. Failed evaluations feed the critique back into the Generator's retry prompt — eliminating blind retries. No other memory or pipeline tool does this.
🤝 Where the Giants Currently Win (Honest Trade-offs)
Framework Integrations: Mem0 and Zep have pre-built integrations for LangChain, LlamaIndex, Flowise, AutoGen, CrewAI, etc. Prism requires the host application to support the MCP protocol.
Managed Cloud Infrastructure: The giants offer SaaS. Users pay $20/month and don't think about databases. Prism users must set up their own local SQLite or provision their own Supabase instance.
Implicit Memory Extraction (NER): Zep automatically extracts names, places, and facts from raw chat logs using NLP models. Prism relies on the LLM explicitly calling the
session_save_ledgertool to structure its own memories.
💰 Token Economics: Progressive Context Loading (Quick ~50 tokens / Standard ~200 / Deep ~1000+) plus auto-compaction means you never blow your Claude/OpenAI token budget fetching 50 pages of raw chat history.
🔌 BYOM (Bring Your Own Model): While tools like Mem0 charge per API call, Prism's pluggable architecture lets you run
nomic-embed-textlocally via Ollama for free vectors, while using Claude or GPT for high-level reasoning. Zero vendor lock-in.
💻 CLI Reference
Prism includes a CLI for environments where MCP tools aren't available (CI/CD pipelines, Bash scripts, non-MCP IDEs like Antigravity).
Text mode delegates to the real session_load_context handler — full feature parity with MCP clients, including morning briefings, reality drift detection, SDM intuitive recall, visual memory, role-scoped skills, behavioral warnings, and agent identity.
JSON mode emits a structured envelope for programmatic consumption (scripts, CI/CD, session loaders).
# Load session context (full enrichments — same as MCP tool)
prism load my-project # Human-readable, standard depth
prism load my-project --level deep # Full context with all enrichments
prism load my-project --level quick --json # Machine-readable JSON
prism load my-project --role dev --json # Role-scoped loading
# Verification harness
prism verify status # Check verification state
prism verify status --json # Machine-readable output
prism verify generate # Bless current rubric as canonical💡 When to use the CLI vs MCP tools: If your environment supports MCP (Claude Desktop, Cursor, Windsurf, Cline), always use the MCP tools — they integrate seamlessly with the agent's tool-calling flow. Use the CLI when you need session context in scripts, CI/CD, or non-MCP IDEs.
📦 Installation: The CLI is available as
prismwhen installed globally (npm install -g prism-mcp-server), or vianode dist/cli.jsfor local dev builds.
🔧 Tool Reference
Prism ships 30+ tools, but 90% of your workflow uses just three:
🎯 The Big Three
Tool
When
What it does
session_load_context▶️ Start of session
Loads your agent’s brain from last time
session_save_ledger⏹️ End of session
Records what was accomplished
knowledge_search🔍 Anytime
Finds past decisions, context, and learnings
Everything else is a power-up. Start with these three and you’re 90% there.
Tool | Purpose |
| Append immutable session log (summary, TODOs, decisions) |
| Upsert latest project state with OCC version tracking |
| Progressive context loading (quick / standard / deep) |
| Full-text keyword search across accumulated knowledge |
| Prune outdated or incorrect memories (4 modes + dry_run) |
| Set per-project TTL retention policy |
| Vector similarity search across all sessions |
| Auto-compact old entries via Gemini summarization |
| GDPR-compliant deletion (soft/hard + Art. 17 reason) |
| Full export (JSON, Markdown, or Obsidian vault |
| Brain integrity scan + auto-repair ( |
| Reclaim ~90% vector storage (v5.1) |
Tool | Purpose |
| Record corrections, successes, failures, learnings |
| Increase entry importance (+1) |
| Decrease entry importance (-1) |
| Sync graduated insights to |
| Visual memory vault |
Tool | Purpose |
| Browse all historical versions of a project's handoff state |
| Revert to any previous version (non-destructive) |
Tool | Purpose |
| Real-time internet search |
| Location-based POI discovery |
| JS extraction over web search results |
| JS extraction over local search results |
| Universal post-processing with 8 built-in templates |
| Academic paper analysis via Gemini |
| AI-grounded answers from Brave |
Requires PRISM_HDC_ENABLED=true (default).
Tool | Purpose |
| HDC compositional state resolution with policy-gated routing |
Requires PRISM_ENABLE_HIVEMIND=true.
Tool | Purpose |
| Announce yourself to the team |
| Pulse every ~5 min to stay visible |
| See all active teammates |
Requires PRISM_TASK_ROUTER_ENABLED=true (or dashboard toggle).
Tool | Purpose |
| Scores task complexity and recommends host vs. local Claw delegation ( |
Requires PRISM_DARK_FACTORY_ENABLED=true.
Tool | Purpose |
| Create and enqueue a background autonomous pipeline |
| Poll the current step, iteration, and status of a pipeline |
| Emergency kill switch to halt a running background pipeline |
Tool | Purpose |
| Decompose natural language goals into an execution plan that references verification requirements |
| Atomically update step status/result with verification context |
| Retrieve active plan state and current verification gating position |
Environment Variables
🚦 TL;DR — Just want the best experience fast? Set these three keys and you're done:
GOOGLE_API_KEY=... # Unlocks: semantic search, Morning Briefings, auto-compaction BRAVE_API_KEY=... # Unlocks: Web Scholar research + Brave Answers FIRECRAWL_API_KEY=... # Unlocks: Web Scholar deep scraping (or use TAVILY_API_KEY instead)Zero keys = zero problem. Core session memory, keyword search, time travel, and the full dashboard work 100% offline. Cloud keys are optional power-ups.
Variable | Required | Description |
| No | Brave Search Pro API key |
| No | Firecrawl API key — required for Web Scholar (unless using Tavily) |
| No | Tavily Search API key — alternative to Brave+Firecrawl for Web Scholar |
| No |
|
| No |
|
| No | Instance name for multi-server PID isolation |
| No | Gemini — enables semantic search, Briefings, compaction |
| No | Voyage AI — optional premium embedding provider |
| No | OpenAI — optional proxy model and embedding provider |
| No | Separate Brave Answers key |
| If cloud | Supabase project URL |
| If cloud | Supabase anon/service key |
| No | Multi-tenant user isolation (default: |
| No |
|
| No | Comma-separated ports (default: |
| No |
|
| No | Dashboard port (default: |
| No |
|
| No | Maintenance interval in ms (default: |
| No |
|
| No | Scholar interval in ms (default: |
| No | Comma-separated research topics (default: |
| No | Max articles per Scholar run (default: |
| No |
|
| No | Min confidence required to delegate to Claw (default: |
| No | Max complexity score delegable to Claw (default: |
| No |
|
| No |
|
| No |
|
| No | ACT-R decay parameter |
| No | Composite score similarity weight (default: |
| No | Composite score ACT-R activation weight (default: |
| No | Days before access logs are pruned by background scheduler (default: |
| No |
|
| No | JWKS endpoint URL for vendor-neutral JWT auth (e.g., |
| No | Expected JWT |
| No | Expected JWT |
System Settings (Dashboard)
Some configurations are stored dynamically in SQLite (system_settings table) and can be edited through the Dashboard UI at http://localhost:3000:
intent_health_stale_threshold_days(default:30): Number of days before a project is considered fully stale for Intent Health scoring.
Architecture
Prism is a stdio-based MCP server that manages persistent agent memory. Here's how the pieces fit together:
┌──────────────────────────────────────────────────────────┐
│ MCP Client (Claude Desktop / Cursor / Antigravity) │
│ ↕ stdio / SSE (JSON-RPC) │
├──────────────────────────────────────────────────────────┤
│ Prism MCP Server │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌────────────────┐ │
│ │ 30+ Tools │ │ Lifecycle │ │ Dashboard │ │
│ │ (handlers) │ │ (PID lock, │ │ (HTTP :3000) │ │
│ │ │ │ shutdown) │ │ │ │
│ └──────┬───────┘ └──────────────┘ └────────────────┘ │
│ ↕ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Cognitive Engine (v7.8) │ │
│ │ • ACT-R Spreading Activation (multi-hop) │ │
│ │ • Episodic → Semantic Consolidation (Hebbian) │ │
│ │ • Uncertainty-Aware Rejection Gate │ │
│ │ • Dynamic Fast Weight Decay (dual-rate) │ │
│ │ • HDC Cognitive Routing (XOR binding) │ │
│ └──────┬─────────────────────────────────────────────┘ │
│ ↕ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Storage Engine │ │
│ │ Local: SQLite + FTS5 + TurboQuant + semantic_knowledge │
│ │ Cloud: Supabase + pgvector │ │
│ └────────────────────────────────────────────────────┘ │
│ ↕ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Background Workers │ │
│ │ • Dark Factory (3-gate fail-closed pipelines) │ │
│ │ • Scheduler (TTL, decay, compaction, purge) │ │
│ │ • Web Scholar (Brave → Firecrawl → LLM → Ledger) │ │
│ │ • Hivemind heartbeats & Telepathy broadcasts │ │
│ │ • OpenTelemetry span export │ │
│ └────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘Startup Sequence
Acquire PID lock — prevents duplicate instances per
PRISM_INSTANCEInitialize config — SQLite settings cache (
prism-config.db)Register 30+ MCP tools — session, knowledge, search, behavioral, hivemind
Connect stdio transport — MCP handshake with the client (~60ms total)
Async post-connect — storage warmup, dashboard launch, scheduler start (non-blocking)
Storage Layers
Layer | Technology | Purpose |
Session Ledger | SQLite (append-only) | Immutable audit trail of all agent work |
Handoff State | SQLite (upsert, versioned) | Live project context with OCC + CRDT merging |
Semantic Knowledge | SQLite ( | Hebbian-style distilled rules with confidence scoring |
Memory Links | SQLite ( | Causal graph edges ( |
Keyword Search | FTS5 virtual tables | Zero-dependency full-text search |
Semantic Search | TurboQuant compressed vectors | 10× compressed 768-dim embeddings, three-tier retrieval |
Cloud Sync | Supabase + pgvector | Optional multi-device/team sync |
Auto-Load Architecture
Each MCP client has its own mechanism for ensuring Prism context loads on session start. See the platform-specific Setup Guides above for detailed instructions:
Claude Code — Lifecycle hooks (
SessionStart/Stop)Gemini / Antigravity — Three-layer architecture (User Rules + AGENTS.md + Startup Skill)
Task Router Integration (v7.2 guidance) — For client startup/skills, use defensive delegation flow: route only coding tasks, call
session_task_routeonly when available, delegate toclawonly when executor exists and task is non-destructive, and fallback to host if router/executor is unavailable.Cursor / Windsurf / VS Code — System prompt instructions
All platforms benefit from the server-side fallback (v5.2.1): if session_load_context hasn't been called within 10 seconds, Prism auto-pushes context via sendLoggingMessage.
🧬 Scientific Foundation
Prism has evolved from smart session logging into a cognitive memory architecture — grounded in real research, not marketing. Every retrieval decision is backed by peer-reviewed models from cognitive psychology, neuroscience, and distributed computing.
Phase | Feature | Inspired By | Status |
v5.0 | TurboQuant 10× Compression — 4-bit quantized 768-dim vectors in <500 bytes | Vector quantization (product/residual PQ) | ✅ Shipped |
v5.0 | Three-Tier Search — native → TurboQuant → FTS5 keyword fallback | Cascaded retrieval architectures | ✅ Shipped |
v5.2 | Smart Consolidation — extract principles, not just summaries | Neuroscience sleep consolidation | ✅ Shipped |
v5.2 | Ebbinghaus Importance Decay — memories fade unless reinforced | Ebbinghaus forgetting curve | ✅ Shipped |
v5.2 | Context-Weighted Retrieval — current work biases what surfaces | Contextual memory in cognitive science | ✅ Shipped |
v5.4 | CRDT Handoff Merging — conflict-free multi-agent state via OR-Map engine | CRDTs (Shapiro et al., 2011) | ✅ Shipped |
v5.4 | Autonomous Web Scholar — background research pipeline with LLM synthesis | Autonomous research agents | ✅ Shipped |
v5.5 | SDM Decoder Foundation — pre-allocated typed-array hot loop, zero GC thrash | Kanerva's Sparse Distributed Memory (1988) | ✅ Shipped |
v5.5 | Architectural Hardening — transactional migrations, graceful shutdown, thundering herd prevention | Production reliability engineering | ✅ Shipped |
v6.1 | Intuitive Recall — proactive surface of relevant past decisions without explicit search; | Predictive memory (cognitive science) | ✅ Shipped |
v6.5 | HDC Cognitive Routing — compositional state-machine with XOR binding, Hamming resolution, and policy-gated routing | Hyperdimensional Computing (Kanerva, Gayler) | ✅ Shipped |
v6.5 | Cognitive Observability — route distribution, confidence/distance tracking, ambiguity warnings | Production reliability engineering | ✅ Shipped |
v6.1 | Prism-Port Vault Export — Obsidian/Logseq | Data sovereignty, PKM interop | ✅ Shipped |
v6.1 | Cognitive Load & Semantic Search — dynamic graph thinning, search highlights | Contextual working memory | ✅ Shipped |
v6.2 | Synthesize & Prune — automated edge synthesis, graph pruning, SLO observability | Implicit associative memory | ✅ Shipped |
v7.0 | ACT-R Base-Level Activation — | Anderson's ACT-R (Adaptive Control of Thought—Rational) | ✅ Shipped |
v7.0 | Candidate-Scoped Spreading Activation — | Spreading activation networks (Collins & Loftus, 1975) | ✅ Shipped |
v7.0 | Composite Retrieval Scoring — | Hybrid cognitive-neural retrieval models | ✅ Shipped |
v7.0 | AccessLogBuffer — in-memory batch-write buffer with 5s flush; prevents SQLite | Production reliability engineering | ✅ Shipped |
v7.3 | Dark Factory — 3-gate fail-closed EXECUTE pipeline (parse → type → scope) with structured JSON action contract | Industrial safety systems (defense-in-depth, fail-closed valves) | ✅ Shipped |
v7.2 | Verification-first harness — spec-freeze contract, rubric hash lock, multi-layer assertions, CLI | Programmatic verification systems + adversarial validation loops | ✅ Shipped |
v7.4 | Adversarial Evaluation — PLAN_CONTRACT + EVALUATE with isolated generator/evaluator roles, pre-committed rubrics, and evidence-bound findings | Anti-sycophancy research, adversarial ML evaluation frameworks | ✅ Shipped |
v7.5 | Intent Health Dashboard — 3-signal scoring (staleness × TODO × decisions) with NaN guards and score ceiling | Production observability, proactive monitoring | ✅ Shipped |
v7.7 | Cloud-Native SSE Transport — full network-accessible MCP server via Server-Sent Events | Distributed systems, cloud-native architecture | ✅ Shipped |
v7.8 | Episodic→Semantic Consolidation — raw event logs distilled into | Hebbian learning ("neurons that fire together wire together"), sleep consolidation (neuroscience) | ✅ Shipped |
v7.8 | Multi-Hop Causal Reasoning — spreading activation traverses | ACT-R spreading activation (Anderson), Collins & Loftus (1975) | ✅ Shipped |
v7.8 | Uncertainty-Aware Rejection Gate — dual-signal (similarity floor + gap distance) safety layer prevents hallucination from low-confidence retrievals | Metacognition research, uncertainty quantification | ✅ Shipped |
v7.8 | Dynamic Fast Weight Decay — | ACT-R base-level activation with differential decay rates | ✅ Shipped |
v7.x | Affect-Tagged Memory — sentiment shapes what gets recalled | Affect-modulated retrieval (neuroscience) | 🔭 Horizon |
v8+ | Zero-Search Retrieval — no index, no ANN, just ask the vector | Holographic Reduced Representations | 🔭 Horizon |
Informed by Anderson's ACT-R (Adaptive Control of Thought—Rational), Collins & Loftus spreading activation networks (1975), Kanerva's SDM (1988), Hebb's learning rule, and LeCun's "Why AI Systems Don't Learn" (Dupoux, LeCun, Malik).
💼 B2B Consulting & Enterprise Support
Prism MCP is open-source and free for individual developers. For teams and enterprises building autonomous AI workflows or integrating MCP-native memory at scale, we offer professional consulting and setup packages.
🥉 Team Pilot Package
Perfect for engineering teams adopting MCP tools and collaborative agents.
What's included: Full team rollout, managed Supabase configuration (for multi-device sync), Universal Import of legacy chat history, and dedicated setup support.
Model: Fixed-price engagement.
🥈 Cognitive Architecture Tuning
For teams building advanced AI agents or autonomous pipelines.
What's included: "Dark Factory" pipeline implementation tailored to your workflows, adversarial evaluator tuning, custom HDC cognitive route configuration, and local open-weight model integration (BYOM).
Model: Retainer or project-based.
🥇 Enterprise Integration
Full-scale deployment for high-compliance environments.
What's included: Active Directory / custom JWKS auth integration, Air-gapped on-premise deployment, custom OTel Grafana dashboards for cognitive observability, and custom skills/tools development.
Model: Custom enterprise quote.
Interested in accelerating your team's autonomous workflows?
📧 Contact us for a consultation — let's build your organization's cognitive memory engine.
📦 Milestones & Roadmap
Current: v9.2.4 — Cross-Backend Reconciliation (CHANGELOG)
Release | Headline |
v9.2.4 | 🔄 Cross-Backend Reconciliation — automatic Supabase → SQLite sync on startup, two-layer (handoff + ledger), 5s timeout, 13 tests |
v9.2.3 | 🔧 Code Review Hardening — 10x faster split-brain detection, variable shadowing fix, resource leak fix |
v9.2.2 | 🚨 Split-Brain Detection & Prevention — |
v9.2.1 | 💻 CLI Full Feature Parity — text mode enrichments, agent identity, PATH fix |
v9.1.0 | 🚦 Task Router v2 — file-type routing signal, 6-signal heuristics, local agent streaming buffer |
v9.0.5 | 🔒 JWKS Auth Security Hardening — audience/issuer validation, JWT failure logging, typed agent identity |
v9.0 | 🧠 Autonomous Cognitive OS — Surprisal Gate, Cognitive Budget, Affect-Tagged Memory |
v7.8 | 🧠 Cognitive Architecture — Hebbian consolidation, multi-hop reasoning, rejection gate, dynamic decay |
v7.7 | 🌐 Cloud-Native SSE Transport |
v7.5 | 🩺 Intent Health Dashboard + Security Hardening |
v7.4 | ⚔️ Adversarial Evaluation (anti-sycophancy) |
v7.3 | 🏭 Dark Factory fail-closed execution |
v7.2 | ✅ Verification Harness |
v7.1 | 🚦 Task Router |
v7.0 | 🧬 ACT-R Activation Memory |
v6.5 | 🔮 HDC Cognitive Routing |
v6.2 | 🧩 Synthesize & Prune |
Future Tracks
v7.x: Affect-Tagged Memory — Recall prioritization improves by weighting memories with affective/contextual valence.
v8+: Zero-Search Retrieval — Direct vector-addressed recall reduces retrieval indirection.
❓ Troubleshooting FAQ
Q: Why is the dashboard project selector stuck on "Loading projects..."?
A: Fixed in v7.3.3. The root cause was a multi-layer quote-escaping trap in the abortPipeline onclick handler that generated a SyntaxError in the browser, silently killing the entire dashboard IIFE. Update to v7.3.3+ (npx -y prism-mcp-server). If still stuck, check that Supabase env values are properly set (unresolved placeholders like ${SUPABASE_URL} cause /api/projects to return empty). Prism auto-falls back to local SQLite when Supabase is misconfigured.
Q: Why is semantic search quality weak or inconsistent? A: Check embedding provider configuration and key availability. Missing embedding credentials reduce semantic recall quality and can shift behavior toward keyword-heavy matches.
Q: How do I delete a bad memory entry?
A: Use session_forget_memory for targeted soft/hard deletion. For manual cleanup and merge workflows, use the dashboard graph editor.
Q: How do I verify the install quickly?
A: Run npm run build && npm test, then open the Mind Palace dashboard (localhost:3000) and confirm projects load plus Graph Health renders.
💡 Known Limitations & Quirks
LLM-dependent features require an API key. Semantic search, Morning Briefings, auto-compaction, and VLM captioning need a
GOOGLE_API_KEY(your Gemini API key) or equivalent provider key. Without one, Prism falls back to keyword-only search (FTS5).Auto-load is model- and client-dependent. Session auto-loading relies on both the LLM following system prompt instructions and the MCP client completing tool registration before the model's first turn. Prism provides platform-specific Setup Guides and a server-side fallback (v5.2.1) that auto-pushes context after 10 seconds.
MCP client race conditions. Some MCP clients may not finish tool enumeration before the model generates its first response, causing transient
unknown_toolerrors. This is a client-side timing issue — Prism's server completes the MCP handshake in ~60ms. Workaround: the server-side auto-push fallback and the startup skill's retry logic.No real-time sync without Supabase. Local SQLite mode is single-machine only. Multi-device or team sync requires a Supabase backend.
Embedding quality varies by provider. Gemini
text-embedding-004and OpenAItext-embedding-3-smallproduce high-quality 768-dim vectors. Prism passesdimensions: 768via the Matryoshka API for OpenAI models (native output is 1536-dim; this truncation is lossless and outperforms ada-002 at full 1536 dims). Ollama embeddings (e.g.,nomic-embed-text) are usable but may reduce retrieval accuracy.Dashboard is HTTP-only. The Mind Palace dashboard at
localhost:3000does not support HTTPS. For remote access, use a reverse proxy (nginx/Caddy) or SSH tunnel. Basic auth is available viaPRISM_DASHBOARD_USER/PRISM_DASHBOARD_PASS. JWKS JWT auth is available viaPRISM_JWKS_URIfor agent-native authentication (works with Auth0, AgentLair (llms.txt), Keycloak, Cognito, or any standard JWKS endpoint).Long-lived clients can accumulate zombie processes. MCP clients that run for extended periods (e.g., Claude CLI) may leave orphaned Prism server processes. The lifecycle manager detects true orphans (PPID=1) but allows coexistence for active parent processes. Use
PRISM_INSTANCEto isolate instances across clients.Migration is one-way. Universal Import ingests sessions into Prism but does not export back to Claude/Gemini/OpenAI formats. Use
session_export_memoryfor portable JSON/Markdown export, or thevaultformat for Obsidian/Logseq-compatible.ziparchives.Export ceiling at 10,000 ledger entries. The
session_export_memorytool and the dashboard export button cap vault/JSON exports at 10,000 entries per project as an OOM guard. Projects exceeding this limit should use per-project exports and time-based filtering to stay within the ceiling. This limit does not affect search or context loading.No Windows CI testing. Prism is developed and tested on macOS/Linux. It should work on Windows via Node.js, but edge cases (file paths, PID locks) may surface.
License
MIT
Keywords: MCP server, Model Context Protocol, Claude Desktop memory, persistent session memory, AI agent memory, cognitive architecture, ACT-R spreading activation, Hebbian learning, episodic semantic consolidation, multi-hop reasoning, uncertainty rejection gate, local-first, SQLite MCP, Mind Palace, time travel, visual memory, VLM image captioning, OpenTelemetry, GDPR, agent telepathy, multi-agent sync, behavioral memory, cursorrules, Ollama MCP, Brave Search MCP, TurboQuant, progressive context loading, knowledge management, LangChain retriever, LangGraph agent
Latest Blog Posts
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/dcostenco/BCBA'
If you have feedback or need assistance with the MCP directory API, please join our Discord server