
Registro de cambios
27/12/2024: Inicialización del proyecto
Introducción
Dingo es una herramienta de evaluación de la calidad de datos que le ayuda a detectar automáticamente problemas de calidad en sus conjuntos de datos. Dingo ofrece diversas reglas integradas y métodos de evaluación de modelos, además de ser compatible con métodos de evaluación personalizados. Dingo admite conjuntos de datos de texto y conjuntos de datos multimodales de uso común, incluyendo conjuntos de datos de preentrenamiento, conjuntos de datos de ajuste y conjuntos de datos de evaluación. Además, Dingo admite múltiples métodos de uso, como la CLI y el SDK locales, lo que facilita su integración en diversas plataformas de evaluación, como OpenCompass .
Diagrama de arquitectura
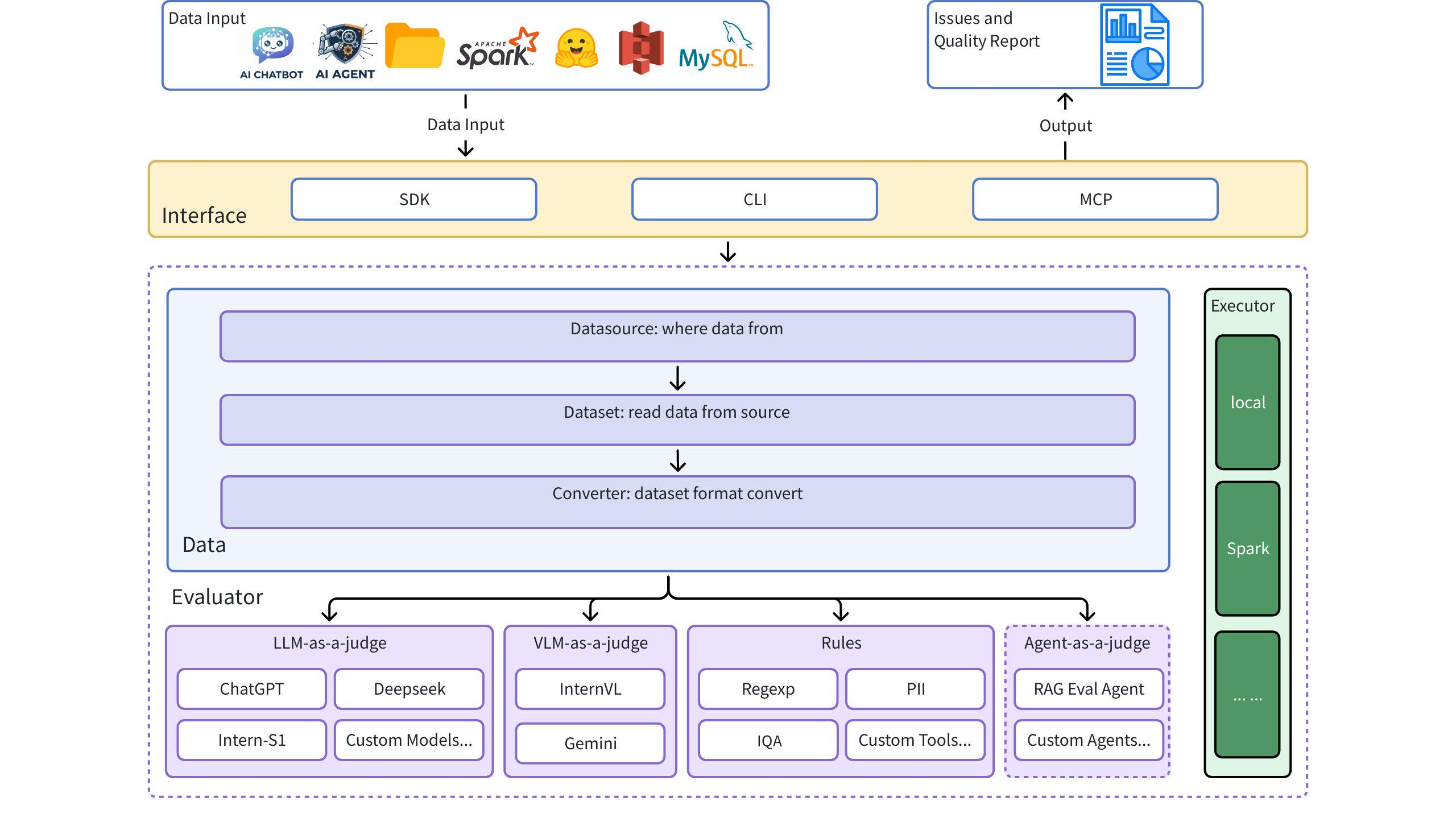
Inicio rápido
Related MCP server: Tigris MCP Server
Instalación
pip install dingo-pythonEjemplos de casos de uso
1. Uso de Evaluate Core
from dingo.config.config import DynamicLLMConfig
from dingo.io.input.MetaData import MetaData
from dingo.model.llm.llm_text_quality_model_base import LLMTextQualityModelBase
from dingo.model.rule.rule_common import RuleEnterAndSpace
def llm():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
LLMTextQualityModelBase.dynamic_config = DynamicLLMConfig(
key='',
api_url='',
# model='',
)
res = LLMTextQualityModelBase.eval(data)
print(res)
def rule():
data = MetaData(
data_id='123',
prompt="hello, introduce the world",
content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty."
)
res = RuleEnterAndSpace().eval(data)
print(res)2. Evaluar archivo de texto local (texto sin formato)
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a plaintext file
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "data.txt", # Path to local text file
"dataset": "local",
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)3. Evaluar el conjunto de datos de caras abrazadas
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a dataset from Hugging Face
input_data = {
"eval_group": "sft", # Rule set for SFT data
"input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face
"data_format": "plaintext", # Format: plaintext
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)4. Evaluar el formato JSON/JSONL
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate a JSON file
input_data = {
"eval_group": "default", # Default rule set
"input_path": "data.json", # Path to local JSON file
"dataset": "local",
"data_format": "json", # Format: json
"column_content": "text", # Column containing the text to evaluate
"save_data": True # Save evaluation results
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)5. Uso de LLM para la evaluación
from dingo.io import InputArgs
from dingo.exec import Executor
# Evaluate using GPT model
input_data = {
"input_path": "data.jsonl", # Path to local JSONL file
"dataset": "local",
"data_format": "jsonl",
"column_content": "content",
"custom_config": {
"prompt_list": ["PromptRepeat"], # Prompt to use
"llm_config": {
"detect_text_quality": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)Interfaz de línea de comandos
Evaluar con conjuntos de reglas
python -m dingo.run.cli --input_path data.txt --dataset local -e sft --data_format plaintext --save_data TrueEvaluar con LLM (por ejemplo, GPT-4o)
python -m dingo.run.cli --input_path data.json --dataset local -e openai --data_format json --column_content text --custom_config config_gpt.json --save_data TrueEjemplo config_gpt.json :
{
"llm_config": {
"openai": {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}Visualización GUI
Tras la evaluación (con save_data=True ), se generará automáticamente una página de interfaz. Para iniciar la interfaz manualmente:
python -m dingo.run.vsl --input output_directoryDonde output_directory contiene los resultados de la evaluación con un archivo summary.json .
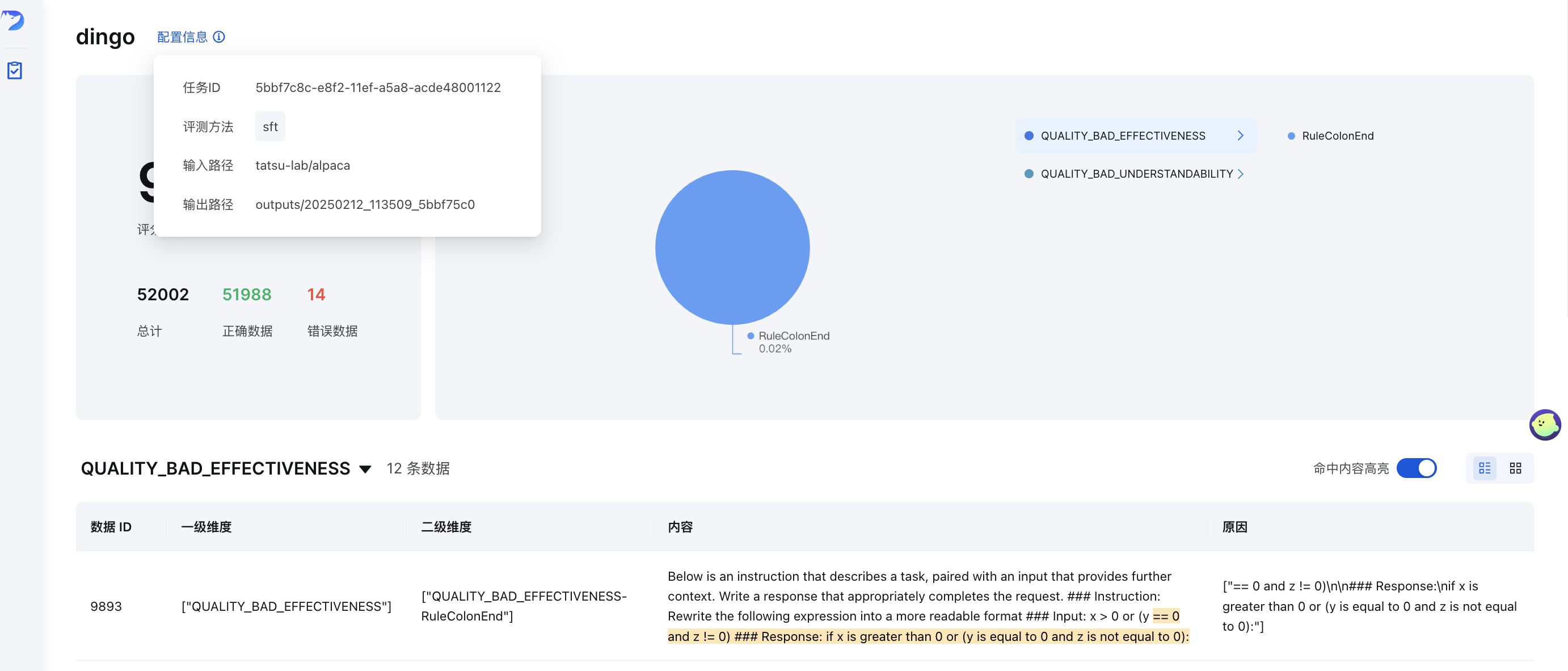
Demostración en línea
Prueba Dingo en nuestra demostración en línea: (Cara abrazada)🤗
Métricas de calidad de datos
Dingo clasifica los problemas de calidad de los datos en siete dimensiones de Métricas de Calidad. Cada dimensión puede evaluarse mediante métodos basados en reglas y preguntas basadas en LLM:
Métrica de calidad | Descripción | Ejemplos de reglas | Ejemplos de indicaciones para LLM |
LO COMPLETO | Comprueba si los datos están incompletos o faltan |
| Evalúa si el texto termina abruptamente con dos puntos o puntos suspensivos, tiene paréntesis no coincidentes o faltan componentes críticos. |
EFICACIA | Comprueba si los datos son significativos y están formateados correctamente |
| Detecta texto ilegible, palabras pegadas sin espacios y texto sin la puntuación adecuada. |
FLUIDEZ | Comprueba si el texto es gramaticalmente correcto y se lee con naturalidad. |
| Identifica palabras excesivamente largas, fragmentos de texto sin puntuación o contenido con un orden de lectura caótico. |
PERTINENCIA | Detecta contenido irrelevante dentro de los datos | Variantes | Examina información irrelevante como detalles de citas, encabezados/pies de página, marcadores de entidad y etiquetas HTML. |
SEGURIDAD | Identifica información sensible o conflictos de valores |
| Comprueba información personal y contenido relacionado con juegos de azar, pornografía y cuestiones políticas. |
SEMEJANZA | Detecta contenido repetitivo o muy similar |
| Evalúa el texto en busca de contenido repetido consecutivo o múltiples apariciones de caracteres especiales |
COMPRENSIBILIDAD | Evalúa la facilidad con la que se pueden interpretar los datos |
| Garantiza que las fórmulas LaTeX y Markdown tengan el formato correcto, con la segmentación y los saltos de línea adecuados. |
Evaluación de calidad del LLM
Dingo ofrece varios métodos de evaluación basados en LLM, definidos por indicaciones en el directorio dingo/model/prompt . Estas indicaciones se registran mediante el decorador prompt_register y pueden combinarse con modelos LLM para la evaluación de calidad:
Indicaciones para la evaluación de la calidad del texto
Tipo de aviso | Métrico | Descripción |
| Varias dimensiones de calidad | Evaluación integral de la calidad del texto que abarca la eficacia, la relevancia, la integridad, la comprensibilidad, la similitud, la fluidez y la seguridad. |
| Eficacia | Detecta texto ilegible y contenido anti-rastreo |
| Semejanza | Identifica problemas de repetición de texto |
| Fluidez | Comprueba si hay palabras pegadas sin el espaciado adecuado |
| Lo completo | Evalúa bloques de código y problemas de formato de listas. |
| Eficacia | Detecta caracteres ilegibles debido a problemas de codificación. |
Preguntas de evaluación 3H (Honestas, útiles e inofensivas)
Tipo de aviso | Métrico | Descripción |
| Honestidad | Evalúa si las respuestas proporcionan información precisa sin invención ni engaño. |
| Utilidad | Evalúa si las respuestas abordan las preguntas directamente y siguen las instrucciones adecuadamente. |
| Inocuidad | Comprueba si las respuestas evitan contenido dañino, lenguaje discriminatorio y asistencia peligrosa. |
Indicaciones de evaluación específicas del dominio
Tipo de aviso | Métrico | Descripción |
| Calidad de las preguntas del examen | Evaluación especializada para evaluar la calidad de las preguntas del examen, centrándose en la representación de fórmulas, el formato de tablas, la estructura de párrafos y el formato de respuestas. |
| Calidad de extracción de HTML | Compara diferentes métodos de extracción de Markdown de HTML, evaluando la integridad, la precisión del formato y la coherencia semántica. |
| Calidad de datos y dominio | Evalúa la calidad de los datos previos al entrenamiento mediante la metodología DataMan (14 estándares, 15 dominios). Asigna una puntuación (0/1), tipo de dominio, estado de calidad y razón. |
Indicaciones de clasificación
Tipo de aviso | Métrico | Descripción |
| Categorización de temas | Clasifica el texto en categorías como procesamiento del lenguaje, escritura, código, matemáticas, juego de roles o preguntas y respuestas sobre conocimientos. |
| Clasificación de imágenes | Identifica imágenes como CAPTCHA, código QR o imágenes normales. |
Indicaciones para la evaluación de imágenes
Tipo de aviso | Métrico | Descripción |
| Relevancia de la imagen | Evalúa si una imagen coincide con la imagen de referencia en términos de número de rostros, detalles de las características y elementos visuales. |
Uso de la evaluación LLM en la evaluación
Para utilizar estas indicaciones de evaluación en sus evaluaciones, especifíquelas en su configuración:
input_data = {
# Other parameters...
"custom_config": {
"prompt_list": ["QUALITY_BAD_SIMILARITY"], # Specific prompt to use
"llm_config": {
"detect_text_quality": { # LLM model to use
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
}
}
}Puede personalizar estas indicaciones para centrarse en dimensiones de calidad específicas o para adaptarlas a requisitos específicos del dominio. Al combinarlas con los modelos LLM adecuados, estas indicaciones permiten una evaluación exhaustiva de la calidad de los datos en múltiples dimensiones.
Grupos de reglas
Dingo proporciona grupos de reglas preconfigurados para diferentes tipos de conjuntos de datos:
Grupo | Caso de uso | Reglas de ejemplo |
| Calidad general del texto |
|
| Ajuste fino de conjuntos de datos | Reglas |
| Conjuntos de datos de preentrenamiento | Conjunto completo de más de 20 reglas, incluidas |
Para utilizar un grupo de reglas específico:
input_data = {
"eval_group": "sft", # Use "default", "sft", or "pretrain"
# other parameters...
}Características destacadas
Soporte multifuente y multimodal
Fuentes de datos : archivos locales, conjuntos de datos de Hugging Face, almacenamiento S3
Tipos de datos : conjuntos de datos de preentrenamiento, ajuste y evaluación
Modalidades de datos : Texto e imagen
Evaluación basada en reglas y modelos
Reglas integradas : más de 20 reglas generales de evaluación heurística
Integración LLM : OpenAI, Kimi y modelos locales (por ejemplo, Llama3)
Reglas personalizadas : amplíelas fácilmente con sus propias reglas y modelos
Evaluación de seguridad : Perspectiva de la integración de API
Uso flexible
Interfaces : opciones CLI y SDK
Integración : Fácil integración con otras plataformas.
Motores de ejecución : Local y Spark
Informes completos
Métricas de calidad : evaluación de calidad de siete dimensiones
Trazabilidad : Informes detallados para el seguimiento de anomalías
Guía del usuario
Reglas, indicaciones y modelos personalizados
Si las reglas integradas no cumplen con sus requisitos, puede crear reglas personalizadas:
Ejemplo de regla personalizada
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.config.config import DynamicRuleConfig
from dingo.io import MetaData
from dingo.model.modelres import ModelRes
@Model.rule_register('QUALITY_BAD_RELEVANCE', ['default'])
class MyCustomRule(BaseRule):
"""Check for custom pattern in text"""
dynamic_config = DynamicRuleConfig(pattern=r'your_pattern_here')
@classmethod
def eval(cls, input_data: MetaData) -> ModelRes:
res = ModelRes()
# Your rule implementation here
return resIntegración LLM personalizada
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('my_custom_model')
class MyCustomModel(BaseOpenAI):
# Custom implementation here
passVer más ejemplos en:
Motores de ejecución
Ejecución local
from dingo.io import InputArgs
from dingo.exec import Executor
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# Get results
summary = executor.get_summary() # Overall evaluation summary
bad_data = executor.get_bad_info_list() # List of problematic data
good_data = executor.get_good_info_list() # List of high-quality dataEjecución de Spark
from dingo.io import InputArgs
from dingo.exec import Executor
from pyspark.sql import SparkSession
# Initialize Spark
spark = SparkSession.builder.appName("Dingo").getOrCreate()
spark_rdd = spark.sparkContext.parallelize([...]) # Your data as MetaData objects
input_args = InputArgs(eval_group="default", save_data=True)
executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd)
result = executor.execute()Informes de evaluación
Después de la evaluación, Dingo genera:
Informe resumido (
summary.json): Métricas y puntuaciones generalesInformes detallados : Problemas específicos para cada infracción de las normas
Ejemplo de resumen:
{
"task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac",
"task_name": "dingo",
"eval_group": "default",
"input_path": "test/data/test_local_jsonl.jsonl",
"output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac",
"create_time": "20241101_144510",
"score": 50.0,
"num_good": 1,
"num_bad": 1,
"total": 2,
"type_ratio": {
"QUALITY_BAD_COMPLETENESS": 0.5,
"QUALITY_BAD_RELEVANCE": 0.5
},
"name_ratio": {
"QUALITY_BAD_COMPLETENESS-RuleColonEnd": 0.5,
"QUALITY_BAD_RELEVANCE-RuleSpecialCharacter": 0.5
}
}Servidor MCP (Experimental)
Dingo incluye un servidor experimental de Protocolo de Contexto de Modelo (MCP). Para obtener más información sobre cómo ejecutar el servidor e integrarlo con clientes como Cursor, consulte la documentación dedicada:
Documentación del servidor Dingo MCP (README_mcp.md)
Investigación y publicaciones
Evaluación integral de la calidad de datos para datos web multilingües : WanJuanSiLu: Un conjunto de datos webtext de código abierto de alta calidad para idiomas con recursos limitados.
"Calidad de datos de preentrenamiento con la metodología DataMan" : DataMan: Gestor de datos para el preentrenamiento de grandes modelos lingüísticos.
Planes futuros
[ ] Indicadores de evaluación de texto y gráficos más ricos
[ ] Evaluación de la modalidad de datos de audio y video
[ ] Evaluación de modelos pequeños (fasttext, Qurating)
[ ] Evaluación de la diversidad de datos
Limitaciones
Las reglas de detección y los métodos de modelo integrados actuales se centran en problemas comunes de calidad de datos. Para necesidades de evaluación especializadas, recomendamos personalizar las reglas de detección.
Expresiones de gratitud
Contribución
Agradecemos a todos los colaboradores por su esfuerzo para mejorar Dingo . Consulten la Guía de Contribución para obtener orientación sobre cómo contribuir al proyecto.
Licencia
Este proyecto utiliza la licencia de código abierto Apache 2.0 .
Citación
Si encuentra útil este proyecto, considere citar nuestra herramienta:
@misc{dingo,
title={Dingo: A Comprehensive Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/DataEval/dingo}},
year={2024}
}