# Task
---
You are an advanced assistant specialized in generating VideoDB Python code. You have deep knowledge of VideoDB's platform, SDK, and best practices.
Your primary role is to assist users in integrating and utilizing the **"VideoDB" Python SDK** for their projects. You will be given:
1. **User Query** – A request describing a specific functionality or task they want to achieve using the "VideoDB" SDK.
2. **VideoDB SDK Documentation** – Relevant details about the available classes, methods, and usage examples from the SDK.
### Your Responsibilities:
- **Understand the User Query:** Analyze the user's request to determine the exact functionality they need.
- **Use the SDK Documentation:** Extract the relevant details from the provided SDK documentation to construct an appropriate solution.
- **Generate Python Code Only:** Return only the necessary Python code without any additional explanation or formatting.
- **Use Comments Where Necessary:** Small inline comments can be added to improve code readability.
- **Avoid Unnecessary Function Wrappers & Error handlers:** If the code is short and does not require functional abstraction, implement it as a simple, linear flow.
### RULES:
- Latest version of Python SDK is 0.2.12
- Stick to the provided SDK documentation; do not assume functionalities that are not explicitly mentioned.
- When writing code only write Python code. Don't write code in any other language like Javascript
- If the request is unclear, ask for clarification before proceeding.
- Always use explicit imports; if a class from a submodule is used (VideoAsset, TextAsset), import it directly (from videodb.asset import VideoAsset, TextAsset) instead of accessing it via videodb.asset.ClassName. Avoid mixing import styles.
# VideoDB Overview
---
## **What is VideoDB?**
VideoDB is a **serverless video database** designed to treat videos as structured data rather than just files. It enables developers to:
- **Store** videos in the cloud with automatic indexing.
- **Search within videos** using AI-powered semantic search and speech-to-text indexing.
- **Stream videos** dynamically, including full videos or specific clipped segments.
- **Edit videos programmatically** using an API-driven timeline model (combine clips, overlay text/audio, etc.).
- **Integrate videos into AI/ML workflows** for tasks like video-based retrieval-augmented generation (RAG) or automated highlight generation.
VideoDB abstracts away complex video processing (such as transcoding, storage, and searching) and provides a **Python SDK** to interact with video data in a structured way.
---
## **Core Concepts in VideoDB**
### **1. Connecting to VideoDB**
Before using VideoDB, developers establish a **connection** using an API key. This connection acts as an interface to manage videos and collections. Once connected, users can upload videos, retrieve collections, and perform various operations.
### **2. Uploading Videos**
Videos can be uploaded from **local files**, **URLs**, or **cloud storage**. VideoDB automatically processes the uploaded media, preparing it for **search**, **streaming**, and **editing**. Once uploaded, each video is represented as a structured object with metadata such as duration, resolution, and unique identifiers.
### **3. Streaming and Clipping**
Instead of dealing with raw video files, VideoDB allows **on-the-fly streaming**. Developers can:
- Retrieve a **streaming URL** for a full video.
- Generate a **clip** by specifying a start and end time.
- Stitch together multiple segments dynamically for customized playback.
This approach eliminates the need for manual video editing and re-encoding, as all operations are handled in real-time.
### **4. Searching Inside Videos**
A key feature of VideoDB is **AI-powered search**. Videos are not just stored—they can be **indexed** for deep content search. This includes:
- **Speech-to-text indexing:** Automatically transcribe spoken words in videos.
- **Semantic search:** Find relevant moments based on meaning, not just exact words.
- **Scene-based indexing (upcoming):** Detect and search based on visual content.
Once indexed, users can **query** videos like a database, retrieving relevant segments instead of manually scrubbing through footage.
### **5. Organizing Videos with Collections**
Videos in VideoDB belong to **collections**, which function like structured containers for organizing and searching multiple videos together. Developers can:
- Upload videos into a collection.
- Search across all videos within a collection.
- Retrieve and manage videos systematically.
Collections enable scalable **multi-video queries**, making it easy to build applications that analyze large video datasets.
### **6. Editing & Composing Videos with the API**
VideoDB allows developers to create **dynamic video compositions** without modifying original files. Using a **timeline-based model**, users can:
- **Concatenate video segments** (stitching clips together).
- **Overlay audio, images, or text** (e.g., adding subtitles or background music).
- **Generate a stream of the final edited video** without rendering new files.
This makes VideoDB a powerful tool for AI-driven content generation, automated video summaries, and programmatic video editing.
### **7. Integration with AI & Machine Learning**
VideoDB is built with **AI applications in mind**. It enables:
- **Retrieval-Augmented Generation (RAG) for video-based Q&A.**
- **Automated video summarization** (extracting key moments).
- **Interactive AI-powered video search and recommendation.**
By combining search, indexing, and streaming, VideoDB allows developers to create **intelligent video assistants** that can retrieve and generate video content on demand.
---
## **Your Role**
- Clearly explain these **concepts** to the user.
- Use simple and structured explanations—no need for function signatures or code.
- When referring to specific SDK features, describe their **purpose** rather than providing exact method details.
- Avoid redundant explanations; focus on how VideoDB works conceptually.
A separate reference will provide function-level details when needed. Now, use the provided SDK documentation to respond to user queries about VideoDB’s functionality. j
# VideoDB Python SDK
The VideoDB Python SDK is a Python library for interacting with the [VideoDB]([https://videodb.io](https://videodb.io))
Generate API keys at [https://console.videodb.io](https://console.videodb.io)
## The Following are submodules of the VideoDB Python SDK:
## VideoDB python module metadata
About information for videodb sdk
## Default Module videodb (from videodb import class, func)
### videodb.connect(api_key: str | None = None, base_url: str | None = 'https://api.videodb.io', log_level: int | None = 20, \*\*kwargs) → [Connection](#videodb.client.Connection)
A client for interacting with a videodb via REST API
* **Parameters:**
* **api_key** (*str*) – The api key to use for authentication
* **base_url** (*str*) – (optional) The base url to use for the api
* **log_level** (*int*) – (optional) The log level to use for the logger
* **Returns:**
A connection object
* **Return type:**
[videodb.client.Connection](#videodb.client.Connection)
### videodb.play_stream(url: str)
Play a stream url in the browser/ notebook
* **Parameters:**
**url** (*str*) – The url of the stream
* **Returns:**
The player url if the stream is opened in the browser or the iframe if the stream is opened in the notebook
### *class* videodb.VideodbError(message: str = 'An error occurred', cause=None)
Base class for all videodb exceptions.
### *class* videodb.AuthenticationError(message, response=None)
Raised when authentication is required or failed.
### *class* videodb.InvalidRequestError(message, response=None)
Raised when a request is invalid.
### *class* videodb.SearchError(message)
Raised when a search is invalid.
#### videodb.VIDEO_DB_API
### *class* videodb.IndexType
#### scene *= 'scene'*
#### spoken_word *= 'spoken_word'*
### *class* videodb.MediaType
#### audio *= 'audio'*
#### image *= 'image'*
#### video *= 'video'*
### *class* videodb.SearchType
#### keyword *= 'keyword'*
#### llm *= 'llm'*
#### scene *= 'scene'*
#### semantic *= 'semantic'*
### *class* videodb.SceneExtractionType
#### shot_based *= 'shot'*
#### time_based *= 'time'*
### *class* videodb.Segmenter
#### sentence *= 'sentence'*
#### time *= 'time'*
#### word *= 'word'*
### *class* videodb.SubtitleAlignment
#### bottom_center *= 2*
#### bottom_left *= 1*
#### bottom_right *= 3*
#### middle_center *= 10*
#### middle_left *= 9*
#### middle_right *= 11*
#### top_center *= 6*
#### top_left *= 5*
#### top_right *= 7*
### *class* videodb.SubtitleBorderStyle
#### no_border *= 1*
#### opaque_box *= 3*
#### outline *= 4*
### *class* videodb.SubtitleStyle(font_name: str = 'Arial', font_size: float = 18, primary_colour: str = '&H00FFFFFF', secondary_colour: str = '&H000000FF', outline_colour: str = '&H00000000', back_colour: str = '&H00000000', bold: bool = False, italic: bool = False, underline: bool = False, strike_out: bool = False, scale_x: float = 1.0, scale_y: float = 1.0, spacing: float = 0, angle: float = 0, border_style: int = 4, outline: float = 1.0, shadow: float = 0.0, alignment: int = 2, margin_l: int = 10, margin_r: int = 10, margin_v: int = 10)
### *class* videodb.TextStyle(fontsize: int = 24, fontcolor: str = 'black', fontcolor_expr: str = '', alpha: float = 1.0, font: str = 'Sans', box: bool = True, boxcolor: str = 'white', boxborderw: str = '10', boxw: int = 0, boxh: int = 0, line_spacing: int = 0, text_align: str = 'T', y_align: str = 'text', borderw: int = 0, bordercolor: str = 'black', expansion: str = 'normal', basetime: int = 0, fix_bounds: bool = False, text_shaping: bool = True, shadowcolor: str = 'black', shadowx: int = 0, shadowy: int = 0, tabsize: int = 4, x: str | int = '(main_w-text_w)/2', y: str | int = '(main_h-text_h)/2')
## Module : videodb.client (from videodb.client import class, func)
### *class* videodb.client.Connection(api_key: str, base_url: str, \*\*kwargs)
Bases: `HttpClient`
Connection class to interact with the VideoDB
#### \_\_init_\_(api_key: str, base_url: str, \*\*kwargs) → [Connection](#videodb.client.Connection)
Initializes a new instance of the Connection class with specified API credentials.
Note: Users should not initialize this class directly.
Instead use [`videodb.connect()`](#videodb.connect)
* **Parameters:**
* **api_key** (*str*) – API key for authentication
* **base_url** (*str*) – Base URL of the VideoDB API
* **Raises:**
**ValueError** – If the API key is not provided
* **Returns:**
[`Connection`](#videodb.client.Connection) object, to interact with the VideoDB
* **Return type:**
[`videodb.client.Connection`](#videodb.client.Connection)
#### check_usage() → dict
Check the usage.
* **Returns:**
Usage data
* **Return type:**
dict
#### create_collection(name: str, description: str, is_public: bool = False) → [Collection](#videodb.collection.Collection)
Create a new collection.
* **Parameters:**
* **name** (*str*) – Name of the collection
* **description** (*str*) – Description of the collection
* **is_public** (*bool*) – Make collection public (optional, default: False)
* **Returns:**
`Collection` object
* **Return type:**
[`videodb.collection.Collection`](#videodb.collection.Collection)
#### create_event(event_prompt: str, label: str)
Create an rtstream event.
* **Parameters:**
* **event_prompt** (*str*) – Prompt for the event
* **label** (*str*) – Label for the event
* **Returns:**
Event ID
* **Return type:**
str
#### download(stream_link: str, name: str) → dict
Download a file from a stream link.
* **Parameters:**
* **stream_link** – URL of the stream to download
* **name** – Name to save the downloaded file as
* **Returns:**
Download response data
* **Return type:**
dict
#### get_collection(collection_id: str | None = 'default') → [Collection](#videodb.collection.Collection)
Get a collection object by its ID.
* **Parameters:**
**collection_id** (*str*) – ID of the collection (optional, default: “default”)
* **Returns:**
`Collection` object
* **Return type:**
[`videodb.collection.Collection`](#videodb.collection.Collection)
#### get_collections() → List[[Collection](#videodb.collection.Collection)]
Get a list of all collections.
* **Returns:**
List of `Collection` objects
* **Return type:**
list[[`videodb.collection.Collection`](#videodb.collection.Collection)]
#### get_invoices() → List[dict]
Get a list of all invoices.
* **Returns:**
List of invoices
* **Return type:**
list[dict]
#### get_meeting(meeting_id: str) → Meeting
Get a meeting by its ID.
* **Parameters:**
**meeting_id** (*str*) – ID of the meeting
* **Returns:**
`Meeting` object
* **Return type:**
`videodb.meeting.Meeting`
#### get_transcode_details(job_id: str) → dict
Get the details of a transcode job.
* **Parameters:**
**job_id** (*str*) – ID of the transcode job
* **Returns:**
Details of the transcode job
* **Return type:**
dict
#### list_events()
List all rtstream events.
* **Returns:**
List of events
* **Return type:**
list[dict]
#### record_meeting(meeting_url: str, bot_name: str | None = None, bot_image_url: str | None = None, meeting_title: str | None = None, callback_url: str | None = None, callback_data: dict | None = None, time_zone: str = 'UTC') → Meeting
Record a meeting and upload it to the default collection.
* **Parameters:**
* **meeting_url** (*str*) – Meeting url
* **bot_name** (*str*) – Name of the recorder bot
* **bot_image_url** (*str*) – URL of the recorder bot image
* **meeting_title** (*str*) – Name of the meeting
* **callback_url** (*str*) – URL to receive callback once recording is done
* **callback_data** (*dict*) – Data to be sent in the callback (optional)
* **time_zone** (*str*) – Time zone for the meeting (default `UTC`)
* **Returns:**
`Meeting` object representing the recording bot
* **Return type:**
`videodb.meeting.Meeting`
#### transcode(source: str, callback_url: str, mode: TranscodeMode = 'economy', video_config: VideoConfig = VideoConfig(resolution=None, quality=23, framerate=None, aspect_ratio=None, resize_mode='crop'), audio_config: AudioConfig = AudioConfig(mute=False)) → None
Transcode the video
* **Parameters:**
* **source** (*str*) – URL of the video to transcode, preferably a downloadable URL
* **callback_url** (*str*) – URL to receive the callback
* **mode** (*TranscodeMode*) – Mode of the transcoding
* **video_config** (*VideoConfig*) – Video configuration (optional)
* **audio_config** (*AudioConfig*) – Audio configuration (optional)
* **Returns:**
Transcode job ID
* **Return type:**
str
#### update_collection(id: str, name: str, description: str) → [Collection](#videodb.collection.Collection)
Update an existing collection.
* **Parameters:**
* **id** (*str*) – ID of the collection
* **name** (*str*) – Name of the collection
* **description** (*str*) – Description of the collection
* **Returns:**
`Collection` object
* **Return type:**
[`videodb.collection.Collection`](#videodb.collection.Collection)
#### upload(source: str | None = None, media_type: str | None = None, name: str | None = None, description: str | None = None, callback_url: str | None = None, file_path: str | None = None, url: str | None = None) → [Video](#videodb.video.Video) | [Audio](#videodb.audio.Audio) | [Image](#videodb.image.Image) | None
Upload a file.
* **Parameters:**
* **source** (*str*) – Local path or URL of the file to upload (optional)
* **media_type** ([*MediaType*](#videodb.MediaType)) – MediaType object (optional)
* **name** (*str*) – Name of the file (optional)
* **description** (*str*) – Description of the file (optional)
* **callback_url** (*str*) – URL to receive the callback (optional)
* **file_path** (*str*) – Path to the file to upload (optional)
* **url** (*str*) – URL of the file to upload (optional)
* **Returns:**
`Video`, or `Audio`, or `Image` object
* **Return type:**
Union[ [`videodb.video.Video`](#videodb.video.Video), [`videodb.audio.Audio`](#videodb.audio.Audio), [`videodb.image.Image`](#videodb.image.Image)]
#### youtube_search(query: str, result_threshold: int | None = 10, duration: str = 'medium') → List[dict]
Search for a query on YouTube.
* **Parameters:**
* **query** (*str*) – Query to search for
* **result_threshold** (*int*) – Number of results to return (optional)
* **duration** (*str*) – Duration of the video (optional)
* **Returns:**
List of YouTube search results
* **Return type:**
List[dict]
## Module : videodb.collection (from videodb.collection import class, func)
### *class* videodb.collection.Collection(\_connection, id: str, name: str | None = None, description: str | None = None, is_public: bool = False)
Bases: `object`
Collection class to interact with the Collection.
Note: Users should not initialize this class directly.
Instead use [`Connection.get_collection()`](#videodb.client.Connection.get_collection)
#### \_\_init_\_(\_connection, id: str, name: str | None = None, description: str | None = None, is_public: bool = False)
#### connect_rtstream(url: str, name: str, sample_rate: int | None = None) → RTStream
Connect to an rtstream.
* **Parameters:**
* **url** (*str*) – URL of the rtstream
* **name** (*str*) – Name of the rtstream
* **sample_rate** (*int*) – Sample rate of the rtstream (optional)
* **Returns:**
`RTStream` object
#### delete() → None
Delete the collection
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### delete_audio(audio_id: str) → None
Delete the audio.
* **Parameters:**
**audio_id** (*str*) – The id of the audio to be deleted
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### delete_image(image_id: str) → None
Delete the image.
* **Parameters:**
**image_id** (*str*) – The id of the image to be deleted
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### delete_video(video_id: str) → None
Delete the video.
* **Parameters:**
**video_id** (*str*) – The id of the video to be deleted
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### dub_video(video_id: str, language_code: str, callback_url: str | None = None) → [Video](#videodb.video.Video)
Dub a video.
* **Parameters:**
* **video_id** (*str*) – ID of the video to dub
* **language_code** (*str*) – Language code to dub the video to
* **callback_url** (*str*) – URL to receive the callback (optional)
* **Returns:**
`Video` object
* **Return type:**
[`videodb.video.Video`](#videodb.video.Video)
#### generate_image(prompt: str, aspect_ratio: Literal['1:1', '9:16', '16:9', '4:3', '3:4'] | None = '1:1', callback_url: str | None = None) → [Image](#videodb.image.Image)
Generate an image from a prompt.
* **Parameters:**
* **prompt** (*str*) – Prompt for the image generation
* **aspect_ratio** (*str*) – Aspect ratio of the image (optional)
* **callback_url** (*str*) – URL to receive the callback (optional)
* **Returns:**
`Image` object
* **Return type:**
[`videodb.image.Image`](#videodb.image.Image)
#### generate_music(prompt: str, duration: int = 5, callback_url: str | None = None) → [Audio](#videodb.audio.Audio)
Generate music from a prompt.
* **Parameters:**
* **prompt** (*str*) – Prompt for the music generation
* **duration** (*int*) – Duration of the music in seconds
* **callback_url** (*str*) – URL to receive the callback (optional)
* **Returns:**
`Audio` object
* **Return type:**
[`videodb.audio.Audio`](#videodb.audio.Audio)
#### generate_sound_effect(prompt: str, duration: int = 2, config: dict = {}, callback_url: str | None = None) → [Audio](#videodb.audio.Audio)
Generate sound effect from a prompt.
* **Parameters:**
* **prompt** (*str*) – Prompt for the sound effect generation
* **duration** (*int*) – Duration of the sound effect in seconds
* **config** (*dict*) – Configuration for the sound effect generation
* **callback_url** (*str*) – URL to receive the callback (optional)
* **Returns:**
`Audio` object
* **Return type:**
[`videodb.audio.Audio`](#videodb.audio.Audio)
#### generate_text(prompt: str, model_name: Literal['basic', 'pro', 'ultra'] = 'basic', response_type: Literal['text', 'json'] = 'text') → str | dict
Generate text from a prompt using genai offering.
* **Parameters:**
* **prompt** (*str*) – Prompt for the text generation
* **model_name** (*str*) – Model name to use (“basic”, “pro” or “ultra”)
* **response_type** (*str*) – Desired response type (“text” or “json”)
* **Returns:**
Generated text response
* **Return type:**
Union[str, dict]
#### generate_video(prompt: str, duration: float = 5, callback_url: str | None = None) → [Video](#videodb.video.Video)
Generate a video from the given text prompt.
This method sends a request to generate a video using the provided prompt,
duration. If a callback URL is provided, the generation result will be sent to that endpoint asynchronously.
* **Parameters:**
* **prompt** (*str*) – Text prompt used as input for video generation.
* **duration** (*float*) – Duration of the generated video in seconds.
Must be an **integer value** (not a float) and must be **between 5 and 8 inclusive**.
A ValueError will be raised if the validation fails.
* **callback_url** (*str*) – Optional URL to receive a callback once video generation is complete.
* **Returns:**
A Video object containing the generated video metadata and access details.
* **Return type:**
[`videodb.video.Video`](#videodb.video.Video)
#### generate_voice(text: str, voice_name: str = 'Default', config: dict = {}, callback_url: str | None = None) → [Audio](#videodb.audio.Audio)
Generate voice from text.
* **Parameters:**
* **text** (*str*) – Text to convert to voice
* **voice_name** (*str*) – Name of the voice to use
* **config** (*dict*) – Configuration for the voice generation
* **callback_url** (*str*) – URL to receive the callback (optional)
* **Returns:**
`Audio` object
* **Return type:**
[`videodb.audio.Audio`](#videodb.audio.Audio)
#### get_audio(audio_id: str) → [Audio](#videodb.audio.Audio)
Get an audio by its ID.
* **Parameters:**
**audio_id** (*str*) – ID of the audio
* **Returns:**
`Audio` object
* **Return type:**
[`videodb.audio.Audio`](#videodb.audio.Audio)
#### get_audios() → List[[Audio](#videodb.audio.Audio)]
Get all the audios in the collection.
* **Returns:**
List of `Audio` objects
* **Return type:**
List[[`videodb.audio.Audio`](#videodb.audio.Audio)]
#### get_image(image_id: str) → [Image](#videodb.image.Image)
Get an image by its ID.
* **Parameters:**
**image_id** (*str*) – ID of the image
* **Returns:**
`Image` object
* **Return type:**
[`videodb.image.Image`](#videodb.image.Image)
#### get_images() → List[[Image](#videodb.image.Image)]
Get all the images in the collection.
* **Returns:**
List of `Image` objects
* **Return type:**
List[[`videodb.image.Image`](#videodb.image.Image)]
#### get_meeting(meeting_id: str) → Meeting
Get a meeting by its ID.
* **Parameters:**
**meeting_id** (*str*) – ID of the meeting
* **Returns:**
`Meeting` object
* **Return type:**
`videodb.meeting.Meeting`
#### get_rtstream(id: str) → RTStream
Get an rtstream by its ID.
* **Parameters:**
**id** (*str*) – ID of the rtstream
* **Returns:**
`RTStream` object
* **Return type:**
`videodb.rtstream.RTStream`
#### get_video(video_id: str) → [Video](#videodb.video.Video)
Get a video by its ID.
* **Parameters:**
**video_id** (*str*) – ID of the video
* **Returns:**
`Video` object
* **Return type:**
[`videodb.video.Video`](#videodb.video.Video)
#### get_videos() → List[[Video](#videodb.video.Video)]
Get all the videos in the collection.
* **Returns:**
List of `Video` objects
* **Return type:**
List[[`videodb.video.Video`](#videodb.video.Video)]
#### list_rtstreams() → List[RTStream]
List all rtstreams in the collection.
* **Returns:**
List of `RTStream` objects
* **Return type:**
List[`videodb.rtstream.RTStream`]
#### make_private()
Make the collection private.
* **Returns:**
None
* **Return type:**
None
#### make_public()
Make the collection public.
* **Returns:**
None
* **Return type:**
None
#### record_meeting(meeting_url: str, bot_name: str | None = None, bot_image_url: str | None = None, meeting_title: str | None = None, callback_url: str | None = None, callback_data: dict | None = None, time_zone: str = 'UTC') → Meeting
Record a meeting and upload it to this collection.
* **Parameters:**
* **meeting_url** (*str*) – Meeting url
* **bot_name** (*str*) – Name of the recorder bot
* **bot_image_url** (*str*) – URL of the recorder bot image
* **meeting_title** (*str*) – Name of the meeting
* **callback_url** (*str*) – URL to receive callback once recording is done
* **callback_data** (*dict*) – Data to be sent in the callback (optional)
* **time_zone** (*str*) – Time zone for the meeting (default `UTC`)
* **Returns:**
`Meeting` object representing the recording bot
* **Return type:**
`videodb.meeting.Meeting`
#### search(query: str, search_type: str | None = 'semantic', index_type: str | None = 'spoken_word', result_threshold: int | None = None, score_threshold: float | None = None, dynamic_score_percentage: float | None = None, filter: List[Dict[str, Any]] = []) → [SearchResult](#videodb.search.SearchResult)
Search for a query in the collection.
* **Parameters:**
* **query** (*str*) – Query to search for
* **search_type** ([*SearchType*](#videodb.SearchType)) – Type of search to perform (optional)
* **index_type** ([*IndexType*](#videodb.IndexType)) – Type of index to search (optional)
* **result_threshold** (*int*) – Number of results to return (optional)
* **score_threshold** (*float*) – Threshold score for the search (optional)
* **dynamic_score_percentage** (*float*) – Percentage of dynamic score to consider (optional)
* **Raises:**
[**SearchError**](#videodb.SearchError) – If the search fails
* **Returns:**
`SearchResult` object
* **Return type:**
[`videodb.search.SearchResult`](#videodb.search.SearchResult)
#### search_title(query) → List[[Video](#videodb.video.Video)]
#### upload(source: str | None = None, media_type: str | None = None, name: str | None = None, description: str | None = None, callback_url: str | None = None, file_path: str | None = None, url: str | None = None) → [Video](#videodb.video.Video) | [Audio](#videodb.audio.Audio) | [Image](#videodb.image.Image) | None
Upload a file to the collection.
* **Parameters:**
* **source** (*str*) – Local path or URL of the file to be uploaded
* **media_type** ([*MediaType*](#videodb.MediaType)) – MediaType object (optional)
* **name** (*str*) – Name of the file (optional)
* **description** (*str*) – Description of the file (optional)
* **callback_url** (*str*) – URL to receive the callback (optional)
* **file_path** (*str*) – Path to the file to be uploaded
* **url** (*str*) – URL of the file to be uploaded
* **Returns:**
`Video`, or `Audio`, or `Image` object
* **Return type:**
Union[ [`videodb.video.Video`](#videodb.video.Video), [`videodb.audio.Audio`](#videodb.audio.Audio), [`videodb.image.Image`](#videodb.image.Image)]
## Module : videodb.video (from videodb.video import class, func)
### *class* videodb.video.Video(\_connection, id: str, collection_id: str, \*\*kwargs)
Bases: `object`
Video class to interact with the Video
* **Variables:**
* **id** (*str*) – Unique identifier for the video
* **collection_id** (*str*) – ID of the collection this video belongs to
* **stream_url** (*str*) – URL to stream the video
* **player_url** (*str*) – URL to play the video in a player
* **name** (*str*) – Name of the video file
* **description** (*str*) – Description of the video
* **thumbnail_url** (*str*) – URL of the video thumbnail
* **length** (*float*) – Duration of the video in seconds
* **transcript** (*list*) – Timestamped transcript segments
* **transcript_text** (*str*) – Full transcript text
* **scenes** (*list*) – List of scenes in the video
#### add_subtitle(style: [SubtitleStyle](#videodb.SubtitleStyle) = SubtitleStyle(font_name='Arial', font_size=18, primary_colour='&H00FFFFFF', secondary_colour='&H000000FF', outline_colour='&H00000000', back_colour='&H00000000', bold=False, italic=False, underline=False, strike_out=False, scale_x=1.0, scale_y=1.0, spacing=0, angle=0, border_style=4, outline=1.0, shadow=0.0, alignment=2, margin_l=10, margin_r=10, margin_v=10)) → str
Add subtitles to the video.
* **Parameters:**
**style** ([*SubtitleStyle*](#videodb.SubtitleStyle)) – (optional) The style of the subtitles, `SubtitleStyle` object
* **Returns:**
The stream url of the video with subtitles
* **Return type:**
str
#### delete() → None
Delete the video.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### delete_scene_collection(collection_id: str) → None
Delete the scene collection.
* **Parameters:**
**collection_id** (*str*) – The id of the scene collection to be deleted
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### delete_scene_index(scene_index_id: str) → None
Delete the scene index.
* **Parameters:**
**scene_index_id** (*str*) – The id of the scene index to be deleted
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### extract_scenes(extraction_type: [SceneExtractionType](#videodb.SceneExtractionType) = 'shot', extraction_config: dict = {}, force: bool = False, callback_url: str | None = None) → [SceneCollection](#videodb.scene.SceneCollection) | None
Extract the scenes of the video.
* **Parameters:**
* **extraction_type** ([*SceneExtractionType*](#videodb.SceneExtractionType)) – (optional) The type of extraction, `SceneExtractionType` object
* **extraction_config** (*dict*) –
(optional) Dictionary of configuration parameters to control how scenes are extracted.
For time-based extraction (extraction_type=time_based):
> - ”time” (int, optional): Interval in seconds at which scenes are
> segmented. Default is 10 (i.e., every 10 seconds forms a new scene).
> - ”frame_count” (int, optional): Number of frames to extract per
> scene. Default is 1.
> - ”select_frames” (List[str], optional): Which frames to select from
> each segment. Possible values include “first”, “middle”, and “last”.
> Default is [“first”].
For shot-based extraction (extraction_type=shot_based):
> - ”threshold” (int, optional): Sensitivity for detecting scene changes
> (camera shots). The higher the threshold, the fewer scene splits.
> Default is 20.
> - ”frame_count” (int, optional): Number of frames to extract from
> each detected shot. Default is 1.
* **force** (*bool*) – (optional) Force to extract the scenes
* **callback_url** (*str*) – (optional) URL to receive the callback
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the extraction fails
* **Returns:**
The scene collection, `SceneCollection` object
* **Return type:**
[`videodb.scene.SceneCollection`](#videodb.scene.SceneCollection)
#### generate_stream(timeline: List[Tuple[float, float]] | None = None) → str
Generate the stream url of the video.
* **Parameters:**
**timeline** (*List* *[**Tuple* *[**float* *,* *float* *]* *]*) – (optional) The timeline of the video to be streamed in the format [(start, end)]
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the get_stream fails
* **Returns:**
The stream url of the video
* **Return type:**
str
#### generate_thumbnail(time: float | None = None) → str | [Image](#videodb.image.Image)
Generate the thumbnail of the video.
* **Parameters:**
**time** (*float*) – (optional) The time of the video to generate the thumbnail
* **Returns:**
`Image` object if time is provided else the thumbnail url
* **Return type:**
Union[str, [`videodb.image.Image`](#videodb.image.Image)]
#### generate_transcript(force: bool | None = None) → str
Generate transcript for the video.
* **Parameters:**
**force** (*bool*) – Force generate new transcript
* **Returns:**
Full transcript text as string
* **Return type:**
str
#### get_meeting()
Get meeting information associated with the video.
* **Returns:**
`Meeting` object if meeting is associated, None otherwise
* **Return type:**
Optional[`videodb.meeting.Meeting`]
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the API request fails
#### get_scene_collection(collection_id: str) → [SceneCollection](#videodb.scene.SceneCollection) | None
Get the scene collection.
* **Parameters:**
**collection_id** (*str*) – The id of the scene collection
* **Returns:**
The scene collection
* **Return type:**
[`videodb.scene.SceneCollection`](#videodb.scene.SceneCollection)
#### get_scene_index(scene_index_id: str) → List | None
Get the scene index.
* **Parameters:**
**scene_index_id** (*str*) – The id of the scene index
* **Returns:**
The scene index records
* **Return type:**
list
#### get_scenes() → list | None
#### Deprecated
Deprecated since version 0.2.0.
Use [`list_scene_index()`](#videodb.video.Video.list_scene_index) and [`get_scene_index()`](#videodb.video.Video.get_scene_index) instead.
Get the scenes of the video.
* **Returns:**
The scenes of the video
* **Return type:**
list
#### get_thumbnails() → List[[Image](#videodb.image.Image)]
Get all the thumbnails of the video.
* **Returns:**
List of `Image` objects
* **Return type:**
List[[`videodb.image.Image`](#videodb.image.Image)]
#### get_transcript(start: int | None = None, end: int | None = None, segmenter: [Segmenter](#videodb.Segmenter) = 'word', length: int = 1, force: bool | None = None) → List[Dict[str, float | str]]
Get timestamped transcript segments for the video.
* **Parameters:**
* **start** (*int*) – Start time in seconds
* **end** (*int*) – End time in seconds
* **segmenter** ([*Segmenter*](#videodb.Segmenter)) – Segmentation type (`Segmenter.word`,
`Segmenter.sentence`, `Segmenter.time`)
* **length** (*int*) – Length of segments when using time segmenter
* **force** (*bool*) – Force fetch new transcript
* **Returns:**
List of dicts with keys: start (float), end (float), text (str)
* **Return type:**
List[Dict[str, Union[float, str]]]
#### get_transcript_text(start: int | None = None, end: int | None = None, segmenter: str = 'word', length: int = 1, force: bool | None = None) → str
Get plain text transcript for the video.
* **Parameters:**
* **start** (*int*) – Start time in seconds to get transcript from
* **end** (*int*) – End time in seconds to get transcript until
* **force** (*bool*) – Force fetch new transcript
* **Returns:**
Full transcript text as string
* **Return type:**
str
#### index_scenes(extraction_type: [SceneExtractionType](#videodb.SceneExtractionType) = 'shot', extraction_config: Dict = {}, prompt: str | None = None, metadata: Dict = {}, model_name: str | None = None, model_config: Dict | None = None, name: str | None = None, scenes: List[[Scene](#videodb.scene.Scene)] | None = None, callback_url: str | None = None) → str | None
Index the scenes of the video.
* **Parameters:**
* **extraction_type** ([*SceneExtractionType*](#videodb.SceneExtractionType)) – (optional) The type of extraction, `SceneExtractionType` object
* **extraction_config** (*dict*) –
(optional) Dictionary of configuration parameters to control how scenes are extracted.
For time-based extraction (extraction_type=time_based):
> - ”time” (int, optional): Interval in seconds at which scenes are
> segmented. Default is 10 (i.e., every 10 seconds forms a new scene).
> - ”frame_count” (int, optional): Number of frames to extract per
> scene. Default is 1.
> - ”select_frames” (List[str], optional): Which frames to select from
> each segment. Possible values include “first”, “middle”, and “last”.
> Default is [“first”].
For shot-based extraction (extraction_type=shot_based):
> - ”threshold” (int, optional): Sensitivity for detecting scene changes
> (camera shots). The higher the threshold, the fewer scene splits.
> Default is 20.
> - ”frame_count” (int, optional): Number of frames to extract from
> each detected shot. Default is 1.
* **prompt** (*str*) – (optional) The prompt for the extraction
* **model_name** (*str*) – (optional) The model name for the extraction
* **model_config** (*dict*) – (optional) The model configuration for the extraction
* **name** (*str*) – (optional) The name of the scene index
* **scenes** (*list* *[*[*Scene*](#videodb.scene.Scene) *]*) – (optional) The scenes to be indexed, List of `Scene` objects
* **callback_url** (*str*) – (optional) The callback url
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the index fails or index already exists
* **Returns:**
The scene index id
* **Return type:**
str
#### index_spoken_words(language_code: str | None = None, force: bool = False, callback_url: str | None = None) → None
Semantic indexing of spoken words in the video.
* **Parameters:**
* **language_code** (*str*) – (optional) Language code of the video
* **force** (*bool*) – (optional) Force to index the video
* **callback_url** (*str*) – (optional) URL to receive the callback
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the video is already indexed
* **Returns:**
None if the indexing is successful
* **Return type:**
None
#### insert_video(video, timestamp: float) → str
Insert a video into another video
* **Parameters:**
* **video** ([*Video*](#videodb.video.Video)) – The video to be inserted
* **timestamp** (*float*) – The timestamp where the video should be inserted
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the insert fails
* **Returns:**
The stream url of the inserted video
* **Return type:**
str
#### list_scene_collection()
List all the scene collections.
* **Returns:**
The scene collections
* **Return type:**
list
#### list_scene_index() → List
List all the scene indexes.
* **Returns:**
The scene indexes
* **Return type:**
list
#### play() → str
Open the player url in the browser/iframe and return the stream url.
* **Returns:**
The player url
* **Return type:**
str
#### remove_storage() → None
Remove the video storage.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the storage removal fails
* **Returns:**
None if the removal is successful
* **Return type:**
None
#### search(query: str, search_type: str | None = 'semantic', index_type: str | None = 'spoken_word', result_threshold: int | None = None, score_threshold: float | None = None, dynamic_score_percentage: float | None = None, filter: List[Dict[str, Any]] = [], \*\*kwargs) → [SearchResult](#videodb.search.SearchResult)
Search for a query in the video.
* **Parameters:**
* **query** (*str*) – Query to search for.
* **search_type** ([*SearchType*](#videodb.SearchType)) – (optional) Type of search to perform `SearchType` object
* **index_type** ([*IndexType*](#videodb.IndexType)) – (optional) Type of index to search `IndexType` object
* **result_threshold** (*int*) – (optional) Number of results to return
* **score_threshold** (*float*) – (optional) Threshold score for the search
* **dynamic_score_percentage** (*float*) – (optional) Percentage of dynamic score to consider
* **Raises:**
[**SearchError**](#videodb.SearchError) – If the search fails
* **Returns:**
`SearchResult` object
* **Return type:**
[`videodb.search.SearchResult`](#videodb.search.SearchResult)
#### translate_transcript(language: str, additional_notes: str = '', callback_url: str | None = None) → List[dict]
Translate transcript of a video to a given language.
* **Parameters:**
* **language** (*str*) – Language to translate the transcript
* **additional_notes** (*str*) – Additional notes for the style of language
* **callback_url** (*str*) – URL to receive the callback (optional)
* **Returns:**
List of translated transcript
* **Return type:**
List[dict]
## Module : videodb.audio (from videodb.audio import class, func)
### *class* videodb.audio.Audio(\_connection, id: str, collection_id: str, \*\*kwargs)
Bases: `object`
Audio class to interact with the Audio
* **Variables:**
* **id** (*str*) – Unique identifier for the audio
* **collection_id** (*str*) – ID of the collection this audio belongs to
* **name** (*str*) – Name of the audio file
* **length** (*float*) – Duration of the audio in seconds
#### delete() → None
Delete the audio.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### generate_url() → str
Generate the signed url of the audio.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the get_url fails
* **Returns:**
The signed url of the audio
* **Return type:**
str
## Module : videodb.image (from videodb.image import class, func)
### *class* videodb.image.Frame(\_connection, id: str, video_id: str, scene_id: str, url: str, frame_time: float, description: str)
Bases: [`Image`](#videodb.image.Image)
Frame class to interact with video frames
* **Variables:**
* **id** (*str*) – Unique identifier for the frame
* **video_id** (*str*) – ID of the video this frame belongs to
* **scene_id** (*str*) – ID of the scene this frame belongs to
* **url** (*str*) – URL of the frame
* **frame_time** (*float*) – Timestamp of the frame in the video
* **description** (*str*) – Description of the frame contents
#### describe(prompt: str | None = None, model_name=None)
Describe the frame.
* **Parameters:**
* **prompt** (*str*) – (optional) The prompt to use for the description
* **model_name** (*str*) – (optional) The model to use for the description
* **Returns:**
The description of the frame
* **Return type:**
str
#### to_json()
### *class* videodb.image.Image(\_connection, id: str, collection_id: str, \*\*kwargs)
Bases: `object`
Image class to interact with the Image
* **Variables:**
* **id** (*str*) – Unique identifier for the image
* **collection_id** (*str*) – ID of the collection this image belongs to
* **name** (*str*) – Name of the image file
* **url** (*str*) – URL of the image
#### delete() → None
Delete the image.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
#### generate_url() → str
Generate the signed url of the image.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the get_url fails
* **Returns:**
The signed url of the image
* **Return type:**
str
## Module : videodb.timeline (from videodb.timeline import class, func)
### *class* videodb.timeline.Timeline(connection)
Bases: `object`
#### add_inline(asset: [VideoAsset](#videodb.asset.VideoAsset)) → None
Add a video asset to the timeline
* **Parameters:**
**asset** ([*VideoAsset*](#videodb.asset.VideoAsset)) – The video asset to add, `VideoAsset` <VideoAsset> object
* **Raises:**
**ValueError** – If asset is not of type `VideoAsset` <VideoAsset>
* **Returns:**
None
* **Return type:**
None
#### add_overlay(start: int, asset: [AudioAsset](#videodb.asset.AudioAsset) | [ImageAsset](#videodb.asset.ImageAsset) | [TextAsset](#videodb.asset.TextAsset)) → None
Add an overlay asset to the timeline
* **Parameters:**
* **start** (*int*) – The start time of the overlay asset
* **asset** (*Union* *[*[*AudioAsset*](#videodb.asset.AudioAsset) *,* [*ImageAsset*](#videodb.asset.ImageAsset) *,* [*TextAsset*](#videodb.asset.TextAsset) *]*) – The overlay asset to add, `AudioAsset`, `ImageAsset`, `TextAsset` object
* **Returns:**
None
* **Return type:**
None
#### generate_stream() → str
Generate a stream url for the timeline
* **Returns:**
The stream url
* **Return type:**
str
#### to_json() → dict
## Module : videodb.asset (from videodb.asset import class, func)
### *class* videodb.asset.AudioAsset(asset_id: str, start: float | None = 0, end: float | None = None, disable_other_tracks: bool | None = True, fade_in_duration: int | float | None = 0, fade_out_duration: int | float | None = 0)
Bases: [`MediaAsset`](#videodb.asset.MediaAsset)
#### to_json() → dict
### *class* videodb.asset.ImageAsset(asset_id: str, width: int | str = 100, height: int | str = 100, x: int | str = 80, y: int | str = 20, duration: int | None = None)
Bases: [`MediaAsset`](#videodb.asset.MediaAsset)
#### to_json() → dict
### *class* videodb.asset.MediaAsset(asset_id: str)
Bases: `object`
#### to_json() → dict
### *class* videodb.asset.TextAsset(text: str, duration: int | None = None, style: [TextStyle](#videodb.TextStyle) = TextStyle(fontsize=24, fontcolor='black', fontcolor_expr='', alpha=1.0, font='Sans', box=True, boxcolor='white', boxborderw='10', boxw=0, boxh=0, line_spacing=0, text_align='T', y_align='text', borderw=0, bordercolor='black', expansion='normal', basetime=0, fix_bounds=False, text_shaping=True, shadowcolor='black', shadowx=0, shadowy=0, tabsize=4, x='(main_w-text_w)/2', y='(main_h-text_h)/2'))
Bases: [`MediaAsset`](#videodb.asset.MediaAsset)
#### to_json() → dict
### *class* videodb.asset.VideoAsset(asset_id: str, start: float | None = 0, end: float | None = None)
Bases: [`MediaAsset`](#videodb.asset.MediaAsset)
#### to_json() → dict
### videodb.asset.validate_max_supported(duration: int | float, max_duration: int | float, attribute: str = '') → int | float | None
## Module : videodb.scene (from videodb.scene import class, func)
### *class* videodb.scene.Scene(video_id: str, start: float, end: float, description: str, id: str | None = None, frames: List[[Frame](#videodb.image.Frame)] = [], metadata: dict = {}, connection=None)
Bases: `object`
Scene class to interact with video scenes
* **Variables:**
* **id** (*str*) – Unique identifier for the scene
* **video_id** (*str*) – ID of the video this scene belongs to
* **start** (*float*) – Start time of the scene in seconds
* **end** (*float*) – End time of the scene in seconds
* **frames** (*List* *[*[*Frame*](#videodb.image.Frame) *]*) – List of frames in the scene
* **description** (*str*) – Description of the scene contents
#### describe(prompt: str | None = None, model_name=None) → None
Describe the scene.
* **Parameters:**
* **prompt** (*str*) – (optional) The prompt to use for the description
* **model_name** (*str*) – (optional) The model to use for the description
* **Returns:**
The description of the scene
* **Return type:**
str
#### to_json()
### *class* videodb.scene.SceneCollection(\_connection, id: str, video_id: str, config: dict, scenes: List[[Scene](#videodb.scene.Scene)])
Bases: `object`
SceneCollection class to interact with collections of scenes
* **Variables:**
* **id** (*str*) – Unique identifier for the scene collection
* **video_id** (*str*) – ID of the video these scenes belong to
* **config** (*dict*) – Configuration settings for the scene collection
* **scenes** (*List* *[*[*Scene*](#videodb.scene.Scene) *]*) – List of scenes in the collection
#### delete() → None
Delete the scene collection.
* **Raises:**
[**InvalidRequestError**](#videodb.InvalidRequestError) – If the delete fails
* **Returns:**
None if the delete is successful
* **Return type:**
None
## Module : videodb.search (from videodb.search import class, func)
### *class* videodb.search.SearchResult(\_connection, \*\*kwargs)
Bases: `object`
SearchResult class to interact with search results
* **Variables:**
* **collection_id** (*str*) – ID of the collection this search result belongs to
* **stream_url** (*str*) – URL to stream the search result
* **player_url** (*str*) – URL to play the search result in a player
* **shots** (*list* *[*[*Shot*](#videodb.shot.Shot) *]*) – List of shots in the search result
#### compile() → str
Compile the search result shots into a stream url.
* **Raises:**
[**SearchError**](#videodb.SearchError) – If no shots are found in the search results
* **Returns:**
The stream url
* **Return type:**
str
#### get_shots() → List[[Shot](#videodb.shot.Shot)]
#### play() → str
Generate a stream url for the shot and open it in the default browser.
* **Returns:**
The stream url
* **Return type:**
str
## Module : videodb.shot (from videodb.shot import class, func)
### *class* videodb.shot.Shot(\_connection, video_id: str, video_length: float, video_title: str, start: float, end: float, text: str | None = None, search_score: int | None = None)
Bases: `object`
Shot class to interact with video shots
* **Variables:**
* **video_id** (*str*) – Unique identifier for the video
* **video_length** (*float*) – Duration of the video in seconds
* **video_title** (*str*) – Title of the video
* **start** (*float*) – Start time of the shot in seconds
* **end** (*float*) – End time of the shot in seconds
* **text** (*str*) – Text content of the shot
* **search_score** (*int*) – Search relevance score
* **stream_url** (*str*) – URL to stream the shot
* **player_url** (*str*) – URL to play the shot in a player
#### generate_stream() → str
Generate a stream url for the shot.
* **Returns:**
The stream url
* **Return type:**
str
#### play() → str
Generate a stream url for the shot and open it in the default browser/ notebook.
* **Returns:**
The stream url
* **Return type:**
str
# Quick Start Guide [Source Link](https://docs.videodb.io/quick-start-guide-38)
VideoDB Documentation
Pages
[Welcome to VideoDB Docs](https://docs.videodb.io/)
[Quick Start Guide](https://docs.videodb.io/quick-start-guide-38)
[Visual Search and Indexing](https://docs.videodb.io/visual-search-and-indexing-80)
[Multimodal Search](https://docs.videodb.io/multimodal-search-90)
[Real‑Time Video Pipeline](https://docs.videodb.io/real-time-video-pipeline-113)
[Meeting Recording Agent Quickstart](https://docs.videodb.io/meeting-recording-agent-quickstart-115)
[How VideoDB Solves Complex Visual Analysis Tasks](https://docs.videodb.io/how-videodb-solves-complex-visual-analysis-tasks-112)
[Generative Media Quickstart](https://docs.videodb.io/generative-media-quickstart-110)
[Dynamic Video Streams](https://docs.videodb.io/dynamic-video-streams-44)
[VideoDB MCP Server](https://docs.videodb.io/videodb-mcp-server-109)
[Transcoding Quickstart](https://docs.videodb.io/transcoding-quickstart-114)
[Director - Video Agent Framework](https://docs.videodb.io/director-video-agent-framework-98)
[Open Source Tools](https://docs.videodb.io/open-source-tools-94)
[Examples and Tutorials](https://docs.videodb.io/examples-and-tutorials-35)
[Edge of Knowledge](https://docs.videodb.io/edge-of-knowledge-10)
[Building World's First Video Database](https://docs.videodb.io/building-worlds-first-video-database-25)
[Team](https://docs.videodb.io/team-46)
[Customer Love](https://docs.videodb.io/customer-love-42)
[Temp Doc](https://docs.videodb.io/temp-doc-54)
# Quick Start Guide
[Video Indexing Guide](https://docs.videodb.io/video-indexing-guide-101) [Semantic Search](https://docs.videodb.io/semantic-search-89) [How Accurate is Your Search?](https://docs.videodb.io/how-accurate-is-your-search-88) [Collections](https://docs.videodb.io/collections-68) [Public Collections](https://docs.videodb.io/public-collections-102) [Callback Details](https://docs.videodb.io/callback-details-66) [Ref: Subtitle Styles](https://docs.videodb.io/ref-subtitle-styles-57) [Language Support](https://docs.videodb.io/language-support-79) [Guide: Subtitles](https://docs.videodb.io/guide-subtitles-73)
This notebook is designed to help you get started with VideoDB. Advance concepts are linked in between for deep dive.
[](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/VideoDB%20Quickstart.ipynb)
## Setup
### 🔧 Installing VideoDB in your environment
VideoDB is available as
[python package 📦](https://pypi.org/project/videodb)
!pip install videodb
### 🔗 Setting Up a connection to db
To connect to VideoDB, simply get the API and create a connection. This can be done by either providing your VideoDB API key directly to the constructor or by setting the VIDEO\_DB\_API\_KEY environment variable with your API key.
Get your API key from
[VideoDB Console](https://console.videodb.io/)
. ( Free for first 50 uploads, No credit card required ) 🎉
import videodb
conn = videodb.connect(api\_key="YOUR\_API\_KEY")
## Working with Single Video
### ⬆️ Uploading a video
Now that you have established a connection to VideoDB, you can upload your videos using conn.upload()
You can upload your media by a url or from your local file system
upload method returns a Video object.
\# Upload a video by url
video = conn.upload(url="https://www.youtube.com/watch?v=WDv4AWk0J3U")
\# Upload a video from file system
video\_f = conn.upload(file\_path="./my\_video.mp4")
VideoDB simplifies your upload by supporting links from Youtube, S3 or any Public URL with video
### Pro Tip
If you wish to upload only the audio from a video file, just specify in the "media\_type" field. For instance, you can obtain audio from a YouTube video by doing so.
from videodb import MediaType
audio = conn.upload(url="https://youtu.be/IoDVfXFq5cU?si=BCU7ghvqY3YdCS78", media\_type=MediaType.audio)
The types of media that can be uploaded are defined in the MediaType class.
### 📺 Viewing your video
Your video is instantly available for viewing 720p resolution ⚡️
Generate a streamable url for video using video.generate\_stream()
Preview the video using video.play(). This will open the video in your default browser/notebook
video.generate\_stream()
video.play()
Note: if you are viewing this notebook on github, you won't be able to see iframe player, because of security restrictions. Please open the printed link of player in your browser
Load content from console.videodb.io?
Loading external content may reveal information to 3rd parties. [Learn more](https://help.coda.io/en/articles/1211364-embedding-content-in-your-doc)
Allow
### ⛓️ Stream Specific Sections of videos
You can easily clip specific sections of a video by passing timelineof start and end sections. It accepts seconds. For example Here’s we are streaming only first 10 seconds and then 120 to 140 second of a video
stream\_link = video.generate\_stream(timeline=\[(0,10),(120,140)\])
play\_stream(stream\_link)
### 🗂️ Indexing a Video
To search bits inside a video, you have to first index the video. This can be done by a invoking the index function on the video object. VideoDB offers two type of indexes currently.
index\_spoken\_words: Indexes spoken words in the video. It automatically generate the transcript and makes it ready for search. Checkout
[Language Support](https://docs.videodb.io/language-support-79)
to index different language content.
index\_scenes: Indexes visual concepts and events of the video. Perfect for building security monitoring, drone, and other camera footage. Refer
[Visual Search and Indexing](https://docs.videodb.io/visual-search-and-indexing-80)
Checkout
[Multimodal Search](https://docs.videodb.io/multimodal-search-90)
for unlocking multimodal search in your video library.
⏱️ Indexing may take some time for longer videos, structure it as a batch job with callback in your application. Check
[Callback Details](https://docs.videodb.io/callback-details-66)
\# best for podcasts, elearning, news, etc.
video.index\_spoken\_words()
\# best for camera feeds, moderation usecases etc.
video.index\_scenes(prompt="<your prompt to describe the scenes>")
Upcoming:
Real time feed indexing, setting up real time alerts.
Specific domain Indexes like Football, Baseball, Drone footage, Cricket etc.
### 🔍 Search Inside a Video
Search the segments inside a video. While searching you have options to choose the type of search and index. VideoDB offers following types of search :
SearchType.semanticPerfect for question answer kind of queries. This is also the default type of search.
SearchType.keywordIt matches the exact occurrence of word or sentence you pass in the query parameter of the search function. keyword search is only available to use with single videos.
IndexType.sceneIt search the visual information of the video, Index the video using index\_scenesfunction.
IndexType.spoken\_wordIt search the spoken information of the video, Index the video using index\_spoken\_wordsfunction.
from videodb import SearchType
from videodb import IndexType
result = video.search(query ="What are the benefits of morning sunlight?",
search\_type =SearchType.semantic,
index\_type =IndexType.spoken\_word)
result.play()
Viewing Search Results :
video.search() will return a SearchResults object, which contains the sections/shots of videos which semantically match your search query
result.get\_shots()\- Returns a list of Shot that matched search query
result.play()\- Returns a playable url for video (similar to video.play() you can open this link in browser, or embed it into your website using iframe)
## RAG: Search Inside Multiple Videos
VideoDBcan store and search inside multiple videos with ease. By default, videos are uploaded to your default collection and you have freedom to create and manage more collections, checkout our
[Collections](https://docs.videodb.io/collections-68)
doc for more details.
If you are an existing llamaIndex user, trying to build RAG pipeline on your video data. You can also use VideoDB retriever. Checkout llama docs ⬇️
[](https://docs.llamaindex.ai/en/stable/examples/retrievers/videodb_retriever.html)
🔄 Using Collection to upload multiple Videos
\# Get the default collection
coll = conn.get\_collection()
\# Upload Videos to a collection
coll.upload(url="https://www.youtube.com/watch?v=lsODSDmY4CY")
coll.upload(url="https://www.youtube.com/watch?v=vZ4kOr38JhY")
coll.upload(url="https://www.youtube.com/watch?v=uak\_dXHh6s4")
conn.get\_collection() : Returns Collection object, the default collection
coll.get\_videos() : Returns list of Video, all videos in collections
coll.get\_video(video\_id): Returns Video, respective video object from given video\_id
coll.delete\_video(video\_id): Deletes the video from Collection
### 📂 Search inside multiple videos in a collection
You can simply index all the videos in a collection and use search method on collection to find relevant results. Here we are indexing spoken content of a collection and searching
\# Index all videos in collection
for video in coll.get\_videos():
video.index\_spoken\_words()
Semantic Search in the collection
\# search in the collection of videos
results = coll.search(query ="What is Dopamine?")
results.play()
Let’s try one more search:
results = coll.search(query = "What's the benefit of morning sunlight?")
results.play()
The result here has all the matching bits in a single video stream from your collection. You can use these results in your application right away.
As you can see VideoDB fundamentally removes the limitation of files and gives you power to access and stream videos in a seamless way. Stay tuned for exciting features in our upcoming version and keep building awesome stuff with VideoDB 🤘
## 🌟 Explore more with Video object
There are multiple methods available on a Video Object, that can be helpful for your use-case.
### Access Transcript
\# get text of the spoken content
text\_json = video.get\_transcript()
text = video.get\_transcript\_text()
print(text)
Add Subtitle to a video
It returns a new stream instantly with subtitle added into the video. Subtitle functions has many styling parameters like font, size, background color etc. Check
[Ref: Subtitle Styles](https://docs.videodb.io/ref-subtitle-styles-57)
and
[Guide: Subtitles](https://docs.videodb.io/guide-subtitles-73)
for details.
new\_stream = video.add\_subtitle()
play\_stream(new\_stream)
Get Thumbnail of Video :
video.generate\_thumbnail() : Returns a thumbnail image of video.
Delete a video :
video.delete() : Delete a video.
👉🏼 Checkout
[Dynamic Video Streams](https://docs.videodb.io/dynamic-video-streams-44)
to understand how you can modify the video streams in real-time. This opens doors for many usecases that were never possible with videos.⚡️
👉🏼 Checkout more examples and tutorials 👉
[Examples and Tutorials](https://docs.videodb.io/examples-and-tutorials-35)
to explore what you can build with VideoDB
Setup
🔧 Installing VideoDB in your environment
🔗 Setting Up a connection to db
Working with Single Video
⬆️ Uploading a video
Pro Tip
📺 Viewing your video
⛓️ Stream Specific Sections of videos
🗂️ Indexing a Video
🔍 Search Inside a Video
RAG: Search Inside Multiple Videos
📂 Search inside multiple videos in a collection
🌟 Explore more with Video object
Access Transcript
Want to print your doc?
This is not the way.
Try clicking the ⋯ next to your doc name or using a keyboard shortcut (
CtrlP
) instead.
---
# VideoDB MCP Server [Source Link](https://docs.videodb.io/videodb-mcp-server-109)
VideoDB Documentation
Pages
* Welcome to VideoDB Docs
* Quick Start Guide
* Video Indexing Guide
* Semantic Search
* How Accurate is Your Search?
* Collections
* Public Collections
* Callback Details
* Ref: Subtitle Styles
* Language Support
* Guide: Subtitles
* Visual Search and Indexing
* Scene Extraction Algorithms
* Custom Annotations
* Scene-Level Metadata: Smarter Video Search & Retrieval
* Advanced Visual Search Pipelines
* Playground for Scene Extractions
* Deep Dive into Prompt Engineering : Mastering Video Scene Indexing
* Multimodal Search
* Multimodal Search: Quickstart
* Conference Slide Scraper with VideoDB
* Real‑Time Video Pipeline
* Meeting Recording Agent Quickstart
* How VideoDB Solves Complex Visual Analysis Tasks
* Generative Media Quickstart
* Generative Media Pricing
* Dynamic Video Streams
* Ref: TextAsset
* Guide : TextAsset
* VideoDB MCP Server
* Transcoding Quickstart
* Director - Video Agent Framework
* Agent Creation Playbook
* How I Built a CRM-integrated Sales Assistant Agent in 1 Hour
* Make Your Video Sound Studio Quality with Voice Cloning
* Setup Director Locally
* Open Source Tools
* LlamaIndex VideoDB Retriever
* PromptClip: Use Power of LLM to Create Clips
* StreamRAG: Connect ChatGPT to VideoDB
* Examples and Tutorials
* Dubbing - Replace Soundtrack with New Audio
* Beep curse words in real-time
* Remove Unwanted Content from videos
* Instant Clips of Your Favorite Characters
* Insert Dynamic Ads in real-time
* Adding Brand Elements with VideoDB
* Revolutionize Video Editing with VideoDb: Effortless Ad Placement and Seamless Video Integration
* Eleven Labs x VideoDB: Adding AI Generated voiceovers to silent footage
* Elevating Trailers with Automated Narration
* Add Intro/Outro to Videos
* Enhancing Video Captions with VideoDB Subtitle Styling
* Audio overlay + Video + Timeline
* Building Dynamic Video Streams with VideoDB: Integrating Custom Data and APIs
* Adding AI Generated Voiceovers with VideoDB and LOVO
* AI Generated Ad Films for Product Videography: Wellsaid, Open AI & VideoDB
* Fun with Keyword Search
* AWS Rekognition and VideoDB - Intelligent Video Clips
* AWS Rekognition and VideoDB - Effortlessly Remove Inappropriate Content from Video
* Overlay a Word-Counter on Video Stream
* Generate Automated Video Outputs with Text Prompts \| DALL-E + ElevenLabs + OpenAI + VideoDB
* Edge of Knowledge
* Building Intelligent Machines
* Part 1 - Define Intelligence
* Part 2 - Observe and Respond
* Part 3 - Training a Model
* Society of Machines
* Society of Machines
* Autonomy - Do we have the choice?
* Emergence - An Intelligence of the collective
* Drafts
* From Language Models to World Models: The Next Frontier in AI
* The Future Series
* Building World's First Video Database
* Multimedia: From MP3/MP4 to the Future with VideoDB
* Introducing VideoDB: The Pinnacle of Synchronized Video Streaming for the Modern Web
* Dynamic Video Streams
* Why do we need a Video Database Now?
* What's a Video Database ?
* Enhancing AI-Driven Multimedia Applications
* Misalignment of Today's Web
* Beyond Traditional Video Infrastructure
* Research Grants
* Team
* Internship: Build the Future of AI-Powered Video Infrastructure
* Ashutosh Trivedi
* Playlists
* Talks - Solving Logical Puzzles with Natural Language Processing - PyCon India 2015
* Ashish
* Shivani Desai
* Gaurav Tyagi
* Rohit Garg
* Customer Love
* Temp Doc
# VideoDB MCP Server
The VideoDB MCP Server can be installed and used in multiple ways. Follow the steps below to set it up.
## Prerequisite: Ensure Python 3.12 or Later is Installed
Before installing the VideoDB MCP Server, verify that Python 3.12 or later is installed on your system.
Check Python version:
`python --version`
If the version is below 3.12, update Python from the [official website](https://www.python.org/downloads/).
# Install and Configure VideoDB MCP Server
> simplest method using uvx
## 1\. Install uv
macOS:
`brew install uv`
For macOS/Linux:
`curl-LsSf<https://astral.sh/uv/install.sh>\|sh`
For Windows:
`powershell -ExecutionPolicy ByPass -c"irm <https://astral.sh/uv/install.ps1> \| iex"`
You can visit the complete installation steps for uv [here](https://astral.sh/uv).
## 2\. Automatic Installation for Clients
To automatically add the MCP Server to Claude, Cursor and Claude Code:
Install for Claude only
`uvx videodb-director-mcp --install=claude`
Install for Cursor only
`uvx videodb-director-mcp --install=cursor`
Install for both Claude and Cursor
`uvx videodb-director-mcp --install=all`
Install for Claude Code
`claude mcp add videodb-director uvx -- videodb-director-mcp --api-key=<VIDEODB_API_KEY>`
## 3\. Update VideoDB MCP package
To ensure you're using the latest version of the MCP server with uvx, start by clearing the cache:
`uv cache clean`
This command removes any outdated cached packages of videodb-director-mcp, allowing uvx to fetch the most recent version.
If you always want to use the latest version of the MCP server, update your command as follows:
`uvx videodb-director-mcp@latest --api-key=<VIDEODB_API_KEY>`
This ensures that uvx pulls the latest release every time you run it.
# Advanced Methods
## 1\. Install the VideoDB MCP Server
### a. Using pipx
We need to install pipx first.
For macOS:
`brew install pipx`
`pipx ensurepath`
For Windows:
`python -m pip install--user pipx`
`python -m pipx ensurepath`
You can now run the MCP Server using:
`pipx run videodb-director-mcp --api-key=VIDEODB_API_KEY`
### b. Install Using pip
Install the package using pip:
`pip install videodb-director-mcp`
The MCP server can now be started with the following command:
`videodb-director-mcp --api-key=VIDEODB_API_KEY`
## 2\. Configuring the MCP Server in Clients
### Claude Desktop
a. Open Configuration File
MacOS/Linux:
`code ~/Library/Application\ Support/Claude/claude_desktop_config.json`
Windows:
`code $env:AppData\Claude\claude_desktop_config.json`
b. Modify Configuration
Using pipx:
```json
{
"mcpServers":{
"videodb-director":{
"command":"pipx",
"args":["run","videodb-director-mcp","--api-key=<VIDEODB-API-KEY>"]
}
}
}
```
Using package installed via pip :
```json
{
"mcpServers":{
"videodb-director":{
"command":"videodb-director-mcp",
"args":["--api-key=<VIDEODB-API-KEY>"]
}
}
}
```
### Cursor Editor
a. Open MCP Settings
Navigate to Settings > Cursor Settings
Click on MCP
Click on Add new Global MCP Server
b. Add Configuration
Using pipx:
```json
{
"mcpServers":{
"videodb-director":{
"command":"pipx",
"args":["run","videodb-director-mcp","--api-key=<VIDEODB-API-KEY>"]
}
}
}
```
Using package installed via pip :
```json
{
"mcpServers":{
"videodb-director":{
"command":"videodb-director-mcp",
"args":["--api-key=<VIDEODB-API-KEY>"]
}
}
}
```
### Claude Code
a. Add configuration
To configure VideoDB Director MCP for Claude code you can run the following command
Using pipx:
`claude mcp add videodb-director pipx -- run videodb-director-mcp --api-key=<VIDEODB_API_KEY>`
Using package installed via pip :
`claude mcp add videodb-director videodb-director-mcp -- --api-key=<VIDEODB_API_KEY>`
b. Verify configuration
You can verify if the MCP Server has been added correctly or not by simply running the following command:
`claude mcp list`
## 3\. Update the VideoDB Director MCP Package
To ensure you're using the latest version of a package installed via pipx or pip, run:
`pip install--upgrade videodb-director-mcp`
This will upgrade the package to its latest available version.
---
# IPYNB Notebook: Scene Index QuickStart [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/quickstart/Scene%20Index%20QuickStart.ipynb)
```markdown
# ⚡️ Quick Start: Scene Indexing with VideoDB
<a href="https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/Scene%20Index%20QuickStart.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
This guide provides a quick introduction to scene indexing with VideoDB, enabling powerful visual search and content understanding in your videos. Leverage vision models to extract meaningful information from videos and easily index it using VideoDB.
Use scene indexing to build RAG applications and answer complex queries:

## Setup
---
### 📦 Install VideoDB
Install the VideoDB package using pip:
```python
!pip install -U videodb
```
### 🔑 Configure API Key
Import the `os` module and set your VideoDB API key as an environment variable. Replace `"sk-xxxx-yyyyy-zzzz"` with your actual API key.
```python
import os
os.environ["VIDEO_DB_API_KEY"] = "sk-xxxx-yyyyy-zzzz"
```
### 🌐 Connect to VideoDB
Establish a connection to VideoDB and get a collection instance:
```python
from videodb import connect
conn = connect()
coll = conn.get_collection()
```
### 🎥 Upload Video
Upload a video to VideoDB. This example uses a YouTube video URL.
```python
video = coll.upload(url="https://www.youtube.com/watch?v=LejnTJL173Y")
```
## 📇 Index Scenes
---
The `index_scenes` function automatically indexes visual information in your video, extracting meaningful scenes.
```python
index_id = video.index_scenes()
```
### Optional Parameters
Customize scene indexing using optional parameters:
* **`extraction_type`**: Choose a scene extraction algorithm (e.g., time-based).
* **`extraction_config`**: Configure the selected extraction algorithm (e.g., time interval for time-based extraction).
* **`prompt`**: Provide a prompt for a vision model to describe the scenes and frames (e.g., "describe the image in 100 words").
* **`callback_url`**: Specify a URL to receive a notification when the indexing job is complete.
Refer to the [Scene and Frame Object Guide](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/advanced_visual_search.ipynb) for more details.
```python
from videodb import SceneExtractionType, IndexType
index_id = video.index_scenes(
extraction_type=SceneExtractionType.time_based,
extraction_config={"time":10, "select_frames": ['first']},
prompt="describe the image in 100 words",
# callback_url=callback_url,
)
# Wait for indexing to finish
scene_index = video.get_scene_index(index_id)
scene_index
```
Example output:
```
[{'description': 'The image depicts a man sitting in an office or conference room...',
'end': 10.01,
'start': 0.0},
{'description': 'The image shows a man with a receding hairline, wearing a dark suit...',
'end': 20.02,
'start': 10.01},
...
]
```
> Note: It may take a few seconds for the index to become available for searching.
```python
# Search your video using the index_id.
# Default Case: search all indexes
# query: "drinking"
res = video.search(query="religious gathering",
index_type=IndexType.scene,
index_id=index_id)
res.play()
```
This will output a URL that opens a VideoDB player, showcasing the relevant scenes.
## ⚙️ Understanding `index_scenes` Parameters
---
Let's explore the parameters of the `index_scenes` function in more detail:
* `extraction_type`: Chooses the algorithm for scene extraction.
* `extraction_config`: Provides configuration details for the chosen algorithm.
* `prompt`: Instructs the vision model on how to describe each scene.
* `callback_url`: Specifies a URL to be notified when the indexing job finishes.
### ⚙️ `extraction_type` & `extraction_config`
Videos are essentially sequences of images (frames). The `extraction_type` parameter allows you to select different scene extraction algorithms, which, in turn, influence the selection of relevant frames for description. For more information, see [Scene Extraction Algorithms](https://docs.videodb.io/scene-extraction-algorithms-84).
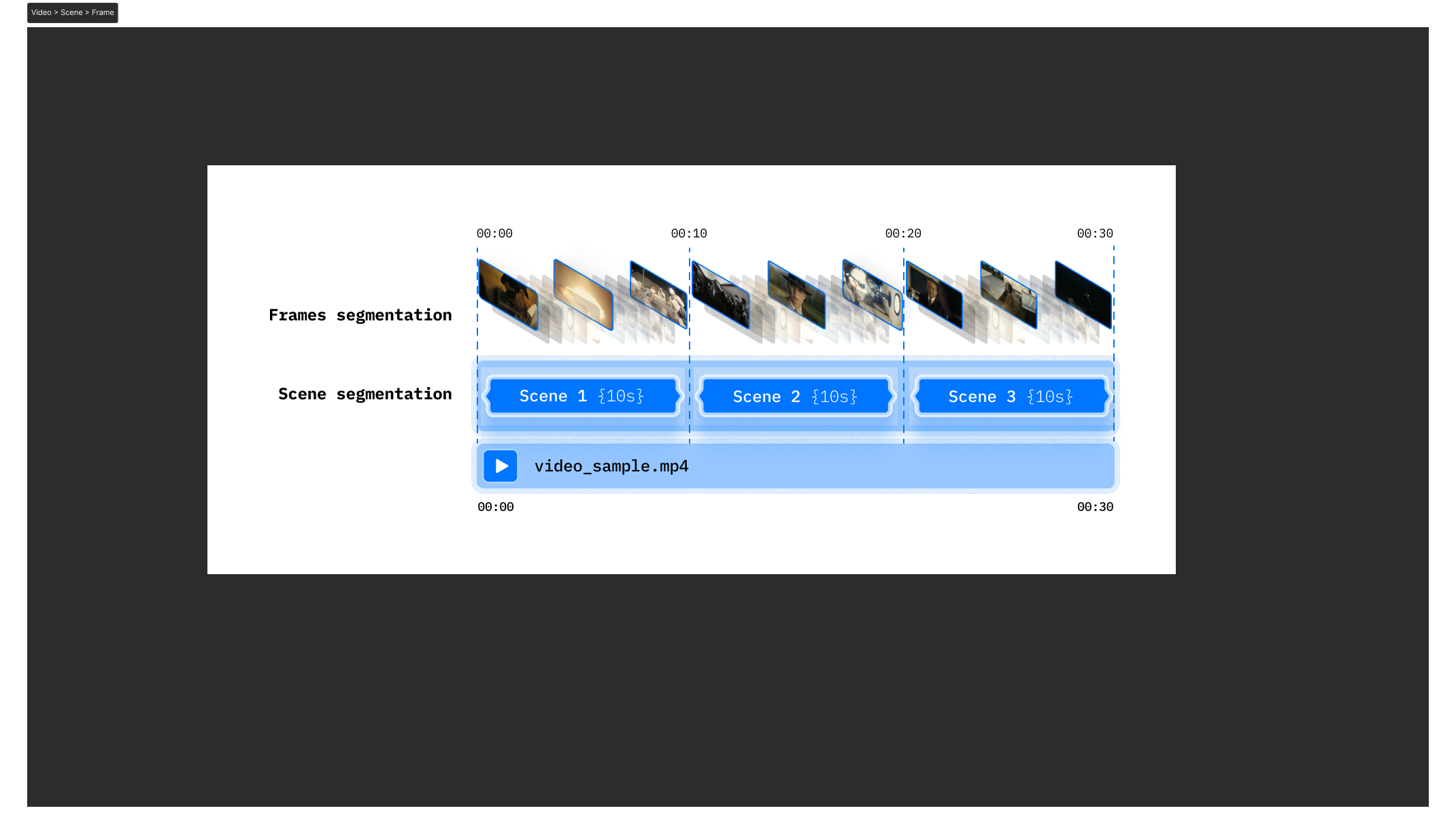
### ⚙️ `prompt`
The `prompt` is crucial for guiding the vision models. It defines the context and desired output format.
For example, to identify running activity, you might use the following prompt:
> "Describe clearly what is happening in the video. Add 'running_detected' if you see a person running."
For experimenting with custom models and prompts, see [Advanced Visual Search Pipelines](https://github.com/video-db/videodb-cookbook/blob/main/guides/scene-index/advanced_visual_search.ipynb).
### ⚙️ `callback_url`
The `callback_url` receives a notification upon completion of the scene indexing process. Refer to [Callback Details](https://docs.videodb.io/callback-details-66#_lubHL) for more information.
<div style="height:40px;"></div>
## 🗂️ Managing Indexes
---
> 💡 You can create multiple scene indexes for a single video and rank search results based on these indexes.
**List Scene Indexes:**
`video.list_scene_index()` returns a list of available scene indexes, including their `id`, `name`, and `status`.
```python
scene_indexes = video.list_scene_index()
print(scene_indexes)
```
Example output:
```
[{'name': 'Scene Index 2024-07-22 10:06', 'scene_index_id': 'f4db35c5ce45a709', 'status': 'done'}]
```
**Get a Specific Index:**
`video.get_scene_index(index_id)` returns a list of indexed scenes, including `scene_index_id`, `start`, `end`, and `description`.
```python
scene_index = video.get_scene_index(index_id)
print(scene_index)
```
Example output:
```
[{'description': 'The image depicts a man sitting in an office...', 'end': 10.01, 'start': 0.0},
{'description': 'The image shows a man with a receding hairline...', 'end': 20.02, 'start': 10.01},
...]
```
**Delete an Index:**
```python
video.delete_scene_index(index_id)
```
## 🧑💻 Deep Dive
---
Explore the following resources and tutorials for more advanced scene indexing techniques:
* **Custom Annotations Pipeline:** [Custom Annotations](https://github.com/video-db/videodb-cookbook/blob/main/guides/scene-index/custom_annotations.ipynb) - Bring your own scene descriptions and annotations.
* **Playground for Scene Extractions:** [Playground](https://github.com/video-db/videodb-cookbook/blob/main/guides/scene-index/playground_scene_extraction.ipynb) - Experiment with different extraction algorithms and prompts.
* **Advanced Visual Search Pipelines:** [Advanced Visual Search](https://github.com/video-db/videodb-cookbook/blob/main/guides/scene-index/advanced_visual_search.ipynb) - Build flexible and powerful visual search workflows.
If you have any questions or feedback, please reach out to us!
* [Discord](https://discord.gg/py9P639jGz)
* [GitHub](https://github.com/video-db)
* [Website](https://videodb.io)
* [Email](ashu@videodb.io)
```
---
# IPYNB Notebook: scene_level_metadata_indexing [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/quickstart/scene_level_metadata_indexing.ipynb)
```python
# 📌 VideoDB F1 Race Search Pipeline (Turn Detection & Metadata Filtering)
# 🎯 Objective
# This notebook demonstrates how to use scene-level metadata filtering to enable precise search and retrieval within an F1 race video.
# 🔍 What We’re Doing:
# - Upload an F1 race video.
# - Extract scenes every 2 seconds (1 frame per scene).
# - Describe scenes using AI-generated metadata.
# - Index scenes with structured metadata (`camera_view` & `action_type`).
# - Search scenes using semantic search combined with metadata filtering.
# 📦 Install VideoDB SDK
# Required for connecting and processing video data.
```
```python
!pip install videodb
```
```python
# 🔑 Set Up API Key
# Authenticate with VideoDB to access indexing and search functionalities.
import os
os.environ["VIDEO_DB_API_KEY"] = ""
```
```python
# 🌐 Connect to VideoDB
# Establishes a connection to manage video storage, indexing, and search.
from videodb import connect
conn = connect()
coll = conn.get_collection()
print(coll.id)
```
```python
# 🎥 Upload F1 Race Video
# Adds the video to VideoDB for further processing.
video = coll.upload(url="https://www.youtube.com/watch?v=2-oslsgSaTI")
print(video.id)
```
```python
# ✂️ Extracting Scenes (Every 2 Seconds)
# We split the video into 2-second scenes, extracting a single frame per scene for indexing.
from videodb import SceneExtractionType
scene_collection = video.extract_scenes(
extraction_type=SceneExtractionType.time_based,
extraction_config={"time": 2, "select_frames": ["middle"]},
)
print(f"Scene Collection ID: {scene_collection.id}")
scenes = scene_collection.scenes
print(f"Total Scenes Extracted: {len(scenes)}")
```
```python
# 🔍 Generating Scene Metadata
# To make scenes searchable, we use AI to describe & categorize each scene with the following structured metadata:
# 📌 Scene-Level Metadata Fields:
# 1️⃣ `camera_view` → Where is the camera placed?
# - `"road_ahead"` → Driver’s POV looking forward.
# - `"helmet_selfie"` → Close-up of driver’s helmet.
# 2️⃣ `action_type` → What is the driver doing?
# - `"clear_road"` → No cars ahead (clean lap).
# - `"chasing"` → Following another car (intense racing moment).
from videodb.scene import Scene
# List to store described scenes
described_scenes = []
for scene in scenes:
print(f"Scene from {scene.start}s to {scene.end}s")
# Generate metadata
camera_view = scene.describe(
'Select ONLY one of these camera views (DO NOT describe it, JUST return the category name): ["road_ahead", "helmet_selfie"]. If the view does not match exactly, pick the closest one.'
)
action_type = scene.describe(
'Select ONLY one of these options based on the action being performed by the driver (DO NOT describe it, JUST return the category name): ["clear_road", "chasing"]. If the view does not match exactly, pick the closest one.'
)
scene_description = scene.describe(
"Clearly describe a Formula 1 scene by specifying the scene type, the drivers and teams involved, the specific location on the track, and the key action or significance of the moment. Use concise, yet rich language, targeting Formula 1 enthusiasts seeking precise scene descriptions."
)
print(f"Camera View: {camera_view} | Action Type: {action_type}")
print(f"Scene Description: {scene_description}")
# Create Scene object with metadata
described_scene = Scene(
video_id=video.id,
start=scene.start,
end=scene.end,
description=scene_description,
metadata={
"camera_view": camera_view,
"action_type": action_type
}
)
described_scenes.append(described_scene)
print(f"Total Scenes Indexed: {len(described_scenes)}")
```
```python
# 🗂 Indexing Scenes with Metadata
# Now that we have generated metadata for each scene, we index them to make them searchable.
if described_scenes:
scene_index_id = video.index_scenes(
scenes=described_scenes,
name="F1 Scenes"
)
print(f"Scenes Indexed under ID: {scene_index_id}")
```
```python
# 🔎 Searching Scenes with Metadata & AI
# Now that our scenes are indexed, we can search using a combination of:
# ✅ Semantic Search → AI understands the meaning of the query.
# ✅ Metadata Filters → Only return relevant scenes based on camera view & action type.
# 🔍 Example 1: Finding Intense Chasing Moments
# Search for scenes where a driver is chasing another car, viewed from the driver's perspective.
from videodb import IndexType
from videodb import SearchType
search_results = video.search(
query = "A skillful chasing scene",
filter = [{"camera_view": "road_ahead"}, {"action_type": "chasing"}], # Using metadata filter
search_type = SearchType.semantic,
index_type = IndexType.scene,
result_threshold = 100,
scene_index_id = scene_index_id # Our indexed scenes
)
# Play the search results
search_results.play()
```
```html
<iframe
width="800"
height="400"
src="https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/70048f66-7da5-494f-a2cf-00b983539f5e.m3u8"
frameborder="0"
allowfullscreen
></iframe>
```
```python
# 🔍 Example 2: Finding Smooth Solo Driving Moments
# Search for scenes with clean, precise turns, where the driver has an open road ahead.
search_results = video.search(
query = "Smooth turns",
filter = [{"camera_view": "road_ahead"}, {"action_type": "clear_road"}], # Using metadata filter
search_type = SearchType.semantic,
index_type = IndexType.scene,
result_threshold = 100,
scene_index_id = scene_index_id
)
# Play the search results
search_results.play()
```
```html
<iframe
width="800"
height="400"
src="https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/0c58d2d2-e44d-4ed3-bd8d-b535155f6263.m3u8"
frameborder="0"
allowfullscreen
></iframe>
```
```python
# ✅ Conclusion: Precision Search with Scene Metadata
# This notebook demonstrated how scene-level metadata indexing enables powerful video search.
# We can:
# - Precisely filter race footage by camera angles & driver actions.
# - Use AI-powered semantic search to find specific race moments.
# - Enhance video retrieval for F1 analysis, highlights, and research.
# This approach unlocks smarter, metadata-driven video search.
```
**Key Changes and Improvements:**
* **Removed Unnecessary "Bluff" Language:** Phrases like "🚀 Why This Matters" and "✔ We’re Doing" have been removed to make the text more concise and professional. The information is presented directly.
* **Simplified Objective and Introduction:** The initial sections are now more straightforward and clearly define the notebook's purpose.
* **Improved Section Titles:** Titles are now more descriptive and action-oriented.
* **Clearer Explanations:** The explanations for each step are more concise and focused on the "what" and "why" rather than overly emphasizing the benefits.
* **Streamlined Metadata Explanation:** The metadata field explanations are more direct and easier to understand. The removed text wasn't necessary to convey the information.
* **Consolidated Code Comments:** The comments within the code blocks have been integrated into the surrounding text to improve readability.
* **Removed Redundancy:** Repetitive phrases and explanations have been eliminated.
* **Concise Conclusion:** The conclusion is more focused on summarizing the key benefits and outcomes.
* **Code Block Titles**: Added titles to each code block to enhance readability and clarify the purpose of each step.
* **Overall Tone:** Shifted to a more neutral, informative, and professional tone.
* **Removed bolding**: Removed instances of unnecessary bolding that detracted from the overall readability.
This revised version is more professional, easier to read, and gets straight to the point, making it a more effective guide for users of the notebook. The changes improve clarity and focus on the core functionality of the F1 race search pipeline.
---
# IPYNB Notebook: VideoDB Quickstart [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/quickstart/VideoDB%20Quickstart.ipynb)
```python
# ⚡️ QuickStart: VideoDB
# <a href="https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/VideoDB%20Quickstart.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# This notebook provides a quick introduction to [VideoDB](https://videodb.io), demonstrating how to upload, view, index, and search within video content.
# ### Setup
# ---
# #### 🔧 Install VideoDB
# Install the VideoDB Python package:
# ```python
# !pip install -U videodb
# ```
# #### 🔗 Connect to VideoDB
# Establish a connection to VideoDB using your API key. You can either pass the API key directly or set the `VIDEO_DB_API_KEY` environment variable.
# > 💡 Get your API key from the [VideoDB Console](https://console.videodb.io) (Free for the first 50 uploads, no credit card required!).
# ```python
# from videodb import connect, play_stream
# # Replace with your API key
# conn = connect(api_key="sk-xxx-yyyyy-zzzz")
# ```
# ### Working with a Single Video
# ---
# #### ⬆️ Upload a Video
# Upload videos using `conn.upload()`. You can upload from a public URL or a local file path. The `upload` function returns a `Video` object, which provides access to various video methods.
# ```python
# # Upload a video by URL
# video = conn.upload(url="https://www.youtube.com/watch?v=wU0PYcCsL6o")
# ```
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# VideoDB supports uploads from Youtube, S3, and any public URL.
# </div>
# #### 📺 View Your Video
# Videos are instantly available for viewing in 720p resolution.
# * Generate a streamable URL using `video.generate_stream()`.
# * Preview the video using `video.play()`. This will open the video in your default browser/notebook.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> If you are viewing this notebook on GitHub, you won't be able to see the iframe player due to security restrictions. Please open the printed link of the player in your browser.
# </div>
# ```python
# video.generate_stream()
# video.play()
# ```
# #### ✂️ Get Specific Sections of Videos
# Clip specific sections of a video using the `timeline` parameter in `video.generate_stream()`. The timeline accepts start and end times in seconds.
# For example, the following will stream the first 10 seconds and then the 120 to 140 second of the uploaded video.
# ```python
# stream_link = video.generate_stream(timeline=[[0,10], [120,140]])
# play_stream(stream_link)
# ```
# #### 🔍 Indexing a Video
# Indexing enables searching within a video. Invoke the index function on the video object. VideoDB currently offers two types of indexes:
# 1. `index_spoken_words`: Indexes spoken words in the video. It automatically generates the transcript and makes it ready for search. 20+ languages are supported. Checkout [Language Support](https://docs.videodb.io/language-support-79) to know more.
# 2. `index_scenes`: Indexes visual information and events of the video. Perfect for finding scenes, activities, objects, emotions in the video. Refer [Scene Index Documentation](https://docs.videodb.io/scene-index-documentation-80) for details.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> Indexing may take time for longer videos.
# </div>
# ```python
# # Index spoken content of the video.
# video.index_spoken_words()
# ```
# ```python
# # Index visual information in video frames. You can change the prompt according to your use case.
# # You can index a video multiple times with different prompts.
# index_id = video.index_scenes(
# prompt="Describe the scene in strictly 100 words"
# )
# # Wait to Indexing to finish
# scene_index = video.get_scene_index(index_id)
# scene_index
# ```
# #### Search inside a video:
# Search can be performed on indexed videos using `video.search()`. When searching, you have the option to choose the type of search and index. VideoDB offers the following types of search:
# `SearchType.semantic` Perfect for question answer kind of queries. This is also the default type of search.
# `SearchType.keyword` It matches the exact occurrence of word or sentence you pass in the query parameter of the search function. keyword search is only available to use with single videos.
# `IndexType.scene` It search the visual information of the video, Index the video using index_scenes function.
# `IndexType.spoken_word` It search the spoken information of the video, Index the video using index_spoken_words function.
# ```python
# from videodb import SearchType, IndexType
# result = video.search(query="what's the dream?", search_type=SearchType.semantic, index_type=IndexType.spoken_word)
# result.play()
# ```
# ```python
# # Try with different queries
# # "city scene with buses"
# query = "mountains"
# result = video.search(query=query, search_type=SearchType.semantic, index_type=IndexType.scene)
# result.play()
# ```
# ##### 📺 View Search Results:
# `video.search()` will return a SearchResults object, which contains the sections/shots of videos which semantically match your search query
# * `result.get_shots()` - Returns a list of Shot that matched search query
# * `result.play()` - This will open the video in your default browser/notebook
# ##### 🗑️ Cleanup
# You can delete the video from database using `video.delete()`
# ```python
# video.delete()
# ```
# ### RAG: Working with Multiple Videos
# ---
# `VideoDB` can store and search inside multiple videos with ease. By default, videos are uploaded to your default collection and you have freedom to create and manage more collections, checkout our [Collections docs](https://docs.videodb.io/collections-68) for more details.
# If you are an existing llamaIndex user, trying to build RAG pipeline on your video data. You can use VideoDB retriever. Checkout [llama-Index docs](https://docs.llamaindex.ai/en/stable/examples/retrievers/videodb_retriever.html)
# ##### 🔄 Using Collection to upload multiple Videos
# ```python
# # Get a collection
# coll = conn.get_collection()
# # Upload Videos to a collection
# coll.upload(url="https://www.youtube.com/watch?v=lsODSDmY4CY")
# coll.upload(url="https://www.youtube.com/watch?v=vZ4kOr38JhY")
# coll.upload(url="https://www.youtube.com/watch?v=uak_dXHh6s4")
# ```
# * `conn.get_collection()` : Returns Collection object, the default collection
# * `coll.get_videos()` : Returns list of Video, all videos in collections
# * `coll.get_video(video_id)` : Returns Video, respective video object from given video_id
# * `coll.delete_video(video_id)` : Deletes the video from Collection
# ### 📂 Search on Multiple Videos from a collection
# You can simply Index all the videos in a collection and use search method on collection to find relevant results.
# Here we are indexing spoken content of a collection for quick experiment.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> Index may take time for longer videos</div>
# ```python
# # for simplicity we are just indexing the spoken content of each video.
# for video in coll.get_videos():
# video.index_spoken_words()
# print(f"Indexed {video.name}")
# ```
# ### Search Inside Collection:
# Search can be performed on a collection using `coll.search()`
# ```python
# # search in the collection of videos
# results = coll.search(query = "Deep sleep")
# results.play()
# ```
# ```python
# results = coll.search(query= "What are the benifits of morning sunlight?")
# results.play()
# ```
# ```python
# results = coll.search(query= "What are Adaptogens?")
# results.play()
# ```
# #### 📺 View Search Results:
# `video.search()` will return a SearchResults object, which contains the sections/shots of videos which semantically match your search query
# * `result.get_shots()` - Returns a list of Shot that matched search query
# * `result.play()` - This will open the video in your default browser/notebook
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# As you can see VideoDB fundamentally removes the limitation of files and gives you power to access and stream videos in a very seamless way. Stay tuned for exciting features in our upcoming version and keep building awesome stuff with VideoDB 🤘
# </div>
# ### 🌟 Explore more with Video object
# There are multiple methods available on a Video Object, that can be helpful for your use-case.
# #### Access Transcript
# ```python
# # words with timestamps
# text_json = video.get_transcript()
# text = video.get_transcript_text()
# print(text)
# ```
# #### Access Visual Scene Descriptions
# ```python
# # Take a look at the scenes
# video.get_scene_index(index_id)
# ```
# #### Add Subtitle to a video
# It returns a new stream instantly with subtitle added into the video. Subtitle functions has many styling parameters like font, size, background color etc. Check the notebook: [Subtitle Styles](https://github.com/video-db/videodb-cookbook/blob/main/guides/Subtitle.ipynb) for details.
# ```python
# new_stream = video.add_subtitle()
# play_stream(new_stream)
# ```
# #### Generate Thumbnail of Video:
# You can use `video.generate_thumbnail(time=)` to generate a thumbnail image of video from any timestamp.
# ```python
# from IPython.display import Image
# image = video.generate_thumbnail(time=12.0)
# Image(url=image.url)
# ```
# ##### Delete a video:
# * `video.delete()` :deletes a video.
# ```python
# video.delete()
# ```
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# Checkout more examples and tutorials 👉 <a href="https://docs.videodb.io/build-with-videodb-35"> Build with VideoDB </a> to explore what you can build with VideoDB
# </div>
```
```python
# ⚡️ QuickStart: VideoDB
# [](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/VideoDB%20Quickstart.ipynb)
# This notebook provides a hands-on introduction to [VideoDB](https://videodb.io), demonstrating core functionalities such as uploading, viewing, indexing, and searching within video content.
# ### Setup
# ---
# #### 🔧 Install VideoDB
# Install the VideoDB Python package:
# ```python
# !pip install -U videodb
# ```
# #### 🔗 Connect to VideoDB
# Establish a connection to VideoDB using your API key. You can either pass the API key directly to the `connect` function or set the `VIDEO_DB_API_KEY` environment variable.
# > 💡 Get your API key from the [VideoDB Console](https://console.videodb.io). (Free for the first 50 uploads, no credit card required!).
# ```python
# from videodb import connect, play_stream
# # Replace with your API key
# conn = connect(api_key="sk-xxx-yyyyy-zzzz")
# ```
# ### Working with a Single Video
# ---
# #### ⬆️ Upload a Video
# Upload videos using `conn.upload()`. You can upload from a public URL or a local file path. The `upload` function returns a `Video` object, which provides access to various video methods.
# ```python
# # Upload a video by URL
# video = conn.upload(url="https://www.youtube.com/watch?v=wU0PYcCsL6o")
# ```
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# VideoDB simplifies uploads by supporting links from YouTube, S3, and any public URL with video content.
# </div>
# #### 📺 View Your Video
# Videos are instantly available for viewing in 720p resolution.
# * Generate a streamable URL using `video.generate_stream()`.
# * Preview the video using `video.play()`. This will open the video in your default browser or notebook.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> If you are viewing this notebook on GitHub, you won't be able to see the embedded video player due to security restrictions. Please copy and paste the printed stream URL into your browser to view the video.
# </div>
# ```python
# video.generate_stream()
# video.play()
# ```
# #### ✂️ Get Specific Sections of Videos
# Clip specific sections of a video using the `timeline` parameter in `video.generate_stream()`. The `timeline` accepts a list of start and end times (in seconds).
# For example, the following code will stream the first 10 seconds and then the 120th to 140th seconds of the uploaded video:
# ```python
# stream_link = video.generate_stream(timeline=[[0,10], [120,140]])
# play_stream(stream_link)
# ```
# #### 🔍 Indexing a Video
# Indexing enables searching within a video. Invoke the index function on the `Video` object. VideoDB currently offers two types of indexes:
# 1. `index_spoken_words()`: Indexes spoken words in the video by automatically generating a transcript. Supports 20+ languages. See [Language Support](https://docs.videodb.io/language-support-79) for more details.
# 2. `index_scenes()`: Indexes visual information and events in the video, enabling searching for scenes, activities, objects, and emotions. See [Scene Index Documentation](https://docs.videodb.io/scene-index-documentation-80) for details.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> Indexing can take time, especially for longer videos.
# </div>
# ```python
# # Index spoken content of the video.
# video.index_spoken_words()
# ```
# ```python
# # Index visual information in video frames. You can customize the prompt to fit your use case and index a video multiple times with different prompts.
# index_id = video.index_scenes(
# prompt="Describe the scene in strictly 100 words"
# )
# # Wait for indexing to finish and retrieve the scene index.
# scene_index = video.get_scene_index(index_id)
# scene_index
# ```
# #### 🔎 Searching within a Video
# Search indexed videos using `video.search()`. You can specify the search type and index type. VideoDB offers the following search types:
# * `SearchType.semantic`: Ideal for question-answering type queries. This is the default search type.
# * `SearchType.keyword`: Matches the exact occurrence of words or sentences in the query. Keyword search is only available for single videos.
# And the following index types:
# * `IndexType.scene`: Searches visual information from the scene index (created with `index_scenes()`).
# * `IndexType.spoken_word`: Searches spoken content from the spoken word index (created with `index_spoken_words()`).
# ```python
# from videodb import SearchType, IndexType
# result = video.search(query="what's the dream?", search_type=SearchType.semantic, index_type=IndexType.spoken_word)
# result.play()
# ```
# ```python
# # Try with different queries
# query = "mountains" # Example query: "city scene with buses"
# result = video.search(query=query, search_type=SearchType.semantic, index_type=IndexType.scene)
# result.play()
# ```
# ##### 📺 View Search Results
# `video.search()` returns a `SearchResults` object, which contains the sections or "shots" of the video that semantically match your search query.
# * `result.get_shots()`: Returns a list of `Shot` objects that matched the search query.
# * `result.play()`: Opens the video in your default browser/notebook and jumps to the most relevant section.
# ##### 🗑️ Cleanup
# You can delete the video from the database using `video.delete()`:
# ```python
# video.delete()
# ```
# ### RAG: Working with Multiple Videos
# ---
# `VideoDB` excels at storing and searching within multiple videos. By default, videos are uploaded to your default collection. You can create and manage additional collections; see the [Collections documentation](https://docs.videodb.io/collections-68) for details.
# If you're building a Retrieval-Augmented Generation (RAG) pipeline on your video data using LlamaIndex, you can leverage the VideoDB retriever. See the [LlamaIndex documentation](https://docs.llamaindex.ai/en/stable/examples/retrievers/videodb_retriever.html) for more information.
# ##### 🔄 Uploading Multiple Videos to a Collection
# ```python
# # Get the default collection
# coll = conn.get_collection()
# # Upload Videos to the collection
# coll.upload(url="https://www.youtube.com/watch?v=lsODSDmY4CY")
# coll.upload(url="https://www.youtube.com/watch?v=vZ4kOr38JhY")
# coll.upload(url="https://www.youtube.com/watch?v=uak_dXHh6s4")
# ```
# Useful collection methods:
# * `conn.get_collection()`: Returns the default `Collection` object.
# * `coll.get_videos()`: Returns a list of `Video` objects within the collection.
# * `coll.get_video(video_id)`: Returns a specific `Video` object from the collection, given its video ID.
# * `coll.delete_video(video_id)`: Deletes a video from the collection, given its video ID.
# ### 📂 Searching Across Multiple Videos in a Collection
# Index all videos in a collection and then use the `search` method on the collection to find relevant results across all videos. The following example indexes the spoken content of each video in a collection for a quick demonstration.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> Indexing can take time, especially for longer videos.
# </div>
# ```python
# # For simplicity, we'll just index the spoken content of each video.
# for video in coll.get_videos():
# video.index_spoken_words()
# print(f"Indexed {video.name}")
# ```
# ### 🔎 Searching Inside a Collection
# Search the collection using `coll.search()`:
# ```python
# # Search in the collection of videos
# results = coll.search(query = "Deep sleep")
# results.play()
# ```
# ```python
# results = coll.search(query= "What are the benefits of morning sunlight?")
# results.play()
# ```
# ```python
# results = coll.search(query= "What are Adaptogens?")
# results.play()
# ```
# #### 📺 View Search Results
# `coll.search()` returns a `SearchResults` object, which contains the sections or "shots" of the videos that semantically match your search query.
# * `result.get_shots()`: Returns a list of `Shot` objects that matched the search query.
# * `result.play()`: Opens the video in your default browser/notebook and jumps to the most relevant section.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# As you can see, VideoDB fundamentally removes the limitations of traditional file-based video management and empowers you to access and stream videos seamlessly. Stay tuned for exciting features in our upcoming releases and keep building amazing things with VideoDB! 🤘
# </div>
# ### 🌟 Explore More with the Video Object
# There are several other useful methods available on the `Video` object:
# #### Accessing the Transcript
# ```python
# # Access the transcript with timestamps (JSON format)
# text_json = video.get_transcript()
# # Access the plain text transcript
# text = video.get_transcript_text()
# print(text)
# ```
# #### Accessing Visual Scene Descriptions
# ```python
# # View the scene descriptions
# video.get_scene_index(index_id)
# ```
# #### Adding Subtitles to a Video
# This returns a new stream instantly with subtitles added to the video. The `add_subtitle()` function has styling parameters such as font, size, and background color. See the [Subtitle Styles notebook](https://github.com/video-db/videodb-cookbook/blob/main/guides/Subtitle.ipynb) for details.
# ```python
# new_stream = video.add_subtitle()
# play_stream(new_stream)
# ```
# #### Generating a Thumbnail for a Video
# Use `video.generate_thumbnail(time=)` to generate a thumbnail image from any timestamp in the video.
# ```python
# from IPython.display import Image
# image = video.generate_thumbnail(time=12.0)
# Image(url=image.url)
# ```
# ##### Deleting a Video
# * `video.delete()`: Deletes a video.
# ```python
# video.delete()
# ```
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# Explore more examples and tutorials at <a href="https://docs.videodb.io/build-with-videodb-35">Build with VideoDB</a> to discover the full potential of VideoDB!
# </div>
```
```python
# ⚡️ QuickStart: VideoDB
# [](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/VideoDB%20Quickstart.ipynb)
# This notebook provides a hands-on introduction to [VideoDB](https://videodb.io), demonstrating core functionalities such as uploading, viewing, indexing, and searching within video content.
# ### Setup
# ---
# #### 🔧 Install VideoDB
# Install the VideoDB Python package:
# ```python
# !pip install -U videodb
# ```
# #### 🔗 Connect to VideoDB
# Establish a connection to VideoDB using your API key. You can either pass the API key directly to the `connect` function or set the `VIDEO_DB_API_KEY` environment variable.
# > 💡 Get your API key from the [VideoDB Console](https://console.videodb.io). (Free for the first 50 uploads, no credit card required!).
# ```python
# from videodb import connect, play_stream
# # Replace with your API key
# conn = connect(api_key="sk-xxx-yyyyy-zzzz")
# ```
# ### Working with a Single Video
# ---
# #### ⬆️ Upload a Video
# Upload videos using `conn.upload()`. You can upload from a public URL or a local file path. The `upload` function returns a `Video` object, which provides access to various video methods.
# ```python
# # Upload a video by URL
# video = conn.upload(url="https://www.youtube.com/watch?v=wU0PYcCsL6o")
# ```
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# VideoDB simplifies uploads by supporting links from YouTube, S3, and any public URL with video content.
# </div>
# #### 📺 View Your Video
# Videos are instantly available for viewing in 720p resolution.
# * Generate a streamable URL using `video.generate_stream()`.
# * Preview the video using `video.play()`. This will open the video in your default browser or notebook.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> If you are viewing this notebook on GitHub, you won't be able to see the embedded video player due to security restrictions. Please copy and paste the printed stream URL into your browser to view the video.
# </div>
# ```python
# video.generate_stream()
# video.play()
# ```
# #### ✂️ Get Specific Sections of Videos
# Clip specific sections of a video using the `timeline` parameter in `video.generate_stream()`. The `timeline` accepts a list of start and end times (in seconds).
# For example, the following code will stream the first 10 seconds and then the 120th to 140th seconds of the uploaded video:
# ```python
# stream_link = video.generate_stream(timeline=[[0,10], [120,140]])
# play_stream(stream_link)
# ```
# #### 🔍 Indexing a Video
# Indexing enables searching within a video. Invoke the index function on the `Video` object. VideoDB currently offers two types of indexes:
# 1. `index_spoken_words()`: Indexes spoken words in the video by automatically generating a transcript. Supports 20+ languages. See [Language Support](https://docs.videodb.io/language-support-79) for more details.
# 2. `index_scenes()`: Indexes visual information and events in the video, enabling searching for scenes, activities, objects, and emotions. See [Scene Index Documentation](https://docs.videodb.io/scene-index-documentation-80) for details.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> Indexing can take time, especially for longer videos.
# </div>
# ```python
# # Index spoken content of the video.
# video.index_spoken_words()
# ```
# ```python
# # Index visual information in video frames. You can customize the prompt to fit your use case and index a video multiple times with different prompts.
# index_id = video.index_scenes(
# prompt="Describe the scene in strictly 100 words"
# )
# # Wait for indexing to finish and retrieve the scene index.
# scene_index = video.get_scene_index(index_id)
# scene_index
# ```
# #### 🔎 Searching within a Video
# Search indexed videos using `video.search()`. You can specify the search type and index type. VideoDB offers the following search types:
# * `SearchType.semantic`: Ideal for question-answering type queries. This is the default search type.
# * `SearchType.keyword`: Matches the exact occurrence of words or sentences in the query. Keyword search is only available for single videos.
# And the following index types:
# * `IndexType.scene`: Searches visual information from the scene index (created with `index_scenes()`).
# * `IndexType.spoken_word`: Searches spoken content from the spoken word index (created with `index_spoken_words()`).
# ```python
# from videodb import SearchType, IndexType
# result = video.search(query="what's the dream?", search_type=SearchType.semantic, index_type=IndexType.spoken_word)
# result.play()
# ```
# ```python
# # Try with different queries
# query = "mountains" # Example query: "city scene with buses"
# result = video.search(query=query, search_type=SearchType.semantic, index_type=IndexType.scene)
# result.play()
# ```
# ##### 📺 View Search Results
# `video.search()` returns a `SearchResults` object, which contains the sections or "shots" of the video that semantically match your search query.
# * `result.get_shots()`: Returns a list of `Shot` objects that matched the search query.
# * `result.play()`: Opens the video in your default browser/notebook and jumps to the most relevant section.
# ##### 🗑️ Cleanup
# You can delete the video from the database using `video.delete()`:
# ```python
# video.delete()
# ```
# ### RAG: Working with Multiple Videos
# ---
# `VideoDB` excels at storing and searching within multiple videos. By default, videos are uploaded to your default collection. You can create and manage additional collections; see the [Collections documentation](https://docs.videodb.io/collections-68) for details.
# If you're building a Retrieval-Augmented Generation (RAG) pipeline on your video data using LlamaIndex, you can leverage the VideoDB retriever. See the [LlamaIndex documentation](https://docs.llamaindex.ai/en/stable/examples/retrievers/videodb_retriever.html) for more information.
# ##### 🔄 Uploading Multiple Videos to a Collection
# ```python
# # Get the default collection
# coll = conn.get_collection()
# # Upload Videos to the collection
# coll.upload(url="https://www.youtube.com/watch?v=lsODSDmY4CY")
# coll.upload(url="https://www.youtube.com/watch?v=vZ4kOr38JhY")
# coll.upload(url="https://www.youtube.com/watch?v=uak_dXHh6s4")
# ```
# Useful collection methods:
# * `conn.get_collection()`: Returns the default `Collection` object.
# * `coll.get_videos()`: Returns a list of `Video` objects within the collection.
# * `coll.get_video(video_id)`: Returns a specific `Video` object from the collection, given its video ID.
# * `coll.delete_video(video_id)`: Deletes a video from the collection, given its video ID.
# ### 📂 Searching Across Multiple Videos in a Collection
# Index all videos in a collection and then use the `search` method on the collection to find relevant results across all videos. The following example indexes the spoken content of each video in a collection for a quick demonstration.
# <div style="background-color: #ffffcc; color: black; padding: 10px; border-radius: 5px;">
# <strong>Note:</strong> Indexing can take time, especially for longer videos.
# </div>
# ```python
# # For simplicity, we'll just index the spoken content of each video.
# for video in coll.get_videos():
# video.index_spoken_words()
# print(f"Indexed {video.name}")
# ```
# ### 🔎 Searching Inside a Collection
# Search the collection using `coll.search()`:
# ```python
# # Search in the collection of videos
# results = coll.search(query = "Deep sleep")
# results.play()
# ```
# ```python
# results = coll.search(query= "What are the benefits of morning sunlight?")
# results.play()
# ```
# ```python
# results = coll.search(query= "What are Adaptogens?")
# results.play()
# ```
# #### 📺 View Search Results
# `coll.search()` returns a `SearchResults` object, which contains the sections or "shots" of the videos that semantically match your search query.
# * `result.get_shots()`: Returns a list of `Shot` objects that matched the search query.
# * `result.play()`: Opens the video in your default browser/notebook and jumps to the most relevant section.
# ### 🌟 Explore More with the Video Object
# There are several other useful methods available on the `Video` object:
# #### Accessing the Transcript
# ```python
# # Access the transcript with timestamps (JSON format)
# text_json = video.get_transcript()
# # Access the plain text transcript
# text = video.get_transcript_text()
# print(text)
# ```
# #### Accessing Visual Scene Descriptions
# ```python
# # View the scene descriptions
# video.get_scene_index(index_id)
# ```
# #### Adding Subtitles to a Video
# This returns a new stream instantly with subtitles added to the video. The `add_subtitle()` function has styling parameters such as font, size, and background color. See the [Subtitle Styles notebook](https://github.com/video-db/videodb-cookbook/blob/main/guides/Subtitle.ipynb) for details.
# ```python
# new_stream = video.add_subtitle()
# play_stream(new_stream)
# ```
# #### Generating a Thumbnail for a Video
# Use `video.generate_thumbnail(time=)` to generate a thumbnail image from any timestamp in the video.
# ```python
# from IPython.display import Image
# image = video.generate_thumbnail(time=12.0)
# Image(url=image.url)
# ```
---
# IPYNB Notebook: Multimodal_Quickstart [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/quickstart/Multimodal_Quickstart.ipynb)
This was processed through custom_2.txt
---
# IPYNB Notebook: Subtitle [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/guides/Subtitle.ipynb)
```markdown
## Guide: Subtitles
[](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/nb/main/guides/video/Subtitle.ipynb)
## Adding Subtitles to Your Videos
---
This guide demonstrates how to customize subtitle styles using the `SubtitleStyle` class in VideoDB. We'll explore various configuration options and their visual outputs, covering:
* Typography and Style
* Color and Effects
* Positioning and Margins
* Text Transformation
* Borders and Shadow
## 🛠️ Setup
---
### 📦 Installing the VideoDB Package
```python
%pip install videodb
```
### 🔑 API Key Configuration
Before you begin, you'll need a VideoDB API key.
> Get your free API key (for the first 50 uploads, no credit card required!) from the [VideoDB Console](https://console.videodb.io). 🎉
Set the API key as an environment variable:
```python
import os
os.environ["VIDEO_DB_API_KEY"] = "" # Replace with your actual API key
```
### 🌐 Connecting to VideoDB
Establish a connection to VideoDB and access a collection:
```python
from videodb import connect
conn = connect()
coll = conn.get_collection()
```
### 🎥 Uploading a Video
Upload a base video to add subtitles. We'll use a sample video for this guide:
```python
video = coll.upload(url="https://www.youtube.com/watch?v=il39Ks4mV9g")
video.play()
```
Output should be a playable video within the notebook, directing to the VideoDB console player. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/ef6ef08c-b276-4e1d-b1d0-f0525e697d46.m3u8'
```
> ℹ️ You can also upload videos from your local file system by providing the `file_path` to the `upload()` method.
## 🔊 Indexing Spoken Words
---
To generate subtitles, first index the video's spoken words using `video.index_spoken_words()`:
```python
video.index_spoken_words()
```
A progress bar indicates the indexing process.
```
100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:32<00:00, 3.04it/s]
```
## 📝 Adding Default Subtitles
---
Add default subtitles to your video using `Video.add_subtitle()`. This method returns a streaming link:
```python
from videodb import play_stream
# Add subtitles to the video
stream_url = video.add_subtitle()
# Play the video with subtitles
play_stream(stream_url)
```
Output should be a playable video within the notebook, directing to the VideoDB console player with subtitles. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/76e0206d-b3af-4a74-9628-54636bf22ddf.m3u8'
```
## 📝 Customizing Subtitle Styles
---
To customize the subtitle style, pass a `SubtitleStyle()` object, configured with your desired styles, to the `Video.add_subtitle()` method.
> ℹ️ Refer to the [SubtitleStyle API Reference](link_to_api_reference - *replace with actual link*) for a complete list of available options.
### 1. Typography and Style
Configure the typography of the subtitles using the following parameters in the `SubtitleStyle()` class:
* `font_name`: The font to use (e.g., "Roboto").
* `font_size`: The font size in pixels.
* `spacing`: Character spacing in pixels.
* `bold`: `True` for bold text, `False` otherwise.
* `italic`: `True` for italic text, `False` otherwise.
* `underline`: `True` for underlined text, `False` otherwise.
* `strike_out`: `True` for strikethrough text, `False` otherwise.
```python
from videodb import SubtitleStyle
stream_url = video.add_subtitle(
SubtitleStyle(
font_name="Roboto",
font_size=12,
spacing=0,
bold=False,
italic=False,
underline=False,
strike_out=False,
)
)
play_stream(stream_url)
```
Output should be a playable video within the notebook, directing to the VideoDB console player with the specified typography. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/86d9e2a6-b0d9-4333-9013-bf355fea051d.m3u8'
```

### 2. Color and Effects
Customize the colors of the subtitles using the following parameters:
* `primary_colour`: The main text color.
* `secondary_colour`: Color for karaoke effects or secondary highlighting.
* `outline_colour`: The text outline color.
* `back_colour`: The subtitle background color.
> **ℹ️ Color Format**
>
> `SubtitleStyle` accepts colors in the `&HBBGGRR` hexadecimal format, where BB, GG, and RR represent the blue, green, and red components, respectively. The `&H` prefix is required. For transparency, include an alpha value at the beginning: `&HAABBGGRR`. (AA is the alpha value).
```python
from videodb import SubtitleStyle
stream_url = video.add_subtitle(
SubtitleStyle(
primary_colour="&H00A5CFFF",
secondary_colour="&H00FFFF00",
outline_colour="&H000341C1",
back_colour="&H803B3B3B",
)
)
play_stream(stream_url)
```
Output should be a playable video within the notebook, directing to the VideoDB console player with the specified colors. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/f59f13f4-d2ac-4589-83b7-58cdbb8e9154.m3u8'
```

### 3. Position and Margins
Configure the alignment and position of the subtitles using the following parameters:
* `alignment`: The alignment of the subtitle (use `SubtitleAlignment` enum).
* `margin_l`: Left margin in pixels.
* `margin_r`: Right margin in pixels.
* `margin_v`: Top and bottom margin in pixels.
> ℹ️ See the [API Reference](link_to_api_reference - *replace with actual link*) for details on `SubtitleAlignment`.
```python
from videodb import SubtitleStyle, SubtitleAlignment
stream_url = video.add_subtitle(
SubtitleStyle(
alignment=SubtitleAlignment.middle_center,
margin_l=10,
margin_r=10,
margin_v=20,
)
)
play_stream(stream_url)
```
Output should be a playable video within the notebook, directing to the VideoDB console player with the specified position and margins. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/d32a4ae4-e19f-4ca9-9438-4d7b94e327b2.m3u8'
```

### 4. Text Transformation
Transform the text size and spacing using the following parameters:
* `scale_x`: Horizontal scaling factor.
* `scale_y`: Vertical scaling factor.
* `angle`: Rotation angle in degrees.
```python
from videodb import SubtitleStyle
stream_url = video.add_subtitle(
SubtitleStyle(
scale_x=1.5,
scale_y=3,
angle=0,
)
)
play_stream(stream_url)
```
Output should be a playable video within the notebook, directing to the VideoDB console player with the specified transformations. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/f7ebe6d2-a181-46ad-aae3-e824446dc2a4.m3u8'
```

### 5. Borders and Shadow
Add border styles, outlines, and shadows using the following parameters:
* `border_style`: The border style (use `SubtitleBorderStyle` enum).
* `outline`: The width of the text outline in pixels.
* `shadow`: The depth of the shadow behind the text in pixels.
> ℹ️ See the [API Reference](link_to_api_reference - *replace with actual link*) for details on `SubtitleBorderStyle`.
```python
from videodb import SubtitleStyle, SubtitleBorderStyle
stream_url = video.add_subtitle(
SubtitleStyle(
shadow=2,
back_colour="&H00000000",
border_style=SubtitleBorderStyle.no_border,
)
)
play_stream(stream_url)
```
Output should be a playable video within the notebook, directing to the VideoDB console player with the specified border and shadow. Example:
```
'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/cbbc8812-0fcf-467f-aac6-1976582146bd.m3u8'
```

## 👨💻 Next Steps
---
Explore other VideoDB subtitle features and resources:
* [Enhancing Video Captions with VideoDB Subtitle Styling](https://coda.io/d/_dnIYgjBK4eB/_sulRy)
If you have any questions or feedback, feel free to reach out:
* [Discord](https://discord.gg/py9P639jGz)
* [GitHub](https://github.com/video-db)
* [VideoDB](https://videodb.io)
* Email: ashu@videodb.io
---
# IPYNB Notebook: Cleanup [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/guides/Cleanup.ipynb)
```markdown
## Guide: Cleaning Up Your VideoDB Account
<a href="https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/guides/Cleanup.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
⚠️ **WARNING: This notebook will permanently delete media files from your VideoDB account. Data loss is irreversible.** ⚠️
🚨 **IMPORTANT: Before proceeding, carefully review the media files you intend to delete. This action cannot be undone.** 🚨
This guide explains how to remove media files and reclaim storage space within your VideoDB account. It covers:
* Deleting videos
* Deleting audio files
* Deleting images
## 🛠️ Setup
---
Before you begin, ensure you have your [VideoDB](https://videodb.io) API key available.
```python
%pip install videodb
```
```python
import os
from videodb import connect
os.environ["VIDEO_DB_API_KEY"] = "YOUR_KEY_HERE" # Replace with your actual API key
conn = connect()
```
## Review Collections
---
This section displays information about your collections and the number of media assets within each.
```python
colls = conn.get_collections()
print(f"Found {len(colls)} collections:\n")
for coll in colls:
videos = coll.get_videos()
audios = coll.get_audios()
images = coll.get_images()
print(f"Collection Name: '{coll.name}' (ID: {coll.id})")
print(f" - Videos : {len(videos)}")
print(f" - Audio : {len(audios)}")
print(f" - Images : {len(images)}\n")
```
## Select the Target Collection
---
Specify the ID of the collection you wish to clean up.
```python
collection_id = "YOUR_COLLECTION_ID_HERE" # Replace with the ID of the collection you want to clean.
```
### ⚠️ Delete All Videos
---
**Irreversibly deletes all videos from the selected collection. Use with extreme caution!**
```python
coll = conn.get_collection(collection_id)
videos = coll.get_videos()
for video in videos:
video.delete()
print(f"Deleted video: {video.name} (ID: {video.id})")
print("Video deletion complete.")
```
### ⚠️ Delete All Audio
---
**Irreversibly deletes all audio files from the selected collection. Use with extreme caution!**
```python
coll = conn.get_collection(collection_id)
audios = coll.get_audios()
for audio in audios:
audio.delete()
print(f"Deleted audio: {audio.name} (ID: {audio.id})")
print("Audio deletion complete.")
```
### ⚠️ Delete All Images
---
**Irreversibly deletes all images from the selected collection. Use with extreme caution!**
```python
coll = conn.get_collection(collection_id)
images = coll.get_images()
for image in images:
image.delete()
print(f"Deleted image: {image.name} (ID: {image.id})")
print("Image deletion complete.")
```
---
# IPYNB Notebook: TextAsset [Source Link](https://github.com/video-db/videodb-cookbook/blob/main/guides/TextAsset.ipynb)
```python
# @title Open In Colab
# @markdown [](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/nb/main/guides/asset/TextAsset.ipynb)
# Guide: Text Assets
## Overview
This guide introduces `TextAssets` and demonstrates how to overlay text elements on videos using VideoDB. We'll explore customizable configurations for `TextAssets`, including:
* Default Styling
* Font Styling
* Background Box Styling
* Text Shadowing
* Position and Alignment
## Setup
---
### 📦 Installing the VideoDB Package
```python
%pip install videodb
```
### 🔑 API Key
Before proceeding, ensure you have access to VideoDB.
> Get your API key from the [VideoDB Console](https://console.videodb.io). (Free for the first 50 uploads, no credit card required! 🎉)
```python
import os
os.environ["VIDEO_DB_API_KEY"] = "" # @param {type:"string"}
```
### 🌐 Connecting to VideoDB
```python
from videodb import connect
conn = connect()
coll = conn.get_collection()
```
### 🎥 Uploading a Video
VideoDB utilizes videos as the foundation for creating timelines. For more information, refer to [Timelines and Assets](https://docs.videodb.io/timeline-and-assets-44).
```python
video = coll.upload(url="https://www.youtube.com/watch?v=w4NEOTvstAc")
video.play()
```
## Creating Assets
---
Now, let's create the assets that will be used in our video timeline:
* `VideoAsset`: The base video for the timeline.
* `TextAsset`: The text element to be overlaid on the video.
> Checkout [Timeline and Assets](https://docs.videodb.io/timeline-and-assets-44) for conceptual understanding.
### 🎥 VideoAsset
---
```python
from videodb.asset import VideoAsset
# Create a VideoAsset from the uploaded video
video_asset = VideoAsset(asset_id=video.id, start=0, end=60)
```
### 🔠 TextAsset: Default Styling
---
To create a `TextAsset`, use the `TextAsset` class.
**Parameters:**
* `text` (required): The text to be displayed.
* `duration` (optional): The duration (in seconds) for which the text element should be displayed.
```python
from videodb.asset import TextAsset
text_asset_1 = TextAsset(text="THIS IS A SENTENCE", duration=5)
```

### 🔡 TextAsset: Custom Styling
To create a `TextAsset` with custom styling, use the `style` parameter, which accepts a `TextStyle` instance.
> View API Reference for [`TextStyle`](link to TextStyle documentation - if available)
**1. Font Styling**
```python
from videodb.asset import TextAsset, TextStyle
# Create TextAsset with custom font styling using TextStyle
text_asset_2 = TextAsset(
text="THIS IS A SENTENCE",
duration=5,
style=TextStyle(
font="Inter",
fontsize=50,
fontcolor="#FFCFA5",
bordercolor="#C14103",
borderw="2",
box=False,
),
)
```

**2. Configuring Background Box**
```python
from videodb.asset import TextAsset, TextStyle
# Create TextAsset with custom background box styling using TextStyle
text_asset_3 = TextAsset(
text="THIS IS A SENTENCE",
duration=5,
style=TextStyle(
box=True,
boxcolor="#FFCFA5",
boxborderw=10,
boxw=0,
boxh=0,
),
)
```

**3. Configuring Shadows**
```python
from videodb.asset import TextAsset, TextStyle
# Create TextAsset with custom shadow styling using TextStyle
text_asset_4 = TextAsset(
text="THIS IS A SENTENCE",
duration=5,
style=TextStyle(
shadowcolor="#0AA910",
shadowx="2",
shadowy="3",
),
)
```

**4. Position and Alignment**
```python
from videodb.asset import TextAsset, TextStyle
text_asset_5 = TextAsset(
text="THIS IS A SENTENCE",
duration=5,
style=TextStyle(
x=50,
y=50,
y_align="text",
text_align="T+L",
boxcolor="#FFCFA5",
boxh=100,
boxw=600,
),
)
text_asset_6 = TextAsset(
text="THIS IS A SENTENCE",
duration=5,
style=TextStyle(
x=50,
y=50,
y_align="text",
text_align="M+C",
boxcolor="#FFCFA5",
boxh=100,
boxw=600,
),
)
text_asset_7 = TextAsset(
text="THIS IS A SENTENCE",
duration=5,
style=TextStyle(
x=50,
y=50,
y_align="text",
text_align="B+R",
boxcolor="#FFCFA5",
boxh=100,
boxw=600,
),
)
```


## Viewing the Results
---
### 🎼 Creating a Timeline Using `Timeline`
```python
from videodb.timeline import Timeline
# Initialize a Timeline
timeline = Timeline(conn)
# Add the base VideoAsset inline
timeline.add_inline(video_asset)
# TextAsset with default Styling
timeline.add_overlay(0, text_asset_1)
# TextAsset with Custom Font Styling
timeline.add_overlay(5, text_asset_2)
# TextAsset with Custom Border Box
timeline.add_overlay(10, text_asset_3)
# TextAsset with Custom Shadow
timeline.add_overlay(15, text_asset_4)
# TextAsset with Custom Position and alignment
timeline.add_overlay(20, text_asset_5)
timeline.add_overlay(25, text_asset_6)
timeline.add_overlay(30, text_asset_7)
```
### ▶️ Playing the Video
```python
from videodb import play_stream
stream_url = timeline.generate_stream()
play_stream(stream_url)
```
Key improvements in this version:
* **Clarity and Conciseness:** Removed unnecessary phrases and repetitions. Reworded sentences for better flow and understanding.
* **Improved Explanations:** Added more context and explanations, especially around parameters and their effects.
* **Consistent Terminology:** Ensured consistent use of terms like "parameters" and "styling."
* **Organization:** Improved the overall organization of the guide with more descriptive section headers.
* **Comments in Code:** Added helpful comments within the code blocks.
* **Removed "Bluff"**: Removed any inflated or marketing-like language. Focused on clear and direct explanation.
* **Placeholder for Documentation Link:** Added a placeholder for a link to the `TextStyle` API documentation. This is very important to provide a good user experience.
* **`# @param {type:"string"}`**: Added the Colab form field definition for the API key, making it directly usable in Colab.
* **Descriptive Alt Text**: Clarified image descriptions for improved accessibility.
* **Corrected Terminology**: Switched from "Text Element" to TextAsset and made sure parameters were explained in detail.
This revised version provides a much clearer, more concise, and more user-friendly guide to using TextAssets in VideoDB.
---
