
Allows audio generation (speech and music) with support for background execution mode and automatic playback offers.
Provides access to GitHub's 35 tools for managing issues, pull requests, and repositories through semantic search and routing.
Provides access to Modal's sandbox environment for compute tasks including video generation and ffmpeg transformations.
Uses OpenAI's API for generating embeddings, tool descriptions, and image descriptions through vision models.
Enables interaction with Slack's 11 tools for messaging and workspace management through the semantic router interface.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@OmniMCPsearch for tools to create a new GitHub issue"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
OmniMCP
Semantic router for MCP ecosystems
Discover and execute tools across multiple MCP servers without context bloat




The Problem
MCP tool definitions consume tokens fast. A typical setup:
Server | Tools | Tokens |
GitHub | 35 | ~26K |
Slack | 11 | ~21K |
Filesystem | 8 | ~5K |
Database | 12 | ~8K |
That's 60K+ tokens before the conversation starts. Add more servers and you're competing with your actual context.
Why this matters
Context bloat kills performance. When tool definitions consume 50-100K tokens, you're left with limited space for actual conversation, documents, and reasoning. The model spends attention on tool schemas instead of your task.
More tools = more hallucinations. With 50+ similar tools (like notification-send-user vs notification-send-channel), models pick wrong tools and hallucinate parameters. Tool selection accuracy drops as the toolset grows.
Dynamic tool loading breaks caching. Loading tools on-demand during inference seems smart, but it invalidates prompt caches. Every new tool added mid-conversation means reprocessing the entire context. Your "optimization" becomes a performance tax.
Tool results bloat context too. A single file read can return 50K tokens. An image is 1K+ tokens base64-encoded. These pile up in conversation history, pushing out earlier context.
The Solution
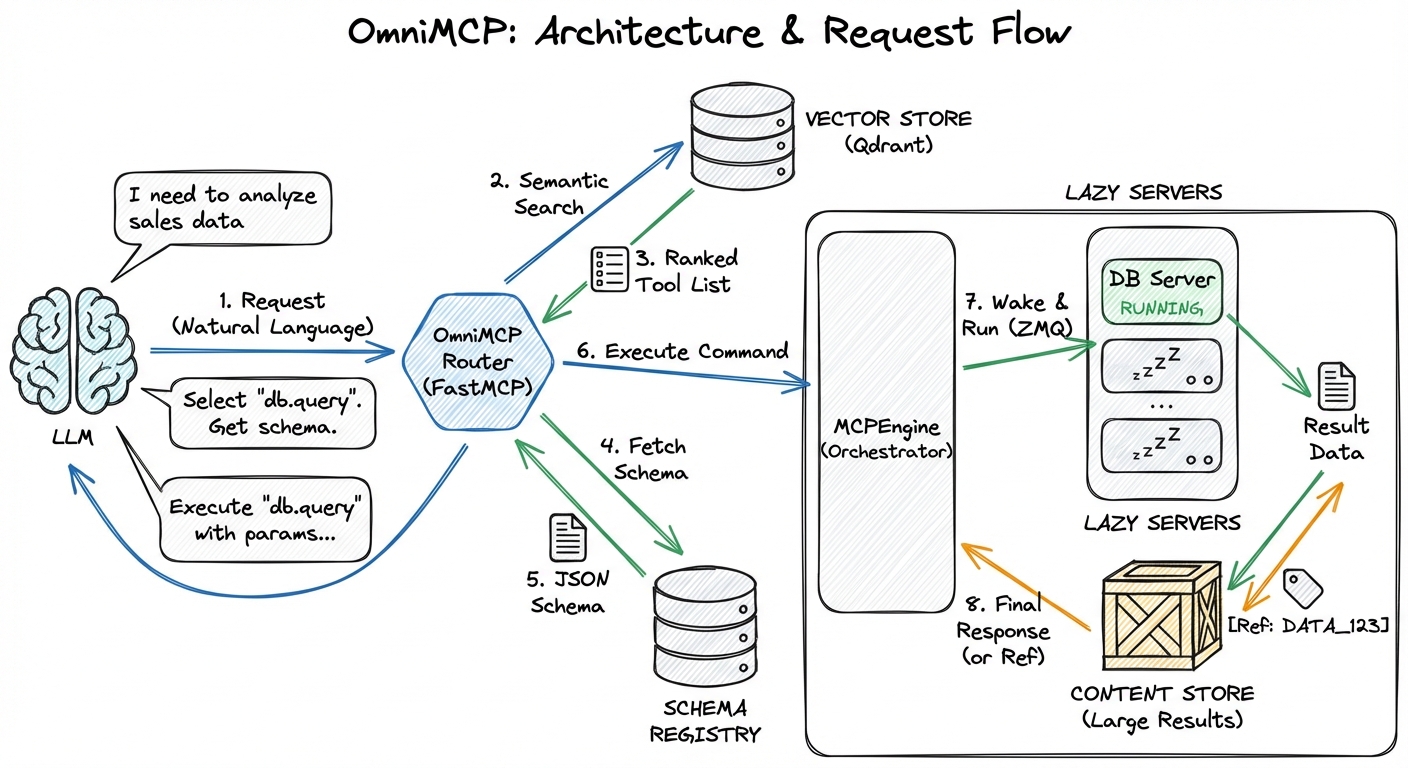
OmniMCP exposes a single as the only entry point to your entire MCP ecosystem. The LLM never sees individual tool definitions—just one unified interface.
How it works:
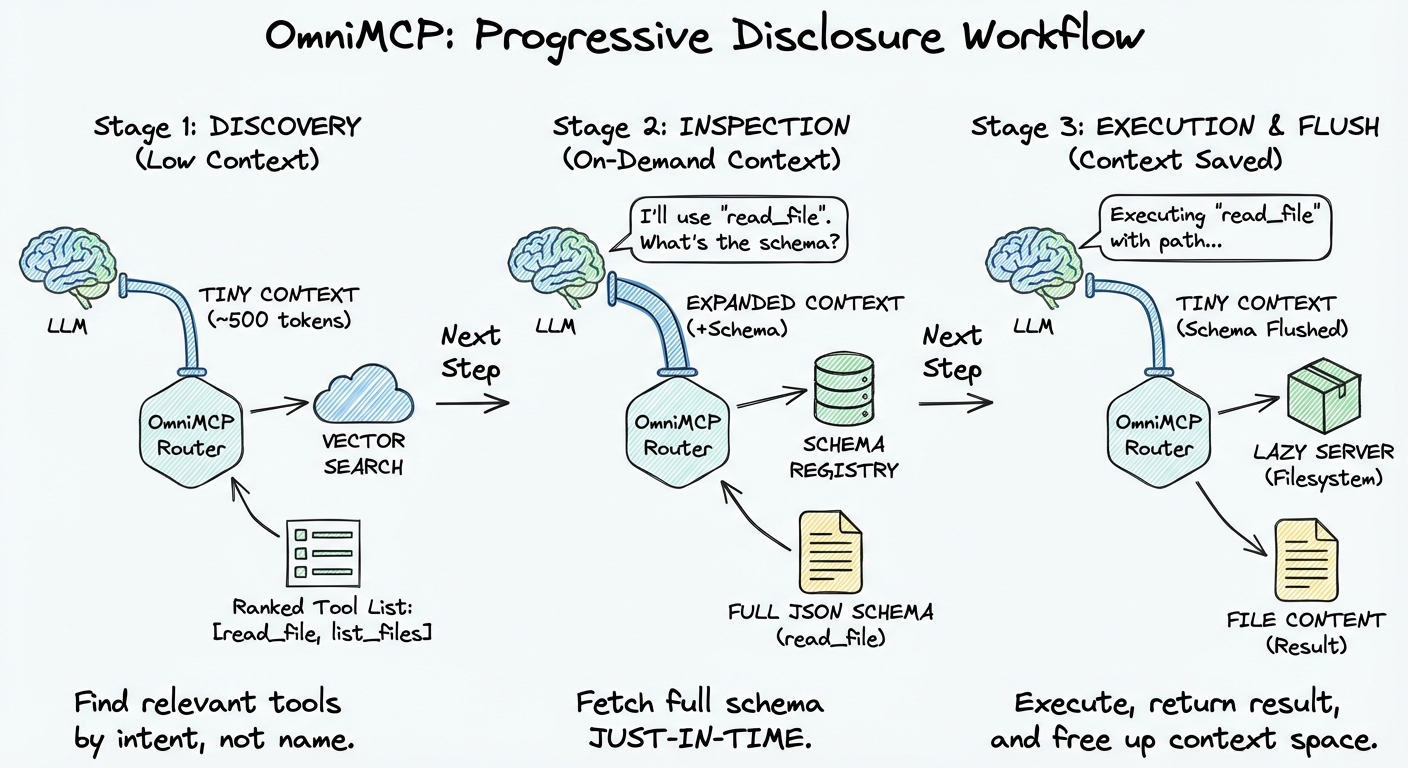
Semantic search → Find relevant tools by intent, not name. Tools are pre-indexed with embeddings, searched at runtime, returned as text results (not tool definitions)
Lazy server loading → Servers start only when needed, shutdown when done
Progressive schema loading → Full JSON schema fetched only before execution, returned as text in conversation
Content offloading → Large results chunked, images described, stored for retrieval
Key insight: Tool schemas appear in conversation text, not in tool definitions. This means:
Prompt caching stays intact (tool definition never changes)
Only relevant schemas enter context (via search results)
No hallucination from similar tool names (model sees 3-5 tools, not 50+)
From ~60K tokens to ~3K. Access to everything, cost of almost nothing.
Architecture: Meta-Tool Pattern
OmniMCP uses the meta-tool pattern, similar to Claude Code's Agent Skills system. Instead of exposing dozens of individual tools, it exposes a single semantic_router meta-tool that acts as a gateway to your entire MCP ecosystem.
Progressive Disclosure Workflow
Architecture & Request Flow
How It Works
Traditional MCP approach:
❌ Problems: Context bloat, tool hallucination, no caching
OmniMCP's meta-tool approach:
✅ Benefits: Single tool definition, server list in description, dynamic discovery
Parallel to Claude Skills
Claude Skills and OmniMCP share the same architectural insight:
Aspect | Claude Skills | OmniMCP |
Meta-tool |
|
|
Discovery | Skill descriptions in tool description | Server list + hints in tool description |
Invocation |
|
|
Context injection | Skill instructions loaded on invocation | Tool schemas fetched on-demand, returned as text |
Cache-friendly | Tool definition never changes | Tool definition never changes |
Dynamic list |
|
|
Behavioral hints | Skill descriptions guide LLM | Server |
Key insight: Both systems inject instructions through prompt expansion rather than traditional function calling. The tool description becomes a dynamic directory that the LLM reads and reasons about, while actual execution details are loaded lazily.
Example of behavioral guidance:
Claude Skills:
OmniMCP hints:
Both inject behavioral instructions that shape how the LLM uses the tools, not just what they do.
Real-World Example
Multi-server orchestration in action:
Claude Code generated a video using OmniMCP(previously pulsar-mcp) to coordinate multiple MCP servers.
The process:
Exa (background mode) - Parallel web searches to gather latest news
Modal Sandbox - Computed and generated video from news data
Filesystem - Retrieved the video file from Modal's output
ffmpeg - Transformed video to GIF format
The workflow:
What this demonstrates:
Semantic discovery - Finding the right tools across servers without knowing their exact names
Background execution - Parallel Exa searches without blocking the conversation
Cross-server coordination - Modal → Filesystem → Modal pipeline with automatic state management
Single interface - All operations through one
semantic_routertool
Without OmniMCP: 50+ tool definitions, complex orchestration, context overflow. With OmniMCP: Discover → Execute → Coordinate. Seamlessly.
Installation
Configuration
Environment Variables
OmniMCP requires several environment variables to operate. You must configure these before running index or serve commands.
Required variables:
Variable | Description | Example |
| OpenAI API key for embeddings and descriptions |
|
| Path for storing offloaded content (large results, images) |
|
Qdrant connection (choose ONE mode):
Mode | Variables | Description |
Local file |
| Embedded Qdrant, persists to disk |
In-memory |
| Embedded Qdrant, no persistence (testing) |
Remote server |
| Docker or self-hosted Qdrant |
Qdrant Cloud |
| Managed Qdrant Cloud |
Optional variables (with defaults):
Variable | Default | Description |
|
| OpenAI embedding model |
|
| Model for generating tool descriptions |
|
| Model for describing images |
|
| Chunk threshold for large results |
|
| Use vision to describe images |
|
| Embedding dimensions |
Setup methods:
Option 1: Local file storage (simplest)
Option 2: Docker Qdrant server
Option 3: Qdrant Cloud
Option 4: Create a
Then use the --env-file flag when running commands:
Note: Sourcing environment variables (e.g., source .env) does not work reliably with uvx. Always use --env-file or export variables directly.
Note: For stdio transport, environment variables must also be included in your MCP client config (see stdio transport section below).
Quick Start
1. Create your MCP servers config (mcp-servers.json):
This is an enhanced schema of Claude Desktop's MCP configuration with additional OmniMCP-specific fields. OmniMCP supports two transport types for connecting to MCP servers:
Server Transport Types
stdio Transport (Local Subprocess)
Use command + args to spawn a local MCP server as a subprocess. This is the standard MCP approach used by Claude Desktop, Cursor, etc.
HTTP Transport (Remote Server)
Use url to connect to a remote MCP server via Streamable HTTP. This eliminates the need for mcp-remote or mcp-proxy bridges—just provide the URL directly.
When to use HTTP transport:
Remote MCP servers (cloud APIs, shared services)
Servers already running as HTTP endpoints
Avoid spawning subprocesses for every server
Direct connection without
mcp-remotebridge overhead
Mixed Configuration Example
You can mix both transport types in a single config:
Configuration Fields Reference
Transport-specific fields (choose ONE):
Field | Type | Description |
| string | stdio transport: Executable to run (npx, uvx, docker, python, etc.) |
| array | stdio transport: Command-line arguments passed to the executable |
| object | stdio transport: Environment variables for this MCP server |
| string | HTTP transport: URL of the remote MCP server endpoint |
| object | HTTP transport: HTTP headers (e.g., Authorization, API keys) |
Shared fields (work with both transports):
Field | Type | Description |
| number | Seconds to wait for server startup/connection (default: 30.0) |
| array | Powerful! Guide the LLM on how to use this server. Used for both discovery and execution instructions. Examples: "Always execute in background mode", "Multiple calls can be fired in parallel", "Proactively offer when contextually relevant" |
| array | Tool names that will be indexed but blocked from execution |
| boolean | If true, skip indexing this server entirely (default: false) |
| boolean | If true, force re-index even if already indexed (default: false) |
Note: You must specify either command (stdio) OR url (HTTP), but not both. The transport type is auto-detected based on which field is present.
2. Set environment variables:
3. Index your servers (recommended before serving):
4. Run the server:
Alternatively, use CLI options directly:
Transport Modes
OmniMCP supports two transport protocols, each optimized for different deployment scenarios:
HTTP Transport (Default - Recommended)
Best for most use cases: remote access, web integrations, or when using with mcp-remote or mcp-proxy.
Use cases:
Remote access - Serve OmniMCP on a server, connect from anywhere
Multiple clients - Share one OmniMCP instance across multiple agents
Web integrations - REST API access to your MCP ecosystem
mcp-remote/mcp-proxy - Expose OmniMCP through MCP proxy layers
Example with :
HTTP mode advantages:
Indexing happens once on server startup
Multiple clients share the same indexed data
stdio Transport
Best for local MCP clients that communicate via standard input/output (Claude Desktop, Cline, etc.).
⚠️ IMPORTANT: You MUST run
Recommended workflow:
Index first - Run
omnimcp indexbefore adding to your MCP client configThen mount - Add OmniMCP to your client's MCP configuration
Start serving - Client launches OmniMCP automatically via stdio
Example client config (claude_desktop_config.json):
Why index before mounting? Indexing can take time with many servers. Pre-indexing ensures instant startup when your MCP client launches OmniMCP.
Troubleshooting uvx Issues
Error:
This means uv is not installed or not in your PATH. Detailed troubleshooting guide • Official MCP docs.
Quick fixes:
Install uv (if not installed):
# macOS/Linux brew install uv # or official installer curl -LsSf https://astral.sh/uv/install.sh | shEnsure uv is in PATH (macOS/Linux):
# Check if installed which uvx # If not found, add to PATH (add to ~/.zshrc or ~/.bashrc) export PATH="$HOME/.local/bin:$PATH" # Or create symlink sudo ln -s ~/.local/bin/uvx /usr/local/bin/uvxUse absolute path in config (find with
which uvx):"command": "/Users/you/.local/bin/uvx" // macOS "command": "C:\\Users\\you\\.local\\bin\\uvx.exe" // Windows
Alternative: Use mcp-remote for HTTP mode
If uvx issues persist, run OmniMCP via HTTP and connect through mcp-remote:
This bypasses stdio issues and works reliably across platforms.
How It Works
OmniMCP exposes a single semantic_router tool that acts as a gateway to your entire MCP ecosystem:
Operations
Operation | Description |
| Semantic search across all indexed tools |
| View server capabilities and limitations |
| Browse tools on a specific server |
| Get full schema before execution |
| Start or shutdown server instances |
| Show active servers |
| Run tools with optional background mode |
| Check background task status |
| Retrieve offloaded content by reference |
Content Management
Large tool results are automatically handled:
Text > 5000 tokens → Chunked, preview returned with reference ID
Images → Offloaded, described with GPT-4 vision, reference returned
Audio → Offloaded, reference returned
Retrieve full content with get_content(ref_id, chunk_index).
Background Execution
For long-running tools:
Docker
OmniMCP can be run in a Docker container with full support for both npx (Node.js MCP servers) and uvx (Python MCP servers).
Pull from Docker Hub
Build Locally (Optional)
Run
With local Qdrant storage:
With remote Qdrant (Cloud or Docker):
Environment file (.env.docker) - choose ONE Qdrant mode:
Available commands:
Development
Related Research
OmniMCP builds on emerging research in scalable tool selection for LLM agents:
ScaleMCP: Dynamic and Auto-Synchronizing Model Context Protocol Tools
Lumer et al. (2025) introduce ScaleMCP, addressing similar challenges in MCP tool selection at scale. Their approach emphasizes:
Dynamic tool retrieval - Giving agents autonomy to discover and add tools during multi-turn interactions
Auto-synchronizing storage - Using MCP servers as the single source of truth via CRUD operations
Tool Document Weighted Average (TDWA) - Novel embedding strategy that selectively emphasizes critical tool document components
Their evaluation across 5,000 financial metric servers demonstrates substantial improvements in tool retrieval and agent invocation performance, validating the importance of semantic search in MCP ecosystems.
Key insight: Both OmniMCP and ScaleMCP recognize that traditional monolithic tool repositories don't scale. The future requires dynamic, semantic-first approaches to tool discovery.
Anthropic's Advanced Tool Use
Anthropic's Tool Search feature (2025) introduces three capabilities that align with OmniMCP's architecture:
Tool Search Tool - Discover thousands of tools without consuming context window
Programmatic Tool Calling - Invoke tools in code execution environments to reduce context impact
Tool Use Examples - Learn correct usage patterns beyond JSON schema definitions
Quote from Anthropic: "Tool results and definitions can sometimes consume 50,000+ tokens before an agent reads a request. Agents should discover and load tools on-demand, keeping only what's relevant for the current task."
This mirrors OmniMCP's core philosophy: expose minimal interface upfront (single semantic_router tool), discover tools semantically, load schemas progressively.
Convergent Evolution
These independent efforts converge on similar principles:
Semantic discovery over exhaustive enumeration
Progressive loading over upfront tool definitions
Agent autonomy to query and re-query tool repositories
Context efficiency as a first-class design constraint
OmniMCP implements these principles through semantic routing, lazy server loading, and content offloading—making large-scale MCP ecosystems practical today.
License
MIT License - see LICENSE for details.
Built after several months of research and development
Multiple architectural iterations • Real-world agent deployments • Extensive testing across diverse MCP ecosystems
OmniMCP emerged from solving actual problems in production agent systems where traditional approaches failed. Every feature—from semantic routing to background execution to content offloading—was battle-tested against the challenges of scaling MCP ecosystems beyond toy examples.
We hope OmniMCP will be useful to the community in building more capable and efficient agent systems.
{kind=link}
{kind=link}
{kind=link}