
Allows AI agents to interact with Canvas LMS by finding relevant resources, retrieving course information, accessing modules and module items, getting file URLs, with planned features for calendar events, assignments, and various analysis capabilities.
Integrates with Google's Gemini API for AI-powered features, specifically for finding relevant resources in Canvas LMS based on natural language queries.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@Canvas MCP - College and High School Coursesshow me upcoming assignments for my calculus course"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
Canvas MCP
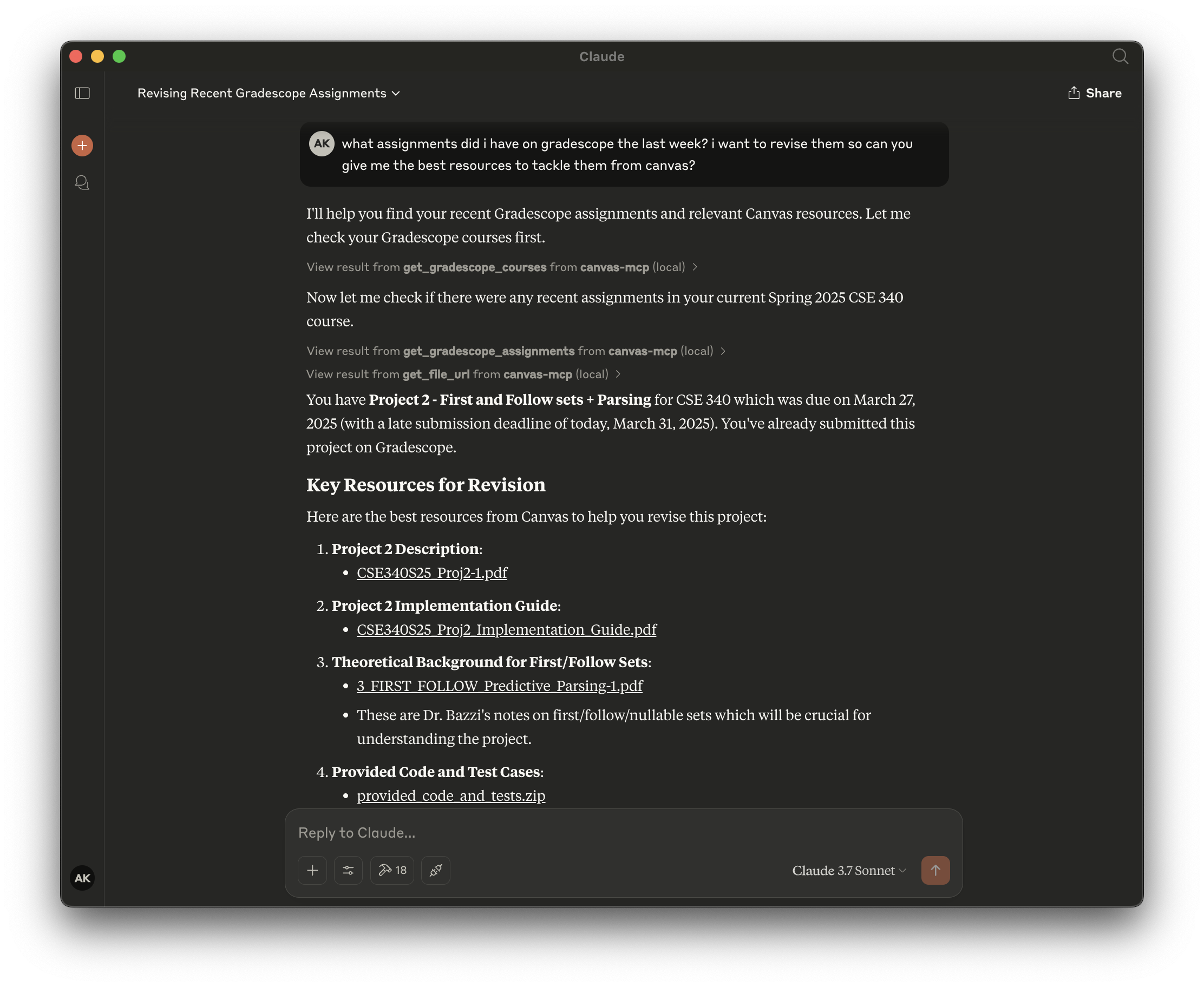
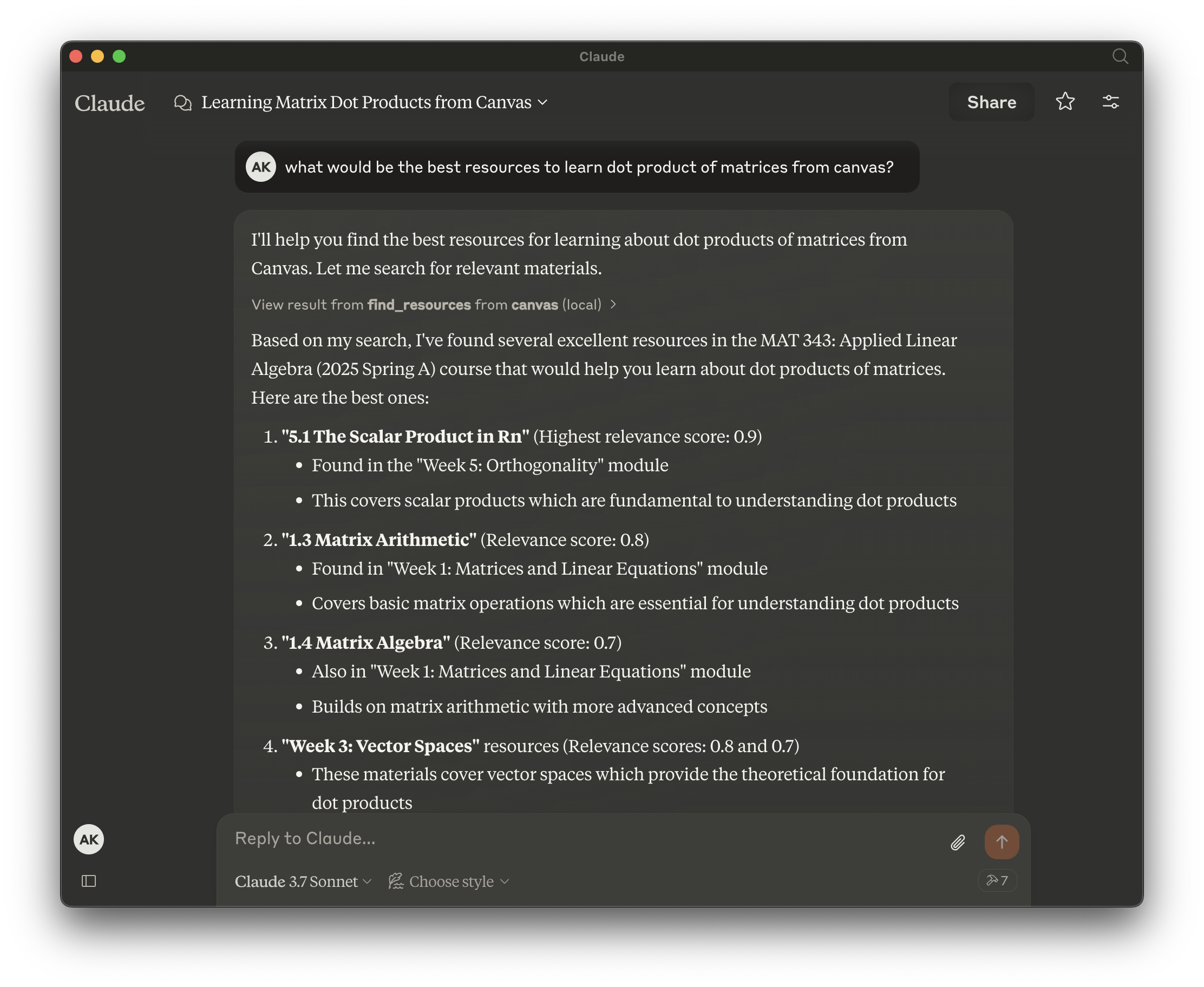
Canvas MCP is a set of tools that allows your AI agents to interact with Canvas LMS and Gradescope.
Features
Find relevant resources - Ability to find relevant resources for a given query in natural language!
Query upcoming assignments - Not only fetch upcoming assignments, but also provide its breakdown for a given course.
Get courses and assignments from Gradescope - Query your Gradescope courses and assignments with natural language, get submission status, and more!
Get courses
Get modules
Get module items
Get file url
Get calendar events
Get assignments
and so much more...
Related MCP server: Canvas MCP Server
Usage
Note down the following beforehand:
Canvas API Key from
Canvas > Account > Settings > Approved Integrations > New Access TokenGradescope Email and Password https://www.gradescope.com/
Installing via Smithery (Preferred)
To install Canvas MCP for Claude Code via Smithery:
Or, for Cursor IDE to use canvas-mcp with other models:
Or, for ChatGPT:
Enable Developer Mode in settings, if not already enabled
Go to
ChatGPT Settings > Connectorsand click Create to add this server URL:https://canvas-mcp--aryankeluskar.run.tools
Manual Configuration (ONLY for local instances)
Create a .env file in the root directory with the following environment variables:
Add the following to your mcp.json or claude_desktop_config.json file:
Built by Aryan Keluskar :)