<p align="center">
<img src="https://raw.githubusercontent.com/aitytech/agentkits-memory/main/assets/logo.svg" alt="AgentKits Logo" width="80" height="80">
</p>
<h1 align="center">AgentKits Memory</h1>
<p align="center">
<em>par <strong>AityTech</strong></em>
</p>
<p align="center">
<a href="https://www.npmjs.com/package/@aitytech/agentkits-memory"><img src="https://img.shields.io/npm/v/@aitytech/agentkits-memory.svg" alt="npm"></a>
<img src="https://img.shields.io/badge/license-MIT-blue.svg" alt="License">
<img src="https://img.shields.io/badge/Claude_Code-Compatible-blueviolet" alt="Claude Code">
<img src="https://img.shields.io/badge/Cursor-Compatible-blue" alt="Cursor">
<img src="https://img.shields.io/badge/Windsurf-Compatible-cyan" alt="Windsurf">
<img src="https://img.shields.io/badge/Cline-Compatible-orange" alt="Cline">
<img src="https://img.shields.io/badge/OpenCode-Compatible-green" alt="OpenCode">
<br>
<img src="https://img.shields.io/badge/tests-970_passed-brightgreen" alt="Tests">
<img src="https://img.shields.io/badge/coverage-91%25-brightgreen" alt="Coverage">
</p>
<p align="center">
<strong>Système de Mémoire Persistante pour Assistants de Codage IA</strong>
</p>
<p align="center">
Votre assistant IA oublie tout entre les sessions. AgentKits Memory résout ce problème.<br>
Décisions, motifs, erreurs et contexte — tout est persisté localement via MCP.
</p>
<p align="center">
<a href="https://www.agentkits.net/memory">Site Web</a> •
<a href="https://www.agentkits.net/memory/docs">Documentation</a> •
<a href="#démarrage-rapide">Démarrage Rapide</a> •
<a href="#comment-ça-fonctionne">Comment Ça Fonctionne</a> •
<a href="#support-multi-plateforme">Plateformes</a> •
<a href="#commandes-cli">CLI</a> •
<a href="#interface-web">Interface Web</a>
</p>
<p align="center">
<a href="../README.md">English</a> · <a href="./README.zh.md">简体中文</a> · <a href="./README.ja.md">日本語</a> · <a href="./README.ko.md">한국어</a> · <a href="./README.es.md">Español</a> · <a href="./README.de.md">Deutsch</a> · <strong>Français</strong> · <a href="./README.pt-br.md">Português</a> · <a href="./README.vi.md">Tiếng Việt</a> · <a href="./README.ru.md">Русский</a> · <a href="./README.ar.md">العربية</a>
</p>
---
## Fonctionnalités
| Fonctionnalité | Avantage |
|---------|---------|
| **100% Local** | Toutes les données restent sur votre machine. Pas de cloud, pas de clés API, pas de comptes |
| **Ultra Rapide** | SQLite natif (better-sqlite3) = requêtes instantanées, latence zéro |
| **Zéro Configuration** | Fonctionne immédiatement. Aucune configuration de base de données requise |
| **Multi-Plateforme** | Claude Code, Cursor, Windsurf, Cline, OpenCode — une seule commande d'installation |
| **Serveur MCP** | 9 outils : save, search, timeline, details, recall, list, update, delete, status |
| **Capture Automatique** | Les hooks capturent automatiquement le contexte de session, l'utilisation des outils et les résumés |
| **Enrichissement IA** | Les workers en arrière-plan enrichissent les observations avec des résumés générés par IA |
| **Recherche Vectorielle** | Similarité sémantique sqlite-vec avec embeddings multilingues (100+ langues) |
| **Interface Web** | Interface navigateur pour visualiser, rechercher, ajouter, modifier et supprimer des mémoires |
| **Recherche en 3 Couches** | La divulgation progressive économise ~87% de tokens vs tout récupérer |
| **Gestion du Cycle de Vie** | Compression, archivage et nettoyage automatiques des anciennes sessions |
| **Export/Import** | Sauvegarde et restauration des mémoires au format JSON |
---
## Comment Ça Fonctionne
```
Session 1: "Use JWT for auth" Session 2: "Add login endpoint"
┌──────────────────────────┐ ┌──────────────────────────┐
│ Vous codez avec l'IA... │ │ L'IA sait déjà : │
│ L'IA prend des décisions│ │ ✓ Décision auth JWT │
│ L'IA rencontre erreurs │ ───► │ ✓ Solutions d'erreurs │
│ L'IA apprend motifs │ saved │ ✓ Motifs de code │
│ │ │ ✓ Contexte de session │
└──────────────────────────┘ └──────────────────────────┘
│ ▲
▼ │
.claude/memory/memory.db ──────────────────┘
(SQLite, 100% local)
```
1. **Configuration unique** — `npx @aitytech/agentkits-memory` configure votre plateforme
2. **Capture automatique** — Les hooks enregistrent les décisions, l'utilisation des outils et les résumés pendant votre travail
3. **Injection de contexte** — La prochaine session démarre avec l'historique pertinent des sessions passées
4. **Traitement en arrière-plan** — Les workers enrichissent les observations avec l'IA, génèrent des embeddings, compressent les anciennes données
5. **Recherche à tout moment** — L'IA utilise les outils MCP (`memory_search` → `memory_details`) pour trouver le contexte passé
Toutes les données restent dans `.claude/memory/memory.db` sur votre machine. Pas de cloud. Pas de clés API requises.
---
## Décisions de Conception Importantes
La plupart des outils de mémoire dispersent les données dans des fichiers markdown, nécessitent des environnements Python ou envoient votre code vers des API externes. AgentKits Memory fait des choix fondamentalement différents :
| Choix de Conception | Pourquoi C'est Important |
|---------------|----------------|
| **Base de données SQLite unique** | Un seul fichier (`memory.db`) contient tout — mémoires, sessions, observations, embeddings. Pas de fichiers dispersés à synchroniser, pas de conflits de fusion, pas de données orphelines. Sauvegarde = copier un seul fichier |
| **Node.js natif, zéro Python** | Fonctionne partout où Node fonctionne. Pas de conda, pas de pip, pas de virtualenv. Même langage que votre serveur MCP — une commande `npx`, c'est fait |
| **Recherche en 3 couches économe en tokens** | Index de recherche d'abord (~50 tokens/résultat), puis contexte chronologique, puis détails complets. Récupérez seulement ce dont vous avez besoin. Les autres outils déversent des fichiers de mémoire entiers dans le contexte, brûlant des tokens sur du contenu non pertinent |
| **Capture automatique via hooks** | Les décisions, motifs et erreurs sont enregistrés au moment où ils se produisent — pas après que vous vous rappeliez de les sauvegarder. L'injection de contexte de session se fait automatiquement au démarrage de la session suivante |
| **Embeddings locaux, pas d'appels API** | La recherche vectorielle utilise un modèle ONNX local (multilingual-e5-small). La recherche sémantique fonctionne hors ligne, ne coûte rien et prend en charge 100+ langues |
| **Workers en arrière-plan** | L'enrichissement IA, la génération d'embeddings et la compression s'exécutent de manière asynchrone. Votre flux de codage n'est jamais bloqué |
| **Multi-plateforme dès le départ** | Un seul flag `--platform=all` configure Claude Code, Cursor, Windsurf, Cline et OpenCode simultanément. Même base de données de mémoire, différents éditeurs |
| **Données d'observation structurées** | L'utilisation des outils est capturée avec classification de type (read/write/execute/search), suivi de fichiers, détection d'intention et narratifs générés par IA — pas de dumps de texte brut |
| **Pas de fuites de processus** | Les workers en arrière-plan s'auto-terminent après 5 minutes, utilisent des fichiers de verrouillage basés sur PID avec nettoyage des verrous périmés, et gèrent SIGTERM/SIGINT gracieusement. Pas de processus zombies, pas de workers orphelins |
| **Pas de fuites de mémoire** | Les hooks s'exécutent comme processus de courte durée (pas de démons longue durée). Les connexions à la base de données se ferment à l'arrêt. Le sous-processus d'embedding a un respawn borné (max 2), des timeouts de requêtes en attente et un nettoyage gracieux de tous les timers et files d'attente |
---
## Interface Web
Visualisez et gérez vos mémoires via une interface web moderne.
```bash
npx @aitytech/agentkits-memory web
```
Puis ouvrez **http://localhost:1905** dans votre navigateur.
### Liste des Sessions
Parcourez toutes les sessions avec vue chronologique et détails d'activité.
### Liste des Mémoires
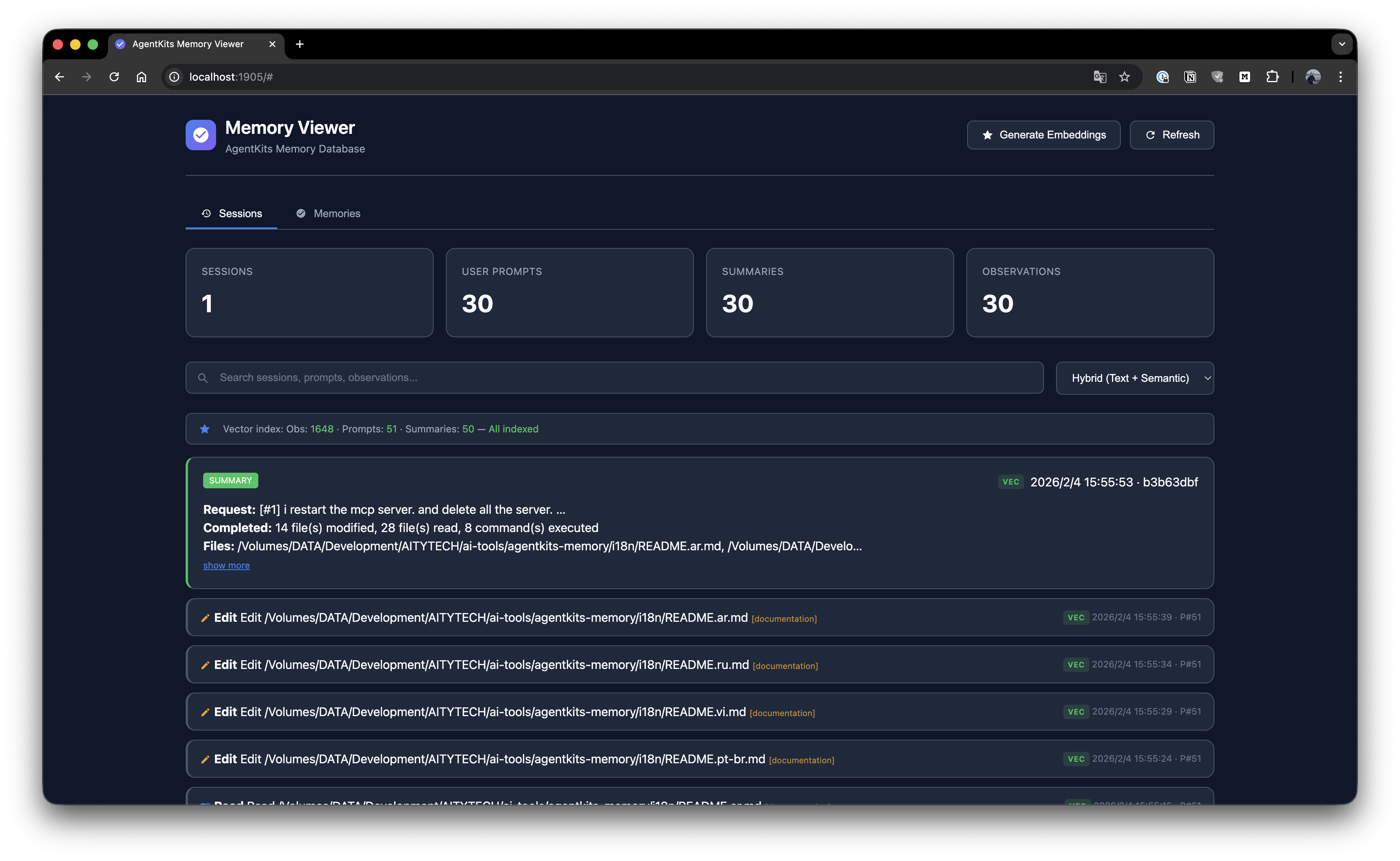
Parcourez toutes les mémoires stockées avec recherche et filtrage par namespace.
### Ajouter une Mémoire
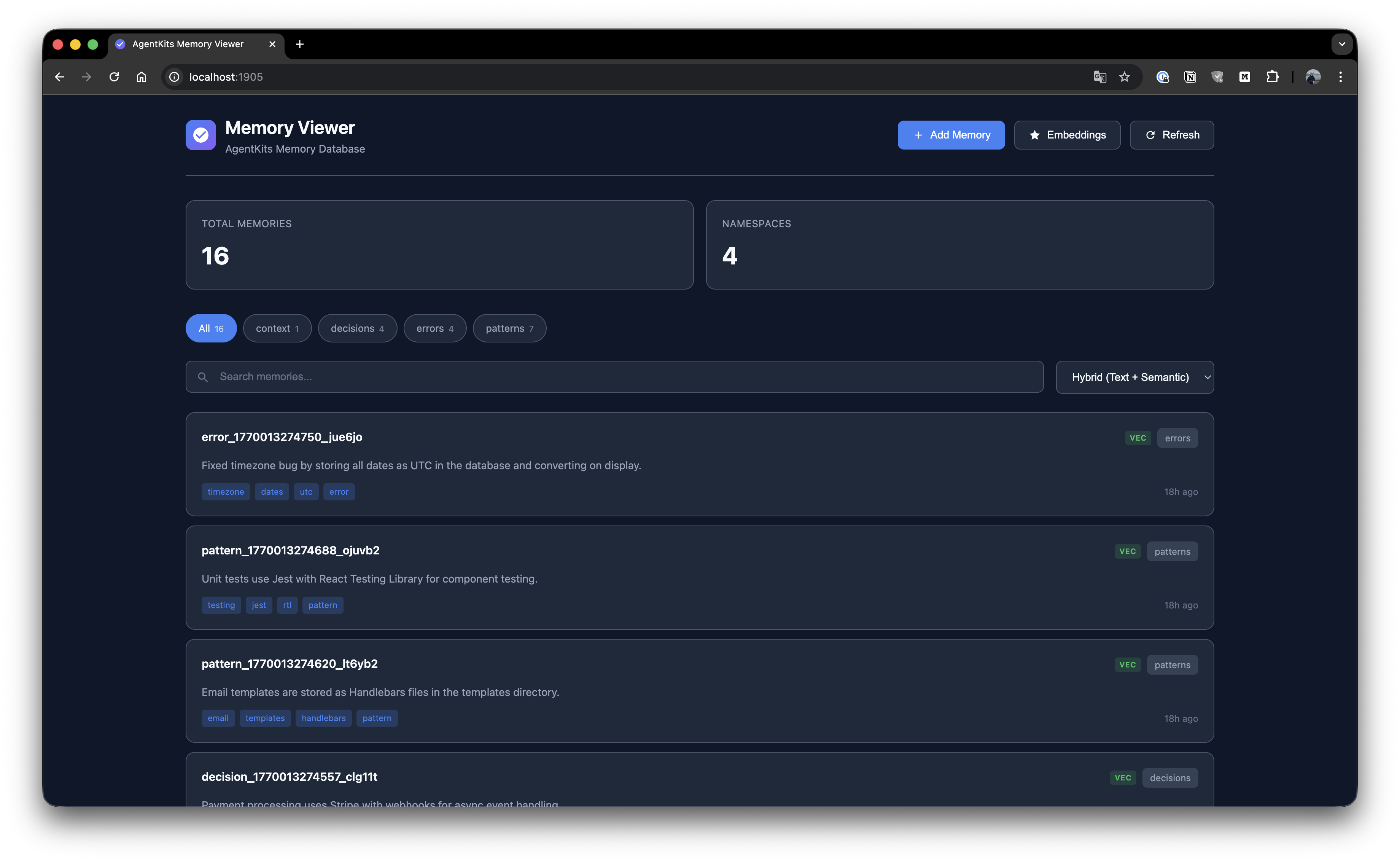
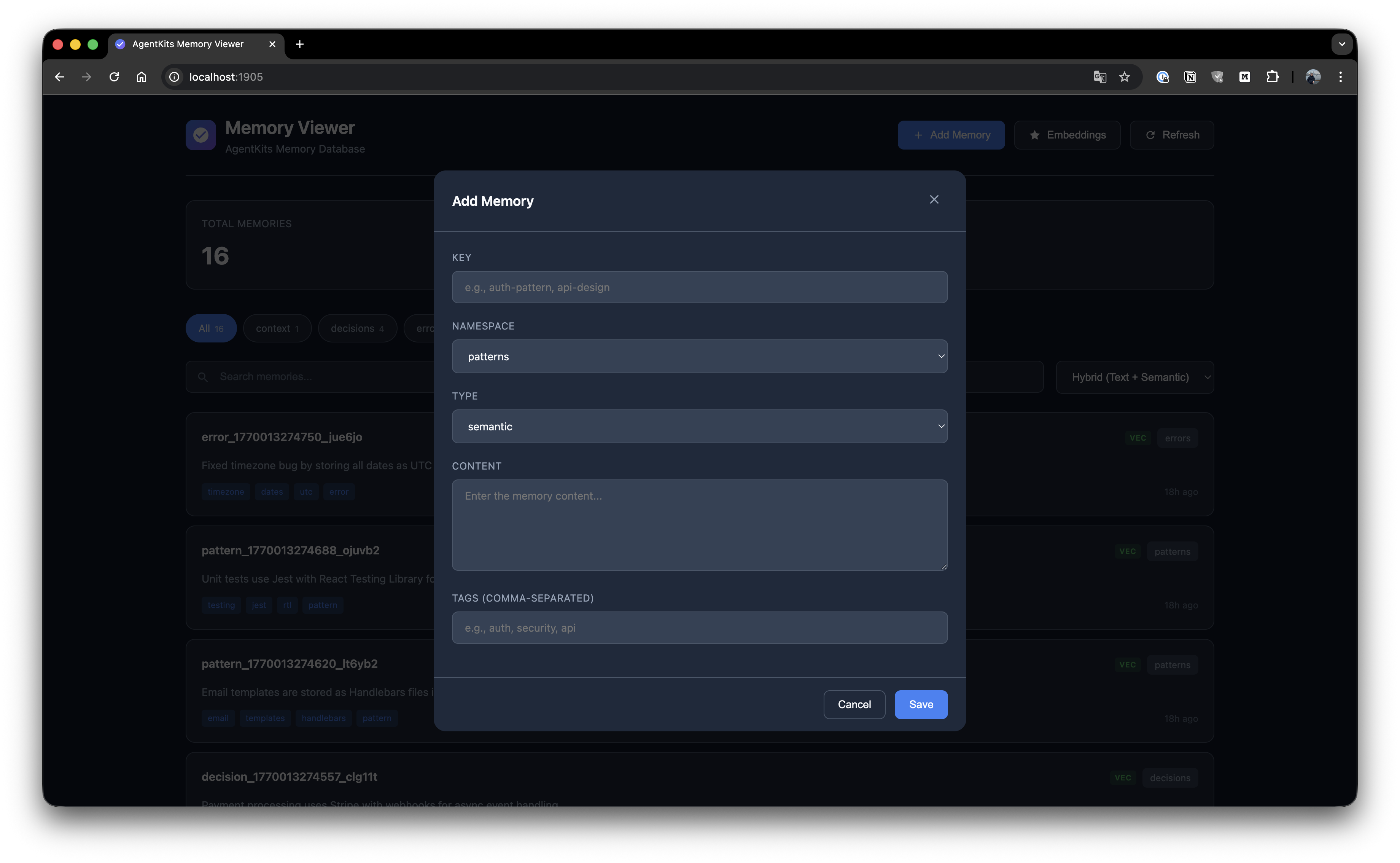
Créez de nouvelles mémoires avec clé, namespace, type, contenu et tags.
### Détails de la Mémoire
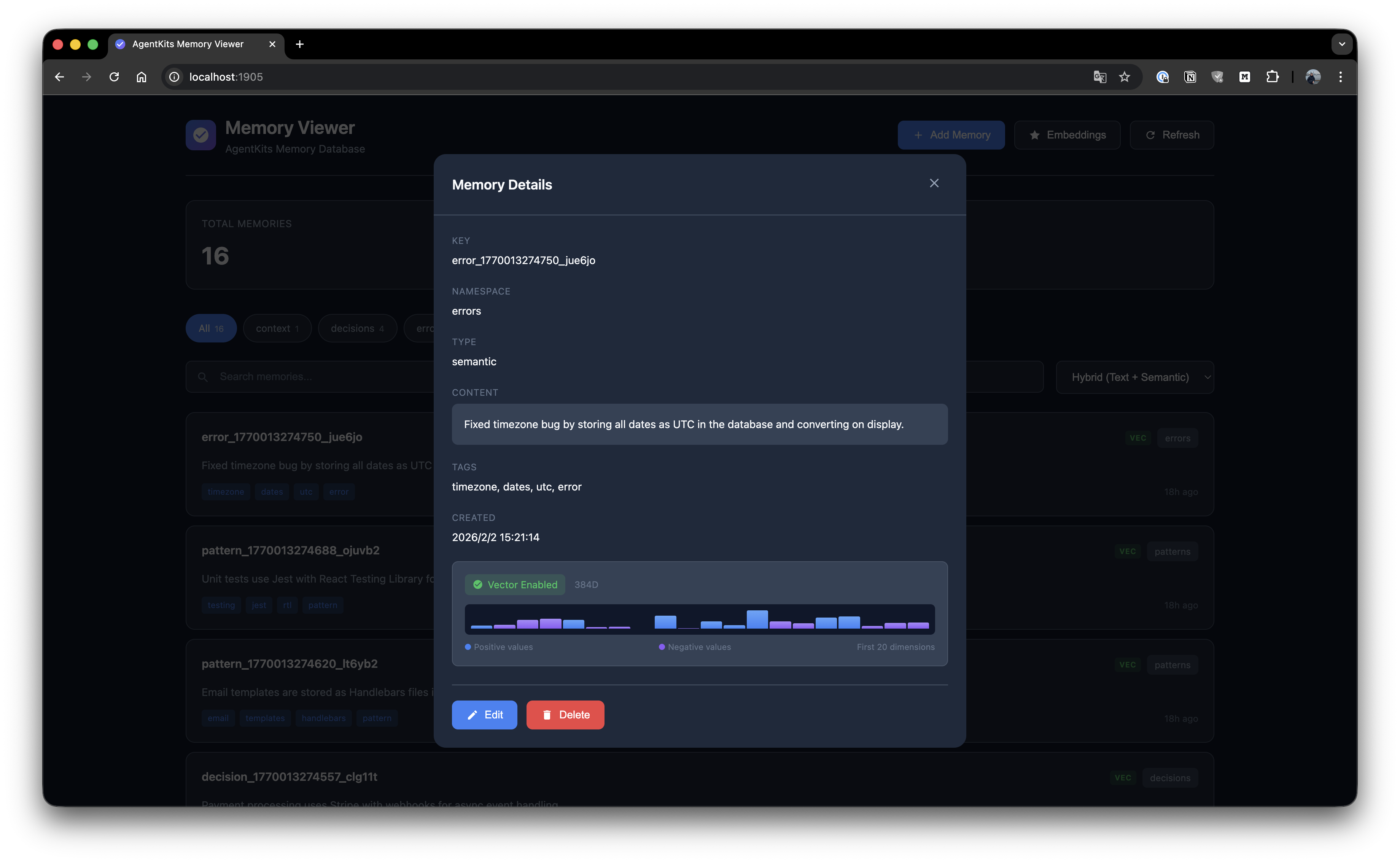
Visualisez les détails complets d'une mémoire avec options d'édition et de suppression.
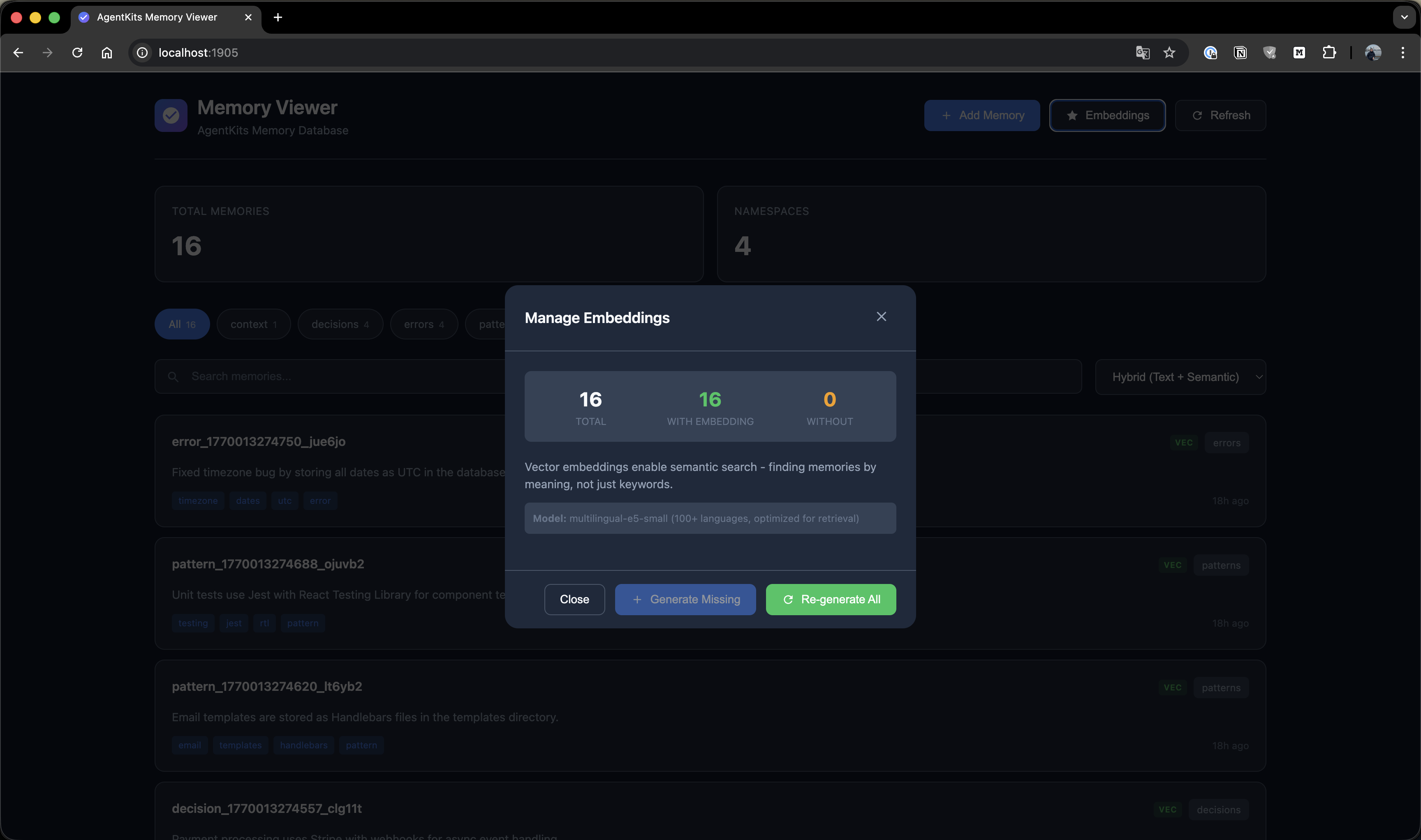
### Gérer les Embeddings
Générez et gérez les embeddings vectoriels pour la recherche sémantique.
---
## Démarrage Rapide
### Option 1 : Marketplace de Plugins Claude Code (Recommandé pour Claude Code)
Installation en une seule commande — aucune configuration manuelle nécessaire :
```bash
/plugin marketplace add aitytech/agentkits-memory
/plugin install agentkits-memory@agentkits-memory
```
Cela installe automatiquement les hooks, le serveur MCP et le skill de workflow mémoire. Redémarrez Claude Code après l'installation.
### Option 2 : Installation Automatique (Toutes les Plateformes)
```bash
npx @aitytech/agentkits-memory
```
Cela détecte automatiquement votre plateforme et configure tout : serveur MCP, hooks (Claude Code/OpenCode), fichiers de règles (Cursor/Windsurf/Cline) et télécharge le modèle d'embedding.
**Cibler une plateforme spécifique :**
```bash
npx @aitytech/agentkits-memory setup --platform=cursor
npx @aitytech/agentkits-memory setup --platform=windsurf,cline
npx @aitytech/agentkits-memory setup --platform=all
```
### Option 3 : Configuration Manuelle MCP
Si vous préférez la configuration manuelle, ajoutez à votre configuration MCP :
```json
{
"mcpServers": {
"memory": {
"command": "npx",
"args": ["-y", "@aitytech/agentkits-memory", "server"]
}
}
}
```
Emplacements des fichiers de configuration :
- **Claude Code** : `.claude/settings.json` (intégré dans la clé `mcpServers`)
- **Cursor** : `.cursor/mcp.json`
- **Windsurf** : `.windsurf/mcp.json`
- **Cline / OpenCode** : `.mcp.json` (racine du projet)
### 3. Outils MCP
Une fois configuré, votre assistant IA peut utiliser ces outils :
| Outil | Description |
|------|-------------|
| `memory_status` | Vérifier le statut du système de mémoire (appelez d'abord !) |
| `memory_save` | Sauvegarder des décisions, motifs, erreurs ou contexte |
| `memory_search` | **[Étape 1]** Index de recherche — IDs + titres légers (~50 tokens/résultat) |
| `memory_timeline` | **[Étape 2]** Obtenir le contexte temporel autour d'une mémoire |
| `memory_details` | **[Étape 3]** Obtenir le contenu complet pour des IDs spécifiques |
| `memory_recall` | Aperçu rapide d'un sujet — résumé groupé |
| `memory_list` | Lister les mémoires récentes |
| `memory_update` | Mettre à jour le contenu ou les tags d'une mémoire existante |
| `memory_delete` | Supprimer des mémoires obsolètes |
---
## Divulgation Progressive (Recherche Économe en Tokens)
AgentKits Memory utilise un **modèle de recherche en 3 couches** qui économise ~70% de tokens par rapport à la récupération du contenu complet d'emblée.
### Comment Ça Fonctionne
```
┌─────────────────────────────────────────────────────────────┐
│ Étape 1 : memory_search │
│ Retourne : IDs, titres, tags, scores (~50 tokens/élément) │
│ → Examinez l'index, choisissez les mémoires pertinentes │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Étape 2 : memory_timeline (optionnel) │
│ Retourne : Contexte ±30 minutes autour de la mémoire │
│ → Comprenez ce qui s'est passé avant/après │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Étape 3 : memory_details │
│ Retourne : Contenu complet pour les IDs sélectionnés seuls │
│ → Récupérez seulement ce dont vous avez réellement besoin │
└─────────────────────────────────────────────────────────────┘
```
### Exemple de Workflow
```typescript
// Étape 1 : Recherche - obtenir un index léger
memory_search({ query: "authentication" })
// → Retourne : [{ id: "abc", title: "JWT pattern...", score: 85% }]
// Étape 2 : (Optionnel) Voir le contexte temporel
memory_timeline({ anchor: "abc" })
// → Retourne : Ce qui s'est passé avant/après cette mémoire
// Étape 3 : Obtenir le contenu complet seulement pour ce dont vous avez besoin
memory_details({ ids: ["abc"] })
// → Retourne : Contenu complet pour la mémoire sélectionnée
```
### Économies de Tokens
| Approche | Tokens Utilisés |
|----------|-------------|
| **Ancienne :** Récupérer tout le contenu | ~500 tokens × 10 résultats = 5000 tokens |
| **Nouvelle :** Divulgation progressive | 50 × 10 + 500 × 2 = 1500 tokens |
| **Économies** | **Réduction de 70%** |
---
## Commandes CLI
```bash
# Installation en une commande (détecte automatiquement la plateforme)
npx @aitytech/agentkits-memory
npx @aitytech/agentkits-memory setup --platform=cursor # plateforme spécifique
npx @aitytech/agentkits-memory setup --platform=all # toutes les plateformes
npx @aitytech/agentkits-memory setup --force # réinstaller/mettre à jour
# Démarrer le serveur MCP
npx @aitytech/agentkits-memory server
# Interface web (port 1905)
npx @aitytech/agentkits-memory web
# Visualiseur terminal
npx @aitytech/agentkits-memory viewer
npx @aitytech/agentkits-memory viewer --stats # statistiques de la base de données
npx @aitytech/agentkits-memory viewer --json # sortie JSON
# Sauvegarder depuis CLI
npx @aitytech/agentkits-memory save "Use JWT with refresh tokens" --category pattern --tags auth,security
# Paramètres
npx @aitytech/agentkits-memory hook settings . # voir les paramètres actuels
npx @aitytech/agentkits-memory hook settings . --reset # réinitialiser aux valeurs par défaut
npx @aitytech/agentkits-memory hook settings . aiProvider.provider=openai aiProvider.apiKey=sk-...
# Export / Import
npx @aitytech/agentkits-memory hook export . my-project ./backup.json
npx @aitytech/agentkits-memory hook import . ./backup.json
# Gestion du cycle de vie
npx @aitytech/agentkits-memory hook lifecycle . --compress-days=7 --archive-days=30
npx @aitytech/agentkits-memory hook lifecycle-stats .
```
---
## Utilisation Programmatique
```typescript
import { ProjectMemoryService } from '@aitytech/agentkits-memory';
const memory = new ProjectMemoryService({
baseDir: '.claude/memory',
dbFilename: 'memory.db',
});
await memory.initialize();
// Stocker une mémoire
await memory.storeEntry({
key: 'auth-pattern',
content: 'Use JWT with refresh tokens for authentication',
namespace: 'patterns',
tags: ['auth', 'security'],
});
// Interroger les mémoires
const results = await memory.query({
type: 'hybrid',
namespace: 'patterns',
content: 'authentication',
limit: 10,
});
// Obtenir par clé
const entry = await memory.getByKey('patterns', 'auth-pattern');
```
---
## Hooks de Capture Automatique
Les hooks capturent automatiquement vos sessions de codage IA (Claude Code et OpenCode uniquement) :
| Hook | Déclencheur | Action |
|------|---------|--------|
| `context` | Démarrage de Session | Injecte le contexte de session précédente + statut de la mémoire |
| `session-init` | Prompt Utilisateur | Initialise/reprend la session, enregistre les prompts |
| `observation` | Après Utilisation d'Outil | Capture l'utilisation de l'outil avec détection d'intention |
| `summarize` | Fin de Session | Génère un résumé structuré de session |
| `user-message` | Démarrage de Session | Affiche le statut de la mémoire à l'utilisateur (stderr) |
Installer les hooks :
```bash
npx @aitytech/agentkits-memory
```
**Ce qui est capturé automatiquement :**
- Lectures/écritures de fichiers avec chemins
- Modifications de code sous forme de diffs structurés (avant → après)
- Intention du développeur (bugfix, feature, refactor, investigation, etc.)
- Résumés de session avec décisions, erreurs et prochaines étapes
- Suivi multi-prompts au sein des sessions
---
## Support Multi-Plateforme
| Plateforme | MCP | Hooks | Fichier de Règles | Installation |
|----------|-----|-------|------------|-------|
| **Claude Code** | `.claude/settings.json` | ✅ Complet | CLAUDE.md (skill) | `--platform=claude-code` |
| **Cursor** | `.cursor/mcp.json` | — | `.cursorrules` | `--platform=cursor` |
| **Windsurf** | `.windsurf/mcp.json` | — | `.windsurfrules` | `--platform=windsurf` |
| **Cline** | `.mcp.json` | — | `.clinerules` | `--platform=cline` |
| **OpenCode** | `.mcp.json` | ✅ Complet | — | `--platform=opencode` |
- **Serveur MCP** fonctionne avec toutes les plateformes (outils de mémoire via protocole MCP)
- **Hooks** fournissent la capture automatique sur Claude Code et OpenCode
- **Fichiers de règles** enseignent le workflow de mémoire à Cursor/Windsurf/Cline
- **Données de mémoire** toujours stockées dans `.claude/memory/` (source unique de vérité)
---
## Workers en Arrière-Plan
Après chaque session, les workers en arrière-plan traitent les tâches en file d'attente :
| Worker | Tâche | Description |
|--------|------|-------------|
| `embed-session` | Embeddings | Génère les embeddings vectoriels pour la recherche sémantique |
| `enrich-session` | Enrichissement IA | Enrichit les observations avec résumés, faits, concepts générés par IA |
| `compress-session` | Compression | Compresse les anciennes observations (10:1–25:1) et génère des résumés de session (20:1–100:1) |
Les workers s'exécutent automatiquement après la fin de session. Chaque worker :
- Traite jusqu'à 200 éléments par exécution
- Utilise des fichiers de verrouillage pour empêcher l'exécution concurrente
- S'auto-termine après 5 minutes (empêche les zombies)
- Réessaie les tâches échouées jusqu'à 3 fois
---
## Configuration du Fournisseur IA
L'enrichissement IA utilise des fournisseurs modulaires. Par défaut c'est `claude-cli` (pas de clé API nécessaire).
| Fournisseur | Type | Modèle par Défaut | Notes |
|----------|------|---------------|-------|
| **Claude CLI** | `claude-cli` | `haiku` | Utilise `claude --print`, pas de clé API nécessaire |
| **OpenAI** | `openai` | `gpt-4o-mini` | N'importe quel modèle OpenAI |
| **Google Gemini** | `gemini` | `gemini-2.0-flash` | Clé Google AI Studio |
| **OpenRouter** | `openai` | any | Définir `baseUrl` sur `https://openrouter.ai/api/v1` |
| **GLM (Zhipu)** | `openai` | any | Définir `baseUrl` sur `https://open.bigmodel.cn/api/paas/v4` |
| **Ollama** | `openai` | any | Définir `baseUrl` sur `http://localhost:11434/v1` |
### Option 1 : Variables d'Environnement
```bash
# OpenAI
export AGENTKITS_AI_PROVIDER=openai
export AGENTKITS_AI_API_KEY=sk-...
# Google Gemini
export AGENTKITS_AI_PROVIDER=gemini
export AGENTKITS_AI_API_KEY=AIza...
# OpenRouter (utilise le format compatible OpenAI)
export AGENTKITS_AI_PROVIDER=openai
export AGENTKITS_AI_API_KEY=sk-or-...
export AGENTKITS_AI_BASE_URL=https://openrouter.ai/api/v1
export AGENTKITS_AI_MODEL=anthropic/claude-3.5-haiku
# Ollama local (pas de clé API nécessaire)
export AGENTKITS_AI_PROVIDER=openai
export AGENTKITS_AI_BASE_URL=http://localhost:11434/v1
export AGENTKITS_AI_MODEL=llama3.2
# Désactiver complètement l'enrichissement IA
export AGENTKITS_AI_ENRICHMENT=false
```
### Option 2 : Paramètres Persistants
```bash
# Sauvegardé dans .claude/memory/settings.json — persiste entre les sessions
npx @aitytech/agentkits-memory hook settings . aiProvider.provider=openai aiProvider.apiKey=sk-...
npx @aitytech/agentkits-memory hook settings . aiProvider.provider=gemini aiProvider.apiKey=AIza...
npx @aitytech/agentkits-memory hook settings . aiProvider.baseUrl=https://openrouter.ai/api/v1
# Voir les paramètres actuels
npx @aitytech/agentkits-memory hook settings .
# Réinitialiser aux valeurs par défaut
npx @aitytech/agentkits-memory hook settings . --reset
```
> **Priorité :** Les variables d'environnement remplacent settings.json. Settings.json remplace les valeurs par défaut.
---
## Gestion du Cycle de Vie
Gérez la croissance de la mémoire au fil du temps :
```bash
# Compresser les observations de plus de 7 jours, archiver les sessions de plus de 30 jours
npx @aitytech/agentkits-memory hook lifecycle . --compress-days=7 --archive-days=30
# Aussi auto-supprimer les sessions archivées de plus de 90 jours
npx @aitytech/agentkits-memory hook lifecycle . --compress-days=7 --archive-days=30 --delete --delete-days=90
# Voir les statistiques du cycle de vie
npx @aitytech/agentkits-memory hook lifecycle-stats .
```
| Étape | Que Se Passe-t-il |
|-------|-------------|
| **Compresser** | L'IA compresse les observations, génère des résumés de session |
| **Archiver** | Marque les anciennes sessions comme archivées (exclues du contexte) |
| **Supprimer** | Supprime les sessions archivées (opt-in, nécessite `--delete`) |
---
## Export / Import
Sauvegardez et restaurez vos mémoires de projet :
```bash
# Exporter toutes les sessions d'un projet
npx @aitytech/agentkits-memory hook export . my-project ./backup.json
# Importer depuis une sauvegarde (déduplique automatiquement)
npx @aitytech/agentkits-memory hook import . ./backup.json
```
Le format d'export inclut les sessions, observations, prompts et résumés.
---
## Catégories de Mémoire
| Catégorie | Cas d'Usage |
|----------|----------|
| `decision` | Décisions d'architecture, choix de pile technique, compromis |
| `pattern` | Conventions de codage, motifs de projet, approches récurrentes |
| `error` | Corrections de bugs, solutions d'erreurs, insights de débogage |
| `context` | Contexte du projet, conventions d'équipe, configuration d'environnement |
| `observation` | Observations de session auto-capturées |
---
## Stockage
Les mémoires sont stockées dans `.claude/memory/` dans le répertoire de votre projet.
```
.claude/memory/
├── memory.db # Base de données SQLite (toutes les données)
├── memory.db-wal # Write-ahead log (temporaire)
├── settings.json # Paramètres persistants (fournisseur IA, config contexte)
└── embeddings-cache/ # Embeddings vectoriels en cache
```
---
## Support des Langues CJK
AgentKits Memory a un **support CJK automatique** pour la recherche de texte en chinois, japonais et coréen.
### Zéro Configuration
Quand `better-sqlite3` est installé (par défaut), la recherche CJK fonctionne automatiquement :
```typescript
import { ProjectMemoryService } from '@aitytech/agentkits-memory';
const memory = new ProjectMemoryService('.claude/memory');
await memory.initialize();
// Stocker du contenu CJK
await memory.storeEntry({
key: 'auth-pattern',
content: '認証機能の実装パターン - JWT with refresh tokens',
namespace: 'patterns',
});
// Rechercher en japonais, chinois ou coréen - ça marche simplement !
const results = await memory.query({
type: 'hybrid',
content: '認証機能',
});
```
### Comment Ça Fonctionne
- **SQLite natif** : Utilise `better-sqlite3` pour des performances maximales
- **Tokenizer trigramme** : FTS5 avec trigramme crée des séquences de 3 caractères pour la correspondance CJK
- **Fallback intelligent** : Les requêtes CJK courtes (< 3 caractères) utilisent automatiquement la recherche LIKE
- **Classement BM25** : Scoring de pertinence pour les résultats de recherche
### Avancé : Segmentation des Mots Japonais
Pour le japonais avancé avec segmentation de mots appropriée, utilisez optionnellement lindera :
```typescript
import { createJapaneseOptimizedBackend } from '@aitytech/agentkits-memory';
const backend = createJapaneseOptimizedBackend({
databasePath: '.claude/memory/memory.db',
linderaPath: './path/to/liblindera_sqlite.dylib',
});
```
Nécessite une build [lindera-sqlite](https://github.com/lindera/lindera-sqlite).
---
## Référence API
### ProjectMemoryService
```typescript
interface ProjectMemoryConfig {
baseDir: string; // Par défaut : '.claude/memory'
dbFilename: string; // Par défaut : 'memory.db'
enableVectorIndex: boolean; // Par défaut : false
dimensions: number; // Par défaut : 384
embeddingGenerator?: EmbeddingGenerator;
cacheEnabled: boolean; // Par défaut : true
cacheSize: number; // Par défaut : 1000
cacheTtl: number; // Par défaut : 300000 (5 min)
}
```
### Méthodes
| Méthode | Description |
|--------|-------------|
| `initialize()` | Initialiser le service de mémoire |
| `shutdown()` | Arrêter et persister les changements |
| `storeEntry(input)` | Stocker une entrée de mémoire |
| `get(id)` | Obtenir une entrée par ID |
| `getByKey(namespace, key)` | Obtenir une entrée par namespace et clé |
| `update(id, update)` | Mettre à jour une entrée |
| `delete(id)` | Supprimer une entrée |
| `query(query)` | Interroger les entrées avec filtres |
| `semanticSearch(content, k)` | Recherche de similarité sémantique |
| `count(namespace?)` | Compter les entrées |
| `listNamespaces()` | Lister tous les namespaces |
| `getStats()` | Obtenir les statistiques |
---
## Qualité du Code
AgentKits Memory est rigoureusement testé avec **970 tests unitaires** répartis sur 21 suites de tests.
| Métrique | Couverture |
|----------|-----------|
| **Instructions** | 90.29% |
| **Branches** | 80.85% |
| **Fonctions** | 90.54% |
| **Lignes** | 91.74% |
### Catégories de Tests
| Catégorie | Tests | Couverture |
|-----------|-------|-----------|
| Service Mémoire Core | 56 | CRUD, recherche, pagination, catégories, tags, import/export |
| Backend SQLite | 65 | Schéma, migrations, FTS5, transactions, gestion d'erreurs |
| Index Vectoriel sqlite-vec | 47 | Insertion, recherche, suppression, persistance, cas limites |
| Recherche Hybride | 44 | FTS + fusion vectorielle, scoring, classement, filtres |
| Économie de Tokens | 27 | Budgets de recherche 3 couches, troncature, optimisation |
| Système d'Embeddings | 63 | Cache, sous-processus, modèles locaux, support CJK |
| Système de Hooks | 502 | Contexte, init session, observation, résumé, enrichissement IA, cycle de vie, workers, adaptateurs, types |
| Serveur MCP | 48 | 9 outils MCP, validation, réponses d'erreur |
| CLI | 34 | Détection de plateforme, génération de règles |
| Intégration | 84 | Flux end-to-end, intégration embeddings, multi-session |
```bash
# Exécuter les tests
npm test
# Exécuter avec couverture
npm run test:coverage
```
---
## Prérequis
- **Node.js LTS** : 18.x, 20.x ou 22.x (recommandé)
- Assistant de codage IA compatible MCP
### Notes sur la Version Node.js
Ce package utilise `better-sqlite3` qui nécessite des binaires natifs. **Les binaires précompilés sont disponibles uniquement pour les versions LTS**.
| Version Node | Statut | Notes |
|--------------|--------|-------|
| 18.x LTS | ✅ Fonctionne | Binaires précompilés |
| 20.x LTS | ✅ Fonctionne | Binaires précompilés |
| 22.x LTS | ✅ Fonctionne | Binaires précompilés |
| 19.x, 21.x, 23.x | ⚠️ Nécessite outils de build | Pas de binaires précompilés |
### Utilisation de Versions Non-LTS (Windows)
Si vous devez utiliser une version non-LTS (19, 21, 23), installez d'abord les outils de build :
**Option 1 : Visual Studio Build Tools**
```powershell
# Téléchargez et installez depuis :
# https://visualstudio.microsoft.com/visual-cpp-build-tools/
# Sélectionnez la charge de travail "Desktop development with C++"
```
**Option 2 : windows-build-tools (npm)**
```powershell
npm install --global windows-build-tools
```
**Option 3 : Chocolatey**
```powershell
choco install visualstudio2022-workload-vctools
```
Voir le [guide Windows node-gyp](https://github.com/nodejs/node-gyp#on-windows) pour plus de détails.
---
## Écosystème AgentKits
**AgentKits Memory** fait partie de l'écosystème AgentKits par AityTech - des outils qui rendent les assistants de codage IA plus intelligents.
| Produit | Description | Lien |
|---------|-------------|------|
| **AgentKits Engineer** | 28 agents spécialisés, 100+ compétences, patterns d'entreprise | [GitHub](https://github.com/aitytech/agentkits-engineer) |
| **AgentKits Marketing** | Génération de contenu marketing par IA | [GitHub](https://github.com/aitytech/agentkits-marketing) |
| **AgentKits Memory** | Mémoire persistante pour assistants IA (ce package) | [npm](https://www.npmjs.com/package/@aitytech/agentkits-memory) |
<p align="center">
<a href="https://agentkits.net">
<img src="https://img.shields.io/badge/Visit-agentkits.net-blue?style=for-the-badge" alt="agentkits.net">
</a>
</p>
---
## Historique des Stars
<a href="https://star-history.com/#aitytech/agentkits-memory&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=aitytech/agentkits-memory&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=aitytech/agentkits-memory&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=aitytech/agentkits-memory&type=Date" />
</picture>
</a>
---
## Licence
MIT
---
<p align="center">
<strong>Donnez à votre assistant IA une mémoire qui persiste.</strong>
</p>
<p align="center">
<em>AgentKits Memory par AityTech</em>
</p>
<p align="center">
Ajoutez une étoile à ce repo s'il aide votre IA à se souvenir.
</p>
