
TAPD Data Fetcher
This server acts as a TAPD Data Fetcher that allows you to:
Fetch requirements data (stories) from configured TAPD projects
Fetch bug/defect data from configured TAPD projects
Return formatted JSON strings of the retrieved data
Support pagination when fetching both requirement and bug data
Connect to AI clients (like Claude) for data analysis via the Model Context Protocol (MCP)
Configure custom TAPD API credentials and workspace IDs for tailored data retrieval
Automatically store fetched data in JSON files
Utilizes Python for implementation, with the project specifically requiring Python 3.10.x for compatibility.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@TAPD Data Fetcherget the latest high priority bugs from TAPD"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
MCP_Agent:RE 项目指南
对话效果预览(项目早期)
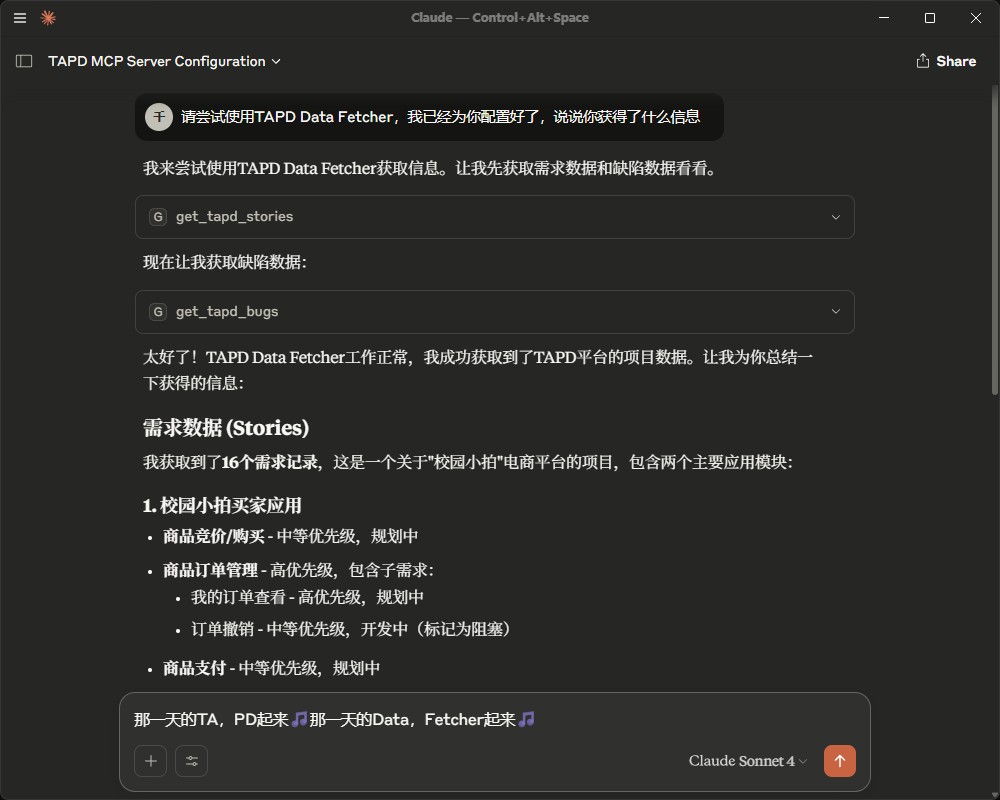
此项目于2025年6月10日由 punkpeye (Frank Fiegel) 收录于 TAPD Data Fetcher | Glama

本项目 GitHub 地址 https://github.com/OneCuriousLearner/MCPAgentRE
本项目在 Gitee 上同步更新,镜像地址为 https://gitee.com/ChiTsuHa-Tau5_C/MCPAgentRE
项目背景
MCP_Agent:RE 是一个用于从 TAPD 平台获取需求和缺陷数据并生成质量分析报告的 Python 项目,旨在为 AI 客户端提供数据支持。
可用的 MCP 服务器
MCP 工具统一放置于 tapd_mcp_server.py 中。
本项目提供了丰富的 MCP 工具集,支持 TAPD 数据的获取、处理、分析和智能摘要功能:
数据获取工具
get_tapd_data(clean_empty_fields)- 从 TAPD API 获取需求和缺陷数据并保存到本地文件,返回数量统计【推荐】适用于首次获取数据或定期更新本地数据
包含需求和缺陷数据的完整集成
get_tapd_stories(clean_empty_fields)- 获取 TAPD 项目需求数据,支持分页并直接返回 JSON 数据,但不保存至本地,建议仅在数据量较小时使用get_tapd_bugs(clean_empty_fields)- 获取 TAPD 项目缺陷数据,支持分页并直接返回 JSON 数据,但不保存至本地,建议仅在数据量较小时使用
数据预处理工具
preprocess_tapd_description(data_file_path, output_file_path, use_api, process_documents, process_images)- 清理 TAPD 数据中description字段的 HTML 样式,提取文字、链接、图片内容并通过 LLM API 优化表达(需要配置 LLM API 密钥),大幅压缩数据长度同时保留关键信息【仍在开发中...】遇到了腾讯文档 API 导出限制问题,API 每日仅限导出 9 篇文档
遇到了 TAPD 数据详情中图片、视频无法导出的问题,仍未在文档中找到相关描述
目前仅支持文本内容的提取和处理
preview_tapd_description_cleaning(data_file_path, item_count)- 预览description字段清理效果,展示压缩比例和提取信息,不修改原始数据docx_summarizer.py- 提取 .docx 文档中的文本、图片和表格信息,并生成摘要【仍在开发中...】
精确搜索工具
precise_search_tapd_data(search_value, search_field, data_type, exact_match, case_sensitive)- TAPD 数据精确搜索工具,支持对需求和缺陷进行精确字段匹配搜索支持按任意字段精确或模糊搜索
可指定搜索需求、缺陷或两者
支持大小写敏感选项
提供匹配信息和统计摘要
search_tapd_by_priority(priority_filter, data_type)- 按优先级搜索 TAPD 数据,快速筛选高中低优先级项目支持高中低优先级预设过滤器
支持具体优先级标签搜索
默认查找高优先级数据(priority >= 3 或 urgent/high)
get_tapd_data_statistics(data_type)- 获取 TAPD 数据统计信息,提供全面的数据分布分析包含数量、优先级、状态、创建者分布
支持需求和缺陷的独立统计
提供最近项目和完成情况统计
时间趋势分析工具
analyze_time_trends(data_type, chart_type, time_field, since, until, data_file_path)- 分析时间趋势,支持需求和缺陷数据,可自定义时间字段、时间范围和图表类型data_type : 数据类型,可选值为 "story" 和 "bug"
chart_type : 图表类型,可选值为 "count" 和 "line"
time_field : 时间字段,可选值为 "created" 和 "updated"
since : 时间范围,格式为 "YYYY-MM-DD",可选
until : 时间范围,格式为 "YYYY-MM-DD",可选
data_file_path : 数据文件路径,可选,默认值为 "local_data/msg_from_fetcher.json"
向量化与搜索工具
vectorize_data(data_file_path, chunk_size, preserve_existing)- 向量化工具,支持自定义数据源的向量化,将数据转换为向量格式,用于后续的语义搜索和分析get_vector_info()- 获取简化版向量数据库状态和统计信息search_data(query, top_k)- 基于语义相似度的智能搜索,支持自然语言查询,返回与查询最相关的结果
数据生成与分析工具
generate_fake_tapd_data(n_story_A, n_story_B, n_bug_A, n_bug_B, output_path)- 生成模拟 TAPD 数据,用于测试和演示(若不指明地址,使用后可能会覆盖本地数据,若需要来自 TAPD API 的正确数据,请再次调用数据获取工具)generate_tapd_overview(since, until, max_total_tokens, use_local_data)- 使用 LLM 简要生成项目概览报告与摘要,用于了解项目概况(需要配置 LLM API 密钥)analyze_word_frequency(min_frequency, use_extended_fields, data_file_path)- 分析 TAPD 数据的词频分布,生成关键词词云统计,为搜索功能提供精准关键词建议
示例工具
example_tool(param1, param2)- 示例工具,展示 MCP 工具注册方式
这些工具支持从数据获取到智能分析的完整工作流,为 AI 驱动的测试管理提供强大支持。
可用的 WorkFlow 脚本
测试用例评估
test_case_rules_customer.py - 测试用例评估规则配置脚本,用于配置测试用例的评估标准和优先级
test_case_require_list_knowledge_base.py - 测试用例需求知识库生成脚本,可从 TAPD 数据中提取需求信息并生成知识库,或手动修改需求信息
test_case_evaluator.py - 测试用例 AI 评估器脚本,用于根据配置的规则评估测试用例质量,并生成评估报告至本地文件
统一接口脚本
提供统一的工具接口,简化 MCP 工具的注册和调用
包含的工具如下:
MCPToolsConfig 类
__init__()- 初始化配置管理器,自动创建项目所需的目录结构(local_data、models、vector_data)_get_project_root()- 获取项目根目录的绝对路径get_data_file_path(relative_path)- 获取数据文件的绝对路径,支持相对路径自动转换get_vector_db_path(name)- 获取向量数据库文件路径,默认为"data_vector"get_model_cache_path()- 获取模型缓存目录路径
ModelManager 类
__init__(config)- 初始化模型管理器,依赖 MCPToolsConfig 实例get_project_model_path(model_name)- 检测本地是否存在指定模型,返回模型路径或 Noneget_model(model_name)- 获取 SentenceTransformer 模型实例,优先使用本地模型,支持自动下载和缓存clear_cache()- 清除全局模型缓存,释放内存资源
TextProcessor 类
extract_text_from_item(item, item_type)- 从 TAPD 数据项(需求/缺陷)中提取关键文本信息,支持不同类型的字段提取策略
FileManager 类
__init__(config)- 初始化文件管理器,依赖 MCPToolsConfig 实例load_tapd_data(file_path)- 加载 TAPD JSON 数据文件,支持绝对路径和相对路径load_json_data(file_path)- 加载 JSON 数据文件,支持错误处理,文件不存在时返回空字典save_json_data(data, file_path)- 保存数据为 JSON 格式,自动创建目录结构read_excel_with_mapping(excel_file_path, column_mapping, na_to_empty=True)- 通用 Excel 读取与列映射,返回 list[dict]
TransmissionManager 类
__init__(file_manager)- 初始化传输管理器,依赖 FileManager 实例update_stats(success, retries)- 更新传输统计信息,记录成功/失败次数和重试次数finalize_report()- 生成最终传输报告,保存统计数据到 JSON 文件
TokenCounter 类
__init__(config)- 初始化 Token 计数器,依赖 MCPToolsConfig 实例,自动尝试加载 DeepSeek tokenizercount_tokens(text)- 计算文本的 token 数量,优先使用 transformers 库精确计算,失败时使用改进的预估模式_try_load_tokenizer()- 尝试加载本地 DeepSeek tokenizer,支持精确 token 计数
BatchingUtils 工具类
split_by_token_budget(items, estimate_tokens_fn, token_threshold, start_index=0)- 基于 token 阈值的贪心分批,返回(本批列表, 下一起点, 估算 tokens)
MarkdownUtils 工具类
parse_markdown_tables(md_text)- 纯解析 Markdown 表格为通用结构[{headers, rows}],不含业务映射
APIManager 类
__init__()- 初始化 API 管理器,支持 DeepSeek 和 SiliconFlow 双 API 配置get_headers(endpoint)- 智能构建 API 请求头,根据 endpoint 自动选择对应的 API 密钥call_llm(prompt, session, model, endpoint, max_tokens)- 兼容多 API 的 LLM 调用接口支持 DeepSeek API(默认):
deepseek-chat、deepseek-reasoner模型支持 SiliconFlow API:
deepseek-ai/DeepSeek-V3.1等模型自动检测API类型并适配不同的请求格式和错误处理
全局实例管理函数
get_config()- 获取全局 MCPToolsConfig 实例(单例模式)get_model_manager()- 获取全局 ModelManager 实例(单例模式)get_file_manager()- 获取全局 FileManager 实例(单例模式)get_api_manager()- 获取全局 APIManager 实例(单例模式)get_transmission_manager()- 获取全局 TransmissionManager 实例(单例模式)get_token_counter()- 获取全局 TokenCounter 实例(单例模式)
Related MCP server: interview-prep-mcp
项目结构
这些目录数据可能未及时更新,请以实际情况为准
MCPAgentRE\
├─config\ # 配置文件目录
├─knowledge_documents\ # 知识文档(Git 提交时默认忽略目录下的文件,若要提交请手动在 .gitignore 中取消忽略)
├─documents_data\ # 文档数据目录(暂时,最终将替换至 local_data)
│ ├─docx_data\ # 存储 .docx 文档的目录
│ ├─excel_data\ # 存储 Excel 表格的目录
│ └─pictures_data\ # 存储图片的目录
├─local_data\ # 本地数据目录,用于存储从 TAPD 获取的数据、数据库等(Git 提交时会被忽略)
│ ├─msg_from_fetcher.json # 从 TAPD 获取的需求和缺陷数据
│ ├─fake_tapd.json # 假数据生成器生成的模拟 TAPD 数据
│ ├─logs\ # 日志文件目录
│ └─vector_data\ # 向量数据库文件目录
│ ├─data_vector.index # 向量数据库索引文件
│ ├─data_vector.metadata.pkl # 向量数据库元数据文件
│ └─data_vector.config.json # 向量数据库配置文件
├─mcp_tools\ # MCP 工具目录
│ ├─data_vectorizer.py # 向量化工具,支持自定义数据源的向量化
│ ├─context_optimizer.py # 上下文优化器,支持智能摘要生成
│ ├─docx_summarizer.py # 文档摘要生成器,提取 .docx 文档内容
│ ├─fake_tapd_gen.py # TAPD 假数据生成器,用于测试和演示
│ ├─word_frequency_analyzer.py # 词频分析工具,生成关键词词云统计
│ ├─data_preprocessor.py # 数据预处理工具,清理和优化 TAPD 数据
│ ├─common_utils.py # 统一的公共工具模块
│ └─example_tool.py # 示例工具
├─models\ # 模型目录
├─test\ # 测试目录
│ ├─test_data_vectorizer.py # 完整测试 data_vectorizer 向量化脚本功能
│ ├─test_word_frequency.py # 词频分析工具测试
│ └─vector_quick_start.py # 向量化功能快速启动脚本
├─.gitignore # Git 提交时遵守的过滤规则
├─.python-version # 记录 Python 版本(3.10)
├─提示词-TAPD平台MCP分析助手.md
├─TAPD平台MCP服务器开发指南.md
├─api.txt # 包含 API 密钥信息,需要自行创建(Git 提交时会被忽略)
├─main.py # 项目入口文件,无实际作用
├─pyproject.toml # 现代的 Python 依赖管理文件
├─README.md # 项目说明文档,也就是本文档
├─tapd_data_fetcher.py # 包含从 TAPD API 获取需求和缺陷数据的逻辑
├─tapd_mcp_server.py # MCP 服务器启动脚本,用于提供所有 MCP 工具
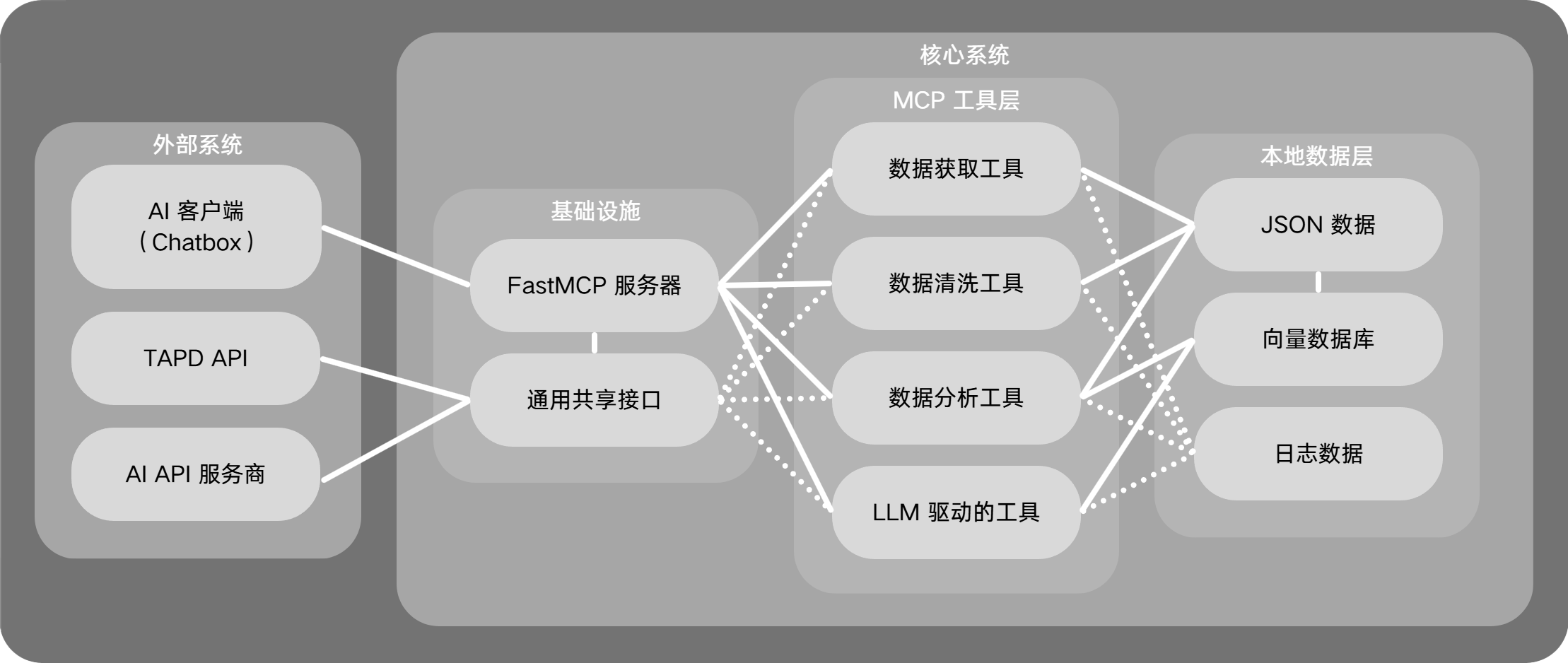
└─uv.lock # UV 包管理器使用的锁定文件架构图
迁移步骤
以下是将项目移植到其他 Windows 电脑的详细步骤(尚未测试 Mac 与 Linux):
一、环境准备
安装Python 3.10
从 Python官网 下载 Python 3.10.x 安装包(建议 3.10.11,与原环境一致)
安装时勾选
Add Python to PATH(关键!否则需手动配置环境变量)验证安装:终端运行
python --version,应输出Python 3.10.11
安装uv工具
终端运行
pip install uv(需确保pip已随Python安装):pip install uv验证安装:运行
uv --version,应显示版本信息关于如何在 UV 中切换 Python 版本,请参考 UV - 管理Python 版本、环境、第三方包 - 知乎
二、项目文件迁移
复制项目目录
将原项目目录
D:\MiniProject\MCPAgentRE完整复制到目标电脑(建议路径无中文/空格,如D:\MCPAgentRE)
三、依赖安装
创建虚拟环境
终端进入项目目录:
cd D:\MCPAgentRE(根据实际路径调整)创建虚拟环境:
uv venv该命令会在项目目录下创建一个名为
.venv的虚拟环境目录
安装项目依赖
运行依赖安装命令:
uv sync该命令会根据 pyproject.toml 安装所有依赖(包括 MCP SDK、aiohttp 等)
四、配置调整
TAPD API配置
在项目根目录下创建
api.txt文件,复制下列文本,并替换配置为目标TAPD项目的真实值:API_USER = '替换为你的TAPD API用户名' API_PASSWORD = '替换为你的TAPD API密码' WORKSPACE_ID = '替换为你的TAPD项目ID'注意:TAPD API 用户名和密码需要从 TAPD 平台获取,具体操作请参阅开放平台文档
WORKSPACE_ID:TAPD 项目 ID,可通过 TAPD 平台获取
提交 Git 时会根据
.gitignore忽略api.txt文件,确保敏感信息不被泄露
LLM API配置
特别提醒:若您的 TAPD 数据需要较高的保密等级,请不要配置此项,或自行在 common_utils.py 的
class APIManager中添加满足保密需求的 LLM API系统现已支持两种 LLM API 提供商,您可以根据需要选择配置:
DeepSeek API配置
如果您需要使用智能摘要功能(generate_tapd_overview)或 description 优化功能(preprocess_tapd_description),需要配置 DeepSeek 或 SiliconFlow API 密钥:
获取API密钥:访问 DeepSeek 开放平台 注册并获取 API 密钥
设置环境变量(Windows PowerShell):
# 临时设置(仅当前会话有效) $env:DS_KEY = "your-deepseek-api-key-here" # 永久设置(推荐) [Environment]::SetEnvironmentVariable("DS_KEY", "your-deepseek-api-key-here", "User")
SiliconFlow API配置
SiliconFlow 提供多种优质模型,包括 DeepSeek、Kimi、Qwen 等:
获取API密钥:访问 SiliconFlow 开放平台 注册并获取 API 密钥
如果这是你的首次注册,在 注册页面 可以填写我的邀请码
nYbojgoI,成功注册后双方均可获得 RMB 14 额度,等价于 100w tokens 的免费试用额度设置环境变量(Windows PowerShell):
# 临时设置(仅当前会话有效) $env:SF_KEY = "your-siliconflow-api-key-here" # 永久设置(推荐) [Environment]::SetEnvironmentVariable("SF_KEY", "your-siliconflow-api-key-here", "User")验证配置:
echo $env:DS_KEY echo $env:SF_KEY注意事项:
设置环境变量后需重启编辑器和 MCP 客户端
如果不配置 API 密钥,智能摘要工具会返回错误提示,但不影响其他功能的使用
若需要使用 SiliconFlow 的其他模型,可在 common_utils.py 文件头部修改
SF_DEFAULT_MODEL变量,或在环境变量中配置SF_DEFAULT_MODEL详细配置说明请参考 SiliconFlow API Docs 与 DeepSeek API Docs
五、测试运行
在终端进入项目文件夹
终端运行:
cd D:\MCPAgentRE(根据实际路径调整)
测试模式
这部分已被移动至 测试模式.md
正常模式
MCP 服务器启动
确保
tapd_mcp_server.py的 main 函数中没有任何 print 语句(或已注释掉),以避免在启动时输出调试信息。运行 MCP 服务器(此操作将由 AI 客户端根据配置文件自动执行,无需手动操作):
uv run tapd_mcp_server.pyMCP 服务调试
确保 tapd_mcp_server.py 的 main 函数中没有任何 print 语句(或已注释掉),以避免在启动时输出调试信息。
运行MCP调试器:
npx -y @modelcontextprotocol/inspector uv --directory . run tapd_mcp_server.py操作文档:调试器 Inspector - MCP 官方文档中文版
WorkFlow 脚本运行
评分规则配置
# 查看规则配置
uv run mcp_tools/test_case_rules_customer.py
# 修改规则配置
uv run mcp_tools/test_case_rules_customer.py --config
# 重置为默认配置
uv run mcp_tools/test_case_rules_customer.py --reset
# 查看帮助信息
uv run mcp_tools/test_case_rules_customer.py --help运行需求单知识库
uv run mcp_tools/test_case_require_list_knowledge_base.py运行 AI 评估器
运行前,请将需要处理的集成用例 Excel 文件放置于
local_data文件夹中
uv run mcp_tools/test_case_evaluator.py六、常见问题排查
依赖缺失:若提示
ModuleNotFoundError,检查是否执行uv add命令,或尝试uv add <缺失模块名>API连接失败:确认
API_USER/API_PASSWORD/WORKSPACE_ID正确,且TAPD账号有对应项目的读取权限Python版本不匹配:确保目标电脑Python版本为3.10.x(通过
python --version验证)
如何将项目连接到AI客户端
前提条件
已在本地电脑上完成项目的迁移和验证
已安装并运行 MCP 服务器
已在本地电脑上安装并运行 AI 客户端(以 Claude Desktop 为例)
连接步骤
配置 Chatbox 以使用 MCP 服务器
打开 Chatbox
配置 MCP 服务器
在 Chatbox 的
设置中,找到MCP标签页在
自定义 MCP 服务器栏,点击添加服务器:复制以下 JSON 配置:
{ "mcpServers": { "tapd_mcp_server": { "command": "uv", "args": [ "--directory", "D:\\MiniProject\\MCPAgentRE", "run", "tapd_mcp_server.py" ] } } }确保
--directory指向的是MCP服务器所在的目录,即D:\MiniProject\MCPAgentRE(请按照实际目录修改)
点击
从剪贴板中的JSON导入
配置 Claude Desktop 以使用 MCP 服务器
打开Claude Desktop
启动Claude Desktop客户端
配置MCP服务器
使用快捷键
Ctrl + ,打开设置页面(或者点击左上角菜单图标 -File-Settings)选择
Developer选项卡点击
Edit Config按钮,将会弹出文件资源管理器编辑高亮提示的
claude_desktop_config.json文件,添加以下内容(若有其他内容,请注意层级关系):{ "mcpServers": { "tapd_mcp_server": { "command": "uv", "args": [ "--directory", "D:\\MiniProject\\MCPAgentRE", "run", "tapd_mcp_server.py" ] } } }注意:
command字段指定了运行MCP服务器的命令(通常为uv)args字段指定了运行MCP服务器的参数,包括项目目录(--directory)和运行的脚本文件(run tapd_mcp_server.py)确保
--directory指向的是MCP服务器所在的目录,即D:\MiniProject\MCPAgentRE(请按照实际目录修改)
保存并关闭文件
设置LLM提示词【推荐】
将 提示词-TAPD平台MCP分析助手.md 文件中的内容复制到 Chatbox 的提示词设置中。
除 Chatbox 外,其他 AI 客户端也可以使用相同的提示词内容。
此功能将帮助您更好地与 MCP 服务器进行交互。根据实际需求调整提示词内容,以提高交互效果。
测试连接
开启一条新对话(若使用 Chatbox,需要点击对话框底部的锤子图标,勾选
tapd_mcp_server)在新的聊天窗口中,输入以下内容测试基础功能:
请使用 tapd_mcp_server 插件获取 TAPD 项目的需求和缺陷数据点击发送按钮,等待 MCP 服务器返回数据
检查返回的数据是否符合预期,包括需求和缺陷的数量和内容
注意事项
确保 MCP 服务器的路径和参数配置正确
如果 MCP 服务器运行时出现错误,检查 MCP 服务器的日志文件(通常位于
%APPDATA%\Claude\logs)以获取更多信息如果 AI 客户端无法识别 MCP 插件,可能需要重新安装或更新 AI 客户端
您可以运行以下命令列出最近的日志并跟踪任何新日志(在 Windows 上,它只会显示最近的日志):
type "%APPDATA%\Claude\logs\mcp*.log"
扩展MCP服务器功能
为了让项目目录结构更清晰,建议将 MCP 工具函数放在
mcp_tools文件夹中。下面是一个添加新工具函数的示例方法。拓展阅读: TAPD平台MCP服务器开发指南.md
添加新 MCP 函数脚本
创建工具函数文件
在
mcp_tools文件夹中创建新的 Python 文件(如new_tool.py)编写异步函数,示例模板:
async def new_function(param1: str, param2: int) -> dict: """ 新工具函数说明 参数: param1: 参数说明 param2: 参数说明 返回: 返回数据结构说明 """ # 函数实现 return {"result": "处理结果"}
注册工具到服务器
在 tapd_mcp_server.py 中添加:
导入语句:
from mcp_tools.new_tool import new_function使用
@mcp.tool()装饰器注册函数:@mcp.tool() async def new_tool(param1: str, param2: int) -> dict: """ 工具功能详细说明 参数: param1 (str): 参数详细说明 param2 (int): 参数详细说明 返回: dict: 返回数据结构详细说明 """ return await new_function(param1, param2)
描述文档最佳实践
为AI客户端添加清晰的文档:
函数级文档:使用详细的中文说明,包括参数类型和返回值结构
参数说明:明确每个参数的数据类型和预期用途
返回说明:详细描述返回字典的每个字段
示例:提供调用示例和预期输出
相关文档或网址
{kind=link}
{kind=link}
Maintenance
Latest Blog Posts
- Your AI Chatbot Just Exposed Your CEO's Salary to an InternBy Om-Shree-0709 on .Agent IdentityMCP SecurityOAuth Delegation
- Why MCP Servers Need Execution Sandboxing (And Why Your Current Stack Isn't Enough)By Om-Shree-0709 on .Agentic AiPrompt InjectionWebAssembly
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/OneCuriousLearner/MCPAgentRE'
If you have feedback or need assistance with the MCP directory API, please join our Discord server