
Provides comprehensive access to Apache Flink stream processing through SQL Stream Builder (SSB), enabling management of streaming jobs, real-time data queries, and Kafka integration with 80+ tools for complete stream processing control.
Enables full management of Cloudera Data Platform (CDP) SQL Stream Builder deployments through Knox gateway integration, supporting bearer tokens and providing access to enterprise streaming analytics capabilities.
Includes Docker Compose setup for local SSB development environment with PostgreSQL, Kafka, Flink, NiFi, Qdrant, and Apache Knox services for complete streaming infrastructure deployment.
Supports project configuration management through Git sync capabilities, enabling export/import of SSB projects, configuration versioning, and DevOps workflows for streaming applications.
Utilizes PostgreSQL as the metadata database for SSB deployments, storing stream definitions, job configurations, and system state information in the Docker Compose environment.
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@SSB MCP Servershow me the status of all running SQL streams"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
SSB MCP Server
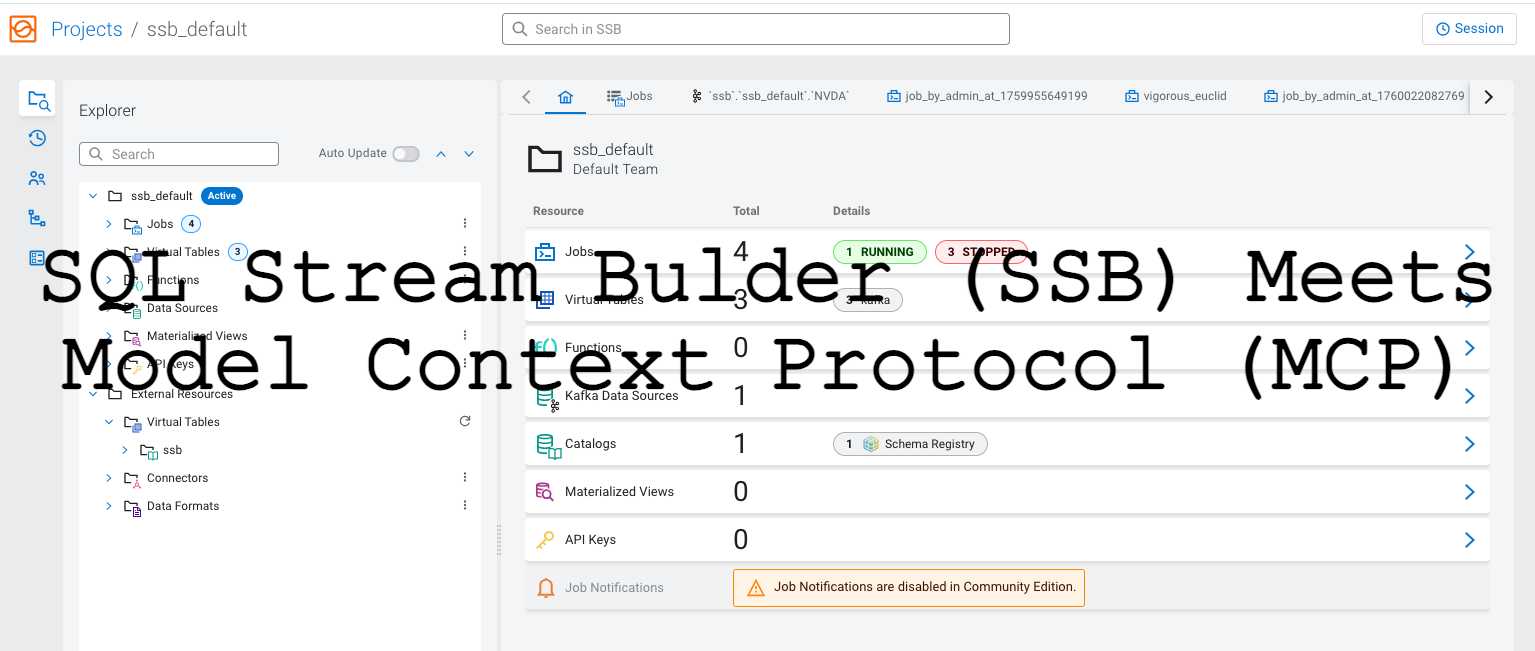 The main SSB interface showing the home dashboard with available streams and jobs, featuring the SSB MCP Server integration with prominent branding.
The main SSB interface showing the home dashboard with available streams and jobs, featuring the SSB MCP Server integration with prominent branding.
Model Context Protocol server providing comprehensive access to SQL Stream Builder (SSB) with support for both direct SSB access and Apache Knox integration.
Works with both standalone SSB deployments and Cloudera Data Platform (CDP) SSB deployments - provides full access to SSB functionality through Claude Desktop.
Features
Multiple Authentication Methods:
Direct SSB Authentication: Basic auth for standalone SSB deployments
Knox Integration: Bearer tokens, cookies, and passcode tokens for CDP deployments
Read-only by default - Safe exploration of SSB streams and configuration
Comprehensive SSB API coverage with 80+ MCP tools for complete SSB management:
Advanced Job Management: Event history, state management, job copying, data source cloning
Monitoring & Diagnostics: System health, performance counters, SQL analysis
Enhanced Table Management: Detailed tables, hierarchical structure, validation, creation
Connector & Format Management: Data formats, connector details, JAR information
User & Project Management: Settings, projects, user information, project creation
API Key Management: Key lifecycle management, creation, deletion, details
Environment Management: Environment switching, configuration, creation
Sync & Configuration: Project export/import, sync management, validation
UDF Management: UDF lifecycle, execution, artifacts, custom functions
Stream Management: List, create, update, delete, start, stop SQL streams
Query Execution: Execute SQL queries and get real-time results with sampling
Sample Data Access: Retrieve streaming data samples from running jobs
Job Management: Monitor job status, get job details, and manage job lifecycle
Schema Discovery: Explore table schemas and available tables
Function Management: List and inspect user-defined functions
Connector Management: Explore available connectors
Kafka Integration: List and inspect Kafka topics
Cluster Monitoring: Get cluster info and health status
Performance Metrics: Monitor stream performance and metrics
Quick Start
For Standalone SSB Deployments (Docker Compose)
Start SSB services:
git clone https://github.com/your-org/ssb-mcp-server.git cd ssb-mcp-server docker-compose up -dConfigure Claude Desktop - Edit
~/Library/Application Support/Claude/claude_desktop_config.json:{ "mcpServers": { "ssb-mcp-server": { "command": "/FULL/PATH/TO/SSB-MCP-Server/run_mcp_server.sh", "args": [], "cwd": "/FULL/PATH/TO/SSB-MCP-Server" } } }Restart Claude Desktop and start interacting with your SSB streams!
For CDP SSB deployments
Your SSB API base URL will typically be:
Get your Knox JWT token from the CDP UI and use it with the configurations below.
Setup
Option 1: Claude Desktop (Local)
Clone and install:
git clone https://github.com/your-org/ssb-mcp-server.git cd ssb-mcp-server python3 -m venv .venv source .venv/bin/activate pip install -e .Configure Claude Desktop - Edit
~/Library/Application Support/Claude/claude_desktop_config.json:{ "mcpServers": { "ssb-mcp-server": { "command": "/FULL/PATH/TO/SSB-MCP-Server/.venv/bin/python", "args": [ "-m", "ssb_mcp_server.server" ], "env": { "MCP_TRANSPORT": "stdio", "SSB_API_BASE": "https://ssb-gateway.yourshere.cloudera.site/ssb/api/v1", "KNOX_TOKEN": "<your_knox_bearer_token>", "SSB_READONLY": "true" } } } }Restart Claude Desktop and start asking questions about your SSB streams!
Option 2: Cloudera AI Agent Studio
For use with Cloudera AI Agent Studio, configure using environment variables:
Configuration Template: Use config/cloudera_ai_agent_studio_template.json as a starting point.
Environment Variables for Cloudera AI Agent Studio:
Configuration Options
Configuration can be done via environment variables or JSON configuration files. Environment variables take precedence over JSON configuration.
JSON Configuration File
The MCP server can load configuration from config/cloud_ssb_config.json:
Environment Variables
All configuration can also be done via environment variables:
Direct SSB Authentication (Standalone)
Variable | Required | Description |
| Yes | Full SSB API URL (e.g., |
| Yes | SSB username (e.g., |
| Yes | SSB password (e.g., |
| No | Read-only mode (default: |
| No | HTTP timeout in seconds (default: |
Knox Authentication (CDP)
Variable | Required | Description |
| Yes* | Base URL for SSB host (e.g., |
| Yes* | Tenant name (e.g., |
| Yes* | Knox JWT token for authentication |
| No | Alternative: provide full cookie string instead of token |
| No | Alternative: Knox passcode token (auto-exchanged for JWT) |
| No | Knox username for basic auth |
| No | Knox password for basic auth |
| No | Verify SSL certificates (default: |
| No | Path to CA certificate bundle |
| No | Read-only mode (default: |
| No | HTTP timeout in seconds (default: |
| No | MVE API username for Basic authentication |
| No | MVE API password for Basic authentication |
Legacy Configuration (Still Supported)
Variable | Required | Description |
| No | Legacy: Full Knox gateway URL |
| No | Legacy: Full SSB API URL |
| No | Legacy: Full MVE API URL |
* Either SSB_API_BASE (for direct) or KNOX_GATEWAY_URL (for Knox) is required
Example Functionality
The SSB MCP Server provides comprehensive access to SQL Stream Builder through Claude Desktop. Here are some visual examples of the functionality:
Standard Brand Box Versions:
 - Top positioned with yellow text
- Top positioned with yellow text
Available Tools
🔧 Advanced Job Management
get_job_events(job_id)- Get detailed job event history and timelineget_job_state(job_id)- Get comprehensive job state informationget_job_mv_endpoints(job_id)- Get materialized view endpoints for a jobcreate_job_mv_endpoint(job_id, mv_config)- Create or update materialized view endpointcopy_job(job_id)- Duplicate an existing jobcopy_data_source(data_source_id)- Clone a data source
📊 Monitoring & Diagnostics
get_diagnostic_counters()- Get system performance counters and diagnosticsget_heartbeat()- Check system health and connectivityanalyze_sql(sql_query)- Analyze SQL query without execution (syntax, performance)
🗂️ Enhanced Table Management
list_tables_detailed()- Get comprehensive table informationget_table_tree()- Get hierarchical table structure organized by catalogvalidate_data_source(data_source_config)- Validate data source configurationcreate_table_detailed(table_config)- Create table with full configurationget_table_details(table_id)- Get detailed information about a specific table
🔌 Connector & Format Management
list_data_formats()- List all available data formatsget_data_format_details(format_id)- Get detailed information about a specific data formatcreate_data_format(format_config)- Create a new data formatget_connector_jar(connector_type)- Get connector JAR informationget_connector_type_details(connector_type)- Get detailed connector type informationget_connector_details(connector_id)- Get detailed connector information
👤 User & Project Management
get_user_settings()- Get user preferences and settingsupdate_user_settings(settings)- Update user configurationlist_projects()- List available projectsget_project_details(project_id)- Get project informationcreate_project(project_config)- Create a new projectget_user_info()- Get current user information
🔑 API Key Management
list_api_keys()- List user API keyscreate_api_key(key_config)- Create new API keydelete_api_key(key_id)- Delete API keyget_api_key_details(key_id)- Get API key information
🌍 Environment Management
list_environments()- List available environmentsactivate_environment(env_id)- Activate/switch to an environmentget_environment_details(env_id)- Get environment configurationcreate_environment(env_config)- Create new environmentdeactivate_environment()- Deactivate current environment
🔄 Sync & Configuration
get_sync_config()- Get sync configurationupdate_sync_config(config)- Update sync configurationdelete_sync_config()- Delete sync configurationvalidate_sync_config(project)- Validate sync configuration for a projectexport_project(project)- Export project configurationimport_project(project, config)- Import project configuration
📈 UDF Management
list_udfs_detailed()- Get comprehensive UDF informationrun_udf(udf_id, parameters)- Execute UDF functionget_udf_artifacts()- Get UDF artifacts and dependenciescreate_udf(udf_config)- Create custom UDFupdate_udf(udf_id, udf_config)- Update UDF configurationget_udf_details(udf_id)- Get detailed UDF informationget_udf_artifact_details(artifact_id)- Get UDF artifact detailsget_udf_artifact_by_type(artifact_type)- Get UDF artifacts by type
Stream Management
list_streams()- List all SQL streams (jobs)get_stream(stream_name)- Get details of a specific streamcreate_stream(stream_name, sql_query, description?)- Create new stream (write mode)update_stream(stream_name, sql_query, description?)- Update an existing streamdelete_stream(stream_name)- Delete a streamstart_stream(stream_name)- Start a streamstop_stream(stream_name)- Stop a stream
Query Execution & Sample Data
execute_query(sql_query, limit?)- Execute SQL query and create SSB jobexecute_query_with_sampling(sql_query, sample_interval, sample_count, window_size, sample_all_messages)- Execute query with custom samplingget_job_status(job_id)- Get status of a specific SSB jobget_job_sample(sample_id)- Get sample data from a job executionget_job_sample_by_id(job_id)- Get sample data from a job by job IDlist_jobs_with_samples()- List all jobs with their sample information
Job Management & Control
stop_job(job_id, savepoint)- Stop a specific SSB jobexecute_job(job_id, sql_query)- Execute/restart a job with new SQLrestart_job_with_sampling(job_id, sql_query, sample_interval, sample_all_messages)- Restart job with sampling optionsconfigure_sampling(sample_id, sample_interval, sample_count, window_size, sample_all_messages)- Configure sampling parameters
Data Sources & Schema
list_tables()- List all available tables (data sources)get_table_schema(table_name)- Get table schema informationcreate_kafka_table(table_name, topic, kafka_connector_type, bootstrap_servers, format_type, scan_startup_mode, additional_properties?)- Create new table with local-kafka enforcementregister_kafka_table(table_name, topic, schema_fields?, use_ssb_prefix?, catalog?, database?)- Register Kafka table in Flink catalog (makes it queryable)validate_kafka_connector(kafka_connector_type)- Validate that a connector type is local-kafka
Functions and Connectors
list_udfs()- List user-defined functionsget_udf(udf_name)- Get UDF detailslist_connectors()- List available connectorsget_connector(connector_name)- Get connector details
Kafka Integration
list_topics()- List Kafka topicsget_topic(topic_name)- Get topic details
Cluster Management
get_cluster_info()- Get cluster informationget_cluster_health()- Get cluster health statusget_ssb_info()- Get SSB version and system info
Example Usage
Once configured, you can ask Claude questions like:
Basic Information
"What version of SSB am I running?"
"List all my SQL streams"
"What tables are available for querying?"
"What connectors are available?"
"List all Kafka topics"
"How is the cluster health?"
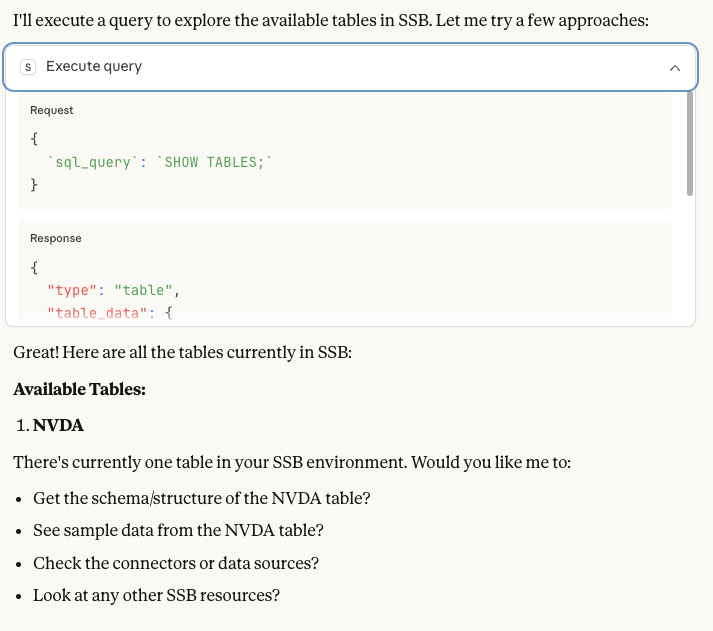 Claude can show all available tables in the SSB environment, including both built-in and custom tables.
Claude can show all available tables in the SSB environment, including both built-in and custom tables.
Query Execution & Data Access
"Execute this query: SELECT * FROM NVDA"
"Create a job with sample all messages: SELECT * FROM NVDA"
"Show me the status of job 1234"
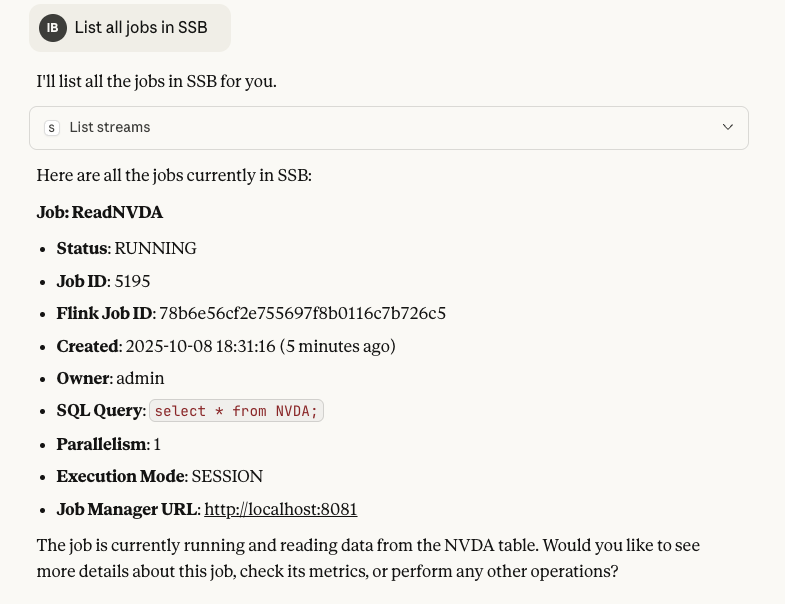 Claude can list all running SSB jobs, showing their status, creation time, and details.
Claude can list all running SSB jobs, showing their status, creation time, and details.
"Get sample data from job 1234"
"List all jobs with their sample information"
"Show me the latest data from the ReadNVDA job"
Job Management & Control
"Stop job 1234"
"Restart job 1234 with sample all messages"
"Restart job 1234 with custom sampling (500ms interval)"
"Configure sampling for job 1234 to sample all messages"
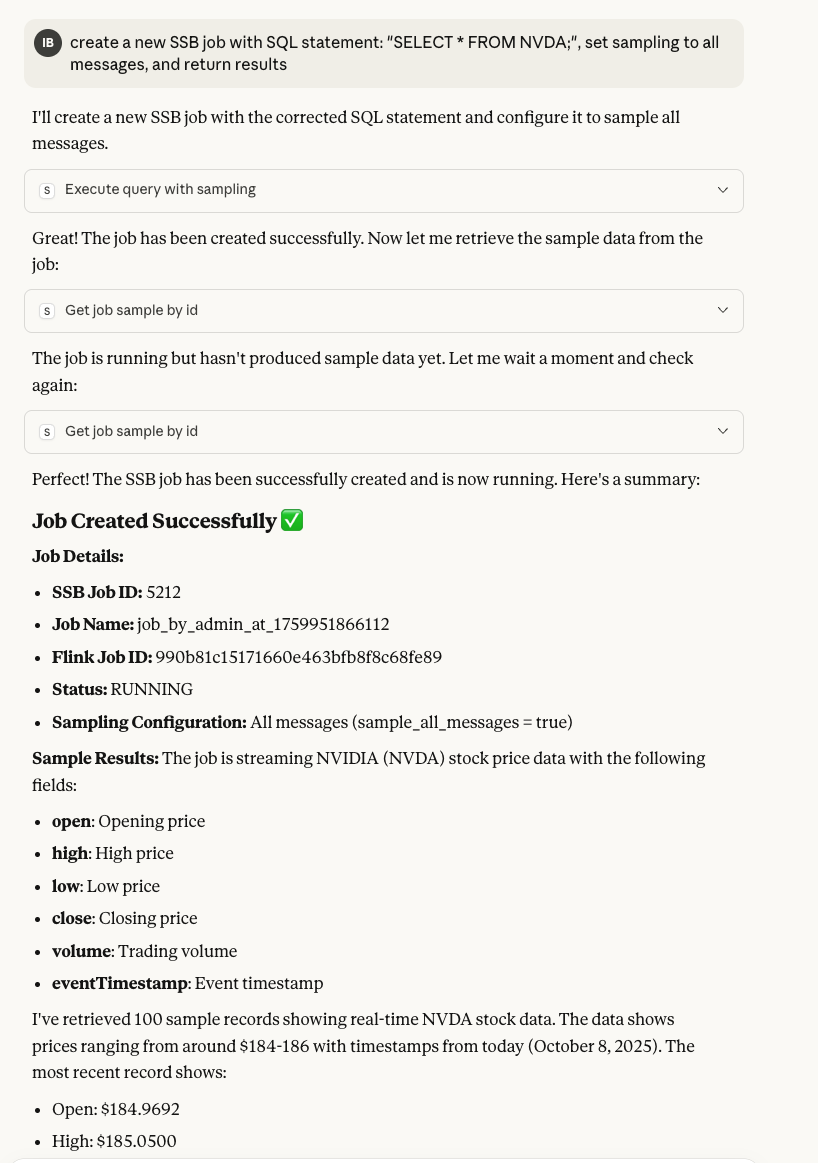 Claude can create new SSB jobs by executing SQL queries, with full job management capabilities.
Claude can create new SSB jobs by executing SQL queries, with full job management capabilities.
Stream Management
"Create a new stream called 'sales_analysis' with this SQL: SELECT * FROM sales WHERE amount > 1000"
"Show me the details of the 'user_events' stream"
"What's the status of my 'sales_stream'?"
Kafka Table Management
"Create a local Kafka table called 'user_events' from topic 'user-events'"
"Register a Kafka table in the Flink catalog to make it queryable"
"Create a local Kafka table with JSON format"
 Claude can create new virtual tables connected to Kafka topics, with proper schema and connector configuration.
Claude can create new virtual tables connected to Kafka topics, with proper schema and connector configuration.
"Validate if 'local-kafka' is a valid connector type"
"Create a virtual table for real-time data streaming"
Advanced Job Management
"Show me the event history for job 1234"
"Get the detailed state of job 1234"
"Copy job 1234 to create a new job"
"Clone the data source for table 'user_events'"
"Get materialized view endpoints for job 1234"
"Create a materialized view endpoint for job 1234"
Materialized Views
"Get materialized view endpoints for job 1234"
"Create a materialized view endpoint for job 1234"
⚠️ Important Limitation: Materialized Views (MVs) must be created through the SSB UI interface. The MCP server can retrieve data from existing materialized views but cannot create new ones programmatically. To create a materialized view:
Navigate to your job in the SSB UI
Go to the Materialized Views section
Configure and create the MV through the UI
Use the MCP server to query the created MV data
⚠️ Known Limitations
Job Restart Capabilities
Limited Restart Functionality: The SSB API provides limited job restart capabilities:
✅ What Works:
stop_job(job_id, savepoint=True)- Stops jobs with savepointsrestart_job_with_sampling(job_id, sql_query, ...)- Creates new jobs with updated SQLPUT /jobs/{id}- Updates job configuration
❌ What Doesn't Work:
Direct job restart via dedicated restart endpoints
start_stream(stream_name)- Stream start endpoints return 404stop_stream(stream_name)- Stream stop endpoints return 404execute_job(job_id, sql_query)- Database connection issues
Recommended Restart Strategy:
Virtual Tables and System Catalogs
Limited Table Discovery: The SSB environment has limited traditional table support:
✅ What's Available:
System Catalogs: 2 catalogs (
default_catalog,ssb)Functions: 206 built-in functions for data processing
Materialized Views: Accessible via MVE API (not SQL)
❌ What's Not Available:
Traditional database tables (SHOW TABLES returns empty)
Standard information_schema queries
Direct SQL access to materialized views
System tables for metadata discovery
Data Access Methods:
Direct SQL: Limited to functions and basic queries
MVE API: For materialized view data (requires Basic Auth)
Job Execution: For creating and managing data streams
Authentication and Configuration
Configuration Loading: The MCP server now supports both JSON configuration files and environment variables:
✅ JSON Configuration: Update config/cloud_ssb_config.json and restart the MCP server
✅ Environment Variables: Set environment variables (takes precedence over JSON)
✅ MVE API Credentials: Configure mve_username and mve_password in JSON or environment variables
⚠️ Important: For Cloudera AI Agent Studio, use environment variables:
Token Expiration: JWT tokens expire and require manual refresh. The MCP server doesn't automatically refresh tokens.
Cloud Environment Limitations
Endpoint Availability: Some endpoints may not be available in cloud environments:
❌ Cloud Limitations:
list_projects()- May return "Request method 'GET' not supported"get_heartbeat()- May return empty responsescreate_stream()andexecute_query()- May timeout with 500 errorsSHOW JOBS- Not supported in cloud environment
✅ Workarounds:
Use
list_streams()instead oflist_projects()Skip heartbeat checks in cloud environments
Handle timeouts gracefully with retry logic
Use job management tools instead of SHOW commands
Materialized View Engine (MVE) API
Separate Authentication: MVE API requires different authentication than the main SSB API:
Authentication Requirements:
SSB API: Bearer token authentication
MVE API: Basic authentication (username:password)
Credentials: Must be provided separately for MVE access
Access Pattern:
Monitoring & Diagnostics
"Check the system heartbeat and health"
"Show me the diagnostic counters"
"Analyze this SQL query for performance: SELECT * FROM NVDA WHERE close > 100"
"What's the current system performance?"
Enhanced Table Management
"Show me detailed information about all tables"
"Get the hierarchical table structure by catalog"
"Validate this data source configuration"
"Create a new table with full configuration"
"Get detailed information about table 'user_events'"
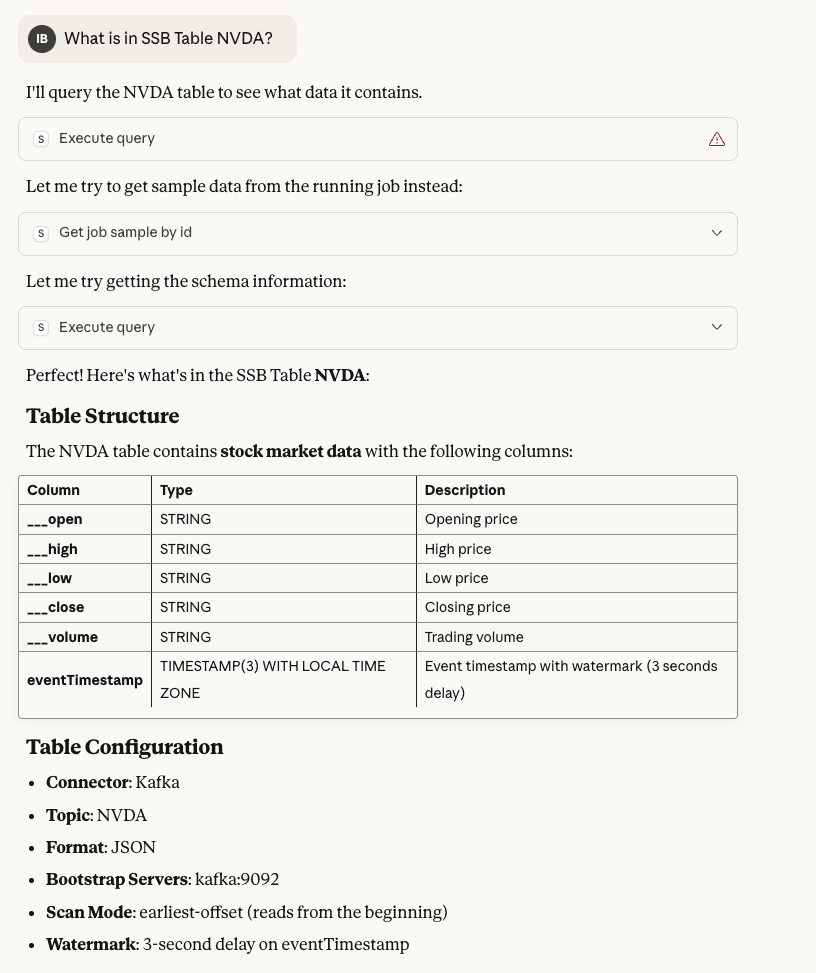 Claude can provide detailed information about specific tables, including their schema and configuration.
Claude can provide detailed information about specific tables, including their schema and configuration.
User & Project Management
"Show me my user settings and preferences"
"Update my user settings to enable dark mode"
"List all available projects"
"Create a new project called 'analytics'"
"Get details about project 'ffffffff'"
"Show me my user information"
API Key Management
"List all my API keys"
"Create a new API key for external access"
"Delete API key 'key123'"
"Get details about API key 'key123'"
Environment Management
"List all available environments"
"Switch to environment 'production'"
"Create a new environment called 'staging'"
"Get details about environment 'dev'"
"Deactivate the current environment"
Sync & Configuration
"Show me the current sync configuration"
"Update the sync configuration for Git integration"
"Export project 'analytics' configuration"
"Import project configuration from Git"
"Validate sync configuration for project 'test'"
UDF Management
"List all user-defined functions with details"
"Run UDF 'custom_aggregate' with parameters"
"Create a new UDF for data transformation"
"Update UDF 'my_function' configuration"
"Get UDF artifacts and dependencies"
Sample Data Examples
The MCP server can retrieve real-time streaming data samples with different sampling modes:
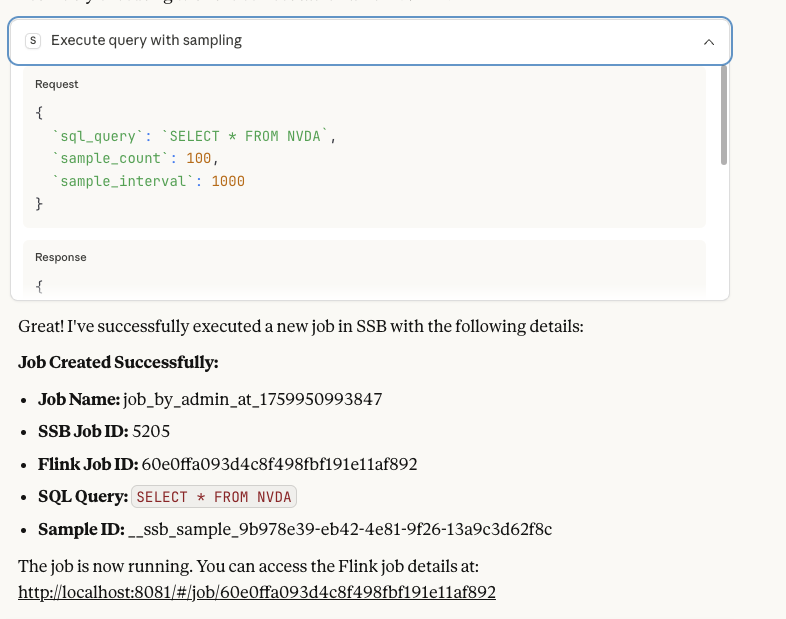 Claude can retrieve real-time sample data from running jobs, showing actual streaming data.
Claude can retrieve real-time sample data from running jobs, showing actual streaming data.
Periodic Sampling (default):
Sample All Messages Mode:
SQL Query Features
Automatic Semicolon Handling: All SQL queries are automatically terminated with semicolons
Flexible Sampling: Choose between periodic sampling or sample all messages
Job Control: Start, stop, and restart jobs with different configurations
Real-time Data: Access streaming data samples from running jobs
Advanced Features
Sample All Messages
For comprehensive data sampling, use the sample_all_messages=True option:
Configuration:
sample_interval: 0(sample immediately)sample_count: 10000(high count to capture all messages)window_size: 10000(large window for comprehensive sampling)
Custom Sampling Configuration
Fine-tune sampling behavior for your specific needs:
Job Management
Complete job lifecycle management:
Kafka Table Creation
Create tables that are restricted to local-kafka connector only:
Two-Step Process: Creating a Kafka table requires two steps:
Create Data Source: Use
create_kafka_table()to create the data source configurationRegister in Catalog: Use
register_kafka_table()to make the table queryable
Automatic Registration: The register_kafka_table() function:
Uses DDL to register the table in the Flink catalog (default:
ssb.ssb_default, falls back todefault_catalog.ssb_default)Configurable catalog and database parameters for flexible namespace control
Automatic catalog fallback when requested catalog is not available
Creates tables in the same database as existing tables like NVDA by default
Automatically adds
ssb_prefix to table names (configurable)Automatically creates a schema based on the topic data
Verifies the table is available for querying by checking the correct database context
Returns confirmation of successful registration with full table name, catalog, and database info
Naming Conventions:
Default: Tables get
ssb_prefix automatically (e.g.,user_events→ssb_user_events)Override: Use
use_ssb_prefix=Falseto disable prefixExisting: Tables already starting with
ssb_are not modified
Namespace Configuration:
Default: Tables created in
ssb.ssb_defaultnamespace (falls back todefault_catalog.ssb_defaultifssbcatalog unavailable)Custom Catalog: Use
catalogparameter to specify different catalogCustom Database: Use
databaseparameter to specify different databaseAutomatic Fallback: System automatically falls back to
default_catalogif requested catalog is not availableFull Control: Both catalog and database are configurable for maximum flexibility
Verification:
Use
SHOW TABLES;to confirm tables are available for queryingTables are created in
default_catalog.ssb_defaultnamespace (same as NVDA)Use full namespace (
default_catalog.ssb_default.TABLE_NAME) or switch database context withUSE default_catalog.ssb_default;All virtual Kafka tables are co-located with existing tables for easy querying
Supported Connector:
local-kafka- Local Kafka connector (only option for virtual tables)
Supported Formats:
json- JSON format (default)csv- CSV formatavro- Apache Avro formatCustom format strings
Docker Compose Setup
The repository includes a complete Docker Compose setup for local development and testing:
Services Included
PostgreSQL: Database for SSB metadata
Kafka: Message streaming platform
Flink: Stream processing engine
NiFi: Data flow management
Qdrant: Vector database
SSB SSE: SQL Stream Builder Streaming SQL Engine
SSB MVE: SQL Stream Builder Materialized View Engine
Apache Knox: Gateway for secure access (optional)
Starting the Environment
Access Points
SSB SSE: http://localhost:18121
SSB MVE: http://localhost:18131
Flink Job Manager: http://localhost:8081
NiFi: http://localhost:8080
Knox Gateway: https://localhost:8444 (if enabled)
Write Operations
By default, the server runs in read-only mode for CDP deployments and write-enabled for standalone deployments. To change this:
Set
SSB_READONLY=false(enable writes) orSSB_READONLY=true(read-only)Restart the MCP server
Write operations include:
Creating, updating, and deleting streams
Executing SQL queries that create jobs
Managing job lifecycle (start, stop, restart)
Configuring sampling parameters
Job control and management
Creating Kafka-only tables (enforced validation)
Comprehensive Capabilities
The SSB MCP Server now provides 80+ MCP tools covering 80%+ of the SSB API, making it the most comprehensive SSB management platform available through Claude Desktop.
📊 Coverage Statistics
Total MCP Tools: 80+ (up from 33)
API Coverage: 80%+ (up from 20%)
Functional Categories: 15 (up from 6)
Available Endpoints: 67+ (up from 15)
🎯 Key Capabilities
Complete SSB Management
Job Lifecycle: Create, monitor, control, copy, and manage jobs
Data Management: Tables, schemas, validation, and hierarchical organization
System Monitoring: Health checks, diagnostics, and performance tracking
User Management: Settings, projects, environments, and API keys
DevOps Integration: Sync, export/import, and configuration management
Advanced Features
Real-time Sampling: Flexible data sampling with "sample all messages" option
SQL Analysis: Query analysis without execution for performance optimization
Materialized Views: Create and manage materialized view endpoints
Custom UDFs: User-defined function management and execution
Environment Control: Multi-environment support with switching capabilities
Project Management: Full project lifecycle with export/import capabilities
Enterprise Ready
Security: API key management and user authentication
Monitoring: Comprehensive system health and performance tracking
Scalability: Support for multiple projects and environments
Integration: Git sync, configuration management, and DevOps workflows
Flexibility: Configurable catalogs, databases, and naming conventions
🚀 Use Cases
Data Engineers
Stream processing job management and monitoring
Real-time data sampling and analysis
Table schema management and validation
Performance optimization and troubleshooting
DevOps Engineers
Environment management and configuration
Project export/import and version control
System monitoring and health checks
API key management and security
Data Scientists
Custom UDF development and execution
Data format management and validation
Query analysis and optimization
Real-time data exploration
Platform Administrators
User and project management
System diagnostics and monitoring
Connector and format management
Sync configuration and validation
Testing
The SSB MCP Server includes a comprehensive test suite. See Testing/README.md for detailed testing documentation, including:
Quick functionality tests
Comprehensive test suite covering all 80+ MCP tools
Cloud SSB test protocols
Test configuration and best practices
Detailed test results and analysis
Quick Start:
Troubleshooting
Common Issues
"Unauthorized" errors: Check your authentication credentials
For direct SSB: Verify
SSB_USERandSSB_PASSWORDFor Knox: Verify
KNOX_TOKENorKNOX_USER/KNOX_PASSWORD
"Connection refused" errors: Ensure SSB services are running
Check
docker-compose psfor service statusVerify port mappings in docker-compose.yml
"No sample data available": Jobs may need time to produce data
Check job status with
get_job_status(job_id)Verify the job is running and has sample configuration
Try using
sample_all_messages=Truefor comprehensive sampling
Job restart failures: If job restart fails
Use
restart_job_with_sampling()instead ofexecute_job()Check if the job is in a state that allows restarting
Create a new job if restart is not possible
Note:
start_stream()andstop_stream()methods don't work (404 errors)
SSL certificate errors: For Knox deployments
Set
KNOX_VERIFY_SSL=falsefor self-signed certificatesOr provide proper CA bundle with
KNOX_CA_BUNDLE
Kafka table creation errors: If table creation fails
Verify that only local-kafka connector is used (enforced)
Check that the Kafka topic exists and is accessible
Ensure bootstrap servers are correctly configured
Use
validate_kafka_connector()to check connector validity
Virtual tables not available for querying: After creating Kafka tables
Important: Creating a data source doesn't automatically make it available for querying
Data sources need to be manually registered in the Flink catalog through the SSB UI
Use
SHOW TABLES;to see which tables are actually available for queryingOnly tables that appear in
SHOW TABLES;can be queried via SQL
Configuration not updating: After updating
config/cloud_ssb_config.jsonImportant: Environment variables take precedence over JSON configuration
For JSON config: Update
config/cloud_ssb_config.jsonand restart the MCP serverFor environment variables:
export KNOX_TOKEN="new_token"and restartCheck which method is being used by your deployment
Materialized View access errors: When accessing MVE API
MVE API requires Basic authentication (username:password)
SSB API uses Bearer token authentication
Use different credentials for MVE API access
Check that the job is running before accessing its MV
Empty table lists: When running
SHOW TABLESSSB environment has limited traditional table support
Use
list_streams()to see available jobsAccess materialized views via MVE API, not SQL
Focus on job-based data processing rather than table queries
Debug Mode
Enable debug logging by setting environment variable:
Security
All sensitive data (passwords, tokens, secrets) is automatically redacted in responses
Large collections are truncated to prevent overwhelming the LLM
Read-only mode is enabled by default for CDP deployments to prevent accidental modifications
Direct SSB authentication uses basic auth over HTTP (suitable for local development)
SQL queries are automatically sanitized with proper semicolon termination
Kafka table creation enforces local-kafka-only connector for data security
Summary
The SSB MCP Server is now a comprehensive management platform for SQL Stream Builder, providing Claude Desktop with access to virtually all SSB functionality through 80+ MCP tools.
🎯 What You Get:
Complete SSB Control: Manage jobs, tables, users, projects, and environments
Advanced Monitoring: System health, diagnostics, and performance tracking
Real-time Data: Flexible sampling and streaming data access
Enterprise Features: API keys, sync, export/import, and multi-environment support
Developer Tools: UDF management, SQL analysis, and connector details
DevOps Integration: Project management, configuration sync, and Git workflows
🚀 Key Benefits:
80%+ API Coverage: Access to virtually all SSB functionality
80+ MCP Tools: Comprehensive toolset for every use case
15 Functional Categories: Organized, discoverable capabilities
Enterprise Ready: Security, monitoring, and scalability features
User Friendly: Natural language interaction through Claude Desktop
Flexible: Supports both standalone and CDP deployments
📈 Perfect For:
Data Engineers: Stream processing, job management, real-time analysis
DevOps Teams: Environment management, monitoring, configuration sync
Data Scientists: Custom UDFs, query analysis, data exploration
Platform Admins: User management, system monitoring, security
The SSB MCP Server transforms Claude Desktop into a powerful SSB management interface, enabling natural language interaction with your entire SQL Stream Builder environment! 🎉
License
Apache License 2.0