
Hybrid RAG MCP Server
Click on "Install Server".
Wait a few minutes for the server to deploy. Once ready, it will show a "Started" state.
In the chat, type
@followed by the MCP server name and your instructions, e.g., "@Hybrid RAG MCP Serversearch the knowledge base for the 2024 annual budget summary"
That's it! The server will respond to your query, and you can continue using it as needed.
Here is a step-by-step guide with screenshots.
Hybrid RAG MCP Server
一个可插拔、可观测、支持 MCP 集成的模块化 RAG(Retrieval-Augmented Generation)服务框架。
项目简介
Hybrid RAG MCP Server 是一个面向工程实践的 RAG 项目,目标是将文档摄取、切分、向量化、混合检索、重排、评测和可观测能力解耦成可组合模块,方便你按需替换模型、向量库和检索策略。
项目适合以下场景:
企业知识库检索
文档问答与内部搜索
MCP 工具化知识增强
RAG 流程实验与评测
可观测的检索系统原型开发
Related MCP server: Modular RAG MCP Server
核心特性
模块化架构:LLM、Embedding、Vector Store、Reranker、Loader、Splitter 都可替换
混合检索:支持 Dense Retrieval + Sparse Retrieval + RRF Fusion
可选重排:支持关闭或启用 rerank 进行二阶段精排
文档摄取:支持 PDF、TXT、Markdown、DOCX 等常见文档格式
可观测性:内置 ingestion/query trace、评测历史与可视化 Dashboard
MCP 集成:可以通过 MCP Tool 形式暴露知识检索能力
交互式调试:提供
Query Playground页面查看 dense / sparse / fusion / rerank 结果
界面预览
Query Playground
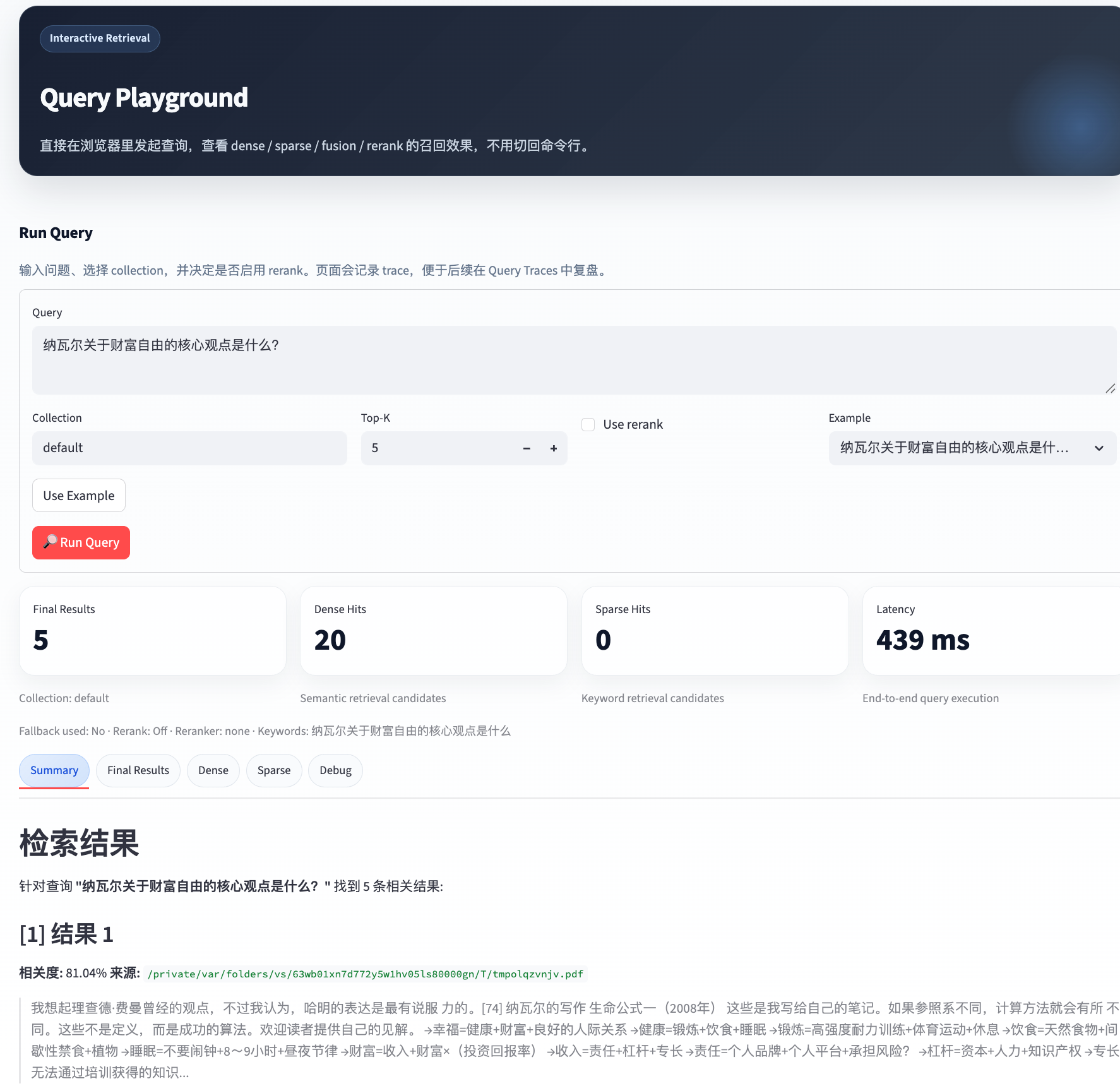
用于直接发起查询,查看 dense / sparse / fusion / rerank 的召回效果。
Data Browser
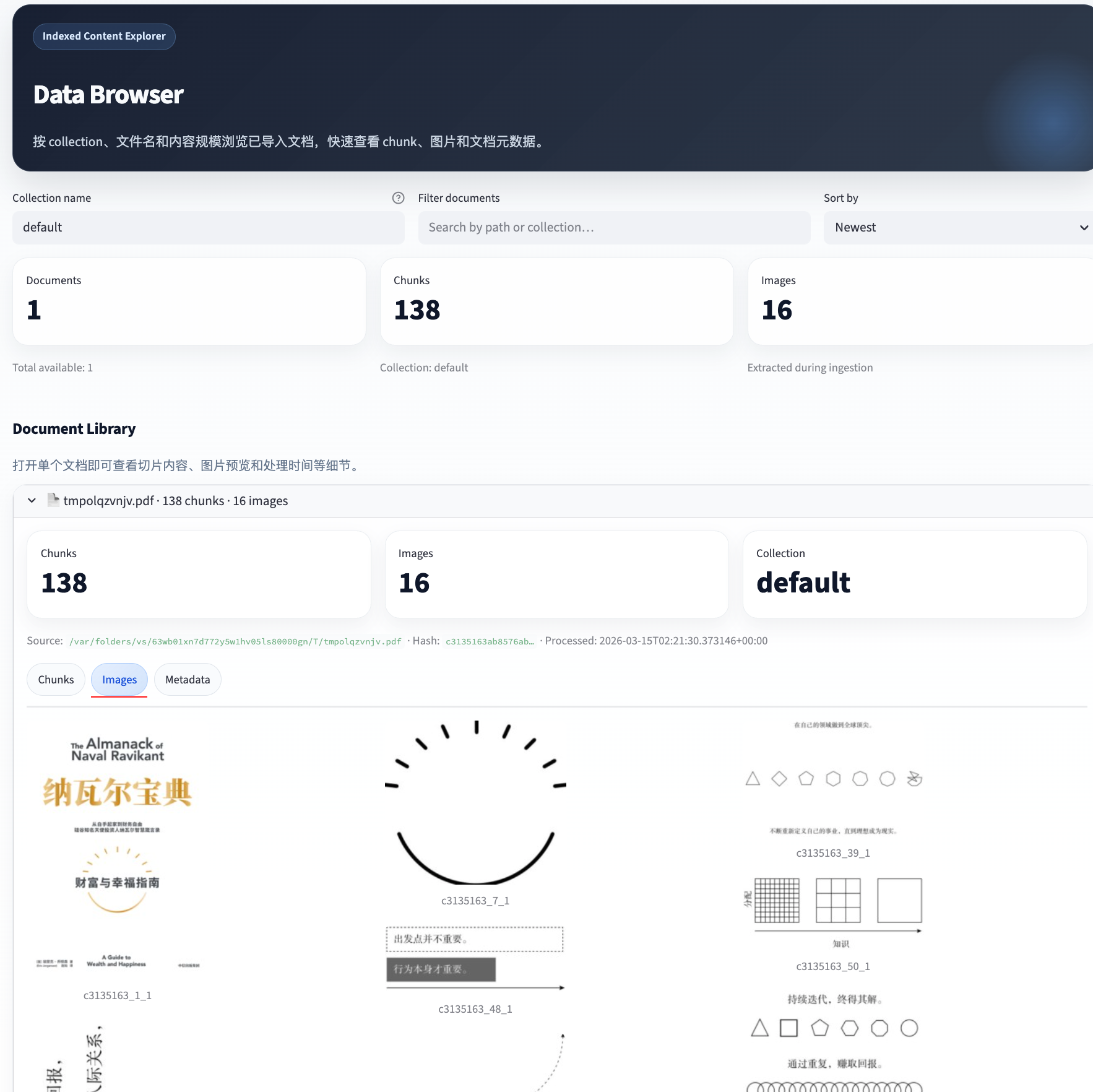
用于浏览已导入文档、chunk 内容、图片与元数据。
系统组成
项目主要由以下部分组成:
src/core/:查询编排、响应构建、追踪上下文等核心逻辑src/ingestion/:文档摄取、切分、编码、索引与存储src/libs/:模型、向量库、加载器、重排器等适配层src/mcp_server/:MCP Server 与工具定义src/observability/:日志、评测、Dashboardscripts/:常用命令行入口tests/:单元测试与集成测试
快速开始
1. 创建虚拟环境并安装依赖
python -m venv .venv
source .venv/bin/activate
pip install -e .[dev]2. 配置模型与服务
编辑 config/settings.yaml,填入你自己的配置:
llm.api_keyembedding.api_key可选的
vision_llm.api_key如果使用 OpenAI 兼容服务,请确认
base_url正确
也可以优先使用环境变量,例如:
export OPENAI_API_KEY="your_api_key"建议不要把真实密钥直接写入仓库并提交到 GitHub。
3. 导入文档
./.venv/bin/python scripts/ingest.py --file path/to/your.pdf --collection default4. 运行查询
./.venv/bin/python scripts/query.py \
--query "纳瓦尔 财富 幸福" \
--collection default \
--verbose5. 启动可视化 Dashboard
./.venv/bin/python scripts/start_dashboard.py --host 127.0.0.1 --port 8501浏览器打开:http://127.0.0.1:8501
可使用页面包括:
OverviewData BrowserIngestion ManagerIngestion TracesQuery PlaygroundQuery TracesEvaluation Panel
配置说明
关键配置位于 config/settings.yaml:
llm:大语言模型配置embedding:向量模型配置vector_store:向量数据库配置retrieval:Dense / Sparse / Fusion 参数rerank:重排配置evaluation:评测配置observability:日志与 trace 配置ingestion:切分、批处理等摄取参数
常见说明
当前中文查询的规则分词较简单,
Sparse Retrieval对“空格分隔关键词”更友好如果你更重视中文稀疏召回,建议后续接入更好的中文分词方案
默认不提交
data/、logs/、虚拟环境与本地 IDE 配置
测试
运行全部测试:
./.venv/bin/python -m pytest运行部分测试:
./.venv/bin/python -m pytest tests/unit -qThis server cannot be installed
Maintenance
Resources
Unclaimed servers have limited discoverability.
Looking for Admin?
If you are the server author, to access and configure the admin panel.
Appeared in Searches
Latest Blog Posts
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/jiarongli517021911144/hybrid-rag-mcp-server'
If you have feedback or need assistance with the MCP directory API, please join our Discord server