
ai-dev-analytics
This server enables structured data collection and analysis for AI-assisted development, turning "vibe coding" into a measurable, improvable process that compounds knowledge over time.
Core Capabilities:
Track tasks (
aida_task_start/aida_task_done): Log task start and completion with automatic duration calculation, grouped by module/stage.Monitor bugs (
aida_log_bug/aida_bug_fix): Record bugs with severity (critical/high/medium/low) and discovery source, then mark them resolved with fix notes.Code reviews (
aida_log_review): Document self-review results with pass/fail status, file scope, and issues found.AI deviation tracking (
aida_log_deviation): Capture instances where AI output didn't meet expectations, categorized by type (UI, API, logic, etc.) and root cause (hallucination, rule-missing, context-insufficient, etc.).Automated file change logging (
aida_log_files): Scangit diffto record modified files and line counts — no manual input required.Highlights (
aida_highlight): Record notable achievements like performance improvements or architectural wins.Current status (
aida_status): Get a real-time snapshot of the active development run — tasks, bugs, and overall progress.Rule sedimentation (
aida_log_rule): Convert recurring deviations into persistent project-level rules (component usage, API conventions, code style) that AI tools reference in future sessions.
Outcome: Each session builds on previous learnings, enabling data-driven retrospectives, sprint reviews, and a standardized SOP from requirement analysis through code generation, review, and rule sedimentation.
Provides specialized configuration and support for the Windsurf IDE, allowing for the collection and visualization of AI development metrics and performance patterns within that environment.
AIDA
让 Vibe Coding 数据化。
每一次 Vibe Coding 都在产生大量信号 —— 偏差、模式、质量数据。 但你关掉终端,这些全部消失。下次对话,继续盲写。 AIDA 在每个开发节点采集结构化数据,用看板可视化,再把偏差规律沉淀成规则 —— 让你的 AI 每次运行都写出更符合预期的代码。
一行配置接入,零工作流改变。
{ "mcpServers": { "aida": { "command": "npx", "args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"] } } }


一行接入 · 场景操作指南 · 数据驱动闭环 · 命令速览 · 重复执行与覆盖策略 · 规则去重与冲突判断 · 命令文档 · 文档导航 · English
一个洞察
Vibe Coding 很强。但它是一个黑箱。
你让 Claude 写一个功能,它写了,你 ship 了。但你对过程零可见性:
AI 完成了多少任务?每个任务花了多长时间?
AI 在哪里偏离了你的项目规范?为什么?
哪些偏差反复出现?加什么规则能根治?
Bug 率多少?哪个阶段产出最多 Bug?
没有数据,你就无法改进。你只是在一遍又一遍地 vibe —— 带着同样的盲区。
AIDA 让不可见变可见。 它在每次 vibe coding 过程中采集结构化数据,用实时看板渲染,再把偏差模式沉淀成项目规则。你的 AI 不再只是写代码 —— 它学习你的项目。
Related MCP server: flaiwheel
🔄 数据驱动闭环
这是 AIDA 的核心 —— 数据进来,规则出去,代码越来越好。
Vibe Coding 过程
↓
AIDA 静默采集结构化数据
(任务、偏差、Bug、自检、文件变更、时间线)
↓
看板可视化呈现规律
"9 个偏差 → 56% 幻觉, 44% 规则缺失"
↓
发现偏差规律 → AI 建议沉淀规则 → 用户确认 → 写入规则库
.aida/rules.json ← 你的 AI 知识库在成长
↓
AI 下次读取规则 → 同样的错误被消除
↓
循环往复 —— 每一轮,AI 输出都更接近你的预期来自真实生产项目的数据:
运行 | 偏差情况 | 发生了什么 | 沉淀的规则 |
第 1 轮 | 47 个任务产生 23 个偏差 | AI 组件用错、布局写反、API 模式不对 | 沉淀 6 条项目专属规则 |
第 2 轮 | 零重复偏差 | AI 读了规则,相同模式的错误归零 | — |
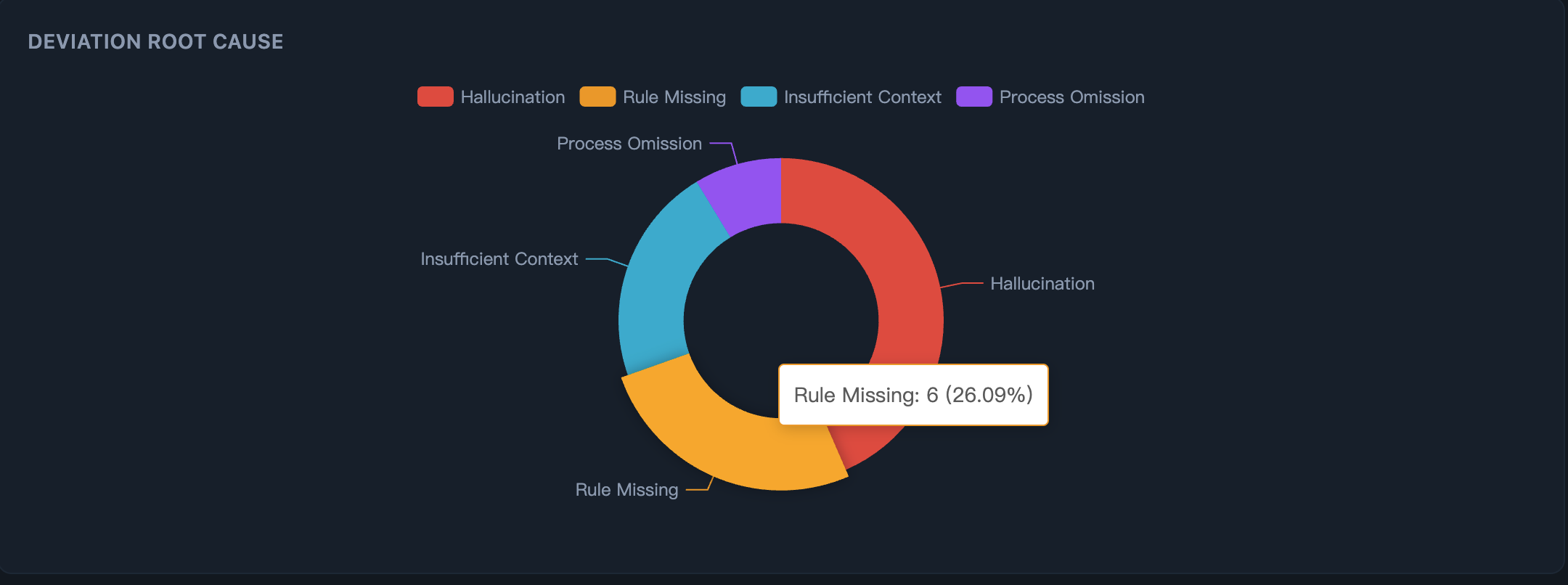
*第一步:看清 AI 为什么出错* —— 根因分布一目了然:是 AI 幻觉、规则缺失、还是上下文不足?
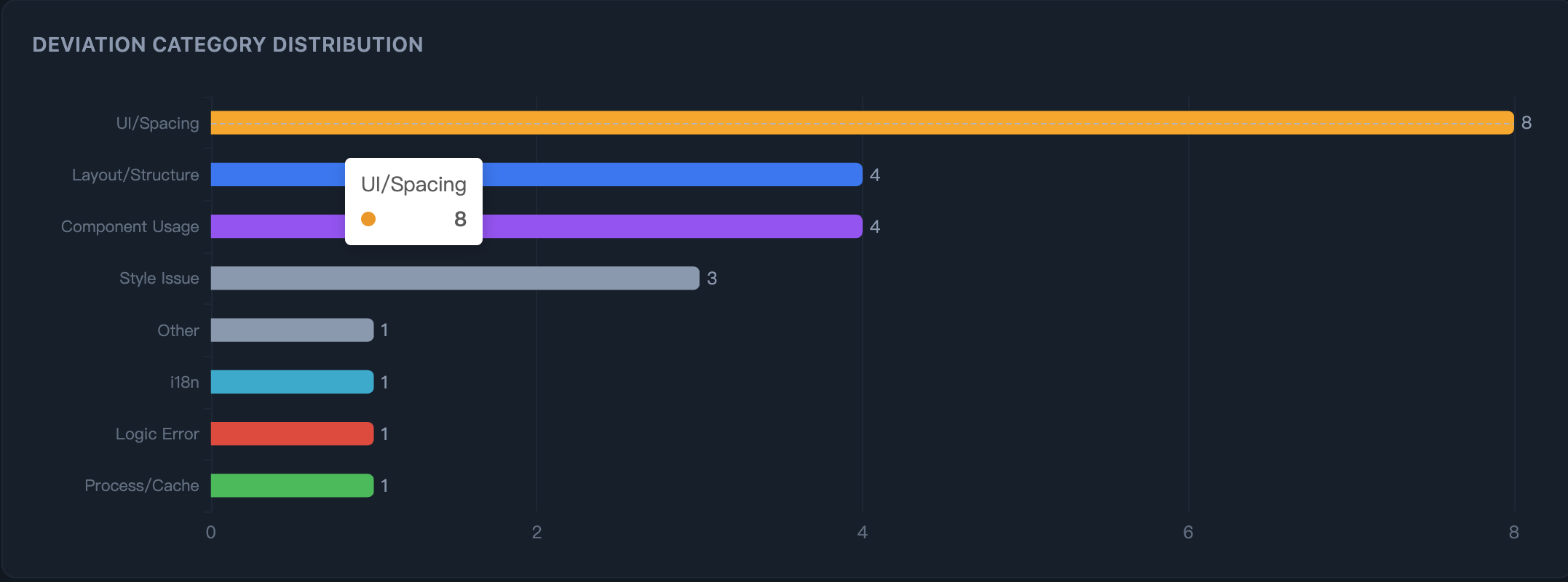
*第二步:看清 AI 在哪出错* —— 类别分布精准定位:UI 间距、布局结构、组件使用、API 模式。
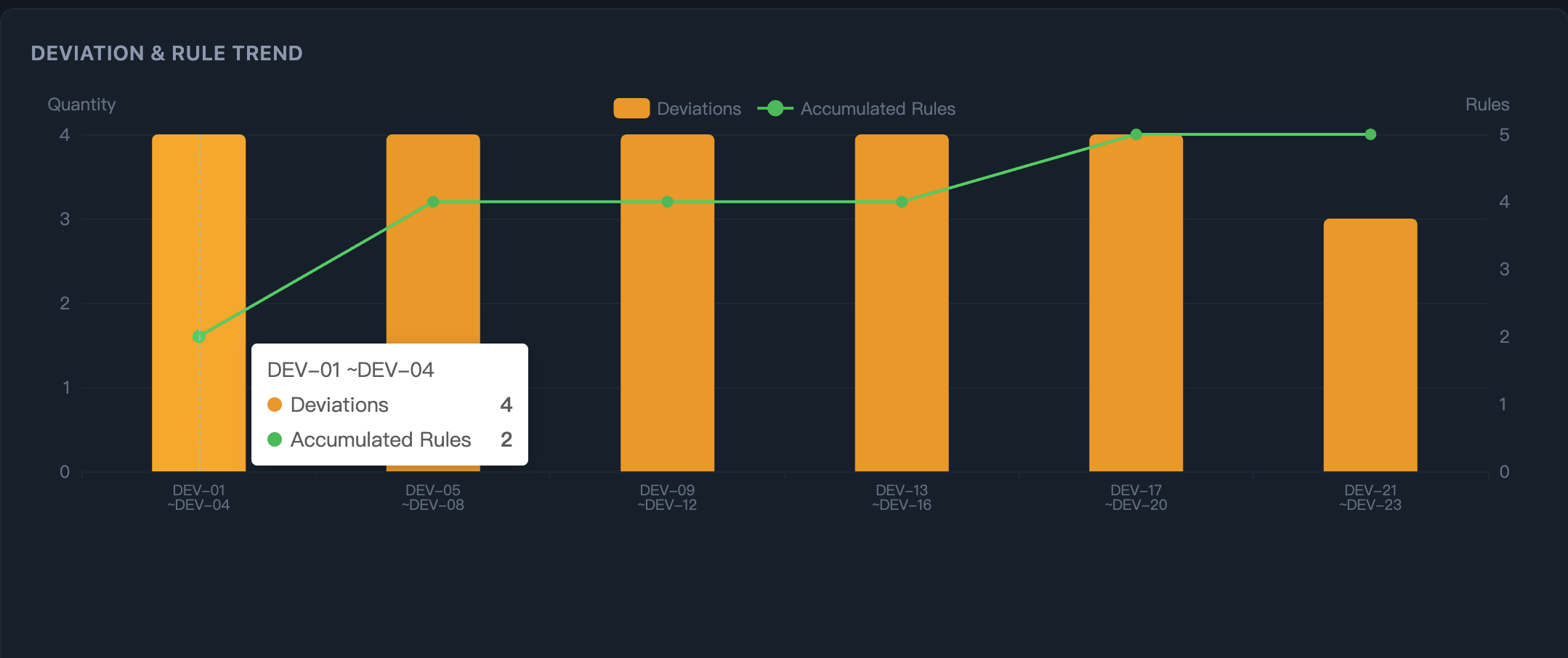
第三步:看规则的复利效应 —— 随着规则积累,重复偏差会逐步下降。
.aida/rules.json 就是你的项目专属 AI 知识库。用 AI 写得越多,它对你的项目就越懂。
📊 数据看板
你的整个 Vibe Coding 过程 —— 结构化、可视化、可操作。
在线 Demo → 真实脱敏数据,无需安装。
AIDA 全方位采集 AI 辅助开发的每个维度,转化为交互式图表:
你能看到什么 | 为什么重要 |
偏差根因分布 | 知道 AI 为什么出错 —— 规则缺失?幻觉?上下文不足? |
偏差类别分布 | 知道 AI 在哪出错 —— 布局?组件?API? |
偏差 & 规则趋势图 | 看着偏差随规则积累而下降 |
Bug 严重度分布 | 追踪质量 —— 哪个阶段产出严重 Bug? |
自检通过率趋势 | AI 代码质量是在变好还是变差? |
各阶段任务完成 | 看到完整开发生命周期的进度 |
文件修改热点 | 哪些文件反复被改?痛点在哪? |
规则溯源表 | 每条规则都关联到产生它的偏差 |
完整开发时间线 | 每个任务、Bug、审查、偏差 —— 按时间排列 |
项目总览(团队视角) | 跨分支统计、开发者对比、需求状态 |
运行 npx ai-dev-analytics dashboard,几秒钟看到你自己项目的数据。
🔒 100% 本地。零外部请求。
AIDA 只往项目里的 .aida/ 目录写 JSON 文件。整个代码库不包含任何外部 HTTP 请求 —— 不发遥测、不上传云端、不请求分析服务、不做任何追踪。你的代码和数据不会离开你的电脑。
⚡ 30 秒上手
在 .mcp.json 里加一行
{ "mcpServers": { "aida": { "command": "npx", "args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"] } } }不需要 SDK,不需要包装器,不需要改代码。把这行加到项目根目录的 .mcp.json,AI 下次写代码时 AIDA 就开始采集数据。
如果
npx较慢,可以先全局安装:npm install -g ai-dev-analytics,然后把 command 改成"aida"。全局安装后也可以直接使用aida命令。
Cursor .cursor/mcp.json:
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}VS Code Copilot .vscode/mcp.json:
{
"servers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}Windsurf ~/.codeium/windsurf/mcp_config.json:
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}Lingma(通义灵码) .lingma/mcp.json:
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}打开看板
npx ai-dev-analytics dashboard打开 http://localhost:2375,即可查看本地数据看板。
🧭 场景操作指南
下面这些是最常见的落地场景。想看详细行为、重复执行语义和边界说明,直接跳到 COMMANDS.md。
1. 新项目初始化
详细步骤见:COMMANDS.md / 场景 1:新项目初始化
适用场景:
仓库里还没有
.aida想从零接入 AIDA
操作:
aida init你会在交互里选择:
collect或full模式需要接入的 AI 工具
是否导入现有工具的规则 / skills 作为 baseline
初始化后建议立即检查:
aida build
aida status2. 老项目迁移到 AIDA
详细步骤见:COMMANDS.md / 场景 2:老项目迁移
适用场景:
项目还在使用旧
.aidevos想把旧 rules / skills / run 数据迁进当前 AIDA 体系
最省事的方式:
aida migrate-legacy如果你想显式指定 baseline tool:
aida migrate-legacy cursor
aida migrate-legacy codex如果你想拆开执行:
aida migrate-dir
aida import cursor
aida migrate
aida memory rebuild
aida build3. 已经初始化过,但产物缺失或版本升级后想补齐
详细步骤见:COMMANDS.md / 场景 3:项目已初始化,但想补齐缺失产物
适用场景:
AGENTS.md/CLAUDE.md/.codex/config.toml被删了旧版本包生成不完整
发新包后想在老项目里补齐生成产物
操作:
aida init然后在交互里选:
Repair missing generated files
或者直接跑:
aida build
aida migrate-legacy其中:
aida build适合“真源没问题,只想重建产物”aida migrate-legacy适合“历史项目想顺手补齐 memory / import / build 全链路”
4. 已有工具规则想回收进 .aida/*.json
详细步骤见:COMMANDS.md / 场景 4:import 和 build 怎么配合
适用场景:
项目里已经有
.cursor/、.claude/、.codex/本地规则想把分散资产统一回收到
.aida/rules.json/.aida/skills.json
操作:
aida import
aida import cursor
aida import codex经验上:
无参数
import:适合把当前项目里能发现的资产统一扫回 AIDA带 baseline tool:适合你明确知道“以某个工具的资产为准”
回收后建议再跑一次:
aida build5. rules 冲突
详细步骤见:COMMANDS.md / 场景 5:rules 冲突
适用场景:
git pull/git merge后.aida/rules.json出现 conflict marker
操作:
aida rules merge如果你想顺手把 skills.json 也一起处理:
aida merge然后建议检查:
aida rules dedupe
aida build6. skills 冲突
详细步骤见:COMMANDS.md / 场景 6:skills 冲突
适用场景:
.aida/skills.json出现 conflict marker
操作:
aida merge或者只处理 skills:
aida skills merge处理完建议再跑:
aida build7. 规则重复、相似、怀疑冲突
相关操作见:COMMANDS.md / 场景 5:rules 冲突
适用场景:
规则越积越多
多分支合并后担心重复
想清理 exact duplicate,再人工看 near duplicate
操作:
aida rules dedupe它会:
自动移除 exact duplicate
提示 near duplicate / potential conflict
如果你手工改了 .aida/rules.json,记得再跑:
aida rules build8. 发布前自检建议
详细步骤见:COMMANDS.md / 场景 8:发布前自检
如果你准备发包,至少建议在当前项目里跑一遍:
npm run build
npm test
npm pack --dry-run
aida build
aida import codex
aida migrate-legacy codex
aida rules build
aida rules dedupe如果仓库里还有冲突样本,建议再补:
aida rules merge
aida merge🧭 命令速览
初始化与迁移
aida init
aida migrate-dir
aida migrate-legacyaida init:初始化新项目;如果项目已初始化,会进入“新增工具 / 修复缺失产物 / 退出”的分支。aida migrate-dir:只做.aidevos -> .aida目录迁移与路径替换;已经迁过时会安全 no-op。aida migrate-legacy:一键迁移老项目;即使项目已经是.aida,也可以重跑,用于补建之前缺失的产物。
构建与合并
aida build
aida merge
aida rules build
aida rules dedupeaida build:从.aida/*.json真源重建规则视图、技能、工具侧产物、MCP 配置和 memory 视图。aida merge:解决.aida/rules.json/.aida/skills.json的 git conflict 内容。aida rules build:只重建规则相关产物。aida rules dedupe:先移除完全重复的规则,再提示近似重复/潜在冲突的规则。
详细说明见 COMMANDS.md。
🧩 规则去重与冲突判断
1. 完全重复如何判断
AIDA 用 fingerprint 判断 exact duplicate。生成规则如下:
转小写
折叠空白字符:多个空格 / 换行 / tab 归一成一个空格
去掉常见中英文标点
trim对归一化后的内容做
sha256取前 12 位作为
fingerprint
这意味着以下内容会被视为同一条规则:
禁止任何形式的臆想,不清楚必须询问禁止任何形式的臆想,不清楚必须询问禁止任何形式的臆想,不清楚必须询问!
2. 近似重复 / 潜在冲突如何判断
aida rules dedupe 不只看 fingerprint。对于不同 fingerprint 的规则,它会继续做近似判断:
只比较同一
category下的规则用和
fingerprint一致的归一化规则做文本清洗按空格切词
过滤长度小于等于 1 的 token
计算 Jaccard 相似度
相似度
>= 0.4时,标记为 potential duplicate
这类规则不会自动合并,只会提示人工处理。原因很简单:语义相近不代表可以安全替换。
3. 当前行为
rules add:按fingerprint阻止新增完全重复规则merge:按fingerprint合并冲突两侧规则build:分发规则视图时会过滤 exact duplicate,避免生成产物里重复出现rules dedupe:会把rules.json里已经存在的 exact duplicate 清掉,并继续提示 near duplicate
🔁 重复执行与覆盖策略
重复执行的目标是补全缺失,不破坏用户手工内容。当前策略如下。
安全重跑的命令
aida init未初始化时:正常初始化
已初始化时:进入交互分支,可选择新增工具或修复缺失文件
aida migrate-dir已经使用
.aida时:直接 no-op
aida migrate-legacy已迁移项目可重跑
适合“老版本包生成不完整,升级后再补建”的场景
不会直接冲掉用户内容的部分
AGENTS.md/CLAUDE.md只维护 AIDA 注入区块
已有自定义内容会尽量保留
.mcp.json/.cursor/mcp.json/.lingma/mcp.json走 JSON merge,把
aidaMCP server 合进去
.codex/config.toml只维护
[mcp_servers.aida]片段,保留其他配置
.gitignore只追加缺失条目,不清空现有内容
会被重建覆盖的部分
以下属于 AIDA 受管生成产物,重复执行会按 .aida/*.json 真源重建:
.aida/rules/*.md.aida/memories/modules/*.md.aida/runs/*/context.md.cursor/rules/aida/*.codex/rules/aida/*.claude/rules/aida/*.lingma/rules/*工具侧由 AIDA 分发的 skill / command 文件
这部分不建议手改。若手改,再次 build / repair / migrate-legacy 时会被覆盖,这是预期行为。
推荐原则
想长期保留的规则、技能、上下文:改
.aida/*.json真源只想修复缺失产物:优先重跑
aida init -> repair或aida migrate-legacy不要把人工内容写进 AIDA 受管生成目录
📁 数据沉淀与绩效汇报
AIDA 不只是可视化 —— 它沉淀数据。每次运行都积累结构化数据,时间越长价值越大。
第 1 周:47 个任务、23 个偏差、5 个 Bug、6 条规则、4064 行代码
第 4 周:180+ 任务、偏差率持续下降、15 条规则、完整质量历史
一个季度:完整的开发记录 —— 可导出、可分析、可汇报所有数据都在 .aida/ 里,格式是结构化 JSON。没有厂商锁定,随时可以导出、查询或接入别的报表系统。
Maintenance
Latest Blog Posts
- Your AI Chatbot Just Exposed Your CEO's Salary to an InternBy Om-Shree-0709 on .Agent IdentityMCP SecurityOAuth Delegation
- Why MCP Servers Need Execution Sandboxing (And Why Your Current Stack Isn't Enough)By Om-Shree-0709 on .Agentic AiPrompt InjectionWebAssembly
MCP directory API
We provide all the information about MCP servers via our MCP API.
curl -X GET 'https://glama.ai/api/mcp/v1/servers/LWTlong/ai-dev-analytics'
If you have feedback or need assistance with the MCP directory API, please join our Discord server